TDengine概述以及架構模型
TDengine
TDengine是一個高效的儲存、查詢、分析時序巨量資料的平臺,專為物聯網、車聯網、工業網際網路、運維監測等優化而設計。
您可以像使用關係型資料庫MySQL一樣來使用它。
TDengine介紹
TDengine是濤思資料面對高速增長的物聯網巨量資料市場和技術挑戰推出的創新性的巨量資料處理產品,它不依賴任何第三方軟體,也不是優化或包裝了一個開源的資料庫或流式計算產品,而是在吸取眾多傳統關係型資料庫、NoSQL資料庫、流式計算引擎、訊息佇列等軟體的優點之後自主開發的產品,在時序空間巨量資料處理上,有著自己獨到的優勢。TDengine的模組之一是時序資料庫。但除此之外,為減少研發的複雜度、系統維護的難度,TDengine還提供快取、訊息佇列、訂閱、流式計算等功能,為物聯網、工業網際網路巨量資料的處理提供全棧的技術方案,是一個高效易用的物聯網巨量資料平臺。與Hadoop等典型的巨量資料平臺相比,它具有如下鮮明的特點:
- 10倍以上的效能提升:定義了創新的資料儲存結構,單核每秒能處理至少2萬次請求,插入數百萬個資料點,讀出一千萬以上資料點,比現有通用資料庫快十倍以上。
- 硬體或雲服務成本降至1/5:由於超強效能,計算資源不到通用巨量資料方案的1/5;通過列式儲存和先進的壓縮演演算法,儲存空間不到通用資料庫的1/10。
- 全棧時序資料處理引擎:將資料庫、訊息佇列、快取、流式計算等功能融為一體,應用無需再整合Kafka/Redis/HBase/Spark/HDFS等軟體,大幅降低應用開發和維護的複雜度成本。
- 強大的分析功能:無論是十年前還是一秒鐘前的資料,指定時間範圍即可查詢。資料可在時間軸上或多個裝置上進行聚合。即席查詢可通過Shell, Python, R, Matlab隨時進行。
- 與第三方工具無縫連線:不用一行程式碼,即可與Telegraf, Grafana, EMQ, HiveMQ, Prometheus, Matlab, R等整合。後續將支援OPC, Hadoop, Spark等, BI工具也將無縫連線。
- 零運維成本、零學習成本:安裝叢集簡單快捷,無需分庫分表,實時備份。類似標準SQL,支援RESTful, 支援Python/Java/C/C++/C#/Go/Node.js, 與MySQL相似,零學習成本。
採用TDengine,可將典型的物聯網、車聯網、工業網際網路巨量資料平臺的總擁有成本大幅降低。但需要指出的是,因充分利用了物聯網時序資料的特點,它無法用來處理網路爬蟲、微博、微信、電商、ERP、CRM等通用型資料。
資料模型和整體架構
資料模型
在典型的物聯網、車聯網、運維監測場景中,往往有多種不同型別的資料採集裝置,採集一個到多個不同的物理量。而同一種採集裝置型別,往往又有多個具體的採集裝置分佈在不同的地點。巨量資料處理系統就是要將各種採集的資料彙總,然後進行計算和分析。對於同一類裝置,其採集的資料都是很規則的。
以智慧電錶為例,假設每個智慧電錶採集電流、電壓、相位三個量,其採集的資料類似如下的表格:
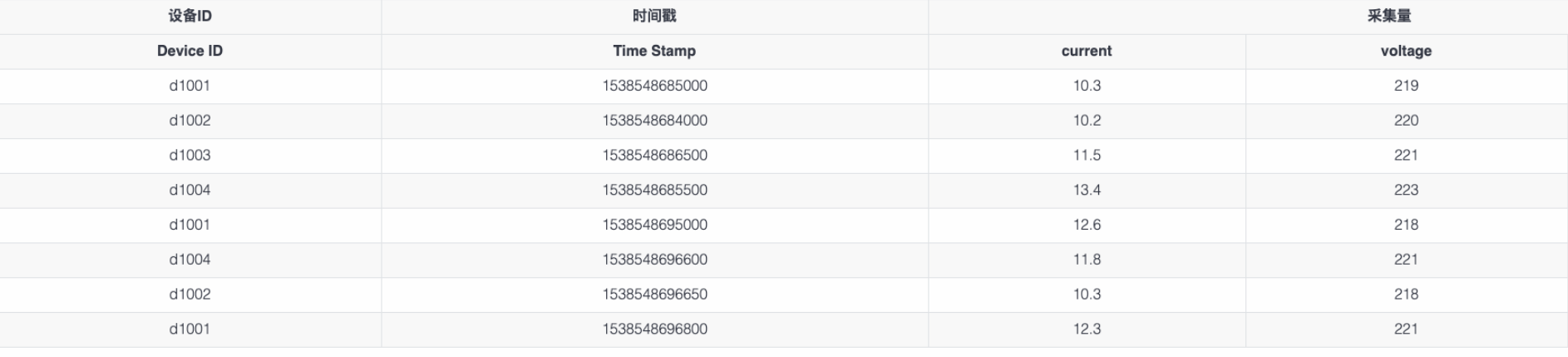
每一條記錄都有裝置ID,時間戳,採集的物理量(如上圖中的電流、電壓、相位),還有與每個裝置相關的靜態標籤(如上述表一中的位置Location和分組groupId)。每個裝置是受外界的觸發,或按照設定的週期採集資料。採集的資料點是時序的,是一個資料流。
關係型資料庫模型
因為採集的資料一般是結構化資料,同時為降低學習門檻,TDengine採用傳統的關係型資料庫模型管理資料。因此使用者需要先建立庫,然後建立表,之後才能插入或查詢資料。TDengine採用的是結構化儲存,而不是NoSQL的key-value儲存。
一個資料採集點一張表
