前端穩定性建設
穩定性是數學或工程上的用語,判別一系統在有界的輸入是否也產生有界的輸出。若是,稱系統為穩定;若否,則稱系統為不穩定。
前端的穩定性大致也可以如此概括,簡單地說就是在外界影響下表現出的某種穩定狀態,例如無報錯、響應快、內容呈現正確等。
要想達到穩定狀態,需要做些有效的防範措施和機制,而這些也正是我們組現在和未來會持續推進的工作之一。
一、監控
線上業務是必須要監控的,否則在排查使用者問題時將無從下手。
1)業務監控
業務監控就是與業務相關的監控,常見的就是Node.js的程式碼紀錄檔。
包括資料庫查詢語句、內部通訊的請求和響應、自定義的列印、程式碼報錯等。
這部分在接入阿里雲的服務後,就可以通過阿里雲提供的紀錄檔網站查詢到,如下所示。
content: { "name": "koa", "pid": 26, "req_id": "4df3f997e7dc6c03eeaac3e1e01ee0f5", "level": 30, "msg": " <-- POST /services/getKey", "time": "2022-08-23T10:25:21.927Z", "v": 0 } content: { "name": "backend", "pid": 26, "level": 20, "msg": "4df3f997e7dc6c03eeaac3e1e01ee0f5 SELECT `id`, `title` FROM `app_global` AS `AppGlobal` WHERE `AppGlobal`.`key` = 'xxxxx' LIMIT 1", "time": "2022-08-23T10:25:21.928Z", "v": 0 }
其中第一條的req_id和第二條msg的第一段字串是一個識別符號,可將通訊和其他紀錄檔串聯起來,這樣就能在幾百萬條紀錄檔中準確的查到,這次通訊查了什麼表、列印了什麼內容等。
還有一部分業務監控需要自己搭建,包括前端的指令碼錯誤、非同步通訊、效能引數等。
目前已研發出SDK,嵌入到線上各個H5網頁,以及小程式。
配套的管理後臺也在穩定執行中,可實時查監控各個專案的異常,非同步通訊的JSON響應。
