走進Redis-扯扯叢集
叢集
為什麼需要切片叢集
已經有了管理主從叢集的哨兵,為什麼還需要推出切片叢集呢?我認為有兩個比較重要的原因:
- 當 Redis 上的資料一直累積的話,Redis 佔用的記憶體會越來越大,如果開啟了持久化功能或者主從同步功能,Redis fork 子程序來生成 RDB 檔案的時候阻塞主執行緒的概率會大大增加。
- 哨兵叢集中 Redis 是由哨兵中心化管理的,如果哨兵叢集出問題了,比如有超過
N/2+1個哨兵下線,並且此時主庫宕機了,哨兵會無法正常選舉出新的主庫。
下面來聊聊 Redis cluster 是如何解決這兩個問題的。
什麼是切片叢集
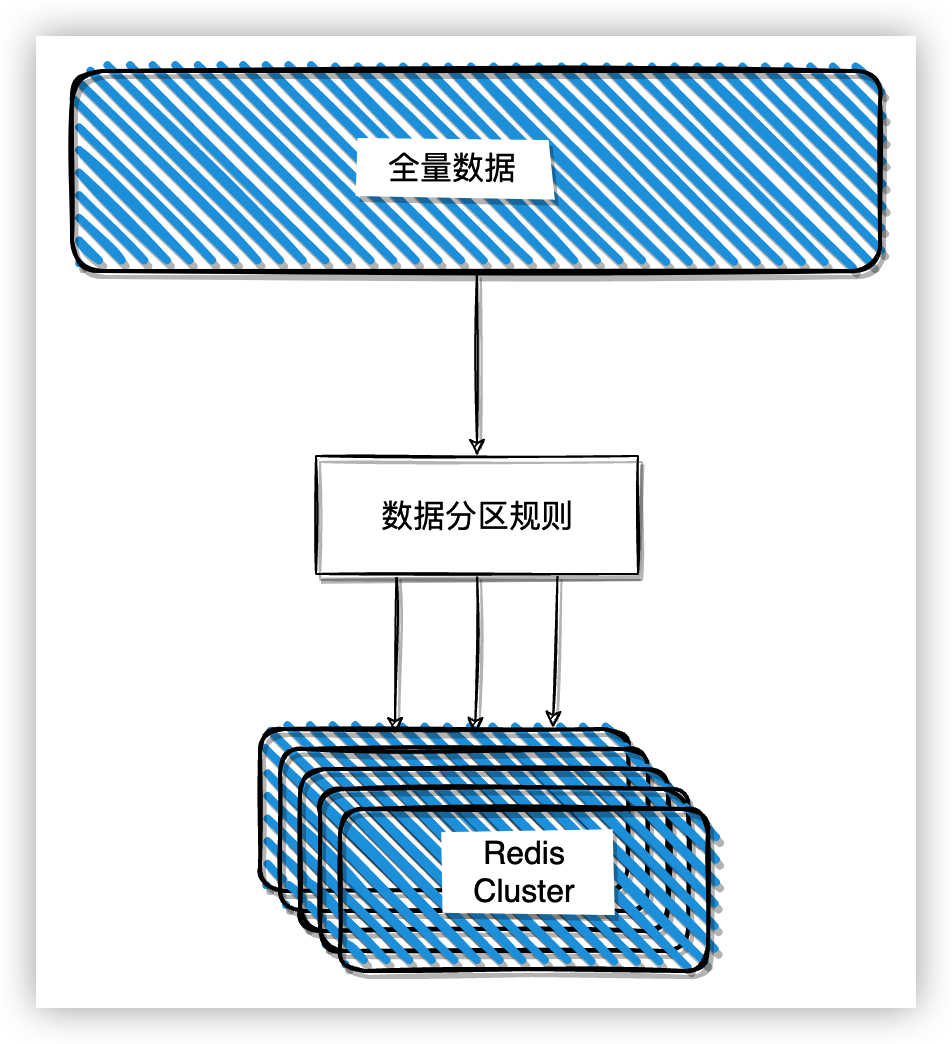
切片叢集是一種水平擴充套件的技術方案,它的主體思想是增加 Redis 範例組成叢集,將原來儲存在單個範例的上資料切片按照某種演演算法分散在各個不同的範例上,以減輕單個範例資料過大時同步和持久化時的壓力。同時,水平擴充套件方案和垂直擴充套件方案相比擴充套件性更強,受硬體和成本的影響更小。
目前主要的實現方案有官方的 Redis Cluster 和 第三方的 Codis。Codis 在官方的 Redis Cluster 成熟之後已經很久沒有更新了,這裡就不特別介紹了,主要介紹下 Redis Cluster 的實現。
資料分割區
切片叢集實際就是一個分散式的資料庫,而分散式資料庫首先要解決的問題就是如何把整個資料集劃分到多個節點上。
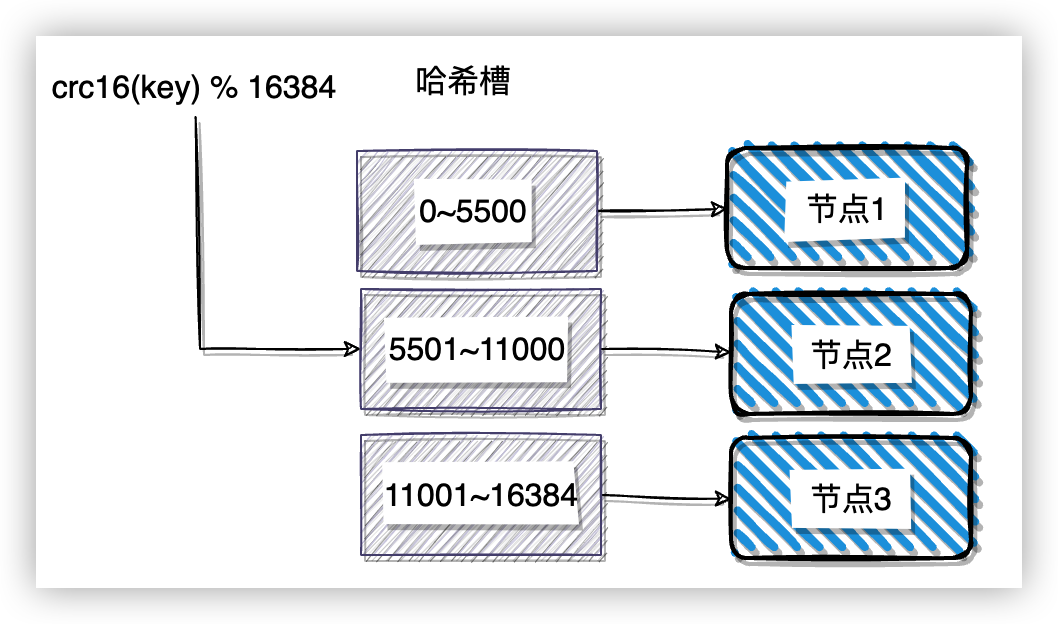
Redis Cluster 採用的是虛擬槽的分割區技術。Redis Cluster 一共定義了 16384 個槽,資料與槽關聯,而不是和實際的節點關聯,這樣可以很好的將資料和節點解耦,方便資料拆分和叢集擴充套件。通常情況下,Redis 會將槽平均分配到節點上,使用者可以使用命令 cluster addslots 來手動分配。需要注意的是,手動分配雜湊槽時必須要把 16384 個槽都分配完,否則 Redis 叢集會無法運作。
對映到節點的流程有兩步:
- 根據 key 計算一個 16 bit 的值,然後將這個值對 16384 取模,得到 key 應該落在哪個槽上: crc16(key) % 16384。
- Redis Cluster 搭建完成的時候會預先分配每個節點負責哪幾個槽的資料,使用者端連線到叢集的時候會獲取到對映關係,然後使用者端會將資料傳送到對應的節點上。
功能限制
叢集功能目前有一些功能限制:
- mset、mget 等批次操作、事務操作,lua 指令碼只支援對落在同一個 slot 上 key 進行操作。
- 叢集只能使用一個 db0,而不像單機 Redis 可以支援 16 個 db。
- 主從複製不支援聯級主從複製,即從庫只能從主庫同步資料。
雜湊標籤(hash tag)
為了解決上述的第一個問題,Redis Cluster 提供了雜湊標籤(hash tag)功能,例如有兩條 Redis 命令:
set Hello world
set Hello1 world
這兩個操作的 key 可能不會落在同一個槽上。這時候如果將 Hello1 改成 {Hello}1,Redis就會只計算被{}包圍的字串屬於那個槽,這樣這兩個命令的 key 就會落在同一個槽上,就可以使用 mset、事務、lua 指令碼來處理了。
可以使用命令 cluster keyslot <key> 來驗證兩個 key 是否落在同一個槽上。
127.0.0.1:30001> cluster keyslot hello
(integer) 866
127.0.0.1:30001> cluster keyslot hello1
(integer) 11613
127.0.0.1:30001> cluster keyslot {hello}1
(integer) 866
請求重定向
如果沒有使用雜湊標籤,如果 Redis 命令中 key 計算之後的雜湊值不是落在當前節點持有的槽內,節點會返回一個 MOVED 錯誤,告訴使用者端該操作應該在哪個節點上執行:
127.0.0.1:30006> set hello1 world
(error) MOVED 11613 127.0.0.1:30003
127.0.0.1:30006>
節點是不會處理請求轉發的功能,我們啟動 redis-cli 的時候可以新增一個 -c 引數,這樣,redis-cli 就會幫我們轉發請求了,而不是返回一個錯誤:
$ redis-cli -p 30006 -c
127.0.0.1:30006> set hello1 world
-> Redirected to slot [11613] located at 127.0.0.1:30003
OK
ACK重定向
當叢集進行伸縮重新分配槽的時候,如果有請求需要處理落在遷移中的槽上,那麼 Redis Cluster 會怎麼處理呢?
