天天寫SQL,這些神奇的特性你知道嗎?
摘要:不要歪了,我這裡說特性它不是 bug,而是故意設計的機制或語法,你有可能天天寫語句或許還沒發現原來還能這樣用,沒關係我們一起學下漲姿勢。
本文分享自華為雲社群《【雲駐共創】天天寫 SQL,你遇到了哪些神奇的特性?》,作者: 龍哥手記 。
一 SQL 的第一個神奇特性
日常開發我們經常會對錶進行聚合查詢操作,但只能在 SELECT 子句中寫下面 3 種內容:通過 GROUP BY 子句指定的聚合鍵、聚合函數(SUM 、AVG 等)、常數,不懂沒關係我們來看個例子
聽我解釋
有學生班級表(tbl_student_class) 以及資料如下
DROP TABLE IF EXISTS tbl_student_class; CREATE TABLE tbl_student_class ( id int(8) unsigned NOT NULL AUTO_INCREMENT COMMENT '自增主鍵', sno varchar(12) NOT NULL COMMENT '學號', cno varchar(5) NOT NULL COMMENT '班級號', cname varchar(20) NOT NULL COMMENT '班級名', PRIMARY KEY (id) ) COMMENT='學生班級表'; -- ---------------------------- -- Records of tbl_student_class -- ---------------------------- INSERT INTO tbl_student_class VALUES ('1', '20190607001', '0607', '影視7班'); INSERT INTO tbl_student_class VALUES ('2', '20190607002', '0607', '影視7班'); INSERT INTO tbl_student_class VALUES ('3', '20190608003', '0608', '影視8班'); INSERT INTO tbl_student_class VALUES ('4', '20190608004', '0608', '影視8班'); INSERT INTO tbl_student_class VALUES ('5', '20190609005', '0609', '影視9班'); INSERT INTO tbl_student_class VALUES ('6', '20190609006', '0609', '影視9班');
我想統計各個班(班級號、班級名)一個有多少人、以及最大的學號,我們該怎麼寫這個查詢 SQL?我想大家用腳都寫得出來
SELECT cno,cname,count(sno),MAX(sno)
FROM tbl_student_class
GROUP BY cno,cname;
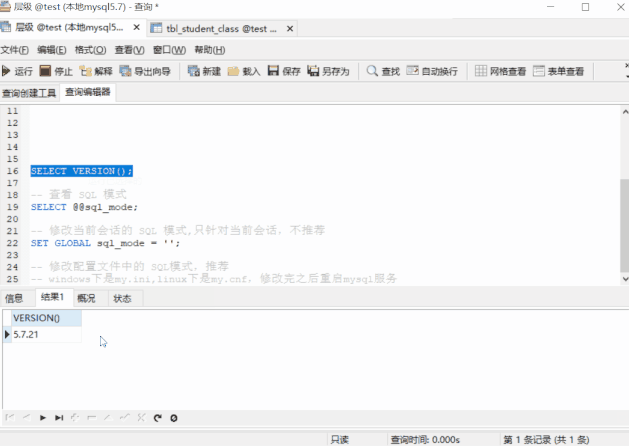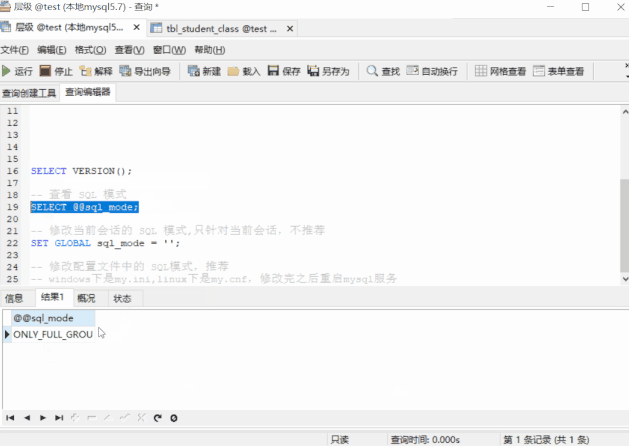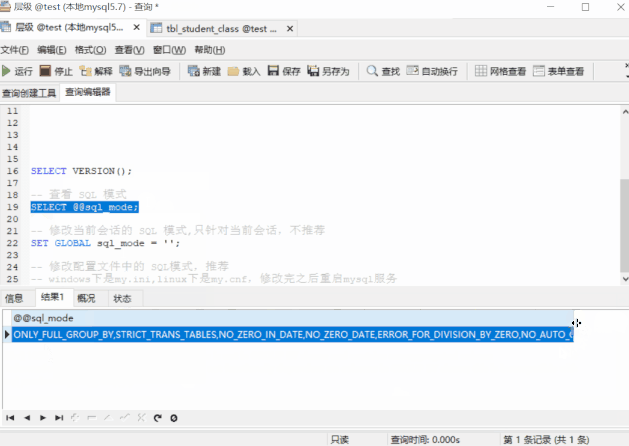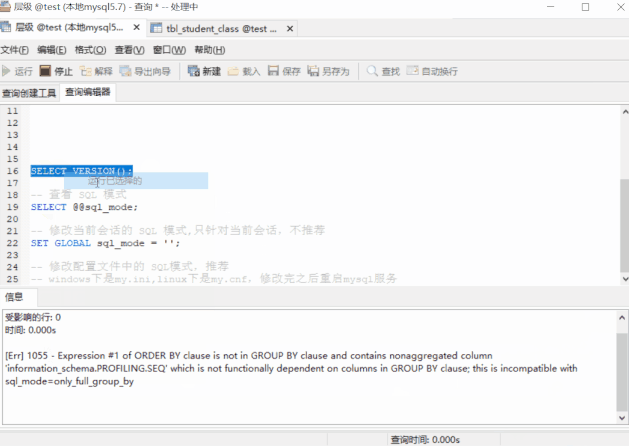
可是有人會想了,cno 和 cname 本來就是一對一,cno 一旦確定,cname 也就確定了嗎,那 SQL 咱們是不是可以這麼寫?