雖然程式碼紀錄檔可以記錄Ajax請求的地址,但是無法輸出Ajax響應的JSON資料,如下所示。
所以才又重新研發了一套前端監控系統,補充伺服器端紀錄檔的不足。
{ "type": "GET", "url": "//web-api.xx.me/game/detail", "status": 200, "endBytes": "0.17KB", "header": { "req-id": "4df3f997e7dc6c03eeaac3e1e01ee0f5" }, "interval": "195.7ms", "network": { "bandwidth": 0, "type": "4G" }, "response": { "status": 1, "data": { "count": 3, "isExperience": true, } } }
注意,在紀錄檔中也有一個req-id欄位,用於和伺服器端的程式碼紀錄檔做關聯,便於排查。
效能監控也是業務監控的一部分,主要監控著白屏、首屏、各個階段的耗時等,如下所示,單位ms。
{ "unloadEventTime": 0, "loadEventTime": 1, "interactiveTime": 580, "firstPaintStart": 771, "firstContentfulPaint": 0, "parseDomTime": 188, "initDomTreeTime": 307, "readyStart": 1, "redirectCount": 0, "compression": 0, "redirectTime": 0, "appcacheTime": 0, "lookupDomainTime": 0, "connectSslTime": 0, "connectTime": 0, "requestTime": 273, "requestDocumentTime": 271, "responseDocumentTime": 2, "TTFB": 272, "now": 775, }
在蒐集到使用者手機中頁面的真實效能情況後,就可針對性的做各種優化。
2)系統監控
系統監控包括伺服器CPU、記憶體、負載、QPS等資訊。
