高效能 Java 計算服務的效能調優實戰
作者:vivo 網際網路伺服器團隊- Chen Dongxing、Li Haoxuan、Chen Jinxia
隨著業務的日漸複雜,效能優化儼然成為了每一位技術人的必修課。效能優化從何著手?如何從問題表象定位到效能瓶頸?如何驗證優化措施是否有效?本文將介紹分享 vivo push 推薦專案中的效能調優實踐,希望給大家提供一些借鑑和參考。
一、背景介紹
在 Push 推薦中,線上服務從 Kafka 接收需要觸達使用者的事件,之後為這些目標使用者選出最合適的文章進行推播。服務由 Java 開發,CPU 密集計算型。
隨著業務的不斷髮展,請求並行及模型計算量越來越大,導致工程上遇到了效能瓶頸,Kafka 消費出現嚴重的積壓現象,無法及時完成目標使用者的分發,業務增長訴求得不到滿足,故亟需進行效能專項優化。
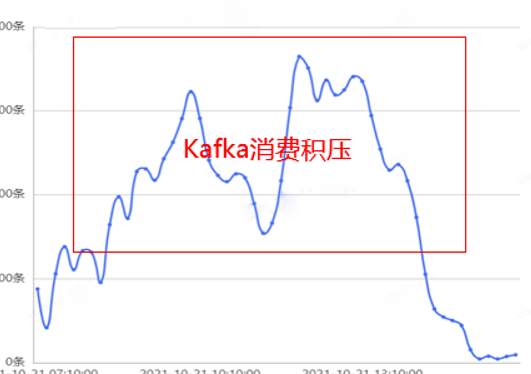
二、優化衡量指標和思路
我們的效能衡量指標是吞吐量 TPS ,由經典公式 TPS = 並行數 / 平均響應時間RT 可以知道,若需提高 TPS,可以有 2 種方式:
-
提高並行數,比如提升單機的並行執行緒數,或者橫向擴容機器數;
-
降低平均響應時間 RT,包括應用執行緒(業務邏輯)執行時間,以及 JVM 本身的 GC 耗時。
實際情況中,我們的機器 CPU 利用率已經很高,達到 80% 以上,提升單機並行數的預期收益有限,故把主要精力投入到降低 RT 上。
下面將從 熱點程式碼 和 JVM GC 兩個方面進行詳解,我們如何分析定位到效能瓶頸點,並使用 3 招將吞吐量提升 100% 。
三、熱點程式碼優化篇
如何快速找到應用中最耗時的熱點程式碼呢?藉助阿里巴巴開源的 arthas 工具,我們獲取到線上服務的 CPU 火焰圖。
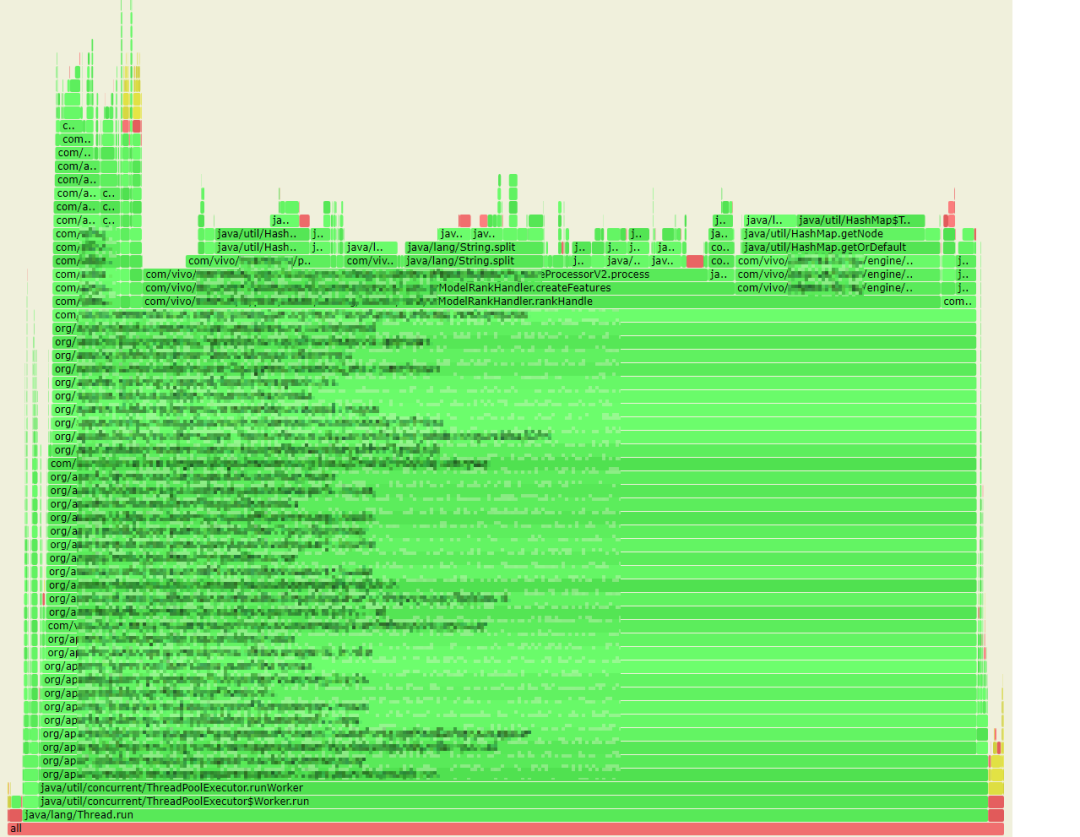
火焰圖說明:火焰圖是基於 perf 結果產生的 SVG 圖片,用來展示 CPU 的呼叫棧。
y 軸表示呼叫棧,每一層都是一個函數。呼叫棧越深,火焰就越高,頂部就是正在執行的函數,下方都是它的父函數。
x 軸表示抽樣數,如果一個函數在 x 軸佔據的寬度越寬,就表示它被抽到的次數多,即執行的時間長。注意,x 軸不代表時間,而是所有的呼叫棧合併後,按字母順序排列的。
火焰圖就是看頂層的哪個函數佔據的寬度最大。只要有「平頂」(plateaus),就表示該函數可能存在效能問題。
