Java 流處理之收集器
Java 流(Stream)處理操作完成之後,我們可以收集這個流中的元素,使之匯聚成一個最終結果。這個結果可以是一個物件,也可以是一個集合,甚至可以是一個基本型別資料。
以記錄 Record 為例:
@Data
@NoArgsConstructor
@AllArgsConstructor
public static class Record {
private String col1;
private String col2;
private int col3;
}
記錄 Record 包含三個屬性:列1(col1)、列2(col2)和 列3(col3)。
建立四個記錄範例:
Record r1 = new Record("a", "1", 1);
Record r2 = new Record("a", "2", 2);
Record r3 = new Record("b", "3", 3);
Record r4 = new Record("c", "4", 4);
新增到列表:
List<Record> records = new ArrayList<>();
records.add(r1);
records.add(r2);
records.add(r3);
records.add(r4);
收集所有記錄的 列1 值,以列表形式儲存結果
List<String> col1List = records.stream()
.map(Record::getCol1)
.collect(Collectors.toList());
log.info("col1List: {}", Json.toJson(col1List));
輸出結果:
col1List: ["a","a","b","c"]
收集所有記錄的 列1 值,且去重,以集合形式儲存
Set<String> col1Set = records.stream()
.map(Record::getCol1)
.collect(Collectors.toSet());
log.info("col1Set: {}", Json.toJson(col1Set));
輸出結果:
col1Set: ["a","b","c"]
收集記錄的 列2 值和 列3 值的對應關係,以字典形式儲存
Map<String, Integer> col2Map = records.stream()
.collect(Collectors.toMap(Record::getCol2, Record::getCol3));
log.info("col2Map: {}", Json.toJson(col2Map));
輸出結果:
col2Map: {"1":1,"2":2,"3":3,"4":4}
記錄的 列2 不能有重複值,否則會丟擲 Duplicate key 異常。
收集所有記錄中 列3 值最大的記錄
Record max = records.stream()
.collect(Collectors.maxBy(Comparator.comparing(Record::getCol3)))
.orElse(null);
log.info("max: {}", Json.toJson(max));
輸出結果:
max: {"col1":"c","col2":"4","col3":4}
收集所有記錄中 列3 值的總和
int sum = records.stream()
.collect(Collectors.summingInt(Record::getCol3));
log.info("sum: {}", sum);
輸出結果:
sum: 10
流的收集需要通過 Stream.collect() 方法完成,方法的引數是一個 Collector(收集器);收集結果時,需要根據收集結果的目標型別,傳遞特定的收集器範例,如上:
- Collectors.toList()
- Collectors.toSet()
- Collectors.toMap()
- Collectors.maxBy()
- Collectors.summingInt()