SELECT cno,cname,count(sno),MAX(sno)
FROM tbl_student_class
GROUP BY cno;
執行報錯了
[Err] 1055 - Expression #2 of SELECT list is not in GROUP BY clause and contains nonaggregated column 'test.tbl_student_class.cname' which is not functionally dependent on columns in GROUP BY clause; this is incompatible with sql_mode=only_full_group_by 提示資訊:SELECT 列表中的第二個表示式(cname)不在 GROUP BY 的子句中,同時它也不是**聚合函數**;這與 sql 模式:ONLY_FULL_GROUP_BY 不相容的哈
那為什麼 GROUP BY 之後不能直接參照原表(不在 GROUP BY 子句)中的列 ?莫急,我們慢慢往下看就明白了
1.0 SQL 模式
MySQL 伺服器可以在不同的 SQL 模式下執行,並且可以針對不同的使用者端以不同的方式應用這些模式,具體取決於 sql_mode 系統變數的值。DBA 可以設定全域性 SQL 模式以匹配站點伺服器操作要求,並且每個應用程式可以將其對談 SQL 模式設定為其自己的要求。
模式會影響 MySQL 支援的 SQL 語法以及它執行的資料驗證檢查,這使得在不同環境中使用 MySQL 以及將 MySQL 與其他資料庫伺服器一起使用變得更加容易。更多詳情請查官網自己找:Server SQL Modes
MySQL 版本不同,內容會略有不同(包括預設值),查閱的時候注意與自身的 MySQL 版本保持一致哈
SQL 模式主要分兩類:語法支援類和資料檢查類,常用的如下
語法支援類
- ONLY_FULL_GROUP_BY
對於 GROUP BY 聚合操作,如果在 SELECT 中的列、HAVING 或者 ORDER BY 子句的列,沒有在 GROUP BY 中出現,那麼這個 SQL 是不合法的 - ANSI_QUOTES
啟用 ANSI_QUOTES 後,不能用雙引號來參照字串,因為它被解釋為識別符。設定它以後,update t set f1="" …,會報 Unknown column ‘’ in field list 這樣的語法錯誤 - PIPES_AS_CONCAT
把 || 視為字串的連線操作符而非 或 運運算元,這種和 Oracle 資料庫是一樣的哈,也和字串的拼接函數 CONCAT () 有點類似 - NO_TABLE_OPTIONS
使用 SHOW CREATE TABLE 時不會輸出 MySQL 特有的語法部分,如 ENGINE,這個在使用 mysqldump 跨 DB 種類遷移的時候需要考慮 - NO_AUTO_CREATE_USER
字面意思不自動建立使用者,在給 MySQL 使用者授權時,我們習慣用 GRANT … ON … TO dbuser,順道一起建立使用者。設定該選項後就與 oracle 操作類似,授權之前必須先建立好使用者