顏色沒有特殊含義,因為火焰圖表示的是 CPU 的繁忙程度,所以一般選擇暖色調。
3.1 優化1:儘量避免原生 String.split 方法
3.1.1 效能瓶頸分析
從火焰圖中,我們首先發現了有 13% 的 CPU 時間花在了 java.lang.String.split 方法上。
熟悉效能優化的同學會知道,原生 split 方法是效能殺手,效率比較低,頻繁呼叫時會耗費大量資源。
不過業務上特徵處理時確實需要頻繁地 split,如何優化呢?
通過分析 split 原始碼,以及專案的使用場景,我們發現了 3 個優化點:
(1)業務中未使用正規表示式,而原生 split 在處理分隔符為 2 個及以上字元時,預設按正規表示式方式處理;眾所周知,正規表示式的效率是低下的。
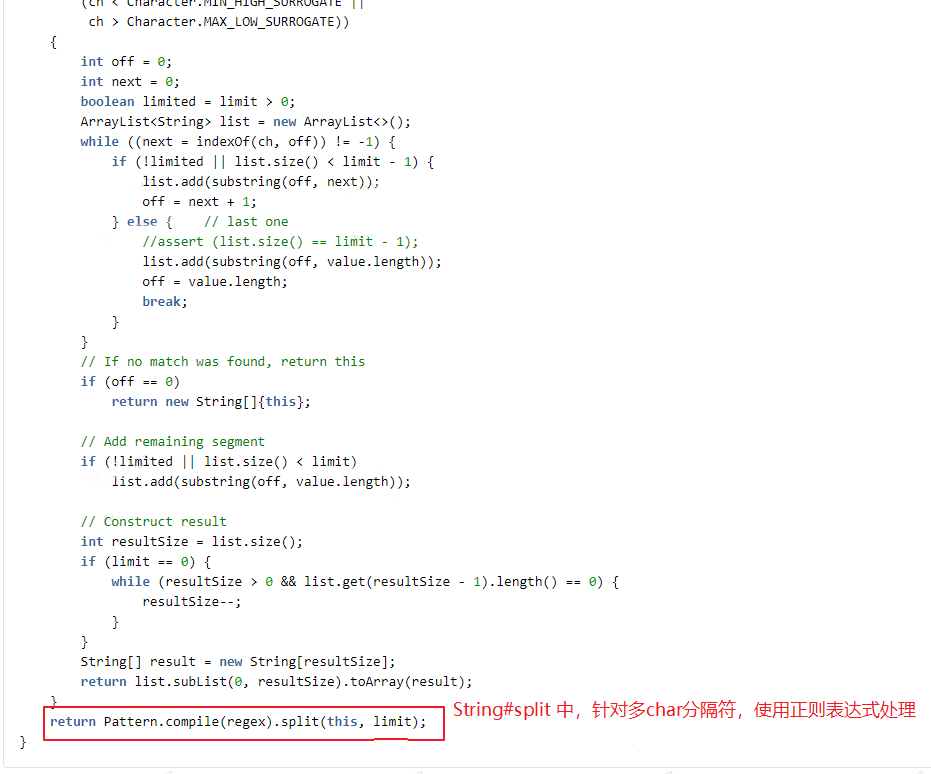
(2)當分隔符為單個字元(且不為正規表示式字元)時,原生 String.split 進行了效能優化處理,但中間有些內部轉換處理,在我們的實際業務場景中反而是多餘的、消耗效能的。
其具體實現是:通過 String.indexOf 及 String.substring 方法來實現分割處理,將分割結果存入 ArrayList 中,最後將 ArrayList 轉換為 string[] 輸出。而我們業務中,其實很多時候需要 list 型結果,多了 2 次 list 和 string[] 的互轉。
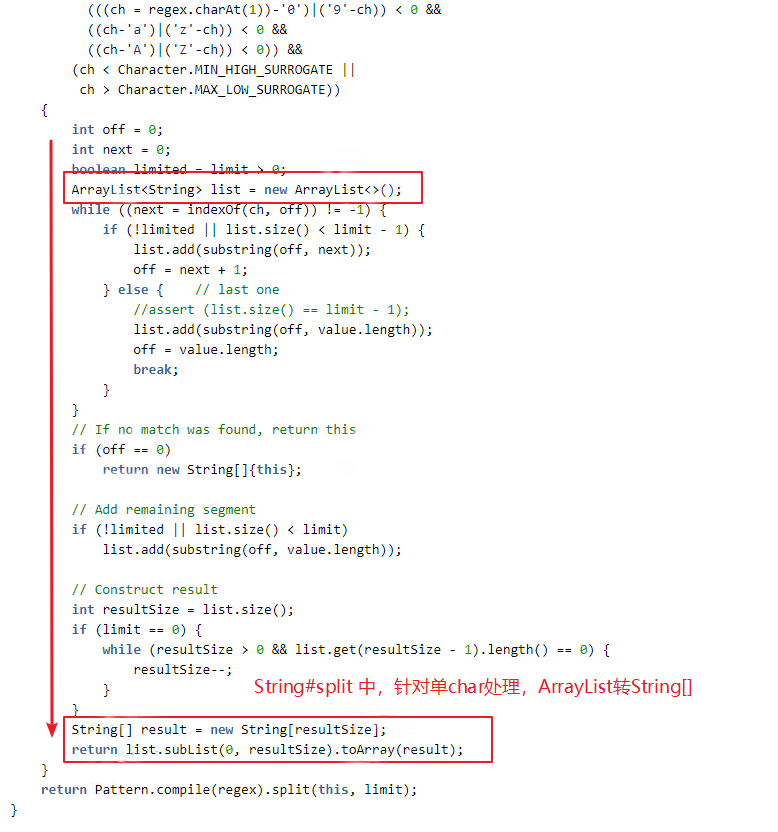
(3)業務中呼叫 split 最頻繁的地方,其實只需要 split 後的第 1 個結果;原生 split 方法或其它工具類有過載優化方法,可以指定 limit 引數,滿足 limit 數量後可以提前返回;但業務程式碼中,使用 str.split(delim)[0] 方式,非效能最佳。
3.1.2 優化方案
針對業務場景,我們自定義實現了效能優化版的 split 實現。
import java.util.ArrayList; import java.util.List; import org.apache.commons.lang3.StringUtils; /** * 自定義split工具 */ public class SplitUtils { /** * 自定義分割函數,返回第一個 * * @param str 待分割的字串 * @param delim 分隔符 * @return 分割後的第一個字串 */ public static String splitFirst(final String str, final String delim) { if (null == str || StringUtils.isEmpty(delim)) { return str; } int index = str.indexOf(delim); if (index < 0) { return str; } if (index == 0) { // 一開始就是分隔符,返回空串 return ""; } return str.substring(0, index); } /** * 自定義分割函數,返回全部 * * @param str 待分割的字串 * @param delim 分隔符 * @return 分割後的返回結果 */ public static List<String> split(String str, final String delim) { if (null == str) { return new ArrayList<>(0); } if (StringUtils.isEmpty(delim)) { List<String> result = new ArrayList<>(1); result.add(str); return result; } final List<String> stringList = new ArrayList<>(); while (true) { int index = str.indexOf(delim); if (index < 0) { stringList.add(str); break; } stringList.add(str.substring(0, index)); str = str.substring(index + delim.length()); } return stringList; } }
相比原生 String.split ,主要有幾方面的改動:
-
放棄正規表示式的支援,僅支援按分隔符進行 split;
-
出參直接返回 list。分割處理實現,與原生實現中針對單字元的處理類似,使用 string.indexOf 及 string.substring 方法,分割結果放入 list 中,出參直接返回 list,減少資料轉換處理;