Redis 定義了一個結構 clusterState 來記錄原生的叢集狀態,其中有幾個成員來記錄槽的資訊:
typedef struct clusterState {
...
clusterNode *migrating_slots_to[CLUSTER_SLOTS]; //記錄槽轉移的目標節點
clusterNode *importing_slots_from[CLUSTER_SLOTS]; //記錄槽轉移的源節點
clusterNode *slots[CLUSTER_SLOTS]; //記錄叢集中槽所屬的節點
...
} clusterState;
當開始重新分配槽時,擁有槽的原節點會將目標節點記錄到 migrating_slots_to 中,目標節點會將原節點資訊記錄到 importing_slots_from 中,重分配槽的過程中,槽的擁有者還是原節點。
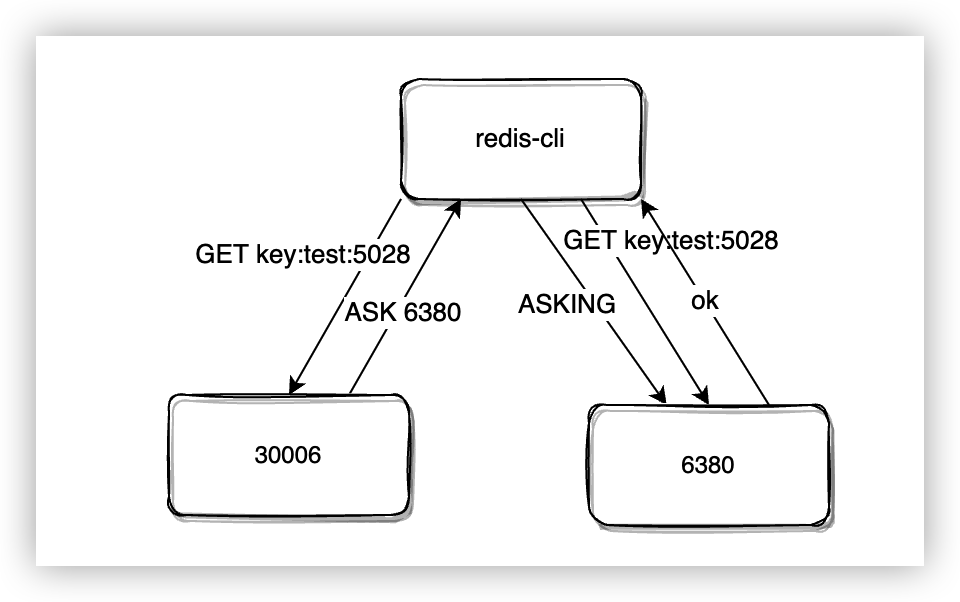
此時原節點收到操作命令時,如果在本地找不到資料,會在 migrating_slots_to 中找到目標節點資訊,然後返回 ACK 重定向來告訴使用者端對應的資料正在遷移到目標節點。
$ redis-cli -p 6380 -c get key:test:5028
(error) ASK 4096 127.0.0.1:6380
收到 ACK 之後,不像 MOVED 錯誤一樣直接到對應的節點上執行命令就可以了,首先需要傳送一個 ASKING,然後再傳送實際的命令。這是因為在重分配槽的過程中,槽的所有者還沒有發生改變,如果直接向目標節點傳送命令,目標節點會直接返回 MOVED 錯誤,因為目標節點在原生的 clusterState→slots 中並沒有發現 key 所屬的槽分配給了自己。
需要注意的是 ASKING 命令是臨時的,收到 AKSING 命令後會開啟 CLIENT_ASKING(askingCommand 函數),執行完命令後會將 CLIENT_ASKING 狀態清除(resetClient函數)。
實驗
在搭建好的叢集中,插入 3 條資料:
mset key:test:5028 world key:test:68253 world key:test:79212 world
這三個 key 都落在槽 4096 上。我們在叢集中加入一個新節點 6380,準備將槽 4096 的資料遷移到 6380 節點上:
redis-cli -p 6380 cluster setslot 4096 importing 750c1ac1e53b8e33da160e7e925be98a37c8b1f3
redis-cli -p 30006 cluster setslot 4096 migrating 8557dbdfdb08a9a939cf526d74d7e35e0dc4b478
importing 命令在 6380 上執行,指定 4096 槽的原節點的 runId,migrating 命令指定 6380 的 runId,runId 使用命令 cluster nodes 檢視。
然後將 key:test:5028 key:test:68253 先遷移到 6380 :
redis-cli -p 30006 migrate 127.0.0.1 6380 "" 0 5000 KEYS key:test:5028 key:test:68253
此時在 30006 上查詢 key:test:79212 的資料是可以正常返回的,而查詢其它兩個 key 都會返回錯誤:
(error) ASK 4096 127.0.0.1:6380
其它寫操作也都會返回這個錯誤。
然後在 6380 上執行 get key:test:5028 會返回 MOVED 錯誤,因為此時槽還沒有遷移完成,槽的擁有者還是 30006:
127.0.0.1:6380> get key:test:5028
(error) MOVED 4096 127.0.0.1:30006
需要先執行 ASKING 命令,在執行其它命令:
127.0.0.1:6380> asking
OK
127.0.0.1:6380> mget key:test:5028
"world"
smart 使用者端
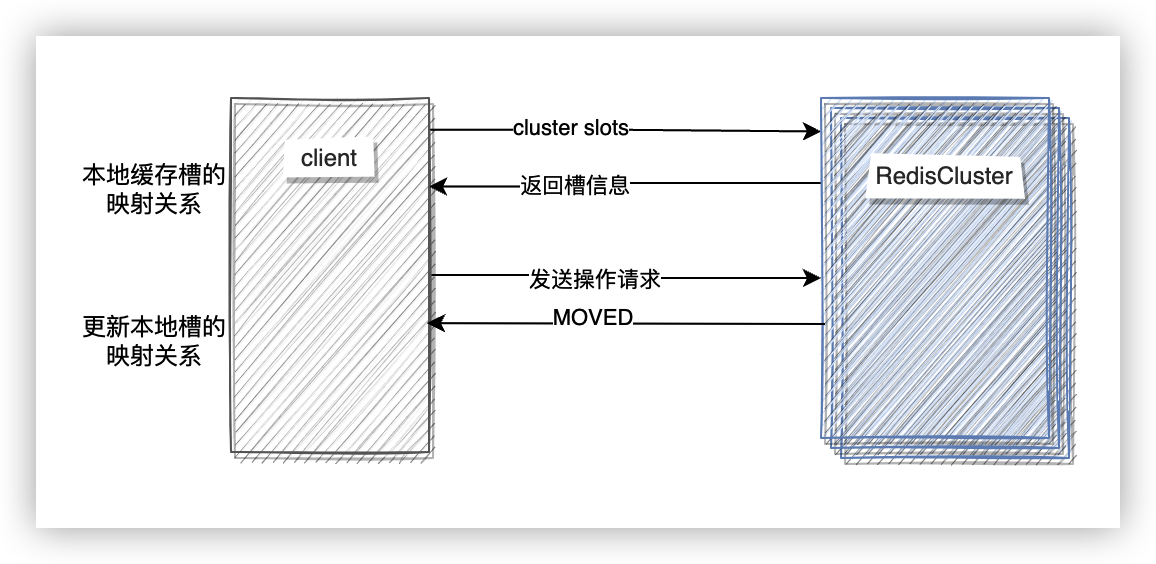
如果要求在往節點寫資料的時候重定向到實際執行命令的節點,想想都覺得這是一個比較低效的實現方式,並且增加了網路開銷。所以,通常 Redis 使用者端採用的實現方式是在本地快取一份槽和節點的對映關係,這個對映關係使用命令 cluster slots 可以獲取。在處理請求的時候,先根據原生的對映關係往對應節點傳送請求,如果收到的 MOVED 錯誤,使用者端會將資料傳送到正確的節點,並且更新原生的對映關係。
快速搭建叢集
Redis 原始碼裡附帶了一個指令碼可以快速搭建叢集,這個指令碼在 utils/create-cluster 目錄中。
這個指令碼要求把 redis 的原始碼拉到本地,編譯之後再執行。如果本地已經安裝了 redis ,並且不想編譯原始碼的可以用我改過的指令碼來模擬:
https://github.com/LooJee/examples/blob/main/docker-compose/redis-cluster/create-cluster。
-
啟動節點。使用命令
./create-cluster start來啟動節點,該指令碼會啟動 6 個節點。$ ./create-cluster start Starting 30001 Starting 30002 Starting 30003 Starting 30004 Starting 30005 Starting 30006使用 ls 命令檢視一下當前目錄,會發現主要生成了三種檔案:節點執行紀錄檔(
.log)、持久化檔案目錄(appendonlydir- )、叢集節點資訊檔案(nodes- .conf)。 -
建立叢集。使用命令
./create-cluster create會自動建立叢集關係。執行成功後,檢視叢集節點資訊檔案,會看到不同節點的角色,runId,ip,port,以及分配到該節點的槽範圍: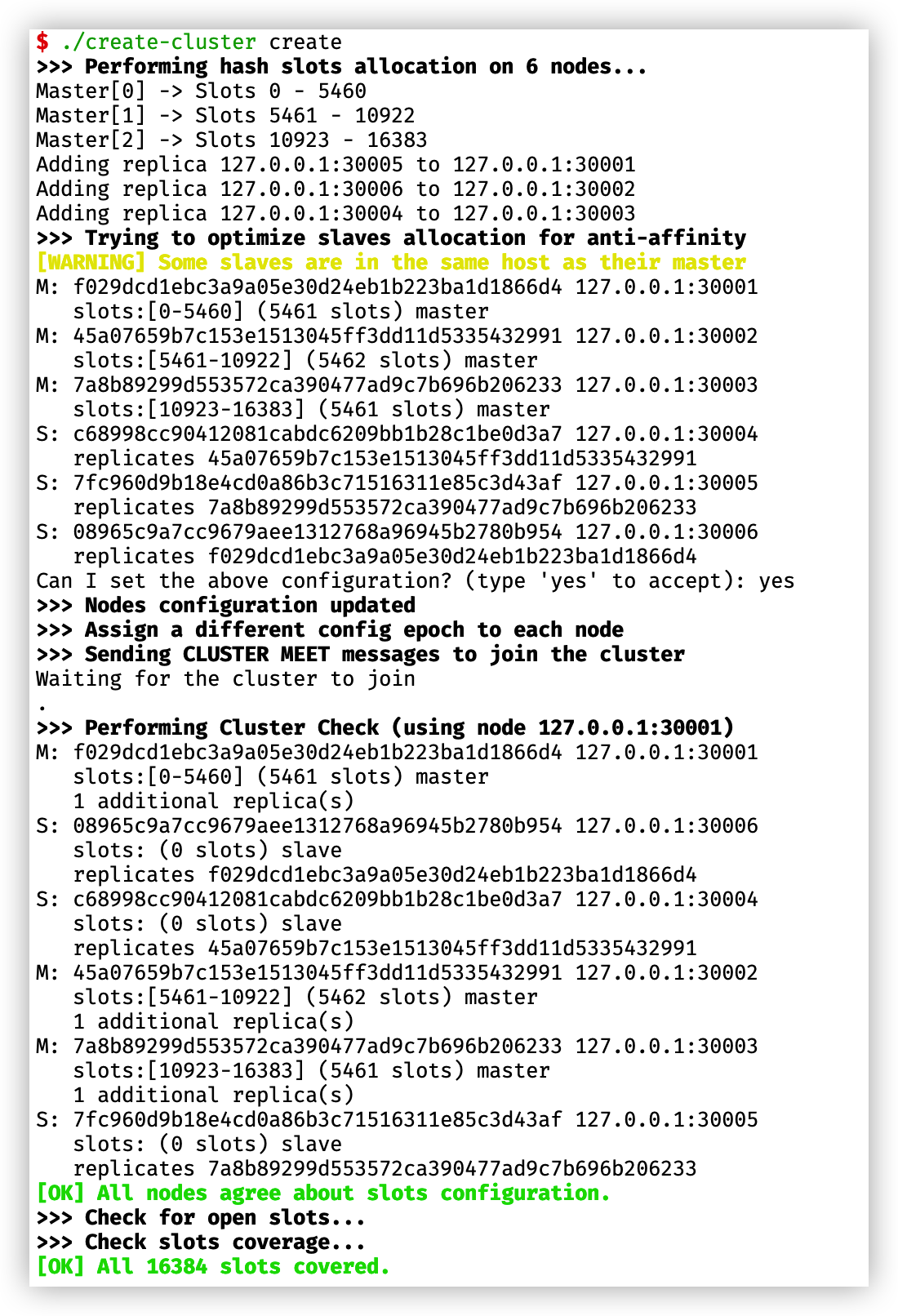
手動搭建叢集
官方的這個指令碼讓我們很快就能擁有一個可以測試的叢集,它把很多細節都隱藏起來了,我們來手動搭建一個叢集,順便理一下 Redis Cluster 到底做了哪些事情。
啟動節點
啟動一個叢集模式的節點需要在組態檔中開啟叢集模式:
cluster-enabled yes
在同一個機器上執行的話每個節點還要指定不同的埠,以及要指定節點資訊儲存檔案,這個檔案會儲存叢集的後設資料:
port 6382
cluster-config-file "nodes-6382.conf"
其它和叢集相關的設定可以檢視官方檔案,本文不做過多贅述。
先啟動三個主節點,組態檔可以從這裡獲取。
redis-server node-6380.conf
redis-server node-6381.conf
redis-server node-6382.conf
啟動的叢集節點會有兩個埠,一個埠是面向使用者端連線的(6379,下稱其為面向使用者埠),另個一埠會在該埠上加 10000 用作叢集內部通訊使用(16379,下稱其為面向匯流排介面)。可以使用命令 netstat -anp | grep redis-server 檢視應用程式的網路資訊:

節點握手
啟動的三個節點是相互獨立的叢集,那麼如何告知這三個節點對方的資訊,讓它們組成叢集呢?