1.1 資料檢查類
- NO_ZERO_DATE
認為日期‘0000-00-00’非法,與是否設定後面的嚴格模式有關係
1、如果設定了嚴格模式,則 NO_ZERO_DATE 自然滿足。但如果是 INSERT IGNORE 或 UPDATE IGNORE,’0000-00-00’依然允許且只顯示 warning;
2、如果在非嚴格模式下,設定了 NO_ZERO_DATE,效果與上面一樣,’0000-00-00’ 允許但顯示 warning;如果沒有設定 NO_ZERO_DATE,no warning,當做完全合法的值;
3、NO_ZERO_IN_DATE 情況與上面類似,不同的是控制日期和天,是否可為 0 ,即 2010-01-00 是否合法;
- NO_ENGINE_SUBSTITUTION
使用 ALTER TABLE 或 CREATE TABLE 指定 ENGINE 時,需要的儲存引擎被禁用或未編譯,該如何處理。啟用 NO_ENGINE_SUBSTITUTION 時,那麼直接丟擲錯誤;不設定此值時,CREATE 用預設的儲存引擎替代,ATLER 不進行更改,並丟擲一個 warning
- STRICT_TRANS_TABLES
設定它,表示啟用嚴格模式。注意 STRICT_TRANS_TABLES 不是幾種策略的組合,單獨指 INSERT、UPDATE 出現少值或無效值該如何處理:
1、前面提到的把 ‘’ 傳給 int,嚴格模式下非法,若啟用非嚴格模式則變成 0,產生一個 warning;
2、Out Of Range,變成插入最大邊界值;
3、當要插入的新行中,不包含其定義中沒有顯式 DEFAULT 子句的非 NULL 列的值時,該列缺少值
1.2 預設模式
當我們沒有修改組態檔的情況下,MySQL 是有自己的預設模式的;版本不同,預設模式也不同
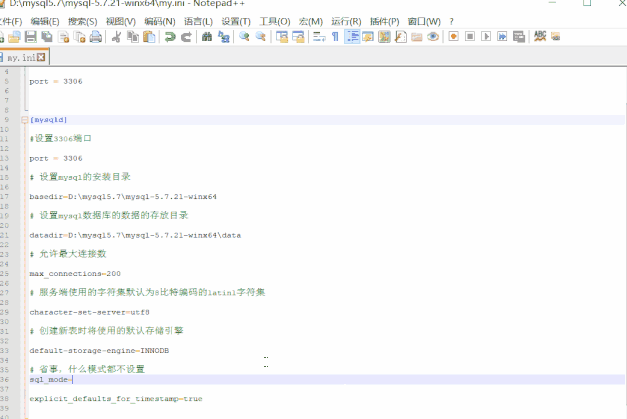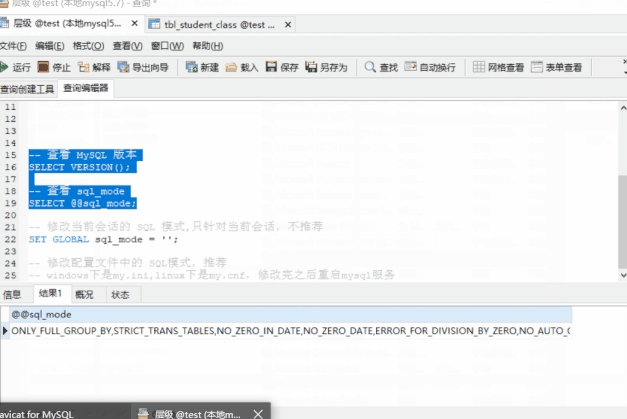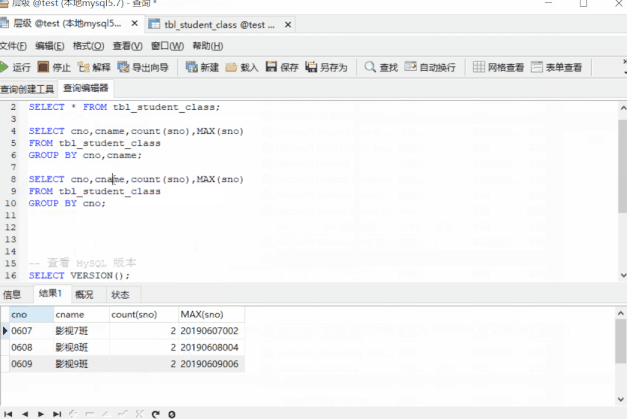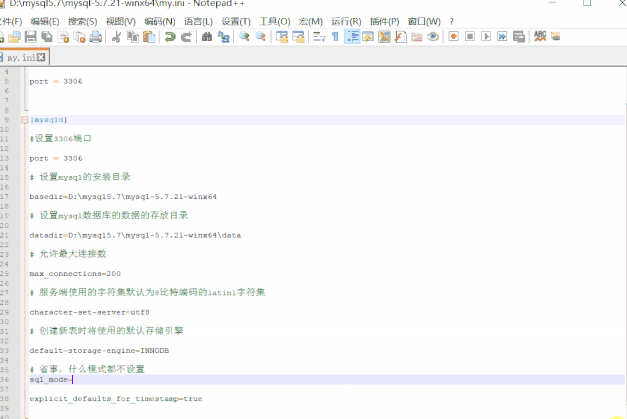
-- 檢視 MySQL 版本 SELECT VERSION(); -- 檢視 sql_mode SELECT @@sql_mode;
我們可以看到,5.7.21 的預設模式包含
ONLY_FULL_GROUP_BY,STRICT_TRANS_TABLES,NO_ZERO_IN_DATE,NO_ZERO_DATE,ERROR_FOR_DIVISION_BY_ZERO,NO_AUTO_CREATE_USER,NO_ENGINE_SUBSTITUTION
而第一個:ONLY_FULL_GROUP_BY 就會約束:當我們進行聚合查詢的時候,SELECT 的列不能直接包含非 GROUP BY 子句中的列。那如果我們去掉該模式(從 「嚴格模式」 到 「寬鬆模式」)呢?
