寫個續集,填坑來了!關於「Thread.sleep(0)這一行‘看似無用’的程式碼」裡面留下的坑。
你好呀,我是居家十三天只出了一次小區門的歪歪。
這篇文章是來填坑的,我以前寫文章的時候也會去填之前的一些坑,但是由於拖延症,大多都會隔上上幾個月。
這次這個坑比較新鮮,就是之前釋出的《沒有二十年功力,寫不出這一行「看似無用」的程式碼!》這篇文章,太多太多的朋友看完之後問出了一個相同的問題:

首先非常感謝閱讀我文章的朋友,同時也特別感謝閱讀的過程中帶著自己的思考,提出有價值的問題的朋友,這對我而言是一種正反饋。
我當時寫的時候確實沒有想到這個問題,所以當突然問起的時候我大概知道原因,由於未做驗證,所以也不敢貿然回答。
於是我尋找了這個問題的答案,所以先說結論:
就是和 JIT 編譯器有關。由於迴圈體中的程式碼被判定為熱點程式碼,所以經過 JIT 編譯後 getAndAdd 方法的進入安全點的機會被優化掉了,所以執行緒不能在迴圈體能進入安全點。
是的,被優化了,我打這個詞都感覺很殘忍。

接下來我準備寫個「下集」,告訴你我是怎麼得到這個結論的。但是為了讓你絲滑入戲,我先帶你簡單的回顧一下「上集」。
另外,先把話說在前面,這知識點吧,屬於可能一輩子都遇不到的那種。因此我把它劃分到我寫的「沒有卵用系列」,看著也就圖一樂。
好了,在之前的那篇文章中,我給出了這樣的一個測試用例:
public class MainTest {
public static AtomicInteger num = new AtomicInteger(0);
public static void main(String[] args) throws InterruptedException {
Runnable runnable=()->{
for (int i = 0; i < 1000000000; i++) {
num.getAndAdd(1);
}
System.out.println(Thread.currentThread().getName()+"執行結束!");
};
Thread t1 = new Thread(runnable);
Thread t2 = new Thread(runnable);
t1.start();
t2.start();
Thread.sleep(1000);
System.out.println("num = " + num);
}
}
按照程式碼來看,主執行緒休眠 1000ms 後就會輸出結果,但是實際情況卻是主執行緒一直在等待 t1,t2 執行結束才繼續執行。
執行結果是這樣的:
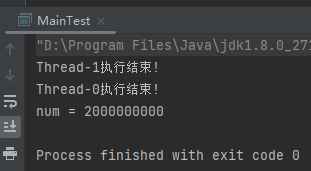
其實我在這裡埋了「彩蛋」,這個程式碼雖然你直接貼上過去就能跑,但是如果你的 JDK 版本高於 10,那麼執行結果就和我前面說的不一樣了。
從結果來看,還是有不少人挖掘到了這個「彩蛋」:

