前言:
網上很多的文章都建議在使用IK分詞器的時候,建立索引的時候使用ik_max_word模式;搜尋的時候使用ik_smart模式。理由是max_word模式分詞的結果會包含smart分詞的結果,這樣操作會使得搜尋的結果很全面。
但在實際的應用中,我們會發現,有些時候,max_word模式的分詞結果並不能夠包含smart模式下的分詞結果。
下面,我們就看一個簡單的測試範例:
假設我們現在要分別在max_word模式和smart模式下搜尋「2022年」,搜尋結果如下表所示:
|
max_word模式
|
0 - 4 : 2022 | ARABIC
4 - 5 : 年 | COUNT
|
|
smart模式
|
0 - 5 : 2022年 | TYPE_CQUAN
|
我們會發現max_word模式下的分詞結果並沒有覆蓋smart模式下的分詞結果。這是什麼原因導致的呢?
下面,我們通過分析IK分詞器的處理流程來尋找答案。
IK分詞器實現原理剖析
IKAnalyzer中包含3個子分詞器
|
LetterSegmenter
|
處理英文字母和阿拉伯數位的分詞器
|
|
CN_QuantifierSegmenter
|
處理中文數量詞的分詞器
|
|
CJKSegmenter
|
處理中文和日韓字元的分詞器
|
下面我們看下這三個子分詞器分別是如何工作的。
英文字元及阿拉伯數位子分詞器
假設我們現在對「111aaa222bbb」這個字串在max_word模式下進行分詞處理,其分詞的處理結果如下所示:
0 - 12 : 111aaa222bbb | LETTER
0 - 3 : 111 | ARABIC
3 - 6 : aaa | ENGLISH
6 - 9 : 222 | ARABIC
9 - 12 : bbb | ENGLISH
上面的第一列代表的是詞元的起始位移和偏移量,中間列是詞元字元資訊,第三列是詞元屬性。
現在我們將上面的字串做一些改變,對字串「111aaa@222bbb」進行分詞處理,我們會發現其分詞結果如下所示:
0 - 13 : 111aa@a222bbb | LETTER
0 - 3 : 111 | ARABIC
3 - 5 : aa | ENGLISH
6 - 7 : a | ENGLISH
7 - 10 : 222 | ARABIC
10 - 13 : bbb | ENGLISH
現在我們再將上面的字串做一些修改,變成「111aaa 222bbb」,那麼我們會得到如下的分詞結果:
0 - 6 : 111aaa | LETTER
0 - 3 : 111 | ARABIC
3 - 6 : aaa | ENGLISH
7 - 13 : 222bbb | LETTER
7 - 10 : 222 | ARABIC
10 - 13 : bbb | ENGLISH
上面的三個字串除了中間的字元外其他地方是一樣的,但是得到的分詞結果卻是有很多相同。
從分詞結果中,我們可以看到LetterSegmenter會拆分出三種詞性的詞元,分別是LETTER(數位英文混合),ARABIC(數位),ENGLISH(英文)。這三種不同的詞元屬性分別對應了三種不同的處理流程。
細心的同學可能還會有一個疑問,字串"111aaa@222bbb"與字串"111aaa 222bbb"解析出來的混合詞元不一樣。這是因為@字元是英文字元的連結符號,但空格並不是。
中文數量詞子分詞器
主要分為數詞處理流程和量詞處理流程兩部分組成,處理流程比較簡單,這裡不再進行詳細敘述。
中文-日韓文子分詞器
主要是根據處理詞典中的詞庫進行分詞處理,那麼如果我們要處理的詞語在詞庫中並不存在的話,會出現什麼情況呢?
