Bert不完全手冊8. 預訓練不要停!Continue Pretraining
- paper: Don't stop Pretraining: Adapt Language Models to Domains and Tasks
- GitHub: https://github.com/allenai/dont-stop-pretraining
論文針對預訓練語料和領域分佈,以及任務分佈之間的差異,提出了DAPT領域適應預訓練(domain-adaptive pretraining)和TAPT任務適應預訓練(task-adaptive pretraining)兩種繼續預訓練方案,並在醫學論文,計算機論文,新聞和商品評價4個領域上進行了測試。想法很簡單就是在垂直領域上使用領域語料做繼續預訓練,不過算是開啟了新的訓練正規化,從之前的pretrain+fintune,到pretrain+continue pretrain+finetune
核心要點主要有以下4個
- 和預訓練差異越大的領域,領域適應繼續預訓練的效果提升越顯著
- 任務適應預訓練輕量好使,效果也不差
- 領域預訓練+任務預訓練效果最好,不過成本較高
- 通過KNN擴充套件任務語料,能逼近領域預訓練的效果
DAPT
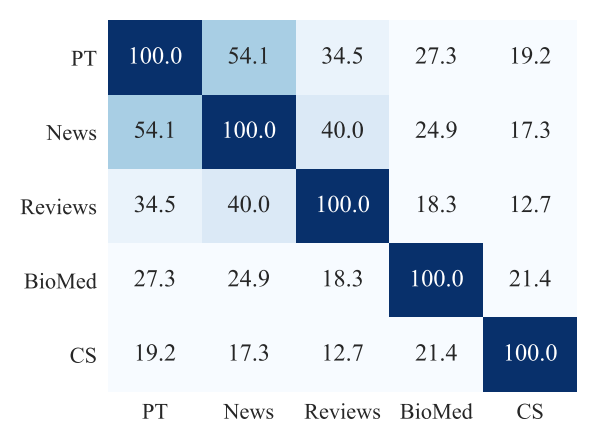
首先作者通過每個領域內的Top10K高頻詞的重合度,來衡量領域之間,以及領域和預訓練語料的文字相似度,相似度News>Reviews>Bio>CS。我們預期DAPT的效果會和相似度相關,理論上在相似度低的領域,繼續預訓練應該帶來更大的提升。
訓練部分作者複用了Roberta的預訓練方案。為了保證4個領域可比,作者通過樣本取樣,以及不同的batch size保證了4個領域的step相同。為了防止災難遺忘,作者只在領域資料上繼續訓練了1個epoch(12.5K steps)。除了News領域,其他領域的繼續預訓練都帶來了MLM Loss的下降。
在下游分類任務微調中,繼續訓練的模型效果都顯著優於原始Roberta,和預訓練語料差異更大的領域CS,Bio整體的效果提升更顯著,如下

為了剔除更多的訓練樣本可能帶來的效果提升,作者按以上的語料相關性,每個領域都選擇了相關性最低的另一個領域的繼續預訓練模型(¬DAPT),對比在下游微調中的效果,部分場景有提升部分有下降,但是都顯著低於對應領域的繼續預訓練模型,從而進一步證明繼續預訓練的收益來自對應領域資訊的補充。
TAPT
TAPT是使用任務樣本直接進行繼續訓練。Task Adaptive和Domain Adaptive的主要區別是,Task對應的資料集更小訓練成本更低,不過因為直接使用任務資料,所以和任務的相關度更高。對應以上DAPT訓練1個epoch(12.5K steps), TAPT訓練100個epoch,每個epochs使用15%的Random Delete來進行樣本增強。
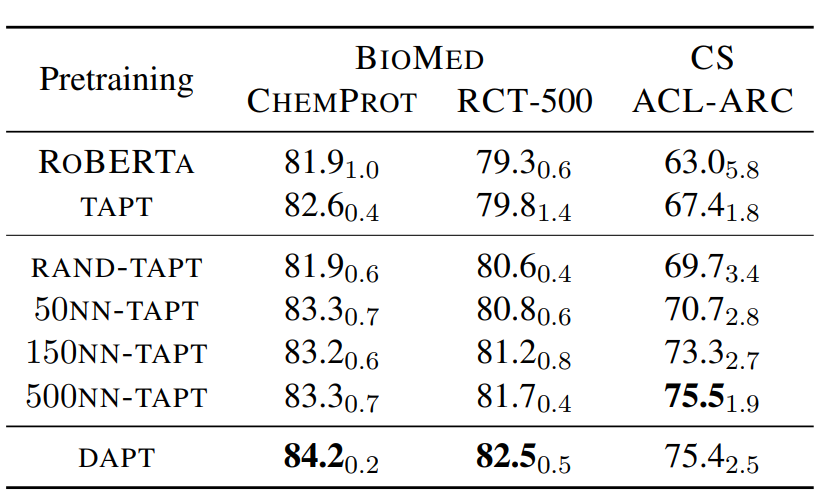
作者對比了只使用DAPT,TAPT以及先使用DAPT+TAPT的效果:整體上DAPT+TAPT的繼續預訓練效果最好。其中針對更加垂直(和預訓練語料相關性更小)的領域DAPT更好。感覺主要是因為領域垂直,TAPT受限於樣本量能提供的領域資訊不足,容易過擬和。而和預訓練語料更相似的新聞領域和評論領域,TAPT的效果甚至超過DAPT,如下