為充分利用其資料的時序性和其他資料特點,TDengine要求對每個資料採集點單獨建表(比如有一千萬個智慧電錶,就需建立一千萬張表,上述表格中的d1001, d1002, d1003, d1004都需單獨建表),用來儲存這個採集點所採集的時序資料。這種設計有幾大優點:
- 能保證一個採集點的資料在儲存媒介上是以塊為單位連續儲存的。如果讀取一個時間段的資料,它能大幅減少隨機讀取操作,成數量級的提升讀取和查詢速度。
- 由於不同採集裝置產生資料的過程完全獨立,每個裝置的資料來源是唯一的,一張表也就只有一個寫入者,這樣就可採用無鎖方式來寫,寫入速度就能大幅提升。
- 對於一個資料採集點而言,其產生的資料是時序的,因此寫的操作可用追加的方式實現,進一步大幅提高資料寫入速度。
如果採用傳統的方式,將多個裝置的資料寫入一張表,由於網路延時不可控,不同裝置的資料到達伺服器的時序是無法保證的,寫入操作是要有鎖保護的,而且一個裝置的資料是難以保證連續儲存在一起的。採用一個資料採集點一張表的方式,能最大程度的保證單個資料採集點的插入和查詢的效能是最優的。
TDengine 建議用資料採集點的名字(如上表中的D1001)來做表名。每個資料採集點可能同時採集多個物理量(如上表中的curent, voltage, phase),每個物理量對應一張表中的一列,資料型別可以是整型、浮點型、字串等。除此之外,表的第一列必須是時間戳,即資料型別為 timestamp。對採集的資料,TDengine將自動按照時間戳建立索引,但對採集的物理量不建任何索引。資料用列式儲存方式儲存。
超級表:同一型別資料採集點的集合
由於一個資料採集點一張表,導致表的數量巨增,難以管理,而且應用經常需要做採集點之間的聚合操作,聚合的操作也變得複雜起來。為解決這個問題,TDengine引入超級表(Super Table,簡稱為STable)的概念。
超級表是指某一特定型別的資料採集點的集合。同一型別的資料採集點,其表的結構是完全一樣的,但每個表(資料採集點)的靜態屬性(標籤)是不一樣的。描述一個超級表(某一特定型別的資料採集點的結合),除需要定義採集量的表結構之外,還需要定義其標籤的schema,標籤的資料型別可以是整數、浮點數、字串,標籤可以有多個,可以事後增加、刪除或修改。 如果整個系統有N個不同型別的資料採集點,就需要建立N個超級表。
在TDengine的設計裡,表用來代表一個具體的資料採集點,超級表用來代表一組相同型別的資料採集點集合。當為某個具體資料採集點建立表時,使用者使用超級表的定義做模板,同時指定該具體採集點(表)的標籤值。與傳統的關係型資料庫相比,表(一個資料採集點)是帶有靜態標籤的,而且這些標籤可以事後增加、刪除、修改。一張超級表包含有多張表,這些表具有相同的時序資料schema,但帶有不同的標籤值。
當對多個具有相同資料型別的資料採集點進行聚合操作時,TDengine會先把滿足標籤過濾條件的表從超級表中找出來,然後再掃描這些表的時序資料,進行聚合操作,這樣需要掃描的資料集會大幅減少,從而顯著提高聚合計算的效能。
叢集與基本邏輯單元
TDengine 的設計是基於單個硬體、軟體系統不可靠,基於任何單臺計算機都無法提供足夠計算能力和儲存能力處理海量資料的假設進行設計的。因此 TDengine 從研發的第一天起,就按照分散式高可靠架構進行設計,是支援水平擴充套件的,這樣任何單臺或多臺伺服器發生硬體故障或軟體錯誤都不影響系統的可用性和可靠性。同時,通過節點虛擬化並輔以自動化負載均衡技術,TDengine 能最高效率地利用異構叢集中的計算和儲存資源降低硬體投資。
主要邏輯單元
TDengine 分散式架構的邏輯結構圖如下:
一個完整的 TDengine 系統是執行在一到多個物理節點上的,邏輯上,它包含資料節點(dnode)、TDengine應用驅動(taosc)以及應用(app)。系統中存在一到多個資料節點,這些資料節點組成一個叢集(cluster)。應用通過taosc的API與TDengine叢集進行互動。下面對每個邏輯單元進行簡要介紹。