- 通過使用者端傳送命令
cluster meet {ip} {port}告知當前節點與哪個節點建立叢集。 - 當前節點與目標面向匯流排埠建立 tcp 連線。
- 當前節點向目標節點傳送 meet 訊息,通知其有新節點加入叢集。
- 目標節點收到 meet 訊息後,返回 pong 訊息,pong 訊息中包含自身節點資訊。
- meet 訊息互動完後,目標節點會和當前節點另外建立一個 tcp 連線,然後傳送 ping 命令,ping 命令中包含自身節點及叢集內其它節點的狀態資料。
- 當節點收到 ping 訊息,如果 ping 中有新節點資訊,就會和新節點建立連線,然後和其進行資料互動。
- 之後兩個節點之間會定時用 ping、pong 訊息交換資訊。
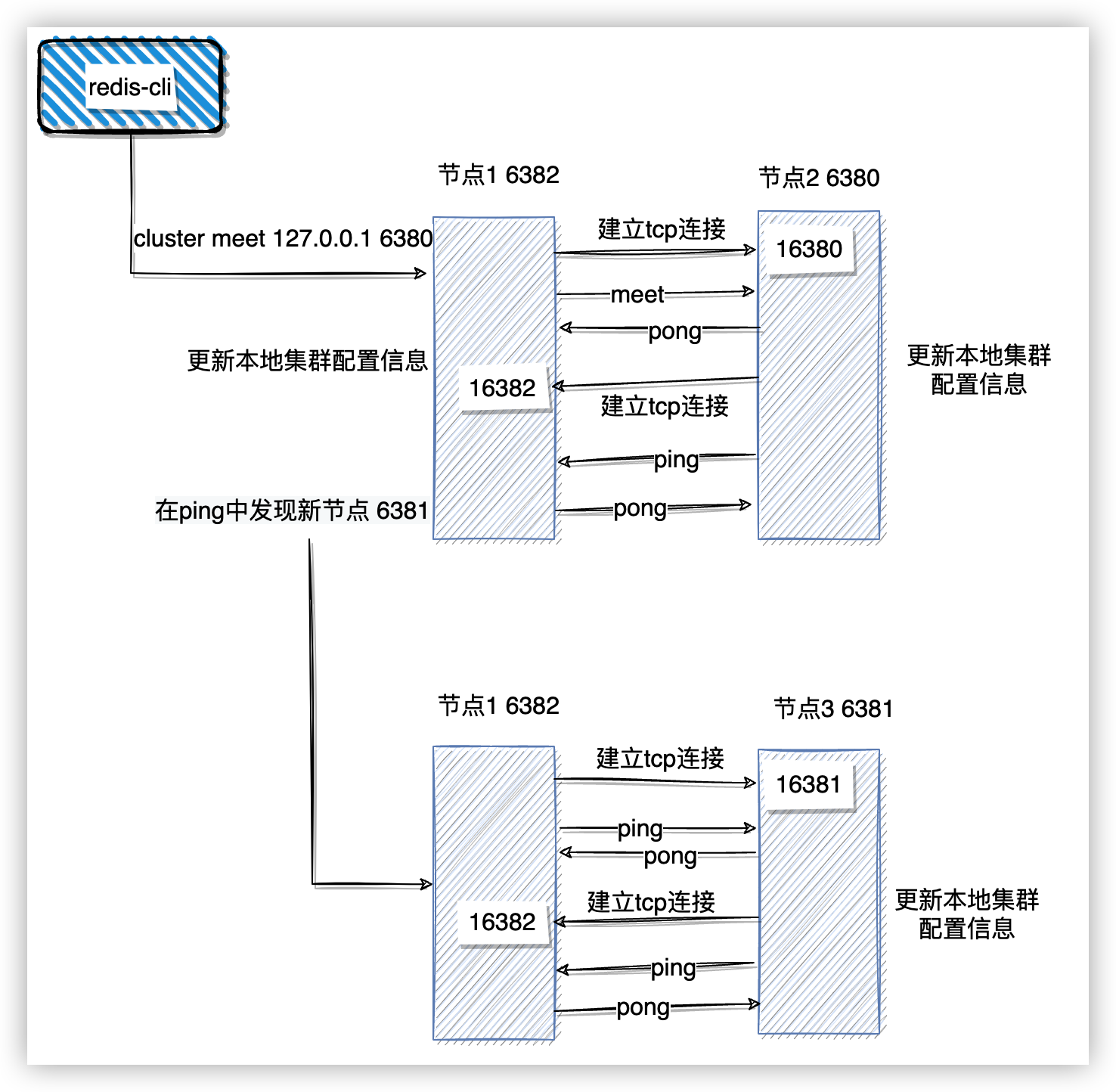
節點握手完成之後,使用命令 cluster nodes 檢視節點狀態:

欄位含義會在下面進行說明。
分配槽
節點握手之後還是不能工作的,使用命令 cluster info 檢視當前叢集狀態,會發現 cluster_state 欄位還是 fail 狀態。這時往 Redis 寫資料的時候也會提示叢集未開始正常服務。
127.0.0.1:6380> set hello world
(error) CLUSTERDOWN Hash slot not served
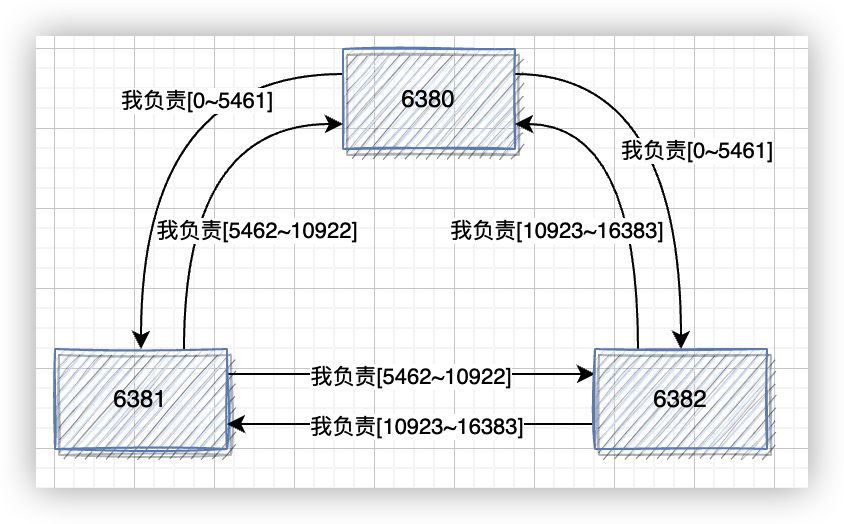
上面提到過,Redis 叢集把所有資料對映到 16384 個槽中,通過命令 cluster addslots 命令為節點分配槽:
redis-cli -h 127.0.0.1 -p 6380 cluster addslots {0..5461}
redis-cli -h 127.0.0.1 -p 6381 cluster addslots {5462..10922}
redis-cli -h 127.0.0.1 -p 6382 cluster addslots {10923..16383}
節點會在 PING 或者 PONG 訊息中帶上自己分配的槽資訊,這樣槽設定資訊就會擴散到整個叢集中。
Redis 把槽資訊儲存在陣列 myslots 中:
typedef struct {
...
unsigned char myslots[CLUSTER_SLOTS/8];
...