我們發現,上述報錯的 SQL
-- 寬鬆模式下 可以執行
SELECT cno,cname,count(sno),MAX(sno)
FROM tbl_student_class
GROUP BY cno;
能正常執行了,但是一般情況下不推薦這樣設定,線上環境往往是 「嚴格模式」,而不是 「寬鬆模式」;雖然案例中,無論是 「嚴格模式」,還是 「寬鬆模式」,結果都是對的,那是因為 cno 與 cname 唯一對應的,如果 cno 與 cname 不是唯一對應,那麼在 「寬鬆模式下」 cname 的值是隨機的,這就會造成難以排查的問題,有興趣的可以去試下;
二 SQL 的第二個神奇特性
2.1 問題描述下
今天我想比較兩個資料集
表 A 一共 50,000,000 行,其中有一列叫「ID」,表 B 也有一列叫「ID」。我想查的是有 A 表裡有多少 ID 在 B 表裡面,資料庫用的是 snowflake,它是一種一種多租戶、事務性、安全、高度可延伸的彈性資料庫,或者叫它實施數倉也行,具備完整的 SQL 支援和 schema-less 資料模式,支援 ACID 的事務,也提供用於遍歷、展平和巢狀半結構化資料的內建函數和 SQL 擴充套件,並支援 JSON 和 Avro 等流行格式;
用 query:
with A as ( select distinct(id) as id from Table_A ), B as ( select distinct(id) as id from Table_B ), result as ( select * from A where id in (select id from B) ) select count(*) from result
返回結果是 26,000,000
也就是說,A 應有 24,000,000 行不在 B 裡面,對吧
可是我把第 11 行的 in 改成 not in 後,情況有點出乎我的意料
with A as ( select distinct(id) as id from Table_A ), B as ( select distinct(id) as id from Table_B ), result as ( select * from A where id not in (select id from B) ) select count(*) from result
返回結果竟然是 0,而不是 24,000,000
於是我在 snowflake 論壇搜了下,發現 5 年前在這貼文下面有人回覆到:
If you use NOT IN (subquery), it compares every returned value and in case of NULL on any side of comparison it stops immediately with non defined result if you use NOT IN (subquery), it compares every returned value and in case of NULL on any side of comparison it stops immediately with non defined result
就是說,當你用 not in,subquery(例如上面第 11 行的 select id from B)裡如果有 Null, 那麼它就會立刻停止,返回未定義的結果,所以最後結果是 0;
該如何解決?很簡單
2.2 去掉 null 值
在第 7 行加了限定 where id is not null 後,結果正常了
with A as ( select distinct(id) as id from Table_A ), B as ( select distinct(id) as id from Table_B where id is not null ), result as ( select * from A where id not in (select id from B) ) select count(*) from result
最終返回結果為 24,000,000,這樣就對了啊
2.3 用 not exists 代替 not in
注意第 11 行,用了 not exists 代替 not in
with A as ( select distinct(id) as id from Table_A ), B as ( select distinct(id) as id from Table_B where id is not null ), result as ( select * from A where not exists (select * from B where A.id=B.id) ) select count(*) from result
返回結果也為 24,000,000
當然,這肯定不是 bug 哈,而是特性,不然不會這麼多年都留著,是我懂得太少了,得惡補下 SQL 哭泣。
不過不知道這個特性設計當初目的是什麼,如果 subquery 返回了 undefined,你好歹給我報個錯啊。這個「特性」不僅僅在 snowflake 上面出現,看 StackOverflow 上討論,貌似 Oracle 也是有這個「特性」的哈
三 SQL 的第三個神奇特性
像 Web 服務這樣需要快速響應的應用場景中,SQL 的效能直接決定了系統是否可以使用;特別在一些中小型應用中,SQL 的效能更是決定服務能否快速響應的唯一標準
嚴格地優化查詢效能時,必須要了解所使用資料庫的功能特點,此外,查詢速度慢並不只是因為 SQL 語句本身,還有可能記憶體分配不佳、檔案結構不合理、刷髒頁等其他原因啊;
因此下面介紹些 SQL 神奇特性,但不能解決所有的效能問題,但是卻能處理很多因 SQL 寫法不合理而產生的效能問題
所以下面儘量介紹一些不依賴具體資料庫實現,使 SQL 執行速度更快、消耗記憶體更少的優化技巧,只需調整 SQL 語句就能實現的通用的優化 Tip
3.1 環境準備
下文所講的內容是從 SQL 層面展開的哈,而不是針對某種特性的資料庫,也就是說,下文的內容基本上適用於任何關係型資料庫都可以;
但是,關係型資料庫那麼多,逐一來演示範例了,顯然不太現實;我們以常用的 MySQL 來進行就行啦
MySQL 版本: 5.7.30-log ,儲存引擎: InnoDB
準備兩張表: tbl_customer 和 tbl_recharge_record

3.2 使用高效的查詢
針對某一個查詢,有時候會有多種 SQL 實現,例如 IN、EXISTS、連線之間的互相轉換
從理論上來講,得到相同結果的不同 SQL 語句應該有相同的效能的哈,但遺憾的是,查詢優化器生成的執行計劃很大程度上要受到外部資料結構的影響
所以,要想優化查詢效能,必須知道如何寫 SQL 語句才能使優化器生成更高效的執行計劃
3.3 使用 EXISTS 代替 IN
關於 IN,相信大家都比較熟悉,使用方便,也容易理解;雖說 IN 使用方便,但它卻存在效能瓶頸
如果 IN 的引數是 1,2,3 這樣的數值列表,一般還不需要特別注意,但如果引數是子查詢,那麼就需要注意了
在大多時候, [NOT]IN 和 [NOT]EXISTS 返回的結果是相同的,但是兩者用於子查詢時,EXISTS 的速度會更快一些
假設我們要查詢有充值記錄的顧客資訊,SQL 該怎麼寫?