物理節點(pnode): pnode是一獨立執行、擁有自己的計算、儲存和網路能力的計算機,可以是安裝有OS的物理機、虛擬機器器或Docker容器。物理節點由其設定的 FQDN(Fully Qualified Domain Name)來標識。資料節點(dnode): dnode 是 TDengine 伺服器側執行程式碼 taosd 在物理節點上的一個執行範例,一個工作的系統必須有至少一個資料節點。dnode包含零到多個邏輯的虛擬節點(VNODE),零或者至多一個邏輯的管理節點(mnode)。dnode在系統中的唯一標識由範例的End Point (EP )決定。EP是dnode所在物理節點的FQDN (Fully Qualified Domain Name)和系統所設定的網路埠號(Port)的組合。通過設定不同的埠,一個物理節點(一臺物理機、虛擬機器器或容器)可以執行多個範例,或有多個資料節點。
虛擬節點(vnode): 為更好的支援資料分片、負載均衡,防止資料過熱或傾斜,資料節點被虛擬化成多個虛擬節點(vnode,圖中V2, V3, V4等)。每個 vnode 都是一個相對獨立的工作單元,是時序資料儲存的基本單元,具有獨立的執行執行緒、記憶體空間與持久化儲存的路徑。一個 vnode 包含一定數量的表(資料採集點)。當建立一張新表時,系統會檢查是否需要建立新的 vnode。一個資料節點上能建立的 vnode 的數量取決於該資料節點所在物理節點的硬體資源。一個 vnode 只屬於一個DB,但一個DB可以有多個 vnode。一個 vnode 除儲存的時序資料外,也儲存有所包含的表的schema、標籤值等。一個虛擬節點由所屬的資料節點的EP,以及所屬的VGroup ID在系統內唯一標識,由管理節點建立並管理。
管理節點(mnode): 一個虛擬的邏輯單元,負責所有資料節點執行狀態的監控和維護,以及節點之間的負載均衡(圖中M)。同時,管理節點也負責後設資料(包括使用者、資料庫、表、靜態標籤等)的儲存和管理,因此也稱為 Meta Node。TDengine 叢集中可設定多個(開源版最多不超過3個) mnode,它們自動構建成為一個虛擬管理節點組(圖中M0, M1, M2)。mnode 間採用 master/slave 的機制進行管理,而且採取強一致方式進行資料同步, 任何資料更新操作只能在 Master 上進行。mnode 叢集的建立由系統自動完成,無需人工干預。每個dnode上至多有一個mnode,由所屬的資料節點的EP來唯一標識。每個dnode通過內部訊息互動自動獲取整個叢集中所有 mnode 所在的 dnode 的EP。
虛擬節點組(VGroup): 不同資料節點上的 vnode 可以組成一個虛擬節點組(vnode group)來保證系統的高可靠。虛擬節點組內採取master/slave的方式進行管理。寫操作只能在 master vnode 上進行,系統採用非同步複製的方式將資料同步到 slave vnode,這樣確保了一份資料在多個物理節點上有拷貝。一個 vgroup 裡虛擬節點個數就是資料的副本數。如果一個DB的副本數為N,系統必須有至少N個資料節點。副本數在建立DB時通過引數 replica 可以指定,預設為1。使用 TDengine 的多副本特性,可以不再需要昂貴的磁碟陣列等儲存裝置,就可以獲得同樣的資料高可靠性。虛擬節點組由管理節點建立、管理,並且由管理節點分配一個系統唯一的ID,VGroup ID。如果兩個虛擬節點的vnode group ID相同,說明他們屬於同一個組,資料互為備份。虛擬節點組裡虛擬節點的個數是可以動態改變的,容許只有一個,也就是沒有資料複製。VGroup ID是永遠不變的,即使一個虛擬節點組被刪除,它的ID也不會被收回重複利用。