-
提供 splitFirst 方法,業務場景只需要分隔符前第一段字串時,進一步提升效能。
3.1.3 微基準測試
如何驗證我們的優化效果呢?首先選用 jmh 作為微基準測試工具,對照選用 原生 String.split 以及 apache 的 StringUtils.split方法,測試結果如下:
選用單字元作為分隔符
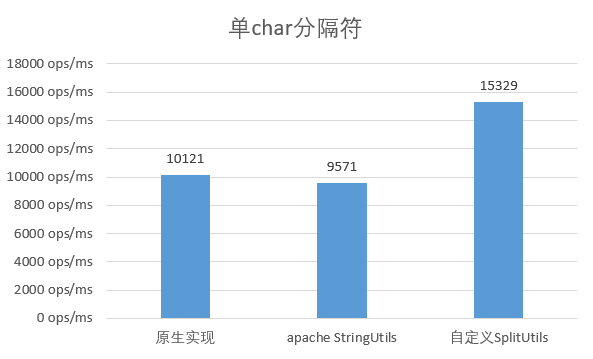
可以看出,原生實現與apache的工具類效能差不多,而自定義實現效能提升了約 50%。
選用多字元作為分隔符
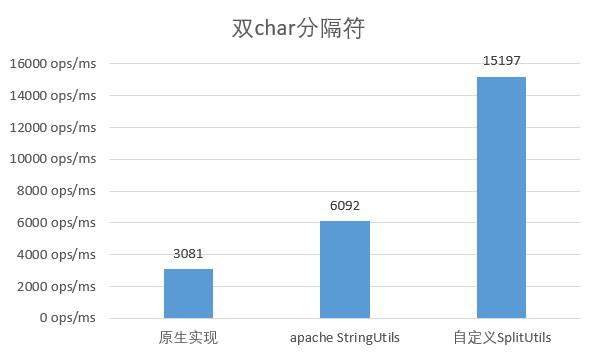
當分隔符使用 2 個長度的字元時,原始實現的效能大幅降低,只有單 char 時的 1/3 ;而apache的實現也降低至原來的 2/3 ,而自定義實現與原來基本保持一致。
選用單字元作為分隔符,只需返回第 1 個分割結果
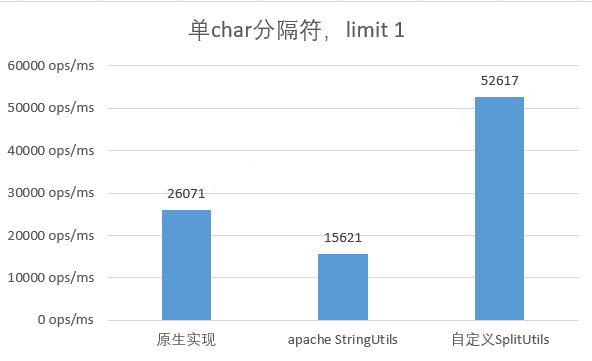
選用單字元作為分隔符,並只需第 1 個分割結果時,自定義實現的效能是原生實現的 2 倍,並是取原生實現完整結果的 5 倍。
3.1.4 端到端優化效果
經微基準測試驗證收益後,我們將優化部署到線上服務中,驗證端到端整體的效能收益;
重新使用arthas採集火焰圖,split 方法耗時降低至 2% 左右;端到端整體耗時下降了 31.77% ,吞吐量上漲了 45.24% ,效能收益特別明顯。
3.2 優化2:加快 map 的查表效率
3.2.1 效能瓶頸分析
從火焰圖中,我們發現 HashMap.getOrDefault 方法耗時佔比也特別多,達到了 20%,主要在查詢權重 map 上,這是因為:
-
業務中確實需高頻呼叫,特徵交叉處理後數量膨脹,單機的呼叫並行達到了約 1000w ops/s。
-
權重 map 本身也很大,儲存了 1000 萬多的 entry,佔用了很大一塊記憶體;同時 hash 碰撞的概率也增大,碰撞時的查詢效率由 O(1) 降低成了 O(n) (連結串列) 或 O(logn) (紅黑樹)。
Hashmap 本身是非常高效的 map 實現,起初我們嘗試了調整載入因子 loadFactor 或 換用其它 map 實現,均未取得明顯收益。
如何才能提升 get 方法的效能呢?