相信大家第一時間想到的是 IN
IN 使用起來確實簡單,也非常好理解;我們來看下它的執行計劃

我們再來看看 EXISTS 的執行計劃:

可以看到的是,IN 的執行計劃中新產生了一張臨時表: <subquery2> ,這會導致效率變慢
所以通常來講,EXISTS 比 IN 更快的原因有兩個
- 1、如果連線列(customer_id)上建立了索引,那麼查詢 tbl_recharge_record 時可以通過索引查詢,而不是全表查詢
- 2、使用 EXISTS,一旦查到一行資料滿足條件就會終止查詢,不用像使用 IN 時一樣進行掃描全表(NOT EXISTS 也一樣)
如果當 IN 的引數是子查詢時,資料庫首先會執行子查詢,然後將結果儲存在一張臨時表裡(內聯檢視),然後掃描整個檢視,很多情況下這種做法非常耗費資源
使用 EXISTS 的話,資料庫不會生成臨時表
但是從程式碼的可讀性上來看,IN 要比 EXISTS 好,使用 IN 時的程式碼看起來更加一目瞭然,易於理解
因此,如果確信使用 IN 也能快速獲取結果,就沒有必要非得改成 EXISTS 了
其實有很多資料庫也嘗試著改善了 IN 的效能
Oracle 資料庫中,如果我們在有索引的列上使用 IN, 也會先掃描索引
PostgreSQL 從版 本 7.4 起也改善了使用子查詢作為 IN 謂詞引數時的查詢速度
說不定在未來的某一天,無論在哪個關係型資料庫上,IN 都能具備與 EXISTS 一樣的效能
3.4 使用連線代替 IN
其實在平時工作當中,更多的是用連線代替 IN 來改善查詢效能,而非 EXISTS,不是說連線更好,而是 EXISTS 很難掌握
回到問題:查詢有充值記錄的顧客資訊,如果用連線來實現,SQL 改如何寫?

這種寫法能充分利用索引;而且,因為沒有了子查詢,所以資料庫也不會生成中間表;所以,查詢效率是不錯的
至於 JOIN 與 EXISTS 相比哪個效能更好,這不太好說;如果沒有索引,可能 EXISTS 會略勝一籌,有索引的話,兩者都差不多
3.5 避免排序
說到 SQL 的排序,我們第一時間想到的肯定是:ORDERBY,通過它,我們可以按指定的某些列來順序輸出結果
但是,除了 ORDERBY 顯示的排序,資料庫內部還有很多運算在暗中進行排序;會進行排序的代表性的運算有下面這些

如果只在記憶體中進行排序,那麼還好;但是如果因記憶體不足而需要在硬碟上排序,那麼效能就會急劇下降
所以,要儘量避免(或減少)無謂的排序,能夠大大提高查詢效率
靈活使用集合運運算元的 ALL 可選項
SQL 中有 UNION 、 INTERSECT 、 EXCEPT 三個集合運運算元,分表代表這集合運算的 並集、交集、差集
預設情況下,這些運運算元會為了排除掉重複資料而進行排序
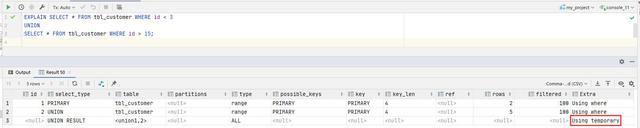
Using temporary 表示進行了排序或者分組,顯然這個 SQL 並沒有進行分組,而是進行了排序運算
所以如果我們不在乎結果中是否有重複資料,或者事先知道不會有重複資料,可以使用 UNIONALL 代替 UNION 試下,可以看到,執行計劃中沒有排序運算了