} clusterMsg;
CLUSTER_SLOTS 的值為 16384,計算之後得到 myslots 陣列的長度為 2048,myslots 等於是一個 bitmap,陣列的每一位代表一個槽的序號,節點在傳送訊息的時候會將自己擁有的槽對應的位設定為 1。例如,上面給 6380 節點分配的節點為 0 ~ 5461,那麼 myslots 的值會如下設定:
| 位元組 | myslots[0] | … | myslots[682] |
|---|---|---|---|
| 位 | 0 | 1 | |
| 值 | 1 | 1 |
這段程式碼是 Redis 計算每個槽應該落在 myslots 陣列哪一位的函數:
void bitmapSetBit(unsigned char *bitmap, int pos) { off_t byte = pos/8; int bit = pos&7; bitmap[byte] |= 1<<bit; }通過計算,大家會發現 Redis 在 myslots 中儲存值類似小端序的方式。例如,槽 7 經過計算後,byte 為 0,即儲存在 myslots[0] 上;bit 為 7 ,即 myslots[0] 的第七位為槽 7。myslots[682] 實際儲存的值會是 0x3f,而不是我們以為的 0xfc。
叢集中的節點並不需要都分配到槽,只要將槽都分配完成就可以正常工作了。分配完成之後,在執行命令 cluster info 會看到 cluster_state 已經是 ok 了,執行命令 cluster nodes 可以檢視當前槽的分配情況:

每個欄位的含義如下:
| 節點id | 即每個節點的runId,唯一的身份標識 |
|---|---|
| 節點ip和地址 | @左側的是面向使用者端埠,右側是面向叢集匯流排埠 |
| 節點角色 | master表示該節點為主庫,slave表示該節點為從庫,myself表示該節點是當前使用者端連線的節點 |
| 主庫id | 以為此時的節點都是主庫,所以顯示的是 - ,如果是從庫的話,這裡會顯示主庫的 runid |
| 傳送 PONG 訊息的時間 | 節點最近一次向其它節點傳送 PING 訊息時的時間戳,格式為毫秒,如果該節點與其它節點的連線正常,並且它傳送的 PING 訊息也沒有被阻塞,那麼這個值將設定為0 |
| 收到 PONG 訊息的時間 | 節點最近一次接收到其它節點傳送的 PONG 訊息時的時間戳,格式為毫秒。 |
| 設定紀元 | 節點所處的設定紀元 |
| 連線狀態 | 節點叢集匯流排的連線狀態。connected 表示連線正常,disconnected 表示連線已斷開 |
| 負責的槽 | 目前每個節點負責的槽。 |
分配從庫
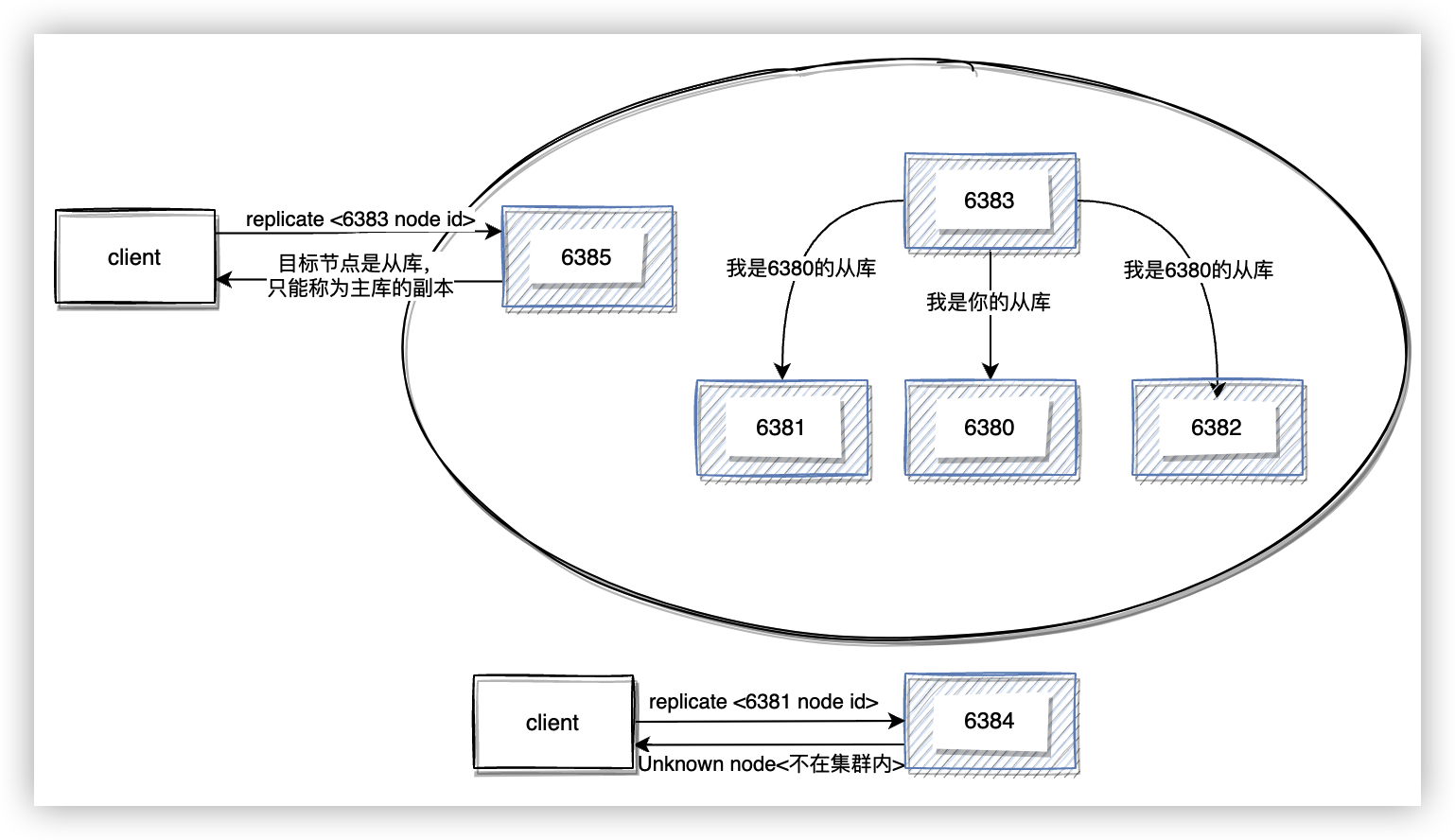
和單例服務一樣,切片叢集也可以通過分配從庫來增加叢集的可用性。通過命令 cluster replicate <node-id> 告訴當前節點與指定主庫 id 建立主從關係。
$ redis-cli -p 6383 cluster replicate 1a43101213e2a80cd2eca1468d2b6a3447059a8a
OK
$ redis-cli -p 6384 cluster replicate 1a43101213e2a80cd2eca1468d2b6a3447059a8a
(error) ERR Unknown node 1a43101213e2a80cd2eca1468d2b6a3447059a8a
分配從庫有幾點需要注意的:
- 收到建立主從關係的命令時,當前節點會檢查本地設定中目標節點是否是同一個叢集內的,如果不是一個叢集的會返回錯誤。
- 從庫只能掛在主庫上,而不能掛在另一個從庫上形成級聯從庫。
- replicate 命令執行成功後,主從關係會通過 gossip 訊息擴散到整個叢集。
檢查叢集狀態
都分配好之後,通過 check 子命令可以檢查叢集的設定是否正確,槽是否已全部分配:
$ redis-cli --cluster check 127.0.0.1:6380
127.0.0.1:6380 (1a431012...) -> 1 keys | 5462 slots | 1 slaves.
127.0.0.1:6381 (37b018c0...) -> 0 keys | 5461 slots | 1 slaves.
127.0.0.1:6382 (63f9cd0e...) -> 0 keys | 5461 slots | 1 slaves.