這部分沒有自研,而是直接接入了阿里雲的Node.js效能平臺。

當線上出現記憶體漏失時,就能通過下載的堆快照匯入Chrome中,以此來分析洩漏原因。
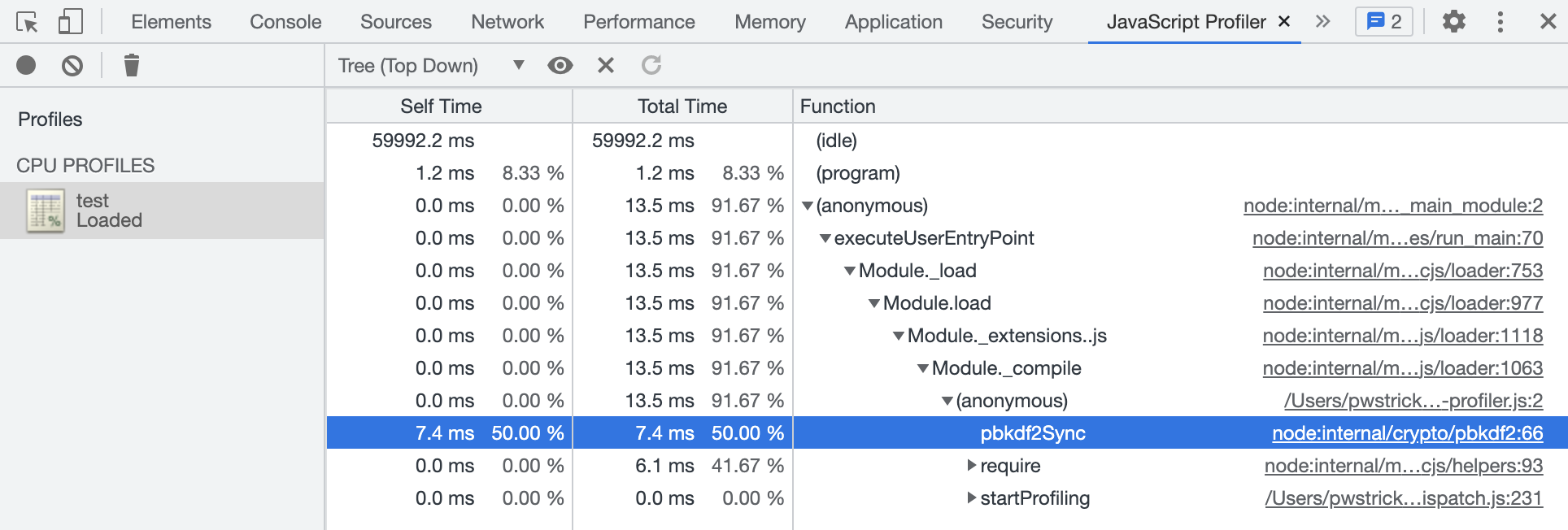
還引入了阿里雲的資料庫監控,可以實時看到慢查詢,並且還能智慧的給出優化建議,自動生成相關索引,效果可以說立竿見影。
3)監控大盤
監控大盤便於觀察核心指標的走向,包括慢響應,5XX介面數量、白屏和首屏各階段佔比等。
監控大盤也是為了能主動發現異常,而不是由使用者上報。
因為一旦發現曲線有異常情況,即迅速上升(例如下圖),那麼就需要抽調資源來排查是什麼問題導致的。
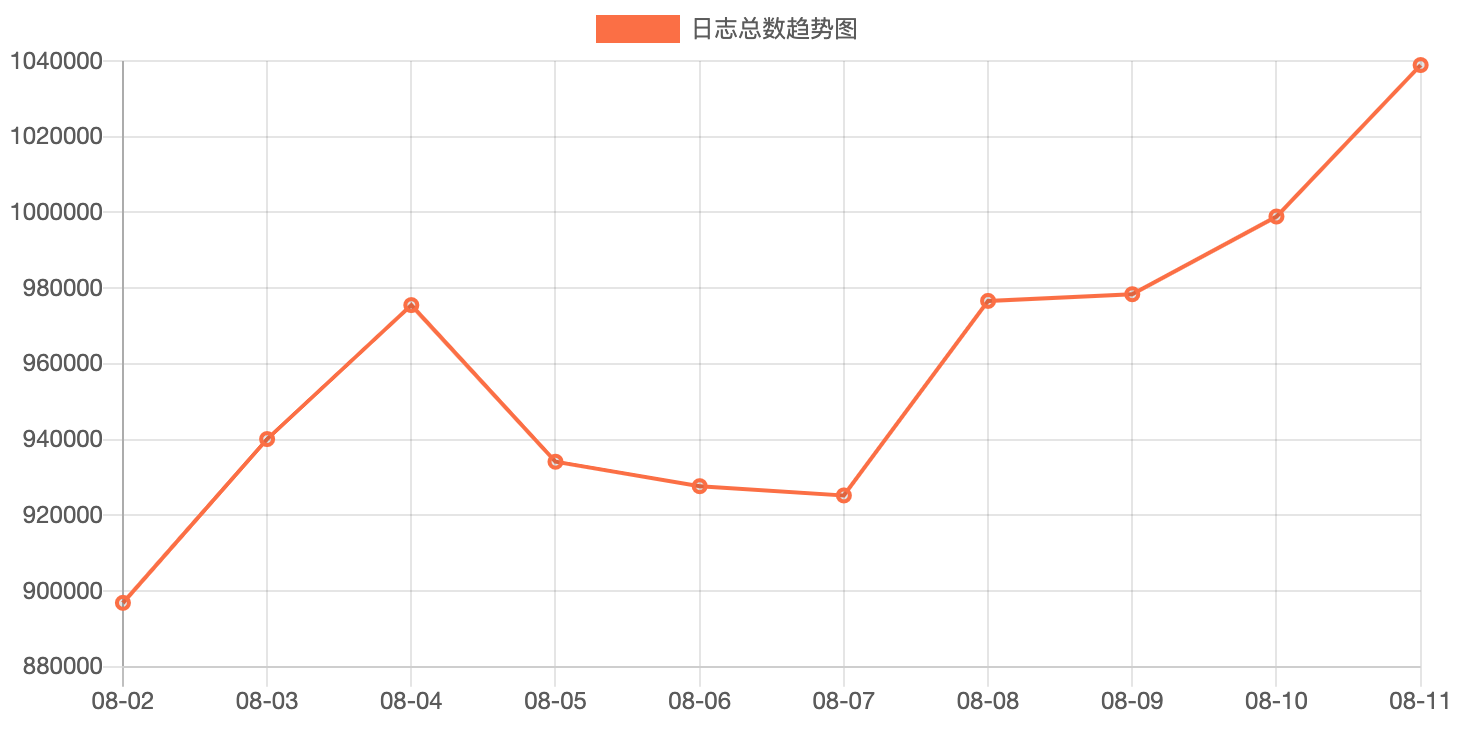
通過監控大盤,還可以發現一些使用者並不關注的問題,例如前端監控在接收比較大的資料時會報大量的500錯誤,還有一些比較隱蔽的邊界條件錯誤等。
這些錯誤並不會非常影響使用者體驗,所以一般也很少會上報到客服,只能通過主動監控來發現。
二、告警
告警也是為了能主動發現問題,及時處理,以免讓使用者感知,降低體驗。
告警主要還是針對後端用Node編寫的服務。
1)業務介面
業務介面就包括對外的H5網頁和對內的管理後臺所涉及的介面。
目前的規則是每分鐘5個以上5XX介面,就會自動在飛書中發訊息告警。
nginx狀態碼告警 - 所屬專案: k8s-log-xxxxxx - 告警名稱: 主站-5xx錯誤狀態碼 - 首次觸發: 2022-08-23 02:24:46 - 告警時間: 2022-08-23 02:24:46 - 告警狀態: 觸發 - 告警嚴重度: 中級 - 錯誤狀態碼: 500 - 紀錄檔詳細: { 'proxy_upstream_name': 'web-website', 'req_id': '92072872edf58909e3f8f2edce6bc5f0', 'status': '500', 'url': '/share/live/xxx.html' }
2)定時任務
定時任務與介面不同,所以不能套用之前的規則。
很多定時任務都是5分鐘執行一次,那如果報錯的話,也是5分鐘一次。
