Flink基礎概念入門
Flink 概述
什麼是 Flink
Apache Apache Flink 是一個開源的流處理框架,應用於分散式、高效能、高可用的資料流應用程式。可以處理有限資料流和無限資料,即能夠處理有邊界和無邊界的資料流。無邊界的資料流就是真正意義上的流資料,所以 Flink 是支援流計算的。有邊界的資料流就是批資料,所以也支援批次處理的。不過 Flink 在流處理上的應用比在批次處理上的應用更加廣泛,統一批次處理和流處理也是 Flink 目標之一。Flink 可以部署在各種叢集環境,可以對各種大小規模的資料進行快速計算。
- 2010~2014Flink 起源於柏林理工大學的研究性專案 Stratosphere
- 2014 年該專案被捐贈給 Apache 軟體基金會
- 2014 年 12 月 Flink 一躍成為 Apache 軟體基金會的頂級專案之一
在德語中,Flink 一詞表示快速和靈巧,專案採用一隻松鼠的彩色圖案作為 logo,這不僅是因為松鼠具有快速和靈巧的特點,還因為柏林的松鼠有一種迷人的紅棕色,而 Flink 的松鼠 logo 擁有可愛的尾巴,尾巴的顏色與 Apache 軟體基金會的 logo 顏色相呼應,也就是說,這是一隻 Apache 風格的松鼠

Flink 的特點
Flink 有如下特點:
- 批流一體:統一批次處理和流處理
- 分散式:Flink 程式可以執行在分散式環境下
- 高效能
- 高可用
- 準確性:Flink 可以保證資料處理的準確性
Flink 應用場景
Flink 主要應用於流式資料分析場景
- 實時 ETL
Extraction-Transformation-Loading 的縮寫,中文名稱為資料抽取、轉換和載入.
整合流計算現有的諸多資料通道和 SQL 靈活的加工能力,對流式資料進行實時清晰、歸併和結構化處理;同時,對離線數倉進行有效的補充和優化,併為資料實時傳輸提供可計算通道。
- 實時報表
實時化採集,加工流式資料儲存;實時監控和展現業務、客戶各類指標,讓資料化運營實時化。
- 監控預警
對系統和使用者行為進行實時監測和分析,以便及時發現危險行為。
- 線上系統
實時計算各類資料指標,並利用實時結果及時調整線上系統的相關策略,並應用於內容投放、智慧推播領域。
Flink 核心組成及生態發展

Flink 核心組成
- Deploy 層:
Flink 支援本地執行、能在獨立叢集或者在被 YARN 或 Mesos 管理的叢集上執行,也能部署在雲上 - Core 層:
Flink 的核心是分散式流式資料引擎,意味著資料以一次一個事件的形式被處理 - API 層:
DataStream、DataSet、Table、SQL API - 擴充套件庫:Flink 還包括了用於複雜事件處理、機器學習、影象處理和 Apache Storm 相容的專用程式碼庫