對於 INTERSECT 和 EXCEPT 也是一樣的,加上 ALL 可選項後就不會進行排序了
加上 ALL 可選項是一個非常有效的優化手段,但各個資料庫對它的實現情況卻是參差不齊,如下圖所示

注意:Oracle 使用 MINUS 代替 EXCEPT;MySQL 壓根就沒有實現 INTERSECT 和 EXCEPT 運算
3.6 使用 EXISTS 來代替 DISTINCT
為了排除重複資料, DISTINCT 也會進行排序
還記得用連線代替 IN 的案例嗎,如果不用 DISTINCT
SQL:SELECT tc.*FROM tbl_recharge_record trr LEFTJOIN tbl_customer tc on trr.customer_id = tc.id
那麼查出來的結果會有很多重複記錄,所以我們必須改進 SQL
SELECTDISTINCT tc.*FROM tbl_recharge_record trr LEFTJOIN tbl_customer tc on trr.customer_id = tc.id
會發現執行計劃中有個 Using temporary,它表示用到了排序運算

我們使用 EXISTS 來進行優化

可以看到,已經規避了排序運算
3.7 在極值函數中使用索引
SQL 語言裡有兩個極值函數:MAX 和 MIN,使用這兩個函數時都會進行排序
例如: SELECTMAX (recharge_amount) FROM tbl_recharge_record
會進行全表掃描,並會進行隱式的排序,找出單筆充值最大的金額
但是如果引數欄位上建有索引,則只需掃描索引,但不需要掃描整張表
例如:SELECTMAX (customer_id) FROM tbl_recharge_record;
會通過索引: idx_c_id 進行掃描,找出充值記錄中最大的顧客 ID
但是這種方法並不是去掉了排序這一過程,而是優化了排序前的查詢速度,從而減弱排序對整體效能的影響
能寫在 WHERE 子句裡的條件千萬不要寫在 HAVING 子句裡
我們來看兩個 SQL 以及其執行結果
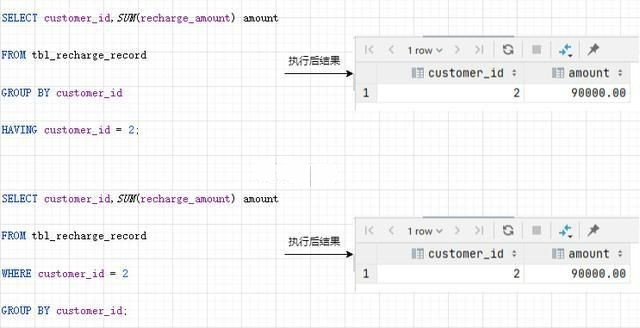
你就明白了
從結果上來看,兩條 SQ 一樣;但是從效能上來看,第二條語句寫法效率更高,原因有兩個:
1)減少排序的資料量
GROUP BY 子句聚合時會進行排序,如果事先通過 WHERE 子句篩選出一部分行,就能夠減輕排序的負擔了
2)有效利用索引
3.8 WHERE 子句的條件裡可以使用索引
HAVING 子句是針對聚合後生成的檢視進行篩選的,但是很多時候聚合後的檢視都沒有繼承原表的索引結構
關於 HAVING,更多詳情可檢視:神奇的 SQL 之 HAVING→ 容易被輕視的主角
在 GROUP BY 子句和 ORDER BY 子句中使用索引
一般來說,GROUP BY 子句和 ORDER BY 子句都會進行排序
如果 GROUP BY 和 ORDER BY 的列有索引,那麼可以提高查詢效率
特別是在一些資料庫中,如果列上建立的是唯一索引,那麼排序過程本身都會被省略掉