TAOSC: taosc是TDengine給應用提供的驅動程式(driver),負責處理應用與叢集的介面互動,提供C/C++語言原生介面,內嵌於JDBC、C#、Python、Go、Node.js語言連線庫裡。應用都是通過taosc而不是直接連線叢集中的資料節點與整個叢集進行互動的。這個模組負責獲取並快取後設資料;將插入、查詢等請求轉發到正確的資料節點;在把結果返回給應用時,還需要負責最後一級的聚合、排序、過濾等操作。對於JDBC, C/C++/C#/Python/Go/Node.js介面而言,這個模組是在應用所處的物理節點上執行。同時,為支援全分散式的RESTful介面,taosc在TDengine叢集的每個dnode上都有一執行範例。
典型的訊息流程
為解釋vnode, mnode, taosc和應用之間的關係以及各自扮演的角色,下面對寫入資料這個典型操作的流程進行剖析。
- 應用通過JDBC、ODBC或其他API介面發起插入資料的請求。
- taosc會檢查快取,看是否儲存有該表的meta data。如果有,直接到第4步。如果沒有,taosc將向mnode發出get meta-data請求。
- mnode將該表的meta-data返回給taosc。Meta-data包含有該表的schema, 而且還有該表所屬的vgroup資訊(vnode ID以及所在的dnode的End Point,如果副本數為N,就有N組End Point)。如果taosc遲遲得不到mnode迴應,而且存在多個mnode, taosc將向下一個mnode發出請求。
- taosc向master vnode發起插入請求。
- vnode插入資料後,給taosc一個應答,表示插入成功。如果taosc遲遲得不到vnode的迴應,taosc會認為該節點已經離線。這種情況下,如果被插入的資料庫有多個副本,taosc將向vgroup裡下一個vnode發出插入請求。
- taosc通知APP,寫入成功
對於第二和第三步,taosc啟動時,並不知道mnode的End Point,因此會直接向設定的叢集對外服務的End Point發起請求。如果接收到該請求的dnode並沒有設定mnode,該dnode會在回覆的訊息中告知mnode EP列表,這樣taosc會重新向新的mnode的EP發出獲取meta-data的請求。
對於第四和第五步,沒有快取的情況下,taosc無法知道虛擬節點組裡誰是master,就假設第一個vnodeID就是master,向它發出請求。如果接收到請求的vnode並不是master,它會在回覆中告知誰是master,這樣taosc就向建議的master vnode發出請求。一旦得到插入成功的回覆,taosc會快取master節點的資訊。
上述是插入資料的流程,查詢、計算的流程也完全一致。taosc把這些複雜的流程全部封裝遮蔽了,對於應用來說無感知也無需任何特別處理。
通過taosc快取機制,只有在第一次對一張表操作時,才需要存取mnode,因此mnode不會成為系統瓶頸。但因為schema有可能變化,而且vgroup有可能發生改變(比如負載均衡發生),因此taosc會定時和mnode互動,自動更新快取。
儲存模型與資料分割區、分片
儲存模型
TDengine儲存的資料包括採集的時序資料以及庫、表相關的後設資料、標籤資料等,這些資料具體分為三部分:
- 時序資料:存放於vnode裡,由data、head和last三個檔案組成,資料量大,查詢量取決於應用場景。容許亂序寫入,但暫時不支援刪除操作,並且僅在update引數設定為1時允許更新操作。通過採用一個採集點一張表的模型,一個時間段的資料是連續儲存,對單張表的寫入是簡單的追加操作,一次讀,可以讀到多條記錄,這樣保證對單個採集點的插入和查詢操作,效能達到最優。
