flink-cdc同步mysql資料到kafka
本文首發於我的個人部落格網站 等待下一個秋-Flink
什麼是CDC?
CDC是(Change Data Capture 變更資料獲取)的簡稱。核心思想是,監測並捕獲資料庫的變動(包括資料 或 資料表的插入INSERT、更新UPDATE、刪除DELETE等),將這些變更按發生的順序完整記錄下來,寫入到訊息中介軟體中以供其他服務進行訂閱及消費。
1. 環境準備
-
mysql
-
kafka 2.3
-
flink 1.13.5 on yarn
說明:如果沒有安裝hadoop,那麼可以不用yarn,直接用flink standalone環境吧。
2. 下載下列依賴包
下面兩個地址下載flink的依賴包,放在lib目錄下面。
如果你的Flink是其它版本,可以來這裡下載。
這裡flink-sql-connector-mysql-cdc,前面一篇文章我用的mysq-cdc是1.4的,當時是可以的,但是今天我發現需要mysql-cdc-1.3.0了,否則,整合connector-kafka會有來衝突,目前mysql-cdc-1.3適用性更強,都可以相容的。
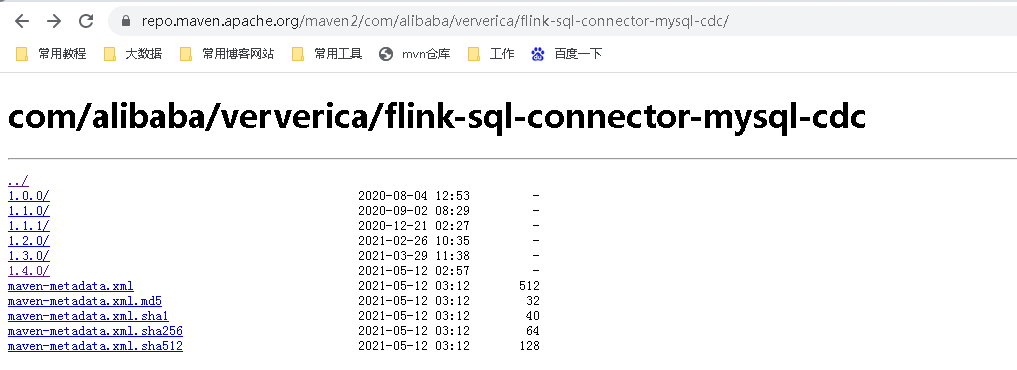
如果你是更高版本的flink,可以自行https://github.com/ververica/flink-cdc-connectors下載新版mvn clean install -DskipTests 自己編譯。
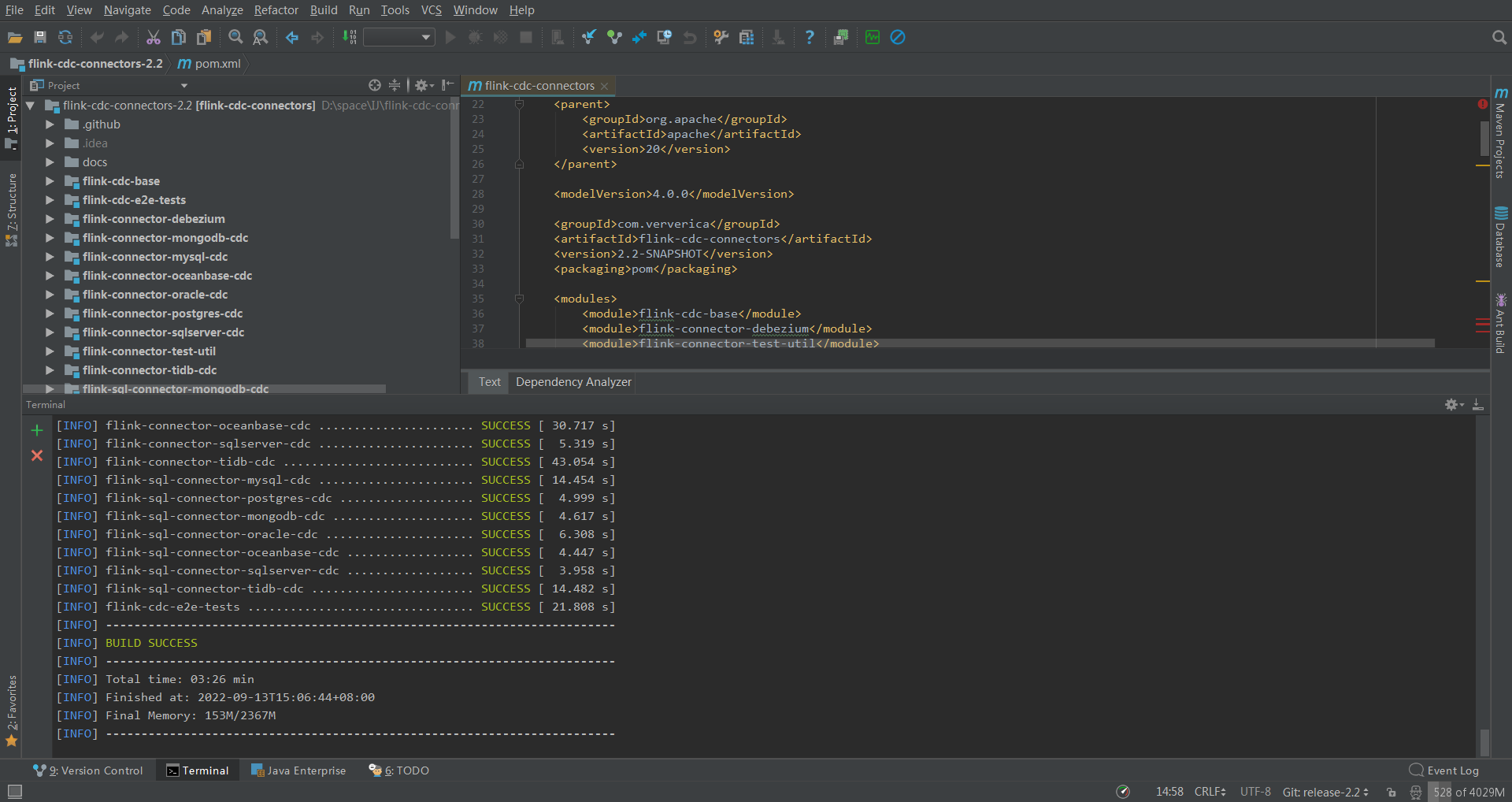
這是我編譯的最新版2.2,傳上去發現太新了,如果重新換個版本,我得去gitee下載原始碼,不然github速度太慢了,然後用IDEA編譯打包,又得下載一堆依賴。我投降,我直接去網上下載了個1.3的直接用了。
我下載的jar包,放在flink的lib目錄下面:
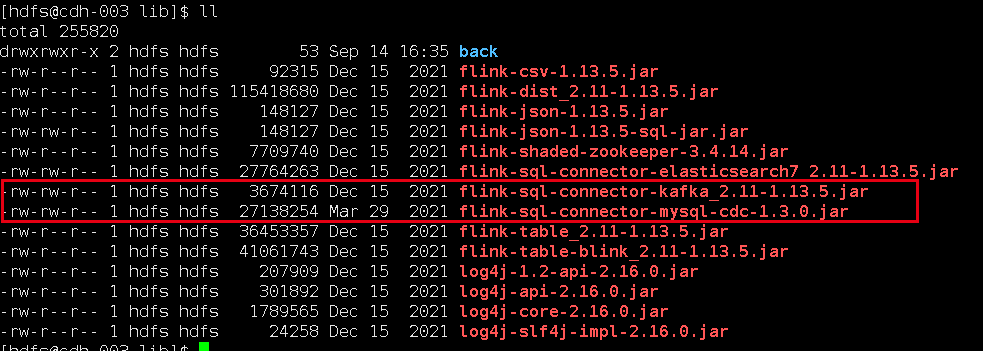
flink-sql-connector-kafka_2.11-1.13.5.jar
flink-sql-connector-mysql-cdc-1.3.0.jar
3. 啟動flink-sql client
- 先在yarn上面啟動一個application,進入flink13.5目錄,執行:
bin/yarn-session.sh -d -s 1 -jm 1024 -tm 2048 -qu root.sparkstreaming -nm flink-cdc-kafka
- 進入flink sql命令列
bin/sql-client.sh embedded -s flink-cdc-kafka

4. 同步資料
這裡有一張mysql表:
CREATE TABLE `product_view` (
`id` int(11) NOT NULL AUTO_INCREMENT,