所以看文章的時候,有機會自己親自驗證一下,說不定會有意外收穫的。
針對程式表現和預期不一致的問題,第一個解決方案是這樣的:
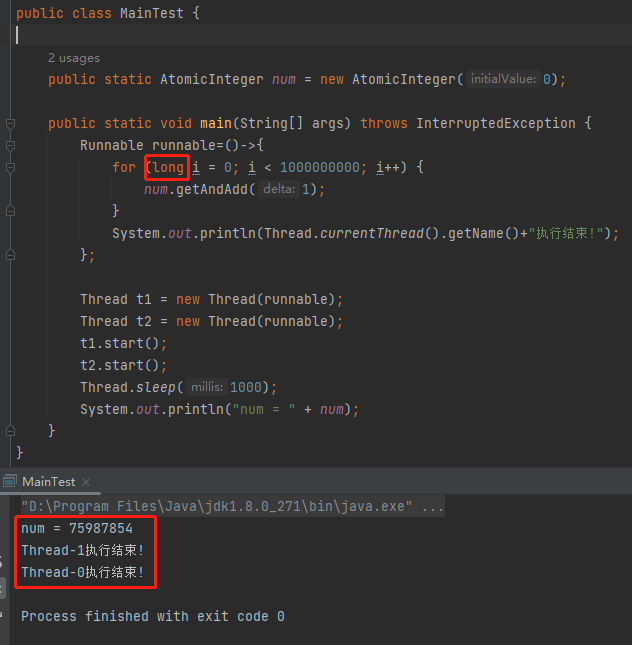
把 int 修改為 long 就搞定了。至於為什麼,之前的文章中已經說明了,這裡就不贅述了。
關鍵的是下面這個解決方案,所有的爭議都圍繞著它展開。
受到 RocketMQ 原始碼的啟示,我把程式碼修改為了這樣:
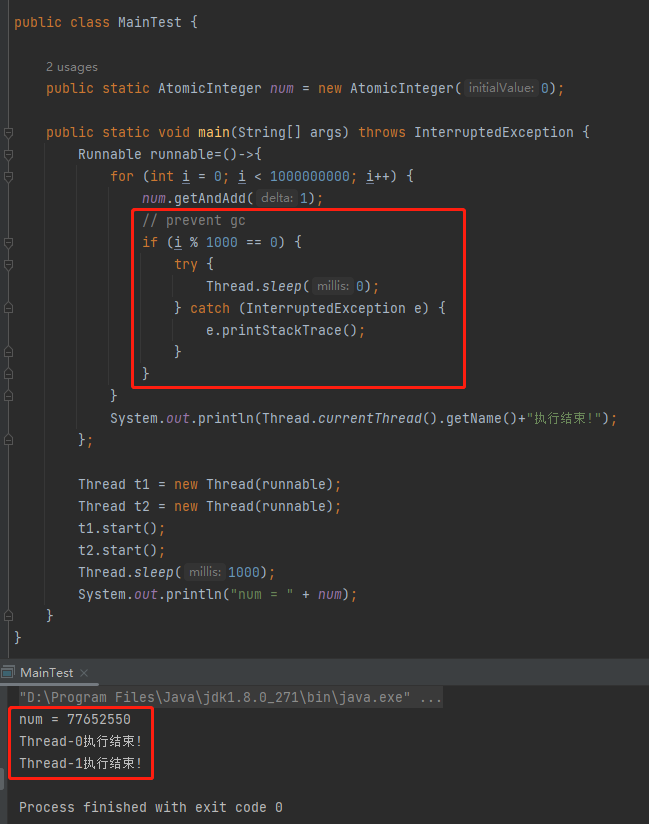
從執行結果上來看 ,即使 for 迴圈的物件是 int 型別,也可以按照預期執行。
為什麼呢?
因為在上集中關於 sleep 我通過查閱資料得出了這樣的兩個結論:
1.正在執行 native 函數的執行緒可以看作「已經進入了safepoint」。 2.由於 sleep 方法是 native 的,所以呼叫 sleep 方法的執行緒會進入 Safepoint。
論點清晰、論據合理、推理完美、事實清楚,所以上集演到這裡就結束了...

直到,有很多朋友問出了這個問題:
可是 num.getAndAdd 底層也是 native 方法呼叫啊?

對啊,和 sleep 方法一樣,這也是 native 方法呼叫啊,完全符合前面的結論啊,它為什麼不進入安全點呢,為什麼要搞差別對待呢?