- 標籤資料:存放於vnode裡的meta檔案,支援增刪改查四個標準操作。資料量不大,有N張表,就有N條記錄,因此可以全記憶體儲存。如果標籤過濾操作很多,查詢將十分頻繁,因此TDengine支援多核多執行緒並行查詢。只要計算資源足夠,即使有數千萬張表,過濾結果能毫秒級返回。
- 後設資料:存放於mnode裡,包含系統節點、使用者、DB、Table Schema等資訊,支援增刪改查四個標準操作。這部分資料的量不大,可以全記憶體儲存,而且由於使用者端有快取,查詢量也不大。因此目前的設計雖是集中式儲存管理,但不會構成效能瓶頸。
與典型的NoSQL儲存模型相比,TDengine將標籤資料與時序資料完全分離儲存,它具有兩大優勢:
- 能夠極大地降低標籤資料儲存的冗餘度:一般的NoSQL資料庫或時序資料庫,採用的K-V儲存,其中的Key包含時間戳、裝置ID、各種標籤。每條記錄都帶有這些重複的內容,浪費儲存空間。而且如果應用要在歷史資料上增加、修改或刪除標籤,需要遍歷資料,重寫一遍,操作成本極其昂貴。
- 能夠實現極為高效的多表之間的聚合查詢:做多表之間聚合查詢時,先把符合標籤過濾條件的表查詢出來,然後再查詢這些表相應的資料塊,這樣大幅減少要掃描的資料集,從而大幅提高查詢效率。而且標籤資料採用全記憶體的結構進行管理和維護,千萬級別規模的標籤資料查詢可以在毫秒級別返回。
資料分片
對於海量的資料管理,為實現水平擴充套件,一般都需要採取分片(Sharding)分割區(Partitioning)策略。TDengine是通過vnode來實現資料分片的,通過一個時間段一個資料檔案來實現時序資料分割區的。
vnode(虛擬資料節點)負責為採集的時序資料提供寫入、查詢和計算功能。為便於負載均衡、資料恢復、支援異構環境,TDengine將一個資料節點根據其計算和儲存資源切分為多個vnode。這些vnode的管理是TDengine自動完成的,對應用完全透明。
對於單獨一個資料採集點,無論其資料量多大,一個vnode(或vnode group, 如果副本數大於1)有足夠的計算資源和儲存資源來處理(如果每秒生成一條16位元組的記錄,一年產生的原始資料不到0.5G),因此TDengine將一張表(一個資料採集點)的所有資料都存放在一個vnode裡,而不會讓同一個採集點的資料分佈到兩個或多個dnode上。而且一個vnode可儲存多個資料採集點(表)的資料,一個vnode可容納的表的數目的上限為一百萬。設計上,一個vnode裡所有的表都屬於同一個DB。一個資料節點上,除非特殊設定,一個DB擁有的vnode數目不會超過系統核的數目。
建立DB時,系統並不會馬上分配資源。但當建立一張表時,系統將看是否有已經分配的vnode, 且該vnode是否有空餘的表空間,如果有,立即在該有空位的vnode建立表。如果沒有,系統將從叢集中,根據當前的負載情況,在一個dnode上建立一新的vnode, 然後建立表。如果DB有多個副本,系統不是隻建立一個vnode,而是一個vgroup(虛擬資料節點組)。系統對vnode的數目沒有任何限制,僅僅受限於物理節點本身的計算和儲存資源。
每張表的meda data(包含schema, 標籤等)也存放於vnode裡,而不是集中存放於mnode,實際上這是對Meta資料的分片,這樣便於高效並行的進行標籤過濾操作。
資料分割區
TDengine除vnode分片之外,還對時序資料按照時間段進行分割區。每個資料檔案只包含一個時間段的時序資料,時間段的長度由DB的設定引數days決定。這種按時間段分割區的方法還便於高效實現資料的保留策略,只要資料檔案超過規定的天數(系統設定引數keep),將被自動刪除。而且不同的時間段可以存放於不同的路徑和儲存媒介,以便於巨量資料的冷熱管理,實現多級儲存。
總的來說,TDengine是通過vnode以及時間兩個維度,對巨量資料進行切分,便於並行高效的管理,實現水平擴充套件。