因為IK分詞是一個基於詞典的分詞器,只有包含在詞典的詞才能被正確切分,IK解決分詞歧義只是根據幾條最佳的分詞實踐規則,並沒有用到任何概率模型,也不具有新詞發現的功能。
因此,如果我們要處理的文字在詞庫中不存在的時候,就會被切分成單個字元的模式。
分詞歧義裁決器
我們嘗試一下在smart模式下對"111aaa 222bbb"進行分詞處理,我們會得到如下的分詞結果:
0 - 6 : 111aaa | LETTER
7 - 13 : 222bbb | LETTER
那麼為什麼smart模式下的分詞結果會和max_word模式下的分詞結果不同呢?通過閱讀IK分詞器的原始碼,我們會發現IK分詞器下的smart模式主要是通過IKArbitrator這個類來實現的。
這個類是分詞結果的歧義處理類。在瞭解IKArbitrator這個類的處理流程之前,我們需要先了解兩個資料結構,Lexeme,QuickSortSet和LexemePath。
Lexeme是分詞器中解析出來的詞元結果,其主要的欄位包括:
// 詞元的起始位移
private int offset;
// 詞元的相對起始位置
private int begin;
// 詞元的長度
private int length;
// 詞元文字
private String lexemeText;
// 詞元型別
private int lexemeType;
QuickSortSet是IK分詞器中用來對詞元進行排序的集合。其中的排序規則是詞元相對起始位置小的優先;相對起始位置相同的情況下,詞元長度大的優先。
LexemePath繼承了QuickSortSet,其代表的是詞元鏈。在IK分詞器的smart模式下,會出現多個詞元鏈的候選集。
那麼,我們怎麼選擇最優的詞元鏈呢?選擇的關鍵就在LexemePath的compareTo方法中。
public int compareTo(LexemePath o) {
// 比較有效文字長度
if (this.payloadLength > o.payloadLength) {
return -1;
} else if (this.payloadLength < o.payloadLength) {
return 1;
} else {
// 比較詞元個數,越少越好
if (this.size() < o.size()) {
return -1;
} else if (this.size() > o.size()) {
return 1;
} else {
// 路徑跨度越大越好
if (this.getPathLength() > o.getPathLength()) {
return -1;
} else if (this.getPathLength() < o.getPathLength()) {
return 1;
} else {
// 根據統計學結論,逆向切分概率高於正向切分,因此位置越靠後的優先
if (this.pathEnd > o.pathEnd) {
return -1;
} else if (pathEnd < o.pathEnd) {
return 1;
} else {
// 詞長越平均越好
if (this.getXWeight() > o.getXWeight()) {
return -1;
} else if (this.getXWeight() < o.getXWeight()) {
return 1;
} else {
// 詞元位置權重比較
if (this.getPWeight() > o.getPWeight()) {
return -1;
} else if (this.getPWeight() < o.getPWeight()) {
return 1;
}
}
}
}
}
}
return 0;
}
接下來,我們看看IK分詞器是如何選擇出最優詞元鏈的?其主要處理流程如下:
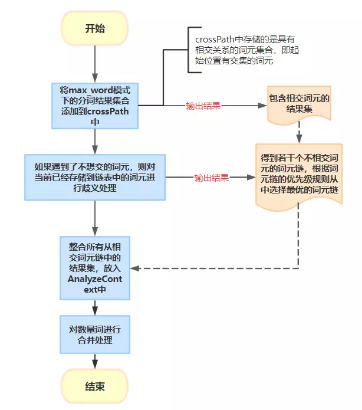
總結:
現在回到前言部分中我們提及的問題,經過我們對IK分詞器處理流程地分析,我們很容易得到答案。
這是因為2022是數詞,而年是量詞。在max_word模式下,數詞和量詞不會進行合併處理。但是在smart模式下,數詞和量詞會進行合併處理。
通過閱讀IK分詞器的原始碼,我們會發現它並沒有採用任何先進的演演算法模型,但是該分詞器依然被廣泛地被使用。
IK分詞器被廣泛使用,從某種意義上說明,很多真實的應用場景,並不需要使用那些先進而複雜的深度學習演演算法模型。低成本的淺層特徵模型也仍然可以達到十分具有競爭力的準確率和召回率。
加入技術交流群,請掃描下方二維條碼。