如果採用上面的規則,那麼將永遠無法收到告警。
所以改成每5分鐘有一次500的錯誤,就會發出告警。
三、事故
當線上出現問題時,需要提前準備好應急方案。
每一次線上事故,都是一次昂貴的付費學習機會,做好覆盤,以免重蹈覆轍。
1)留一手
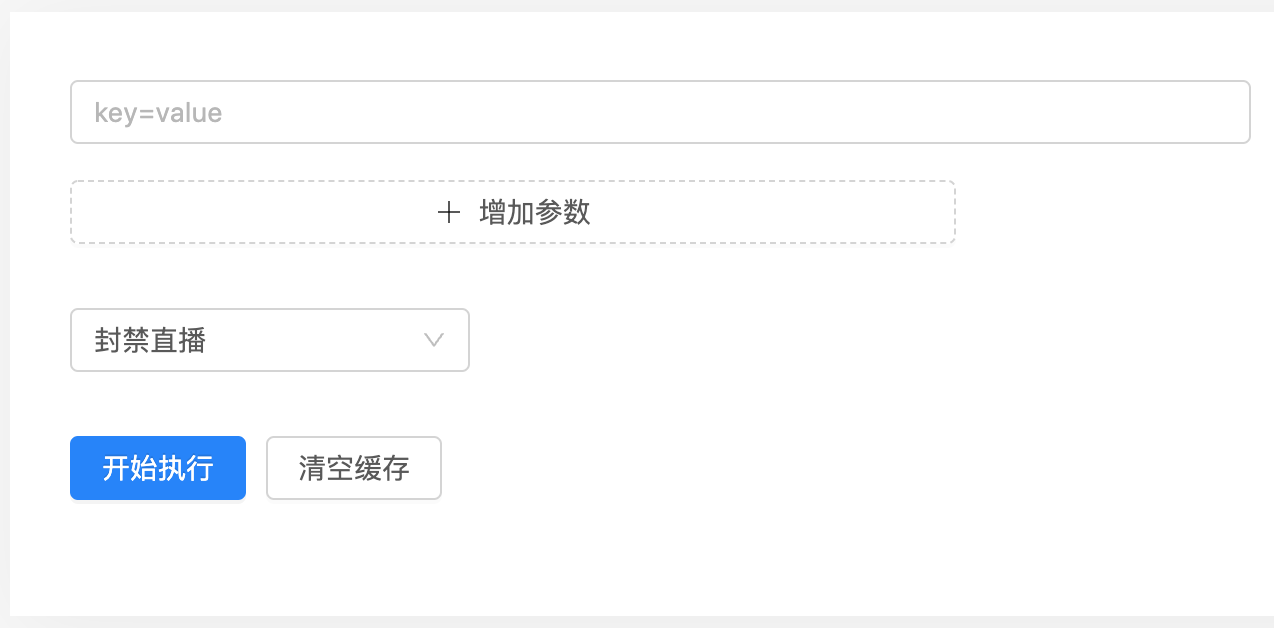
如果能預判線上可能出現的問題,那麼可以留一手,迅速響應。
例如在某一時刻榜單定時任務可能會執行失敗,那麼就預設個頁面,手動觸發。
頁面可以像下圖這樣,下拉框就是各類介面名稱,可自定義引數,按鈕請求介面。
2)責任人
公司內部有個技術問題對接大群,各類版本和H5需求還有單獨的群。
所以在將問題拋到群裡後,可相對比較快的找到責任人。
對於最近上線的業務,我們都會安排專門的人隨時待命解決問題。
在解決問題後,馬上預估影響面,並告知業務方。
3)做覆盤
覆盤有固定的格式,包括名稱、持續時間、影響範圍、經過、原因和解決方案。
寫好後發一封公司郵件,告知所有人這次事故的來龍去脈。
覆盤不是為了批鬥,而是為了更好的找出問題,更好的修復問題,不要再犯相同的錯誤。
有必要的話,還可以將所有相關人員拉上,組織一場會議。
大家各自發言,看看是否還有其他沒有注意到的問題,都丟擲來。
四、測試
公司有一個測試團隊,當大家研發完成後,後面的流程就會轉到他們那邊。
1)自行測試
測試團隊會出一份測試用例檔案,他們會給出部分需要自測的用例。
當自測完成後,再去發一封提測郵件,然後他們再接手。
之所以要自測,是因為在測試驗收時經常發生主流程都跑不通的情況。
還需要讓研發修改,這樣來來回回非常影響效率,所以才會要求自測。
2)單元測試
單元測試是我們組內部一直在推,但收效並不明顯。
好處毋庸置疑,之前專門做過分析。
上次升級Node環境版本時,因為一個服務沒有連線,導致一個介面報錯。
因為影響範圍很小,所以也沒有在第一時間收到反饋。
後面與運維溝通,發現可以線上上釋出的時候增加一個單元測試的流程。
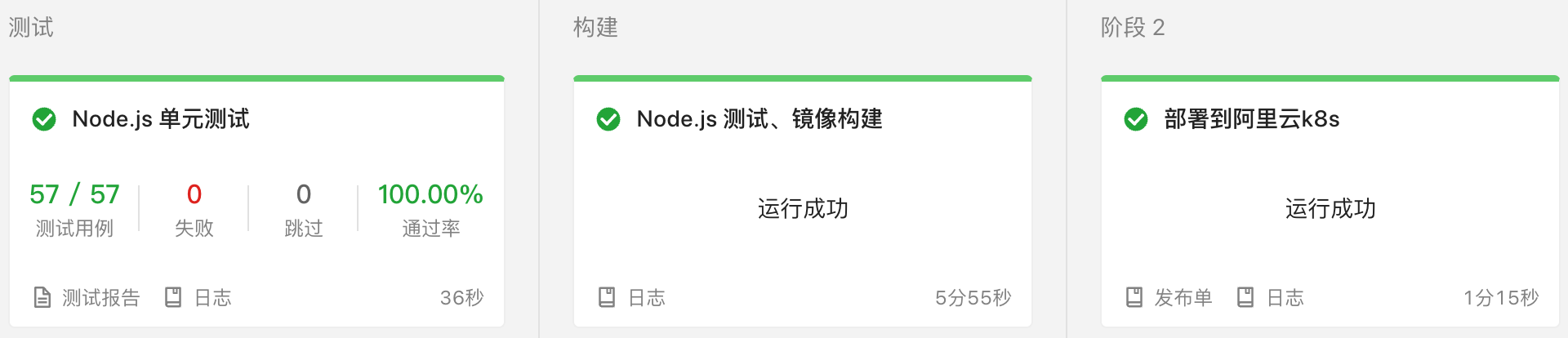
在單元測試中,寫一些程式碼驗證服務是否連通,若無法連通就斷言失敗,從而阻止後續的構建和部署。點選測試報告,還有專門的分析頁面可以檢視。