[OK] 1 keys in 3 masters.
0.00 keys per slot on average.
>>> Performing Cluster Check (using node 127.0.0.1:6380)
M: 1a43101213e2a80cd2eca1468d2b6a3447059a8a 127.0.0.1:6380
slots:[0-5461] (5462 slots) master
1 additional replica(s)
M: 37b018c0b4d8c5d9f13a56f6461b3f534de0003a 127.0.0.1:6381
slots:[5462-10922] (5461 slots) master
1 additional replica(s)
S: c0763947801dcf2292b6ce7678a60f84c4f13bc2 127.0.0.1:6385
slots: (0 slots) slave
replicates 63f9cd0ee52af85dad46088a0ed44f66a584f44c
M: 63f9cd0ee52af85dad46088a0ed44f66a584f44c 127.0.0.1:6382
slots:[10923-16383] (5461 slots) master
1 additional replica(s)
S: 64af469d5d2cab1a0730a865d4ac8bc53444191b 127.0.0.1:6384
slots: (0 slots) slave
replicates 37b018c0b4d8c5d9f13a56f6461b3f534de0003a
S: 8bb20a4da7577c39dbc025e0cdd58e9a51c26164 127.0.0.1:6383
slots: (0 slots) slave
replicates 1a43101213e2a80cd2eca1468d2b6a3447059a8a
[OK] All nodes agree about slots configuration.
>>> Check for open slots...
>>> Check slots coverage...
[OK] All 16384 slots covered.
叢集通訊
Redis Cluster 中,每個範例上都會儲存槽和範例的對應關係,以及自身的狀態資訊。Redis Cluster 會通過 gossip 協定,節點間彼此不斷通訊交換資訊,就像流言一樣,一段時間後所有的節點都會知道叢集的完整資訊。
工作原理
-
每個範例有一個定時任務
clusterCron,該定時任務會從叢集內隨機挑一些範例,給它們傳送 PING 訊息,用來檢測這些範例是否線上,並交換彼此的狀態資訊。挑選範例的邏輯有兩個:-
每過 1 秒隨機挑 5 個節點,找出最久沒有通訊的節點傳送 PING 訊息;
//clusterCron是每100毫秒呼叫一次,iteration每次呼叫加1, //所以等於是每秒選擇一個節點傳送PING訊息 if (!(iteration % 10)) { int j; /* Check a few random nodes and ping the one with the oldest * pong_received time. */ for (j = 0; j < 5; j++) { de = dictGetRandomKey(server.cluster->nodes); clusterNode *this = dictGetVal(de); /* Don't ping nodes disconnected or with a ping currently active. */ if (this->link == NULL || this->ping_sent != 0) continue; if (this->flags & (CLUSTER_NODE_MYSELF|CLUSTER_NODE_HANDSHAKE)) continue; if (min_pong_node == NULL || min_pong > this->pong_received) { min_pong_node = this; min_pong = this->pong_received; } } if (min_pong_node) { serverLog(LL_DEBUG,"Pinging node %.40s", min_pong_node->name); clusterSendPing(min_pong_node->link, CLUSTERMSG_TYPE_PING); } } -
找出最後一次通訊時間大於
cluster_node_timeout / 2的節點;//每次收到 if (node->link && node->ping_sent == 0 && (now - node->pong_received) > server.cluster_node_timeout/2) { clusterSendPing(node->link, CLUSTERMSG_TYPE_PING); continue; }
-
-
範例收到 PING 訊息後,會回覆一個 PONG 訊息。
-
PING 和 PONG 訊息中都包含範例自身的狀態資訊、1/10 其它範例的狀態資訊(至少3個)以及槽的對映資訊。
通訊開銷
gossip 訊息體的定義如下:
typedef struct {
char nodename[CLUSTER_NAMELEN]; //40位元組
uint32_t ping_sent; //4位元組
uint32_t pong_received; //4位元組
char ip[NET_IP_STR_LEN]; //46位元組
uint16_t port; //2位元組
uint16_t cport; //2位元組
uint16_t flags; //2位元組
uint32_t notused1; //4位元組
} clusterMsgDataGossip;
可以看到一個訊息體的大小為 104 個位元組。每次傳送訊息時還會帶上 1 / 10 的節點資訊,如果按照官方限制的叢集最大節點數 1000 來計算,每次傳送的訊息體大小為 10400 個位元組。clusterCron 是每 100 毫秒執行一次,每個範例每秒發出的訊息為 104000 個位元組。定時任務中還會給超時未通訊的節點傳送 PING 訊息,假設每次定時任務有 10 個節點超時,那麼每個節點每秒總的訊息大小為 1M 多。當叢集節點數較多時,通訊開銷還是很大的。
為了減少通訊開銷,我們可以做如下操作:
- 需要避免過大的叢集,必要時可以將一個叢集根據業務拆分成多個叢集。
- 適當調整 cluster_node_timeout 的值,減少每次定時需要傳送的訊息數。
故障轉移
故障發現
Redis Cluster 也通過主觀下線(pfail)和客觀下線(fail)來識別叢集中的節點是否發生故障。叢集中每個節點定時通過 PING、PONG 來檢查叢集中其它節點和自己的通訊狀態。當目標節點和自己在超過 cluster-node-timeout 時間內未成功通訊,那麼當前節點會將該節點狀態標記為主觀下線。相關程式碼在 clusterCron 函數中:
mstime_t node_delay = (ping_delay < data_delay) ? ping_delay :
data_delay;
if (node_delay > server.cluster_node_timeout) {
/* Timeout reached. Set the node as possibly failing if it is
* not already in this state. */
if (!(node->flags & (CLUSTER_NODE_PFAIL|CLUSTER_NODE_FAIL))) {
serverLog(LL_DEBUG,"*** NODE %.40s possibly failing",
node->name);
//將目標節點狀態標記為pfail
node->flags |= CLUSTER_NODE_PFAIL;
update_state = 1;
}
}
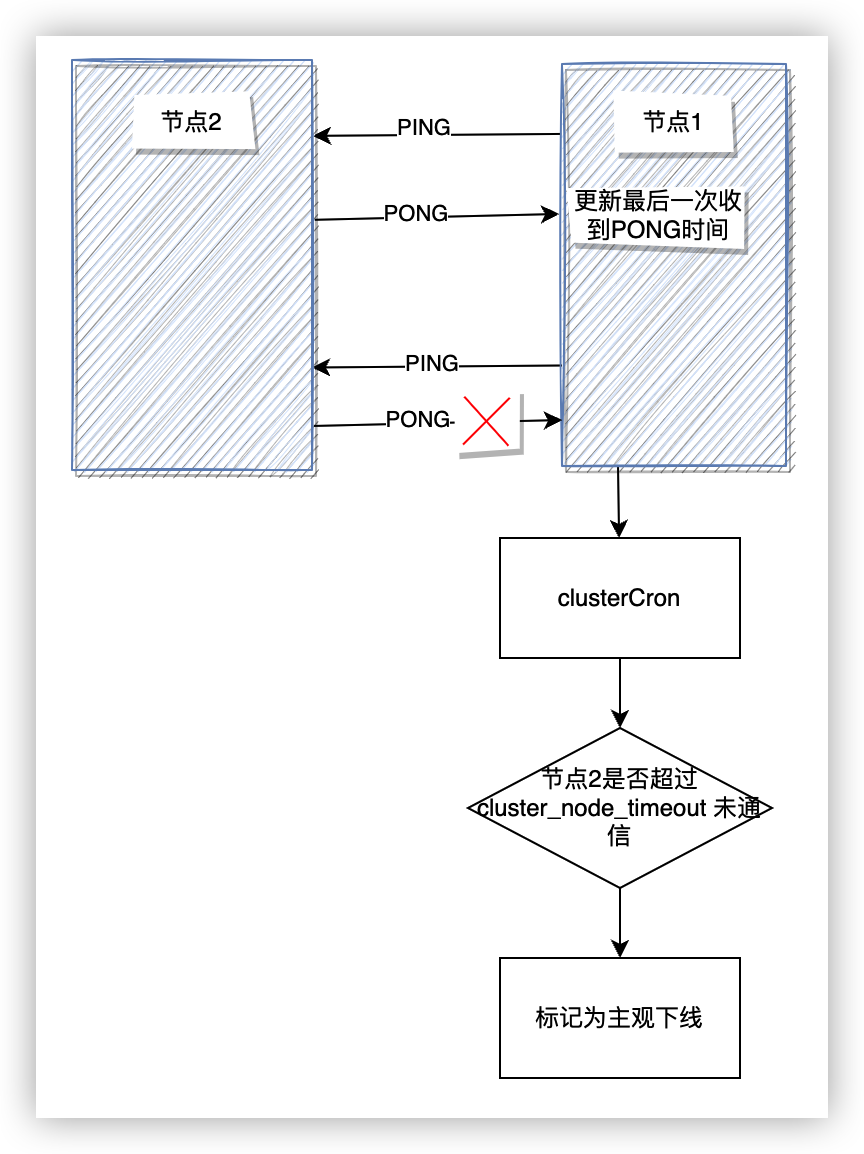
每個節點通過結構clusterNode 來儲存叢集節點資訊,該結構中的 fail_reports 欄位記錄了其它報告該節點主觀下線的節點,flags 欄位維護目標節點的狀態。
typedef struct clusterNode {
...