作者進一步嘗試了Cross Task Transfer,就是使用相同領域中任務1做繼續預訓練,然後在任務2上進行微調。效果顯著低於使用相同任務的語料做T繼續訓練,這進一步說明了相同領域不同任務間的語料分佈也是存在差異的,所以在部分任務上TAPT的效果要優於DAPT。
那能否在保留當前任務分佈的前提下,拓展任務相關語料,解決TAPT樣本量不足的問題呢?比較直觀的方案就是使用文字Embedding,從相同領域的樣本中,使用KNN抽取任務對應的K個相似樣本來擴充任務樣本。作者使用的是詞袋模型VAMPIRE來計算文字表徵,對比了不同引數K的效果,500KNN已經逼近DAPT。如果你有耐心>_<的話,KNN配合TAPT確實算是更優的方案,它的預訓練成本顯著低於DAPT,但又比TAPT的效果以及泛化性要顯著更好
領域差異
說了半天繼續預訓練可以提高下游任務的效果,不過究竟繼續預訓練幹了啥??這部分在作者也沒有很詳細的證明,所以我們只能藉助相關paper來猜想一哈~
- 領域詞彙/實體/ngram差異: 垂直領域和通用領域的主要差異在專屬實體和短語,也就是領域知識資訊。繼續預訓練可以提供這部分的補充資訊。不過這其實也challenge了論文複用Roberta的預訓練方案並一定是最優方案,可能SpanBert或者ERNIE,甚至K-Bert對應的知識增強,實體掩碼方案更合適
- 整體語料差異: 除知識之外,常規的文字表達和上下文語境也存在整體差異,可以通過繼續與訓練來進行調整。
- 優化空間分佈,提高線性可分性:在之前探測Bert Finetune對向量空間的影響中我們討論過,微調其實是對預訓練文字表徵的空間分佈進行了調整,使得在下游任務中空間分佈更簡單更加線性可分,這裡猜測繼續預訓練其實也起到了類似的效果。
- 提高模型泛化:在下游任務微調中,模型往往只更新/依賴任務相關的區域性資訊,而繼續預訓練目標的設定使得模型能更全面的學習領域/任務相關的上下文知識,一定程度上提高模型的泛化能力,起到更優的bayesian prior的作用
案例
總結下,針對單任務模型,直接使用TAPT成本最低實用性最高,針對領域底層大模型,使用DAPT效果更好。不過使用起來具體使用哪種預訓練方案,以及如何避免災難遺忘,感覺還是要case by case的來看。一些相關的案例有
- 金融負面主體識別比賽:Rank3的方案就嘗試了在任務語料上繼續預訓練,並且配合實體掩碼相關的預訓練方案來提升模型效果。
- 疫情期間民情識別比賽: 作者用比賽資料提供的任務樣本,以及任務樣本相關的未標註樣本進行做curated tapt,平均準確率有1個點左右的提升
- 淘寶UGC情感分類:評論底層大模型,使用評論領域語料來繼續預訓練,用於上層的子任務
最近在復現一些比賽方案時,嘗試了下在金融負面主體這個任務中引入TAPT,因為是實體相關的情感分類問題,因此在TAPT上使用了Whole Word和Entity粒度結合的MLM作為預訓練目標。在使用多工的基礎上,使用TAPT進一步訓練後F1進一步有0.2%個點的提升,不過這個提升只有當預訓練使用全部語料的時候才顯著,如果和下游微調一樣保留部分資料用於測試,則不會有顯著的效果提升,這裡的效果對比更支援上面的提高模型泛化能力這個假設~具體實現詳見ClassicSolution/fin_neg_entity