Flink 生態發展
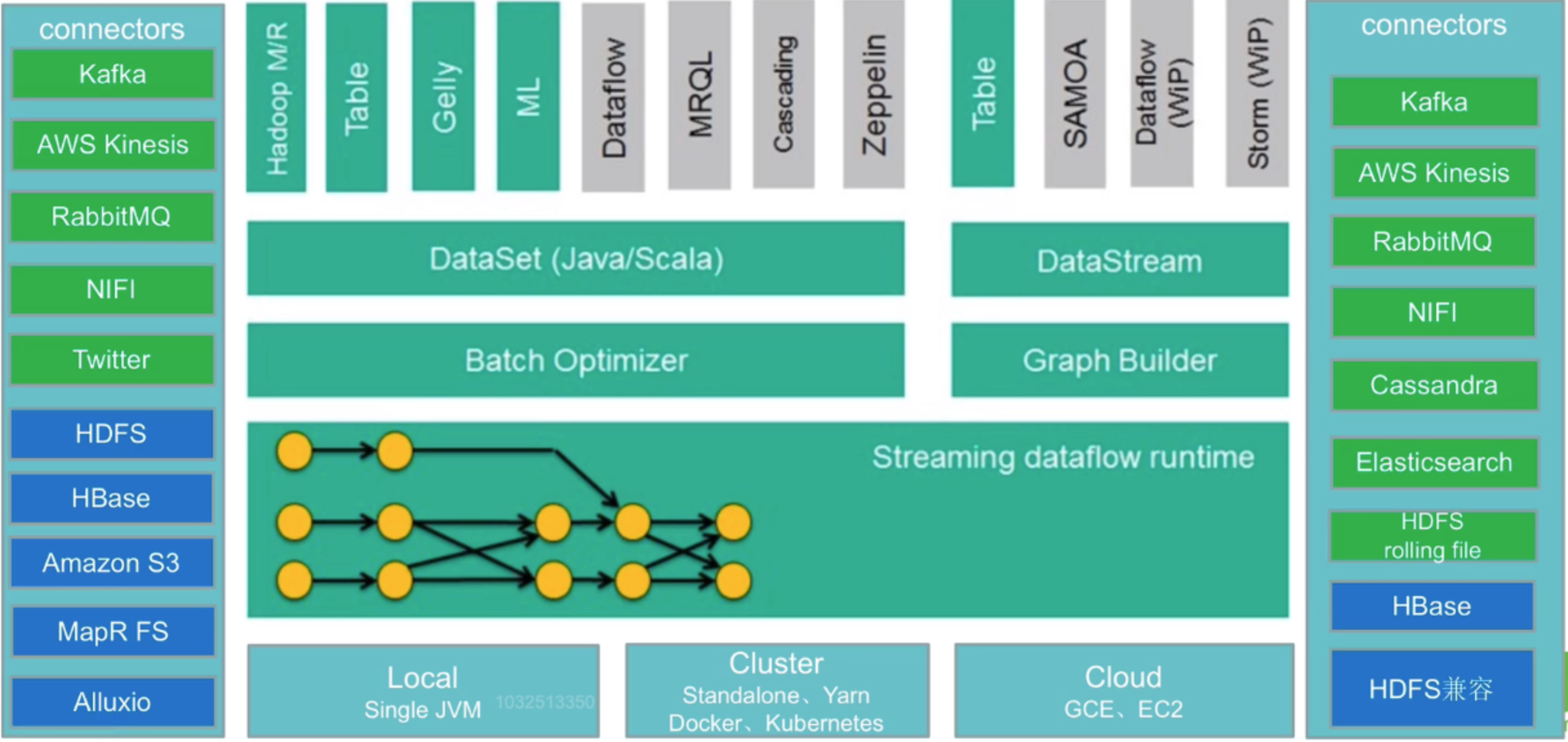
-
輸入 Connectors(左側部分)
-
流處理方式:包含 Kafka、AWS kinesis(實時資料流服務)、RabbitMQ、NIFI(資料管道)、Twitter(API)
-
批次處理方式:包含 HDFS、HBase、Amazon S3(檔案系統)、MapR FS(檔案系統)、ALLuxio(基於記憶體的分散式檔案系統)
-
-
中間是 Flink 核心部分
-
輸出 Connectors(右側部分)
-
流處理方式:包含 Kafka、AWS kinesis(實時資料流服務)、RabbitMQ、NIFI(資料管道)、Cassandra(NoSQL 資料庫)、ES、HDFS rolling file(捲動檔案)
-
批次處理方式:包含 HBase、HDFS
-
流處理引擎的技術選型
計算框架對比圖:
| 產品 | 模型 | API | 保證次數 | 容錯機制 | 狀態管理 | 延時 | 吞吐量 |
|---|---|---|---|---|---|---|---|
| storm | Native(資料進入立即處理) | 組合式 | At-least-once | Record ACKS | 無 | Low | Low |
| Trident | mirco-batching(劃分為小批次處理) | 組合式 | Exectly-once | Record ACKs | 基於操作(每次操作由一個狀態) | Medium | Medium |
| Spark streaming | mirco-batching | 宣告式(提供封裝後的高階函數) | Exectly-once | RDD Checkpoint | 基於 DStream | Medium | High |
| Flink | Native | 宣告式 | Exectly-once | Checkpoint | 基於操作 | Low | Hign |
市面上的流處理引擎不止 Flink 一種,其他的比如 Storm、SparkStreaming、Trident 等,如何進行選型,給大家一些建議:
- 流資料要進行狀態管理,選擇使用 Trident、Spark Streaming 或者 Flink
- 訊息傳遞需要保證 At-least-once(至少一次)或者 Exacly-once(僅一次)不能選擇 Storm
- 對於小型獨立專案,有低延遲要求,可以選擇使用 Storm,更簡單
- 如果專案已經引入了 Spark,實時處理需求可以滿足的話,建議直接使用 Spark 中的 Spark Streaming
- 訊息投遞要滿足 Exactly-once(僅一次),資料量大、有高吞吐、低延遲要求,要進行狀態管理或視窗統計,建議使用 Flink