轉置折積
2022-09-14 06:02:45
一. 基本操作
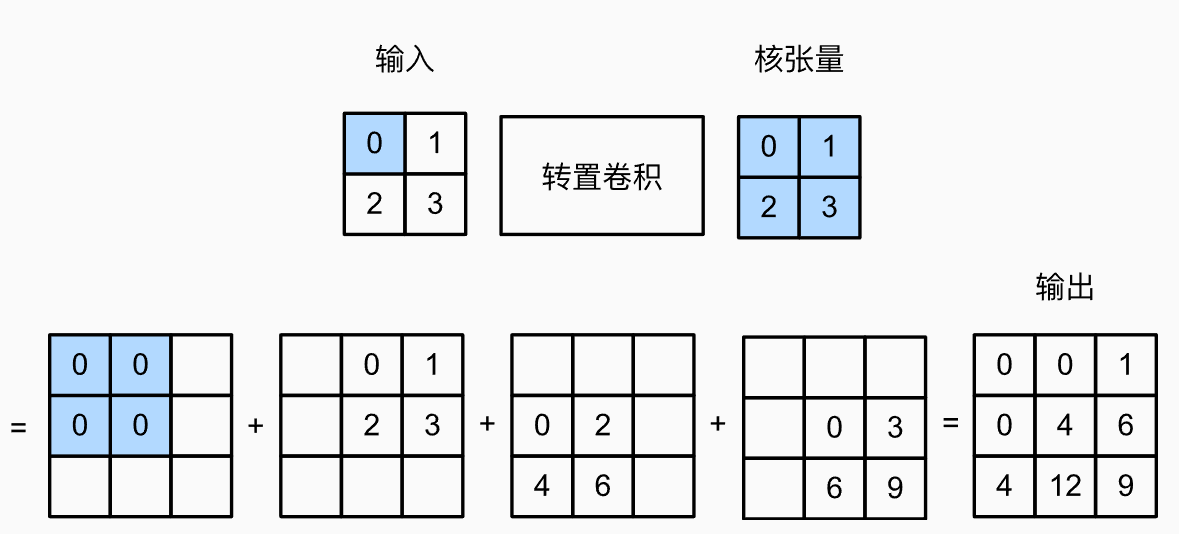
不同於一般的折積做的是多個元素->1個元素,轉置折積是從1個元素到多個元素
二. 填充、步幅和多通道
1. 填充
- 常規折積中padding是在輸入的外圈新增元素,轉置折積中的padding則是在輸出中刪除外圈的元素
x = torch.tensor([[0.0, 1.0], [2.0, 3.0]])
x = x.reshape(1, 1, 2, 2)
k = torch.tensor([[4.0, 7.0], [2.0, 2.0]])
k = k.reshape(1, 1, 2, 2)
tconv1 = nn.ConvTranspose2d(1, 1, kernel_size=2, padding=0, bias=False)
tconv1.weight.data = k
print(tconv1(x))
tconv2 = nn.ConvTranspose2d(1, 1, kernel_size=2, padding=1, bias=False)
tconv2.weight.data = k
print(tconv2(x))
Output:
tensor([[[[ 0., 4., 7.],
[ 8., 28., 23.],
[ 4., 10., 6.]]]], grad_fn=<ConvolutionBackward0>)
tensor([[[[28.]]]], grad_fn=<ConvolutionBackward0>)
2. 步幅
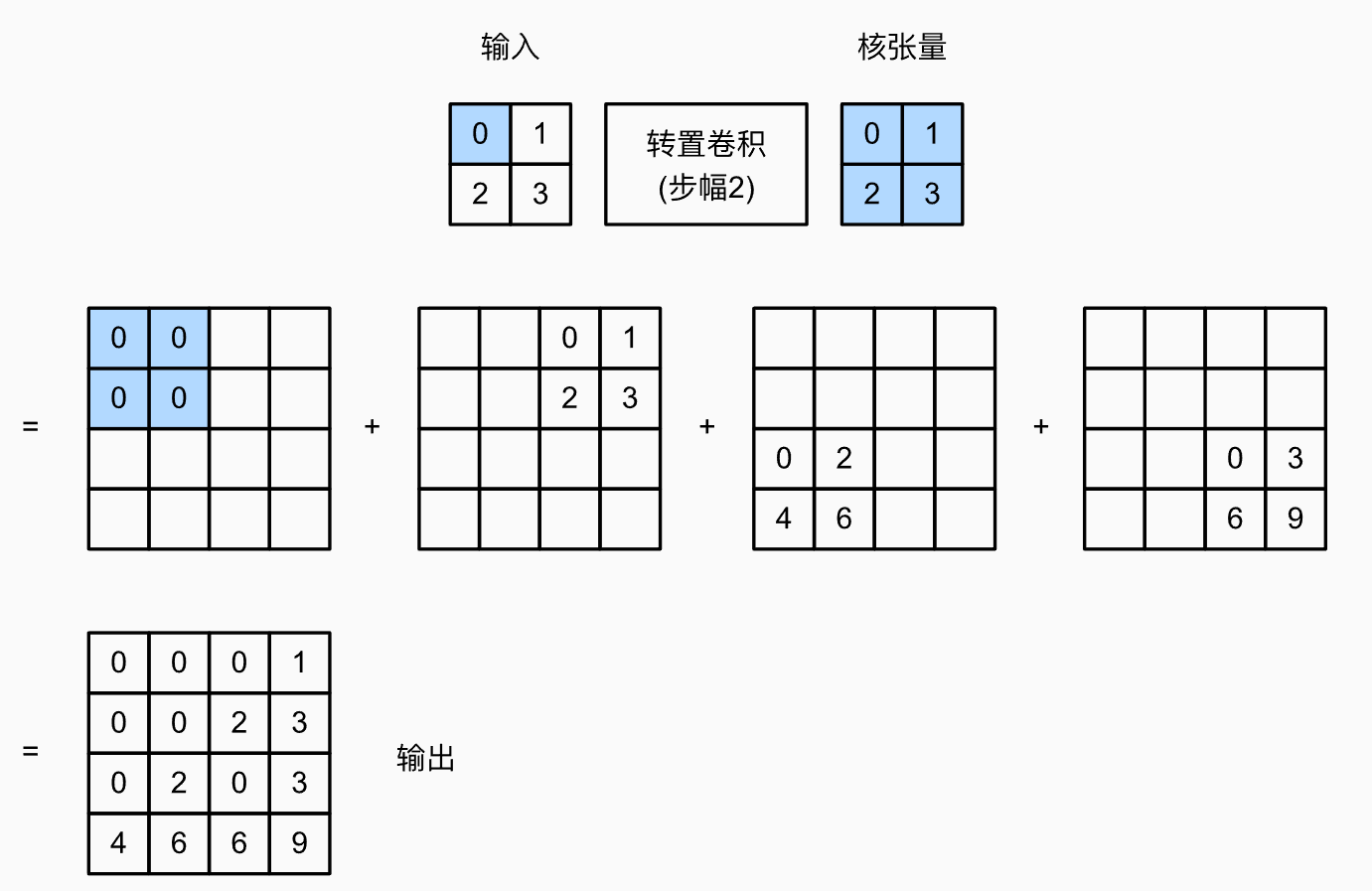
- 步幅這裡指的是每一個畫素擴充套件出的的輸出的擺放方式。
x = torch.tensor([[0.0, 1.0], [2.0, 3.0]])
x = x.reshape(1, 1, 2, 2)
k = torch.tensor([[4.0, 7.0], [2.0, 2.0]])
k = k.reshape(1, 1, 2, 2)
tconv1 = nn.ConvTranspose2d(1, 1, kernel_size=2, stride=4, bias=False)
tconv1.weight.data = k
print(tconv1(X))
Output:
tensor([[[[ 0., 0., 0., 0., 4., 7.],
[ 0., 0., 0., 0., 2., 2.],
[ 0., 0., 0., 0., 0., 0.],
[ 0., 0., 0., 0., 0., 0.],
[ 8., 14., 0., 0., 12., 21.],
[ 4., 4., 0., 0., 6., 6.]]]], grad_fn=<ConvolutionBackward0>)