int flags; //記錄節點當前狀態
...
list *fail_reports; //記錄主觀下線的節點
} clusterNode;
Redis Cluster 處理主觀下線→客觀下線的流程如下:
- 當一個節點被標記為主觀下線後,它的狀態會隨著 PING 訊息在叢集內傳播。
- 收到有其它節點報告該節點主觀下線時,會先將 fail_reports 中部分上報時間大於
cluster_node_timeout * 2的節點清除,然後計算當前有多少節點上報主觀下線。 - 當叢集內有超過一半的持有槽節點報告節點主觀下線,將節點標記為客觀下線。
- 將客觀下線狀態廣播到叢集中。
- 觸發故障恢復流程。
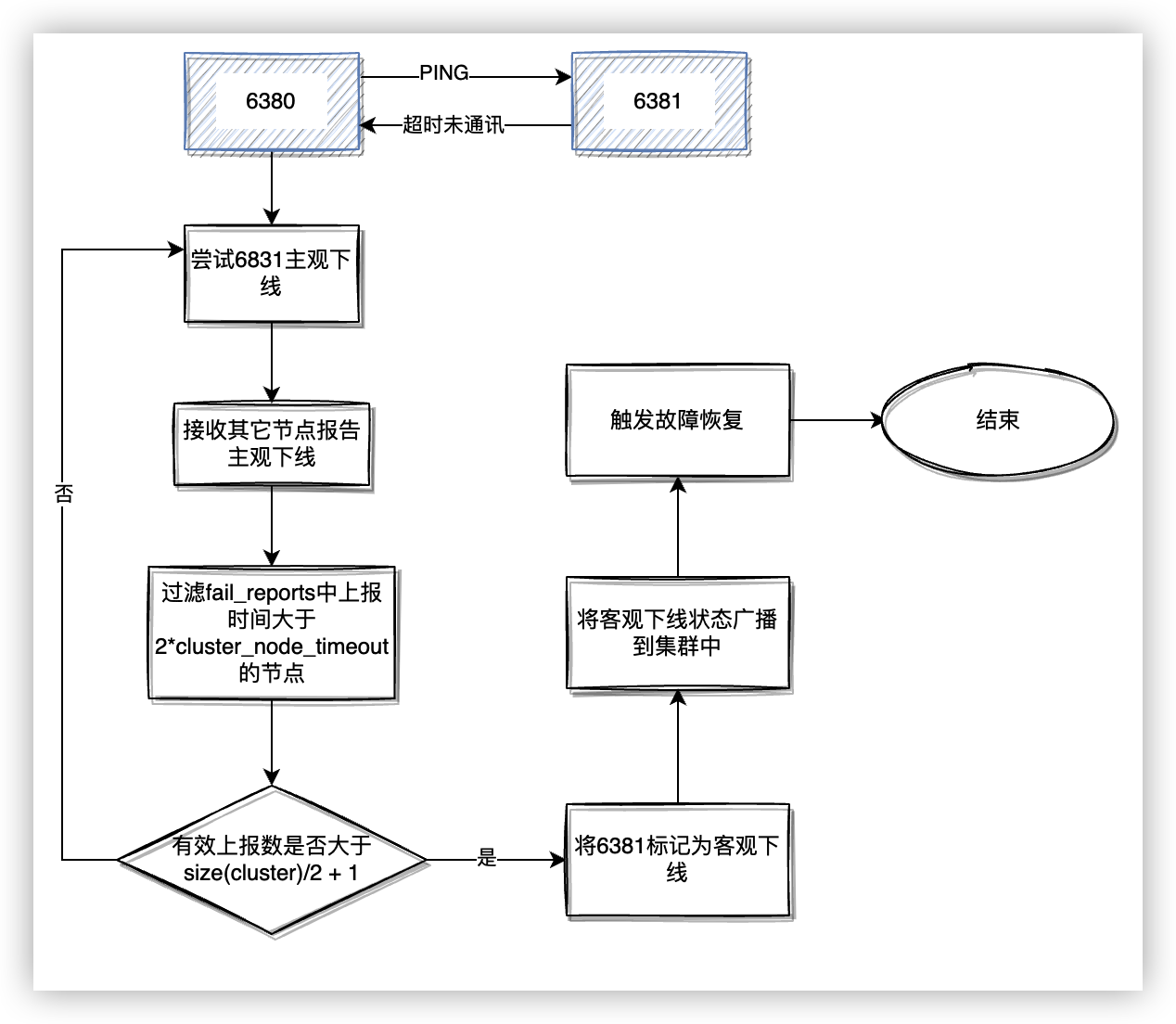
故障恢復
故障節點變為客觀下線後,如果下線節點是持有槽的主節點,那麼它的從節點就會參與競選主節點,承擔故障恢復的義務。在定時任務 clusterCron 中會呼叫 clusterHandleSlaveFailover 來檢測到主節點的狀態是否是客觀下線,如果是客觀下線就會嘗試故障恢復。
篩選
- 從節點的設定引數
cluster-replica-no-failover設定為 true 的時候,該節點會只作為從節點存在,失去競選主節點的機會。 - 過濾與主節點斷線時間過大的。
- 首先會獲取時間基準,有兩種情況:當從節點的副本狀態(
repl_state)還是連線狀態(REPL_STATE_CONNECTED),會使用和主節點的最後通訊時間;否則,從節點會使用斷線時間。 - 獲取時間基準後,會用當前時間減去時間基準,如果結果大於
cluster_node_timeout,會將結果減去cluster_node_timeout(等於是從節點判斷主節點主觀下線後的時間開始計算?)最終得到data_age。 - 最後將
data_age和cluster-slave-validity-factor*cluster_node_timeout+repl_ping_slave_period比較,如果較大,則會失去競選主節點的機會。 - 當
cluster-slave-validity-factor設定為 0 的時候,會直接進行下一步。
- 首先會獲取時間基準,有兩種情況:當從節點的副本狀態(
選舉
-
準備選舉時間。從節點通過篩選之後不會立刻發起選舉,而是會先確定一個選舉的開始時間。 這主要是為了讓主從副本進度最接近原主節點的從節點優先發起選舉,以及讓原主節點的
Fail狀態有足夠的時間在叢集內傳播。選舉時間會有一個固定的基準時間(
failover_auth_time = mstime()+500+random()%500),然後從節點根據主節點下所有從節點的副本進度決定排名(fail_over_rank),根據排名決定選舉延遲時間(failover_auth_time += fail_over_rank * 1000)。同時,副本進度會通過廣播傳送給所有相同主節點下的從節點,讓它們更新排名。 -
傳送選舉請求。當選舉時間到了之後,當前節點將叢集的設定紀元(
clusterState.currentEpoch)加 1,然後再叢集內廣播選舉訊息(訊息型別為CLUSTERMSG_TYPE_FAILOVER_AUTH_REQUEST)。叢集內的節點收到拉票訊息後,會進行以下判斷:- 如果自己不是持有槽的主節點,放棄選舉。