`user_id` int(11) NOT NULL,
`product_id` int(11) NOT NULL,
`server_id` int(11) NOT NULL,
`duration` int(11) NOT NULL,
`times` varchar(11) NOT NULL,
`time` datetime NOT NULL,
PRIMARY KEY (`id`),
KEY `time` (`time`),
KEY `user_product` (`user_id`,`product_id`) USING BTREE,
KEY `times` (`times`) USING BTREE
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4;
-- 樣本資料
INSERT INTO `product_view` VALUES ('1', '1', '1', '1', '120', '120', '2020-04-24 13:14:00');
INSERT INTO `product_view` VALUES ('2', '1', '1', '1', '120', '120', '2020-04-24 13:14:00');
INSERT INTO `product_view` VALUES ('3', '1', '1', '3', '120', '120', '2020-04-24 13:14:00');
INSERT INTO `product_view` VALUES ('4', '1', '1', '2', '120', '120', '2020-04-24 13:14:00');
INSERT INTO `product_view` VALUES ('5', '8', '1', '1', '120', '120', '2020-05-14 13:14:00');
INSERT INTO `product_view` VALUES ('6', '8', '1', '2', '120', '120', '2020-05-13 13:14:00');
INSERT INTO `product_view` VALUES ('7', '8', '1', '3', '120', '120', '2020-04-24 13:14:00');
INSERT INTO `product_view` VALUES ('8', '8', '1', '3', '120', '120', '2020-04-23 13:14:00');
INSERT INTO `product_view` VALUES ('9', '8', '1', '2', '120', '120', '2020-05-13 13:14:00');
- 建立資料表關聯mysql