3. 多通道
nn.ConvTranspose2d(2, 1, kernel_size=2, bias=False)指的是用1個\(2*2*2\)的折積核做轉置折積。
x = torch.tensor([[[0, 1.0], [2.0, 3.0]],
[[4, 5], [7, 8]]])
x = x.reshape(1, 2, 2, 2)
k = torch.tensor([[[0.0, 1.0], [2.0, 3.0]],
[[4, 5], [2, 3]]])
k = k.reshape(2, 1, 2, 2)
tconv3 = nn.ConvTranspose2d(2, 1, kernel_size=2, bias=False)
tconv3.weight.data = k
print(x)
print(k)
print(tconv3(x))
print(tconv3(x).shape)
Output:
tensor([[[[0., 1.],
[2., 3.]],
[[4., 5.],
[7., 8.]]]])
tensor([[[[0., 1.],
[2., 3.]]],
[[[4., 5.],
[2., 3.]]]])
tensor([[[[16., 40., 26.],
[36., 93., 61.],
[18., 49., 33.]]]], grad_fn=<ConvolutionBackward0>)
torch.Size([1, 1, 3, 3])
- 下面分析下為啥是這個結果
原圖中第一個畫素的擴充套件方式為:
\[0*
\begin{matrix}
0 & 1 \\
2 & 3 \\
\end{matrix}
+4*
\begin{matrix}
4 & 5 \\
2 & 3 \\
\end{matrix}
=
\begin{matrix}
16 & 20\\
8 & 12\\
\end{matrix}
\]
其他畫素點的展開方式也是同樣的。
轉置折積同樣遵循用幾個折積核輸出幾個通道的原則。
三. 轉置折積與普通折積的形狀互逆操作
只需要把Conv和ConvTranspose的kernel,padding,stride引數指定成一樣的即可。
X = torch.rand(size=(1, 10, 16, 16))
conv = nn.Conv2d(10, 20, kernel_size=5, padding=2, stride=3)
tconv = nn.ConvTranspose2d(20, 10, kernel_size=5, padding=2, stride=3)
tconv(conv(X)).shape == X.shape
Output:
True
本文來自部落格園,作者:SXQ-BLOG,轉載請註明原文連結:https://www.cnblogs.com/sxq-blog/p/16689306.html