- 使用索引
使用索引是最常用的 SQL 優化手段,這個大家都知道,怕就怕大家不知道:明明有索引,為什麼查詢還是這麼慢(為什麼索引沒用上)
關於索引未用到的情況,可檢視:神奇的 SQL 之擦肩而過 → 真的用到索引了嗎,本文就不做過多闡述了
總之就是:查詢儘量往索引上靠,規避索引未用上的情況
- 減少臨時表
在 SQL 中,子查詢的結果會被看成一張新表(臨時表),這張新表與原始表一樣,可以通過 SQL 進行操作
但是,頻繁使用臨時表會帶來兩個問題
- 1、臨時表相當於原表資料的一份備份,會耗費記憶體資源
- 2、很多時候(特別是聚合時),臨時表沒有繼承原表的索引結構
因此,儘量減少臨時表的使用也是提升效能的一個重要方法
- 靈活使用 HAVING 子句
對聚合結果指定篩選條件時,使用 HAVING 子句是基本原則
但是如果對 HAVING 不熟,我們往往找出替代它的方式來實現,就像這樣
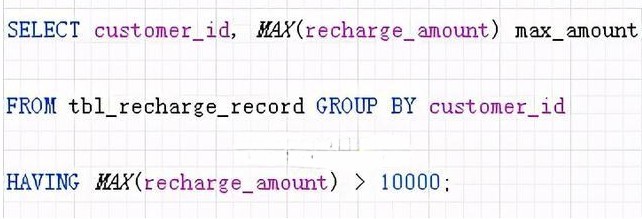
然而,對聚合結果指定篩選條件時不需要專門生成中間表,像下面這樣使用 HAVING 子句就可以
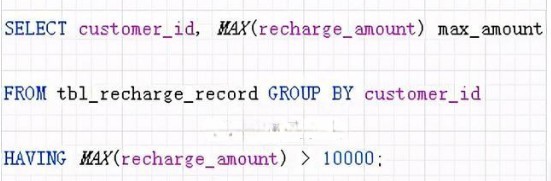
HAVING 子句和聚合操作都是同時執行的,所以比起生成臨時表後再執行 WHERE 子句,效率會更高一些,而且程式碼看起來也更簡潔
需要對多個欄位使用 IN 謂詞時,讓它們彙總到一處
SQL-92 中加入了行與行比較的功能,這樣一來,比較謂詞 = 、<、> 和 IN 謂詞的引數就不再只是標量值了,而應是值列表了
我們來看一個範例,多個欄位使用 IN 謂詞

這段程式碼中用到了兩個子查詢,我們可以進行列彙總優化,把邏輯寫在一起

這樣一來,子查詢不用考慮關聯性,而且只執行一次就可以
還可以進一步簡化,在 IN 中寫多個欄位的組合

簡化後,不用擔心連線欄位時出現的型別轉換問題,也不會對欄位進行加工,因此可以使用索引
先進行連線再進行聚合
連線和聚合同時使用時,先進行連線操作可以避免產生中間表
合理地使用檢視
檢視是非常方便的工具,我們在日常工作中經常用到
但是,如果沒有經過深入思考就定義複雜的檢視,可能會帶來巨大的效能問題
特別是檢視的定義語句中包含以下運算的時候,SQL 會非常低效,執行速度也會變得非常慢
小結下
文中雖然列舉了幾個要點,但其實優化的核心思想只有一個,那就是找出效能瓶頸所在,然後解決它;
其實不只是資料庫和 SQL,計算機世界裡容易成為效能瓶頸的也是對硬碟,也就是檔案系統的存取(因此可以通過增加記憶體,或者使用存取速度更快的硬碟等方法來提升效能)
不管是減少排序還是使用索引,亦或是避免臨時表的使用,其本質都是為了減少對硬碟的存取!
四 高斯資料庫特性為啥優異
首先,能釋放 CPU 多核心的計算資源
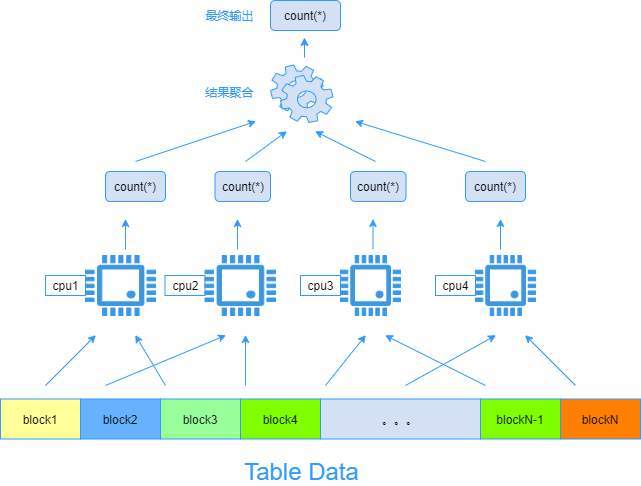