3.2.2 優化方案
分析過程中我們發現查詢 map 的 key(交叉處理後的特徵 key )是字串型,且平均長度在 20 以上;我們知道 string 的 equals 方法其實是遍歷比對 char[] 中的字元,key 越長則比對效率越低。
public boolean equals(Object anObject) { if (this == anObject) { return true; } if (anObject instanceof String) { String anotherString = (String)anObject; int n = value.length; if (n == anotherString.value.length) { char v1[] = value; char v2[] = anotherString.value; int i = 0; while (n-- != 0) { if (v1[i] != v2[i]) return false; i++; } return true; } } return false; }
是否可以將 key 的長度縮短,或者甚至換成數值型?通過簡單的微基準測試,我們發現思路應該是可行的。
於是與演演算法同學溝通,巧的是演演算法同學正好也有相同訴求,他們在切換新訓練框架過程中發現 string 的效率特別低,需要把特徵換成數值型。
一拍即合,方案很快確定:
-
演演算法同學將特徵 key 對映成 long 型數值,對映方法為自定義的 hash 實現,儘量減少 hash 碰撞概率;
-
演演算法同學訓練輸出新模型的權重 map ,可以保留更多 entry ,以打平基線模型的效果指標;
-
打平基線模型的效果指標後,線上伺服器端灰度新模型,權重 map 的 key 改用 long 型,驗證效能指標。
3.2.3 優化效果
在增加了 30% 的特徵 entry 數下(模型效果超過基線),工程上的效能也達到了明顯收益;
端到端整體耗時下降了 20.67%,吞吐量上漲了 26.09%;此外記憶體使用上也取得了良好收益,權重map的記憶體大小下降了30%。
四、JVM GC優化篇
Java 設計垃圾自動回收的目的是將應用程式開發人員從手動動態記憶體管理中解放出來。開發人員無需關心記憶體的分配與回收,也不用關注分配的動態記憶體的生存期。這完全消除了一些與記憶體管理相關的錯誤,代價是增加了一些執行時開銷。
在小型系統上開發時,GC 的效能開銷可以忽略,但擴充套件到大型系統(尤其是那些具有大量資料、許多執行緒和高事務率的應用程式)時,GC 的開銷不可忽視,甚至可能成為重要的效能瓶頸。
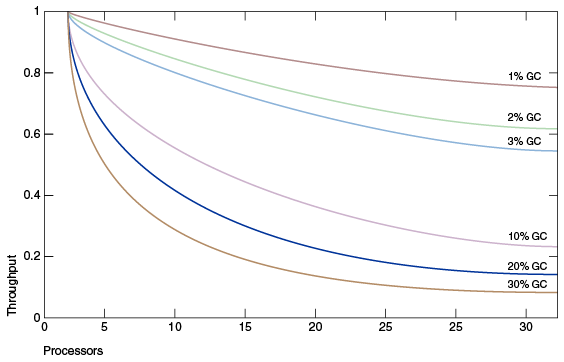
上圖 模擬了一個理想的系統,除了垃圾收集之外,它是完全可伸縮的。紅線表示在單處理器系統上只花費 1% 時間進行垃圾收集的應用程式。這意味著在擁有 32 個處理器的系統上,吞吐量損失超過 20% 。洋紅色線顯示,對於垃圾收集時間為 10% 的應用程式(在單處理器應用程式中,垃圾收集時間不算太長),當擴充套件到 32 個處理器時,會損失 75% 以上的吞吐量。
故 JVM GC 也是很重要的效能優化措施。
我們的推薦服務使用高配計算資源(64核256G),GC的影響因素挺可觀;通過採集監控線上服務 GC 資料,發現我們的服務 GC 情況挺糟糕的,每分鐘YGC累計耗時約 10s。
GC 開銷為何這麼大,如何降低 GC 的耗時呢?