需要注意的是,在單元測試中不能在資料庫中增加資料,以免造成線上資料的混亂。
3)迴歸測試
測試組會在我們修改完BUG後,會做迴歸測試,不過目前是依賴人工迴歸。
測試組最近正在研發自動化的迴歸,有望以後也整合到程式碼釋出流程中。
對於一些有特殊要求的業務,測試組還會做壓力和效能測試。
五、工具
有句話叫能依靠工具就不要依賴流程,能建立流程就不要依賴人的主動性。
在我們團隊內部已經發布了共同作業流程、活動設定、Git分支管理等規範。
在制訂規範後,解決了很多問題,不過如果有工具加持,那麼工作效率可以提升的更高。
1)自研
根據公司業務和技術棧,我們組自研了很多工具。
榜單活動設定直接釋放了4個組的人力,從原先的3天開發時間,降低到了1小時,經過時間的沉澱,活動也能更穩定。
通用設定已服務於5個小組,大大降低了開發和測試成本,不用再為一個小需求大動干戈。
BFF平臺減少了介面的開發和偵錯成本,以及冗餘的增刪改查程式碼,加速與頁面的聯調。
依託VSCode開放的API,自研了一個外掛,可以選中某個方法,直接從路由層跳轉到服務層的宣告處,便於檢視原始碼邏輯。
2)第三方
有些工具還是需要第三方提供,我們或是直接使用,或是做一層封裝。
在研發過程中,我們會頻繁地將自己分支與測試分支合併,然後再手動釋出程式碼。
後面將合併與釋出自動關聯,合併後就自動去釋出程式碼,減少了枯燥的手動操作。
要存取公司的管理後臺需要進入內網,內網會限制IP,需要先將IP加入到白名單內,才能存取。
原先是運維手動新增,但是有點工作量,後面就根據阿里雲提供的介面,我們自行建立了一套管理介面。
後續增加、刪除和查詢都在此管理介面中操作,許可權也開放給了相關人員。
3)Code Review
Code Review的好處在有很多人分析過,不再贅述,團隊內部已舉辦十多場。
我們組會對比較重要且複雜的業務做Code Review,目的是為了發現研發人員沒有想到的問題。
當大家在看程式碼和理解其思路時,可以對寫法、邏輯提出自己的看法。
還可以避免在共同作業時才會發現的問題,儘早解決減少損失。
順便說下,為了提升技術氛圍,內部的技術分享也在持續推進中,已舉辦二十多場,成員輪流主講。