Collectors(java.util.stream.Collectors) 是一個工具類,內建若干收集器,我們可以通過呼叫不同的方法快速獲取相應的收集器範例。
收集器(java.util.stream.Collector)本質是一個 介面,包含以下五個方法:
- Supplier supplier()
- BiConsumer<A, T> accumulator()
- BinaryOperator combiner()
- Function<A, R> finisher()
- Set
characteristics()
以 Collectors.toList() 為例演示收集器的工作過程。
建立一箇中間結果容器
supplier() 方法會返回一個 Supplier 範例,呼叫該範例的 get() 方法,會建立一箇中間結果容器。

@Override
public Supplier<List<String>> supplier() {
return new Supplier<List<String>>() {
@Override
public List<String> get() {
List<String> container = new ArrayList<>();
return container;
}
};
}
考慮到收集的元素型別 String,這裡的中間結果容器型別為 ArrayList
根據收集過程的需要,中間結果容器可以是任意的資料結構。
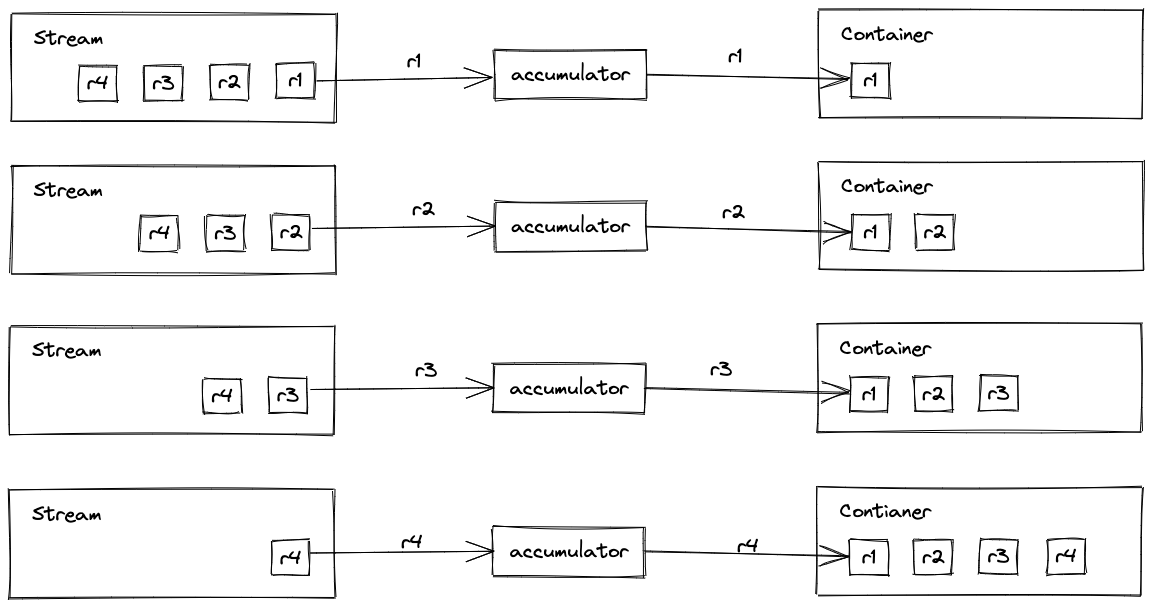
逐一遍歷流中的每個元素,處理完成之後,新增到中間結果
accumulator() 方法會返回一個 BiConsumer 範例,它有一個 accept() 方法,
引數1:中間結果
引數2:流中遍歷到的某個元素
遍歷過程是 Java 自動完成的,每遍歷一個元素,會自動呼叫 BiConsumer.accept 方法。我們只需要在方法中實現元素的處理過程,然後把元素的處理結果新增到中間結果中就可以了。
@Override
public BiConsumer<List<String>, String> accumulator() {
return new BiConsumer<List<String>, String>() {
@Override
public void accept(List<String> container, String col) {
container.add(col);
}
};
}
這個範例中,流中的元素不需要任何處理,直接新增至中間結果即可。
中間結果轉換成最終結果
finisher() 方法會返回一個 Fuction 範例,它有一個 apply() 方法,
引數:中間結果
返回:最終結果
遍歷過程結束之後,Java 會自動呼叫 Function.apply() 方法,將中間結果轉換成最終結果。

@Override
public Function<List<String>, List<String>> finisher() {
return new Function<List<String>, List<String>>() {
@Override
public List<String> apply(List<String> container) {
return container;
}
};
}
這個範例中,中間結果就是最終結果,不需要任何處理,直接返回中間結果即可。
combiner()是做什麼的?
流中的元素可以被並行處理,這樣的流稱為並行流。並行流相當於把一個大流切分成多個小流,內部使用多執行緒,並行處理這些小流。每一個小流遍歷完成之後,都會產生一個小的中間結果,需要將這些小的中間結果合併成一個大的中間結果。
假設有兩個小流,收集開始時,會建立兩個中間結果:
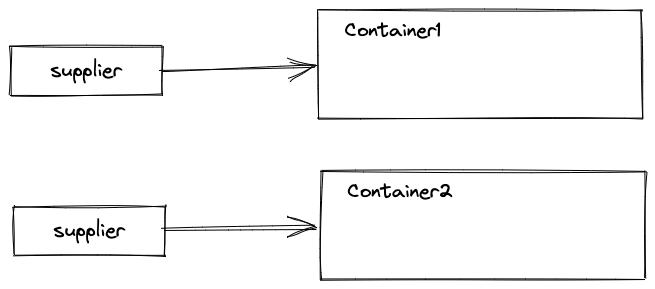
中間結果也是通過 Supplier.get() 方法建立的。
並行遍歷兩個小流,將各自流的處理結果新增到各自的中間結果中:
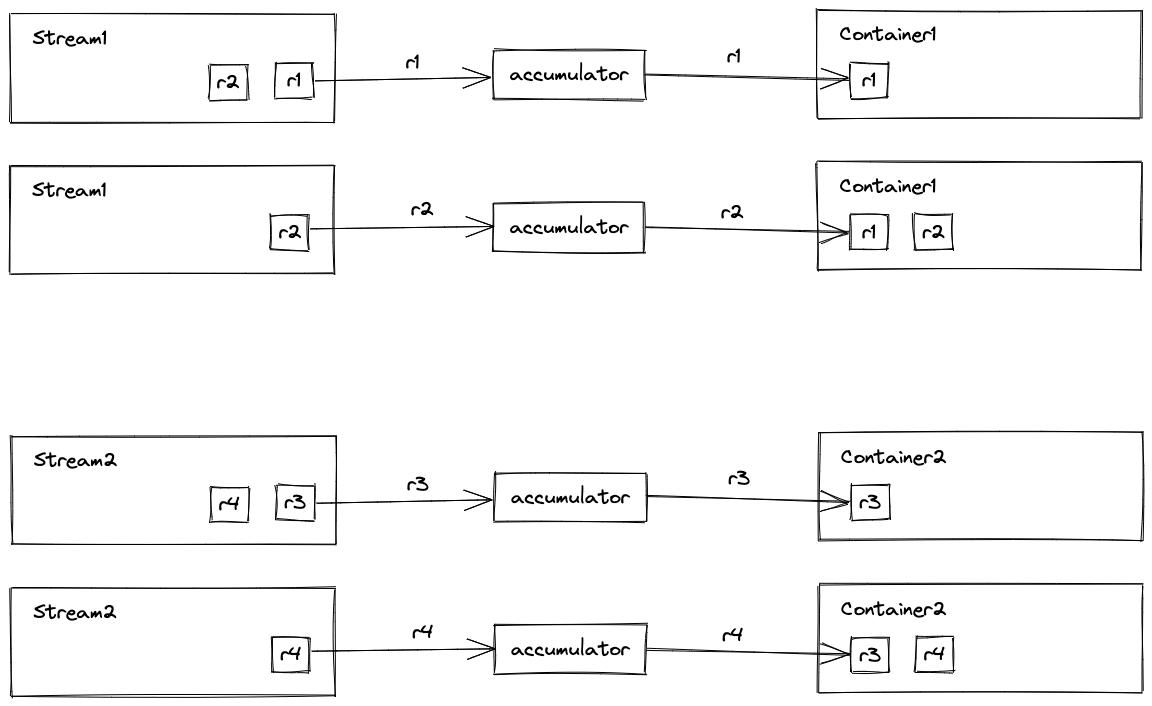