4.1 優化3:使用堆外快取代替堆內快取
4.1.1 效能瓶頸分析
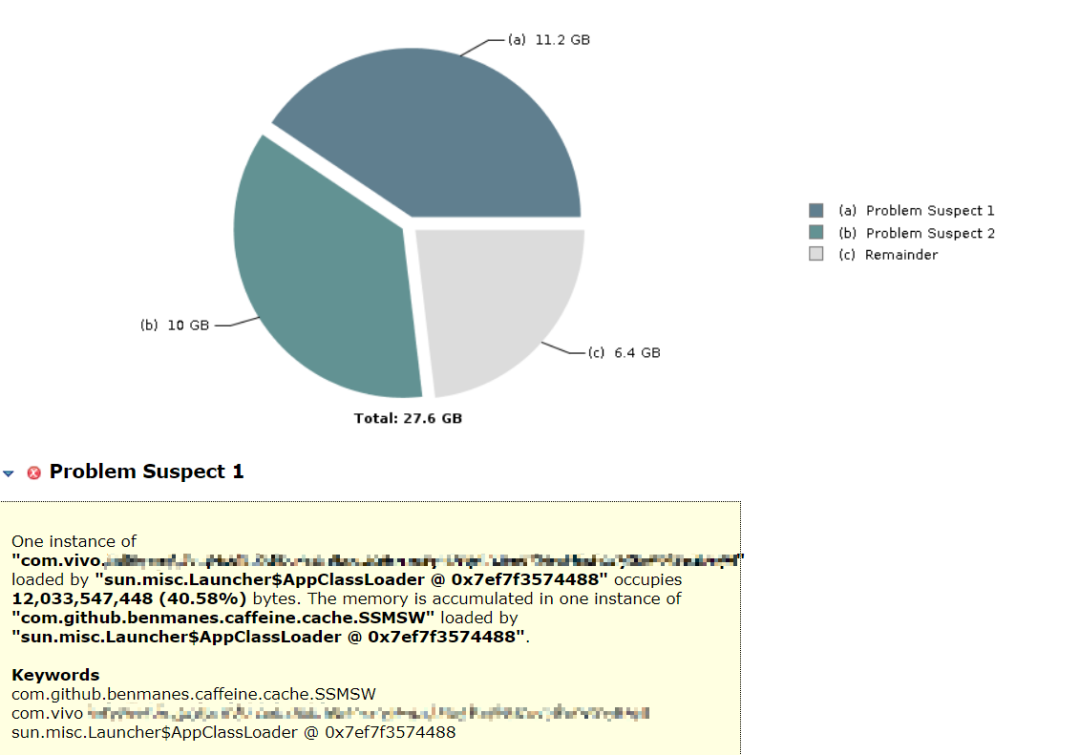
我們 dump 了服務的存活堆物件,使用 mat 工具進行記憶體分析,發現有 2 個物件特別巨大,佔了總存活堆記憶體的 76.8%。其中:
-
第 1 大物件是本地快取,儲存了細粒度級別的常用資料,每臺機器千萬級別資料量;使用 caffine 快取元件,快取自動重新整理週期設定 1 小時;目的是儘量減少 IO 查詢次數;
-
第 2 大物件是模型權重 map 本身,常駐記憶體中,不會 update,等新模型載入後被作為舊模型進行解除安裝。
4.1.2 優化方案
如何能儘量快取較多的資料,同時避免過大的 GC 壓力呢?