- 如果自己已經在當前紀元(
lastVoteEpoch)投過票,則不處理請求。 - 判斷傳送訊息的節點是否是從節點,以及它的主節點是否確實是已經下線。
- 針對某個主節點的故障轉移,每個節點在
cluster_node_timeout * 2的時間段內建會投票一次。 - 申請故障轉移的訊息中會攜帶節點持有的槽,節點會一次檢查槽的原持有者的設定紀元是否小於等於訊息中攜帶的新設定紀元。如果有槽持有者的設定紀元大於當前訊息中攜帶的紀元,則表示可能有管理者對槽進行了重新分配,當前節點會拒絕本次選舉請求。
當以上檢查都通過的時候,當前節點會有一下幾個操作:
- 記錄投票紀元((
lastVoteEpoch)。 - 記錄給本次故障節點的投票時間(
sender→slaveof→voted_time)。 - 應答本次故障轉移請求(
clusterSendFailorAuth)。
-
替換主節點。從節點收到應答後,會將
failover_auth_count加 1,當該值大於叢集中持有槽的主節點數的一半時(failover_auth_count > cluster→size / 2 + 1),會開始替換主節點流程(clusterFailoverReplaceYourMaster):- 首先會將自己提升為主節點,然後停止向原主節點的副本同步操作。
- 將原主節點持有的槽轉交給自己負責。
- 更新叢集狀態資訊。
- 廣播訊息,通知叢集內其它節點自己當選為新的主節點。
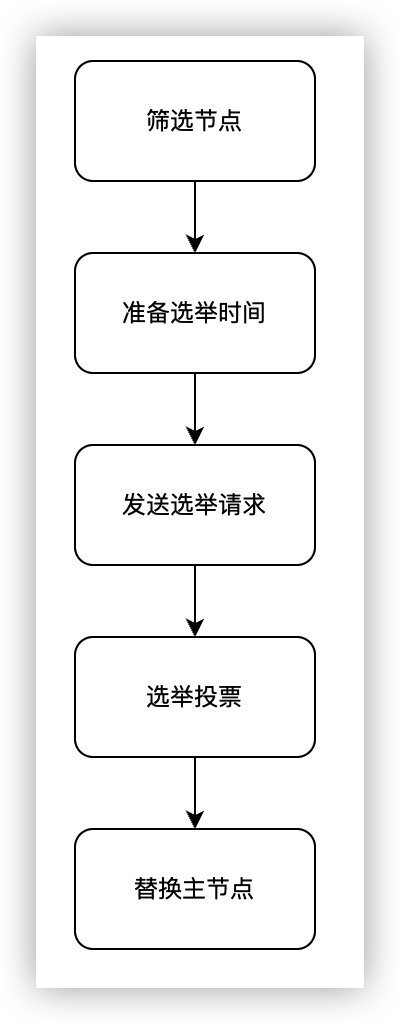
實驗
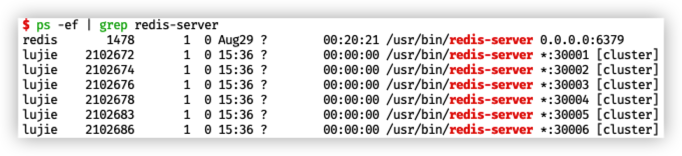
準備一個簡單的 Redis Cluster,可以使用 快速搭建叢集 中提到的方法搭建一個叢集。這時候會得到一個 3 主庫,3 從庫的叢集。使用命令 ps -ef | grep redis-server 來檢視範例是否都已經執行:
然後使用命令 redis-cli -p 30001 cluster nodes 檢視叢集內主從節點的分配和槽的分配:

模擬節點下線可以使用命令 kill 來實現,這裡讓節點 30001 下線,上面使用 ps 命令看到 30001 的程序id 為 2102672,使用命令 kill -9 2102672 殺死 30001 程序。這時用 redis-cli -p 30002 cluster nodes 命令檢視叢集節點資訊:

我們可以看到 30001節點的狀態為客觀離線(fail),30001 原來的從節點 30006 通過選舉成為了新的主節點。我們可以看下 30006 的紀錄檔,看看這個過程,vim 30006.log :
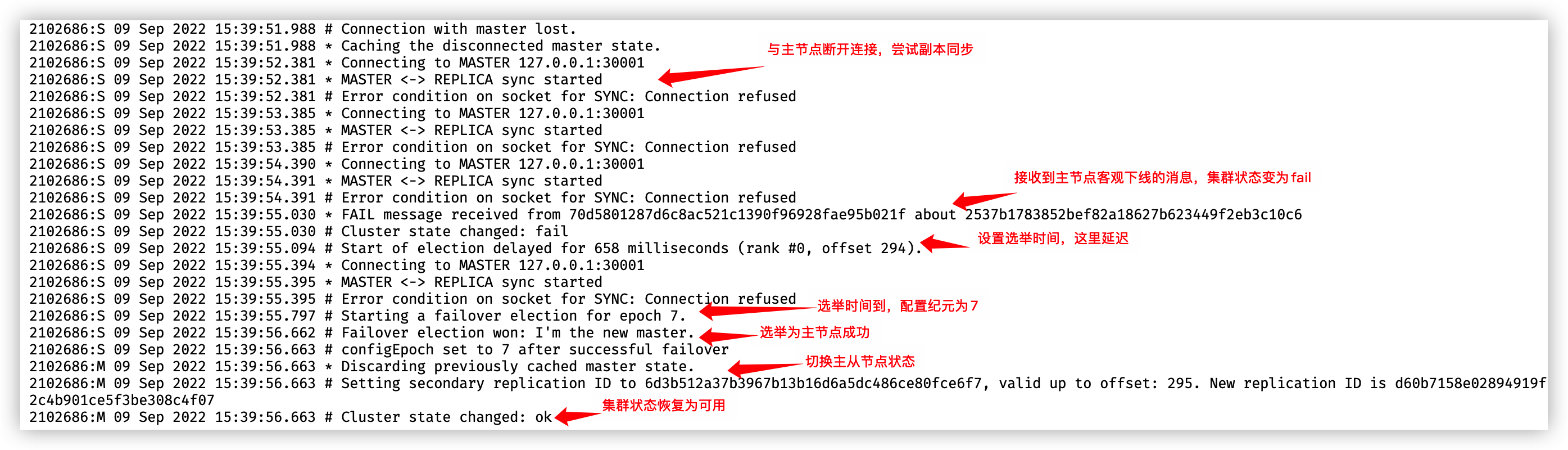
選舉時間延遲 658 毫秒,計算方式在 選舉 的第一點有提到過。
然後我們選擇一個主節點和一個從節點的紀錄檔檔案檢視是否有參加投票,主節點選擇 30002,可以看到紀錄檔中有將票投給 30006 節點(紀錄檔中列印的是 30006 的 runId):

從節點選擇 30005,看到從節點並沒有參加投票:

後話
Redis 的原始碼和檔案真的非常有觀賞性。原始碼裡的註釋十分豐富,邏輯看不懂的時候看下注釋基本能明白程式碼的作用。檔案是我接觸過的開源專案裡寫的最好的。希望能堅持下來,從 Redis 裡學到更多更好的程式碼設計思想。