眾所周知,軟體計算能力的提升一方面得益於 CPU 硬體能力的增強,另一方面也得益於軟體設計層面能夠充分利用 CPU 的計算資源。當前處理器普遍採用多核設計,GaussDB (for MySQL) 單個節點最多可以支援 64 核的 CPU。單執行緒查詢的方式至多能用滿一個核的 CPU 資源,效能提升程度有限,遠遠無法滿足企業巨量資料量查詢場景下對降低時延的要求。因此,複雜的查詢分析型計算過程必須考慮充分利用 CPU 的多核計算資源,讓多個核參與到平行計算任務中才能大幅度提升查詢計算的處理效率;

下圖是使用 CPU 多核資源平行計算一個表的 count () 過程的例子:表資料進行切塊後分發給多個核進行平行計算,** 每個核計算部分資料得到一箇中間 count () 結果 **,並在最後階段將所有中間結果進行聚合得到最終結果
然後,是並行查詢
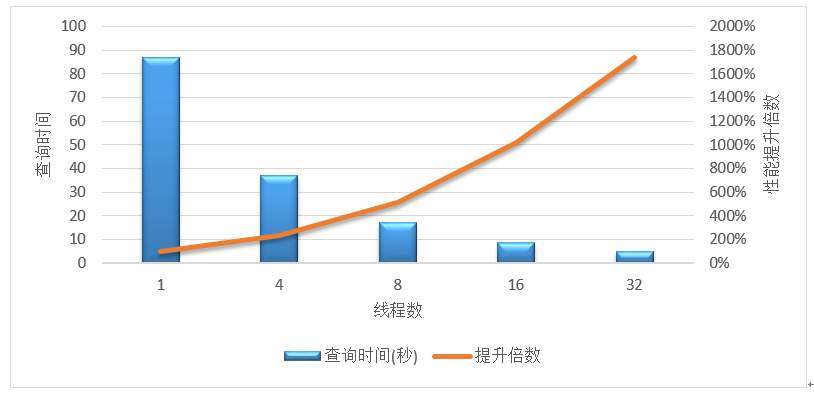
GaussDB (for MySQL) 支援並行執行的查詢方式,用於降低分析型查詢場景的處理時間,滿足企業級應用對查詢低時延的要求。如前面所述,並行查詢的基本實現原理是將查詢任務進行切分並分發到多個 CPU 核上進行計算,充分利用 CPU 的多核計算資源來縮短查詢時間。並行查詢的效能提升倍數,理論上與 CPU 的核數正相關,就是說並行度越高能夠使用的 CPU 核數就越多,效能提升的倍數也就越高;
下圖展示的是:在 GaussDB (for MySQL) 的 64U 範例上查詢 100G 資料量的 COUNT (*) 查詢耗時,不同的查詢並行度分別對應不同耗時,並行度越高對應的查詢耗時越短
它支援多種型別的並行查詢運算元,以滿足客戶各種不同複雜查詢場景。當前最新版本(2021-9)已經支援的並行查詢場景包括:
- 主鍵查詢、二級索引查詢
- 主鍵掃描、索引掃描、範圍掃描、索引等值查詢,索引逆向查詢
- 並行條件過濾(where/having)、投影計算
- 並行多表 JOIN(包括 HashJoin、NestLoopJoin、SemiJoin 等)查詢
- 並行聚合函數運算,包括 SUM/AVG/COUNT/BIT_AND/BIT_OR/BIT_XOR 等
- 並行表示式運算,包括算術運算、邏輯運算、一般函數運算及混合運算等
- 並行分組 group by、排序 order by、limit/offset、distinct 運算
- 並行 UNION、子查詢、檢視查詢
- 並行分割區表查詢
- 並行查詢支援的資料型別包括:整型、字元型、時間型別、浮點型等等
- 其他查詢
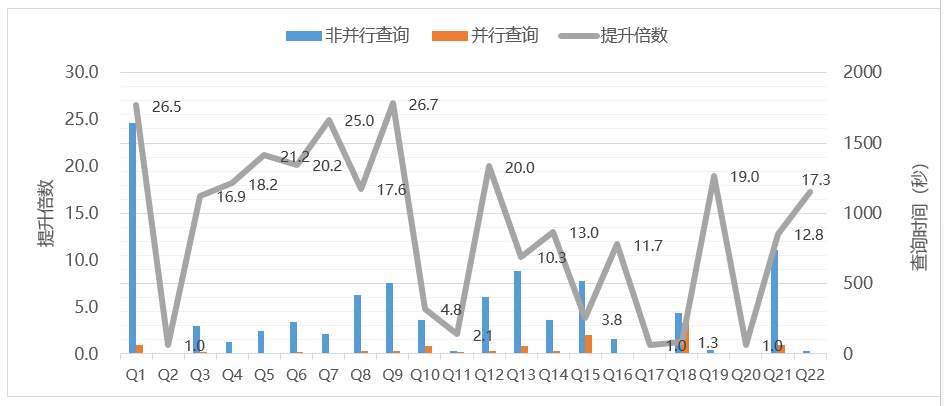
下圖是 GaussDB (for MySQL) 並行查詢針對 TPC-H 的 22 條查詢場景所做的效能測試結果,測試資料量為 100G,並行執行緒資料是 32。下圖展示了並行查詢相比傳統 MySQL 單執行緒查詢的效能提升情況:32 並行執行下,單表複雜查詢最高提升 26 倍效能,普遍提升 20 + 倍效能。多表 JOIN 複雜查詢最高提升近 27 倍效能,普遍提升 10 + 倍效能,子查詢效能也有較大提升;
總而言之
GaussDB (for MySQL) 並行查詢充分呼叫了 CPU 的多核計算資源,極大降低了分析型查詢場景的處理時間,大幅度提升了資料庫效能,可以很好的滿足客戶多種複雜查詢場景的低時延要求。