combiner() 方法會返回一個 BinaryOperator 範例,它有一個 apply() 方法:
引數1:中間結果1
引數2:中間結果2
返回:中間結果
Java 會在合適的時機自動呼叫 BinaryOperator.apply() 方法,將小的中間結果合併成大的中間結果。
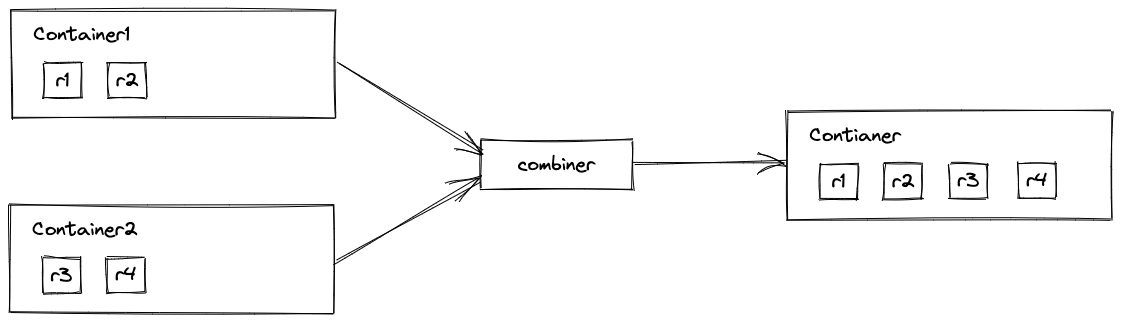
@Override
public BinaryOperator<List<String>> combiner() {
return new BinaryOperator<List<String>>() {
@Override
public List<String> apply(List<String> container1, List<String> container2) {
container1.addAll(container2);
return container1;
}
};
}
characteristics()是什麼的?
characteristics() 會返回一個 Characteristics(列舉)集合範例,用於設定收集器的特性,支援以下三個值:
-
CONCURRENT
收集器支援並行使用
-
UNORDERED
收集器不保證元素順序
-
IDENTITY_FINISH
收集器中間結果可直接轉換成最終結果
Java 可以根據這些特性值,保證收集器正確地、有效率地執行。
完整程式碼
Collector<String, List<String>, List<String>> collector = new Collector<String, List<String>, List<String>>() {
@Override
public Supplier<List<String>> supplier() {
return new Supplier<List<String>>() {
@Override
public List<String> get() {
List<String> container = new ArrayList<>();
return container;
}
};
}
@Override
public BiConsumer<List<String>, String> accumulator() {
return new BiConsumer<List<String>, String>() {
@Override
public void accept(List<String> container, String col) {
container.add(col);
}
};
}
@Override
public BinaryOperator<List<String>> combiner() {
return new BinaryOperator<List<String>>() {
@Override
public List<String> apply(List<String> container1, List<String> container2) {
container1.addAll(container2);
return container1;
}
};
}
@Override
public Function<List<String>, List<String>> finisher() {
return new Function<List<String>, List<String>>() {
@Override
public List<String> apply(List<String> container) {
return container;
}
};
}
@Override
public Set<Characteristics> characteristics() {
return new HashSet<>();
}
};
col1List = records.stream()
.map(Record::getCol1)
.collect(collector);
log.info("col1List: {}", Json.toJson(col1List));