大膽假設
看到問題的時候,我的第一反應就是先把鍋甩給 JIT 吧,畢竟除了它,其他的我也實在想(不)不(了)到(解)。
為什麼我會直接想到 JIT 呢?
因為迴圈中的這一行的程式碼屬於典型的熱點程式碼:
num.getAndAdd(1);
參照《深入理解JVM虛擬機器器》裡面的描述,熱點程式碼,主要是分為兩類:
被多次呼叫的方法。 被多次執行的迴圈體。
前者很好理解,一個方法被呼叫得多了,方法體內程式碼執行的次數自然就多,它成為「熱點程式碼」是理所當然的。
而後者則是為了解決當一個方法只被呼叫過一次或少量的幾次,但是方法體內部存在迴圈次數較多的迴圈體,這樣迴圈體的程式碼也被重複執行多次,因此這些程式碼也應該認為是「熱點程式碼」。很明顯,我們的範例程式碼就屬於這種情況。
在我們的範例程式碼中,迴圈體觸發了熱點程式碼的編譯動作,而回圈體只是方法的一部分,但編譯器依然必須以整個方法作為編譯物件。
因為編譯的目標物件都是整個方法體,不會是單獨的迴圈體。
既然兩種型別都是「整個方法體」,那麼區別在於什麼地方?
區別就在於執行入口(從方法第幾條位元組碼指令開始執行)會稍有不同,編譯時會傳入執行入口點位元組碼序號(Byte Code Index,BCI)。
這種編譯方式因為編譯發生在方法執行的過程中,因此被很形象地稱為「棧上替換」(On Stack Replacement,OSR),即方法的棧幀還在棧上,方法就被替換了。
說到 OSR 你就稍微耳熟了一點,是不是?畢竟它也偶現於面試環節中,作為一些高(裝)階(逼)面試題存在。
其實也就這麼回事。
好,概念就先說到這裡,剩下的如果你想要詳細瞭解,可以去翻閱書裡面的「編譯物件與觸發條件」小節。
我主要是為了引出虛擬機器器針對熱點程式碼搞了一些優化這個點。
基於前面的鋪墊,我完全可以假設如下兩點:
1.由於 num.getAndAdd 底層也是 native 方法呼叫,所以肯定有安全點的產生。 2.由於虛擬機器器判定 num.getAndAdd 是熱點程式碼,就來了一波優化。優化之後,把本來應該存在的安全點給乾沒了。

小心求證
其實驗證起來非常簡單,前面不是說了嗎,是 JIT 優化搞的鬼,那我直接關閉 JIT 功能,再跑一次,不就知道結論了嗎?
如果關閉 JIT 功能後,主執行緒在睡眠 1000ms 之後繼續執行,說明什麼?
說明迴圈體裡面可以進入 safepoint,程式執行結果符合預期。
所以結果是怎麼樣的呢?
我可以用下面的這個引數關閉 JIT:
-Djava.compiler=NONE