我們想到了把快取物件移到堆外,這樣可以不受堆內記憶體大小的限制;並且堆外記憶體,並不受 JVM GC 的管控,避免了快取過大對 GC 的影響。經過調研,我們決定採用成熟的開源堆外快取元件 OHC 。
(1)OHC 介紹
簡介
OHC 全稱為 off-heap-cache,即堆外快取,是 2015 年針對 Apache Cassandra 開發的快取框架,後來從 Cassandra 專案中獨立出來,成為單獨的類庫,其專案地址為https://github.com/snazy/ohc 。
特性
-
資料儲存在堆外,只有少量後設資料儲存堆內,不影響 GC
-
支援為每個快取項設定過期時間
-
支援設定 LRU、W_TinyLFU 驅逐策略
-
能夠維護大量的快取條目
-
支援非同步載入快取
-
讀寫速度在微秒級別
(2)OHC 用法
快速開始:
OHCache ohCache = OHCacheBuilder.newBuilder().
keySerializer(yourKeySerializer)
.valueSerializer(yourValueSerializer)
.build();
可選設定項:
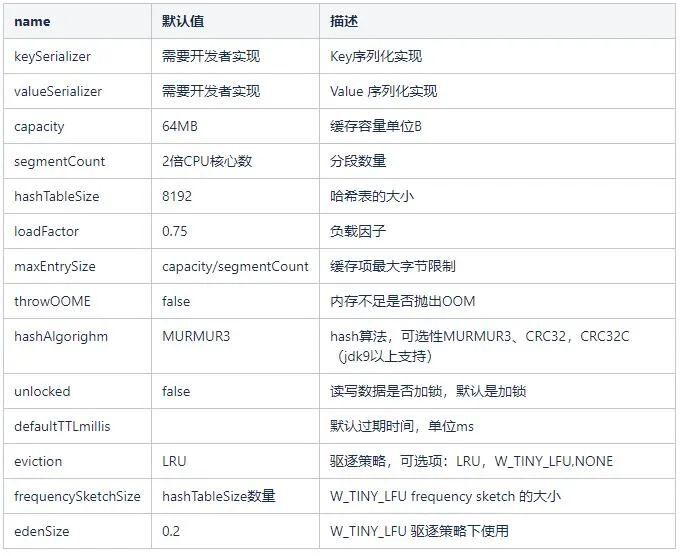
在我們的服務中,設定 capacity 容量 12G,segmentCount 分段數 1024,序列化協定使用 kryo。
4.1.3 優化效果
切換到堆外快取後,服務 YGC 降低到了 800ms / 每分鐘,端到端的整體吞吐量上漲了約 20%。
4.2 思考題
在Java GC優化中,我們把本地快取物件從Java堆內移到了堆外,取得了不錯的效能收益。 還記得上文提到的另一個巨型物件, 模型權重 map 嗎 ?模型權重 map 能否也從 Java 堆內移除?
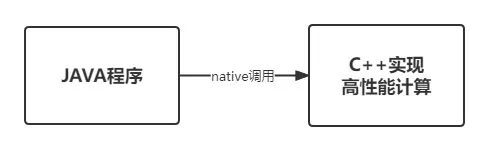
答案是可以的。我們使用C++改寫了模型推理計算部分,包括權重map的儲存與檢索、排序得分計算等邏輯;然後將C++程式碼輸出為 so 庫檔案,Java程式通過 native 方式呼叫,實現將權重map從 Jvm 堆內移出,獲得了很好的效能收益。
五、結束語
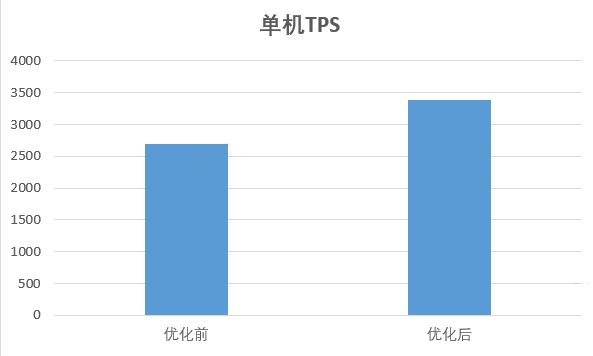
通過上文介紹的 3 個措施,我們從 熱點程式碼優化 與 Jvm GC兩方面改善了服務負載與效能,整體吞吐量翻了 1 倍,達到了階段性的預期目標。
不過效能調優是永無止境的,而且每個業務場景、每個系統的實際情況也都是千差萬別,很難用1篇文章去涵蓋介紹所有的優化場景。希望本文介紹的一些調優實戰經驗,比如如何確定優化方向、如何著手分析以及如何驗證收益,能給大家一些借鑑和參考。