knn演演算法詳解
2022-09-13 21:01:11
1.什麼是knn演演算法
俗話說:物以類聚,人以群分。看一個人什麼樣,看他身邊的朋友什麼樣就知道了(這裡並沒歧視誰,只是大概率是這樣)
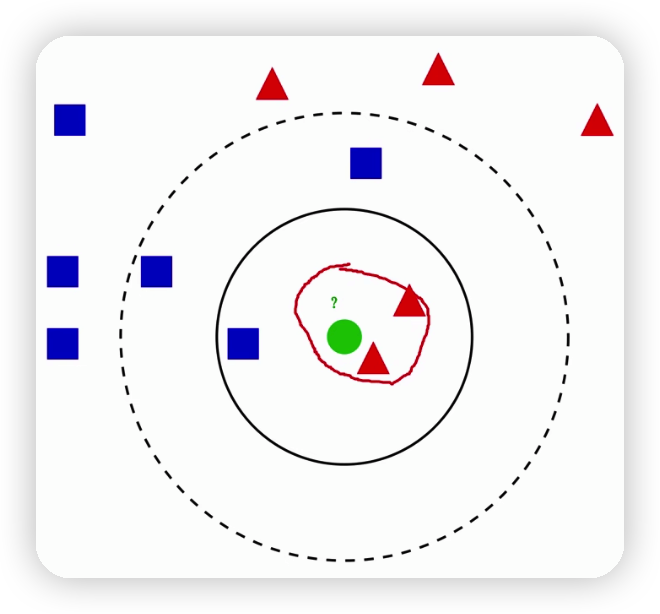
對於判斷下圖綠色的球是哪種資料型別的方法就是根據尋找他最近的k個資料,根據k的值來推測新資料的型別。
比如下圖離綠球最近的紅三角有兩個,藍方塊有一個,因此推測綠色的球為紅色的三角,這就是knn演演算法的思想
2.演演算法原理
2.1通用步驟
2.1.1計算距離
剛才說knn演演算法的思想就是根據當前資料最近的k個資料的值來判斷當前資料的型別,這就要先計算出當前資料到其它資料的距離,可以使用歐幾里得距離(所有的距離求出來之後各自平方並相加,然後對相加的結果進行開放)或馬氏距離
2.1.2升序排列
將上一步計算的每個頂點到該點的距離進行排序,一般將序列變為升序
2.1.3取前K個
對已經排序好的距離序列,取前k個即可
2.1.4加權平均
比方取的是前7個元素(即k=7),前兩個值特別小,也即和需要判斷其型別的元素距離特別近,則這兩個元素的權值就可以設定為很大;而剩餘5個元素則離相對比較遠一點,則這五個元素對應的權值也就比較小,這樣算出來的加權平均算出來的元素的型別與真實資料型別的概率才是最大的,如果直接取算術平均則相差可能會比較大
注意:此處並不能計算算術平均值
2.2 K的選取
2.2.1 K的值太大
如果選的k太大,會導致分類模糊,比如:假設有1000個已知的資料點,然後k取800,無論你怎麼分基本都是你這1000個資料組成的資料集的狀態,因為800個已經可以涵蓋絕大多數的資料的型別了,所以會導致分類模糊
2.2.2 K的值太小
受個例影響,波動較大
2.3 如何選取K
2.3.1 經驗
比方說先取一個5把演演算法跑一邊,發現是概率是50,在取個6發現概率是60,在取個7發現概率是55,則k的合適的值就是6,可以一個一個去嘗試
2.3.2 均方根誤差
取下圖(近似均方根誤差的圖)峰值(準確性最高)對應的k的值即可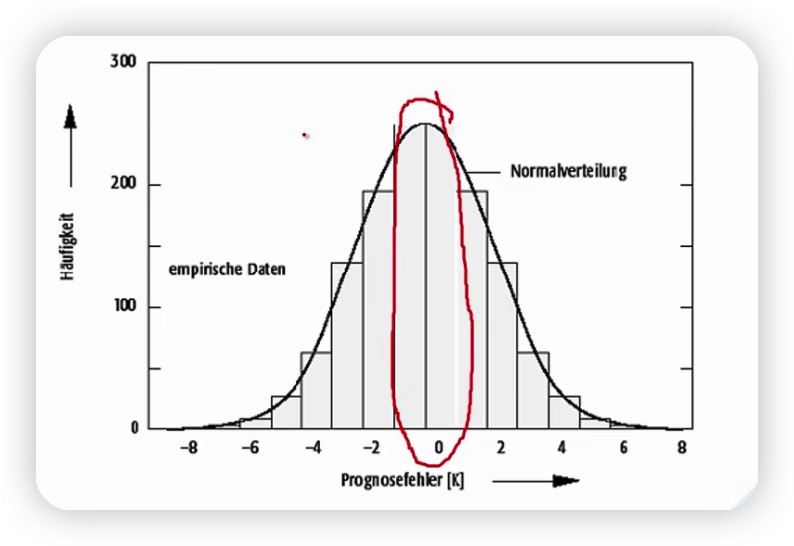
3.實戰應用
3.1 癌症檢測資料
資料獲取方法: 連結:https://pan.baidu.com/s/1w8cyvknAazrAYnAXdvtozw提取碼:zxmt
資料部分內容如下
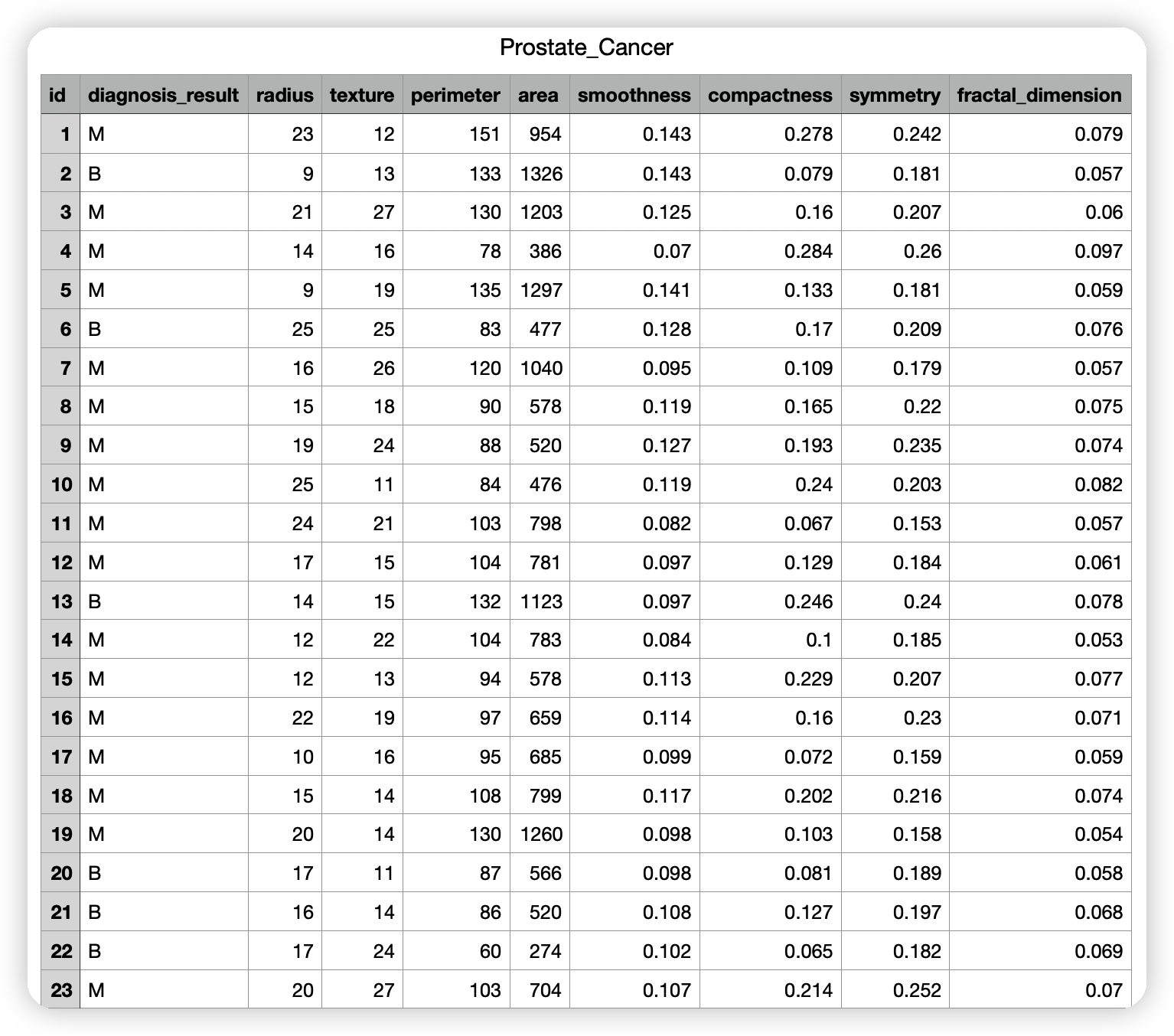
目的:給一個癌症檢測資料,然後根據該資料判斷該患者是良性的還是惡性的
import csv
#讀取
import random
with open('Prostate_Cancer.csv','r') as file:
reader = csv.DictReader(file)
datas=[row for row in reader]
#分組