CREATE TABLE product_view_source (
`id` int,
`user_id` int,
`product_id` int,
`server_id` int,
`duration` int,
`times` string,
`time` timestamp,
PRIMARY KEY (`id`) NOT ENFORCED
) WITH (
'connector' = 'mysql-cdc',
'hostname' = '192.168.1.2',
'port' = '3306',
'username' = 'bigdata',
'password' = 'bigdata',
'database-name' = 'test',
'table-name' = 'product_view'
);
這樣,我們在flink sql client操作這個表相當於操作mysql裡面的對應表。
- 建立資料表關聯kafka
CREATE TABLE product_view_kafka_sink(
`id` int,
`user_id` int,
`product_id` int,
`server_id` int,
`duration` int,
`times` string,
`time` timestamp,
PRIMARY KEY (`id`) NOT ENFORCED
) WITH (
'connector' = 'upsert-kafka',
'topic' = 'flink-cdc-kafka',
'properties.bootstrap.servers' = '192.168.1.2:9092',
'properties.group.id' = 'flink-cdc-kafka-group',
'key.format' = 'json',
'value.format' = 'json'
);
這樣,kafka裡面的flink-cdc-kafka這個主題會被自動建立,如果想指定一些屬性,可以提前手動建立好主題,我們操作表product_view_kafka_sink,往裡面插入資料,可以發現kafka中已經有資料了。
- 同步資料

建立同步任務,可以使用sql如下:
insert into product_view_kafka_sink select * from product_view_source;
這個時候是可以退出flink sql-client的,然後進入flink web-ui,可以看到mysql表資料已經同步到kafka中了,對mysql進行插入,kafka都是同步更新的。
通過kafka控制檯消費,可以看到資料已經從mysql同步到kafka了:

參考資料
https://ververica.github.io/flink-cdc-connectors/master/content/about.html