random.shuffle(datas)#將所有資料打亂,相當於完牌之前,先洗牌
n=len(datas)//3#將所有資料集分成兩份,一份當做測試集,一份當做訓練集 兩個斜槓表示整除
#0到n-1為測試集
test_set=datas[0:n]
#n到後面所有資料為訓練集
train_set=datas[n:]
#knn
#算距離
def distance(d1,d2):
res=0#歐幾里得距離需要用一個變數來存距離的平方和
for key in("radius","texture", "perimeter","area", "smoothness", "compactness", "symmetry", "fractal_dimension"):
res+=(float(d1[key])-float(d2[key]))**2#對同一維度的值進行相減之後進行平方
return res**0.5#開方
k=5#測試k的值即可
def knn(data):
#1.算距離
res=[
{"result": train['diagnosis_result'],"distance": distance(data,train)}
for train in train_set
]
#2.排序-升序
res=sorted(res, key=lambda item:item['distance'])#將res裡的結果按照距離的大小進行升序排列
#3.取前k個元素
res2=res[0:k]
#4.加權平均
result={'B':0,'M':0}
#先算總距離
sum=0
for r in res2:
sum+=r['distance']
for r in res2:
result[r['result']]+=1-r['distance']/sum#距離越近distance就越小除以總距離之後就越小,所以用1減去之後就越大,保證越近的距離權值越大的要求
# print("經過knn演演算法得到的概率為:")#經過knn演演算法判斷得到的結果
# print(result)
# print("原資料的結果為:"+data['diagnosis_result'])#原資料的結果
if (result['B'] > result['M']):
return 'B'
else:
return 'M'
#knn(test_set[0])#在測試集裡面找一個資料表示當前需要判斷型別的資料
#測試階段
correct=0#表示原結果與knn演演算法執行結果相同的次數
for test in test_set:
result=test['diagnosis_result']#獲取原資料的結果
result2=knn(test)#knnu演演算法之後的結果
if(result == result2):
correct+=1
print("使用knn演演算法得到的準確率為:{:.2f}%".format(100*correct/len(test_set)))
執行結果圖