然後再次執行程式:
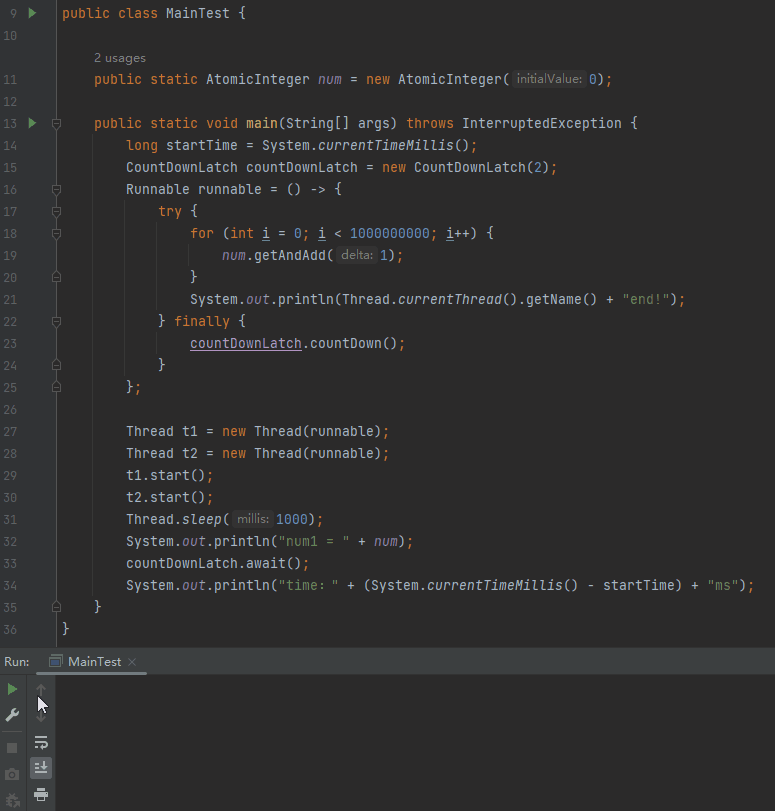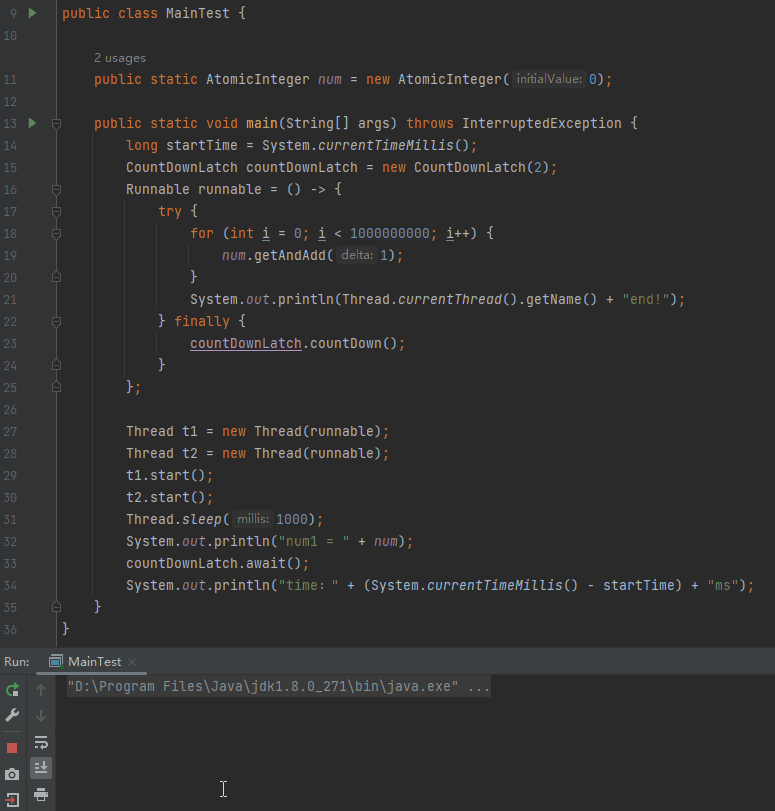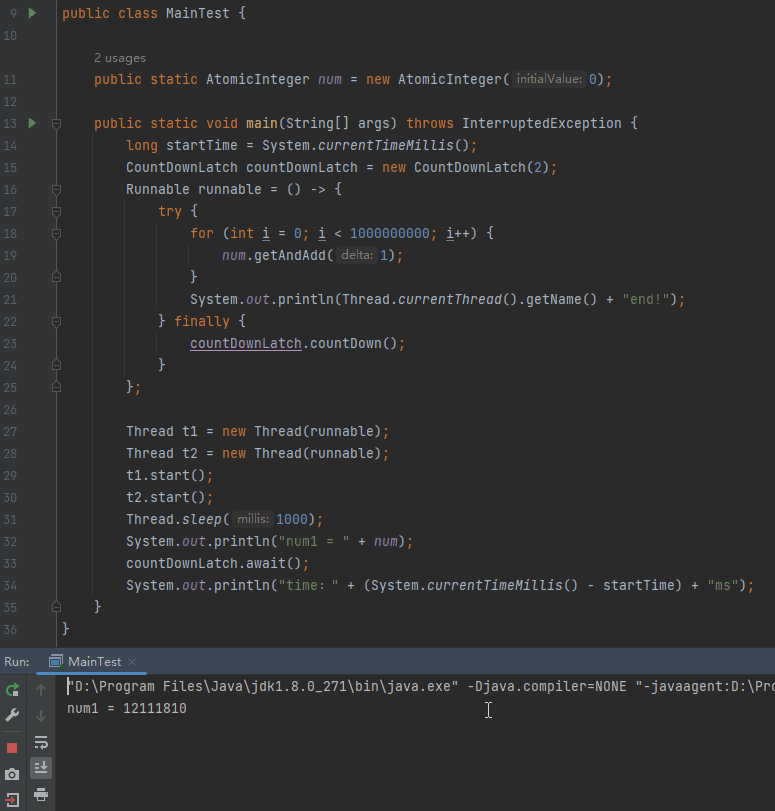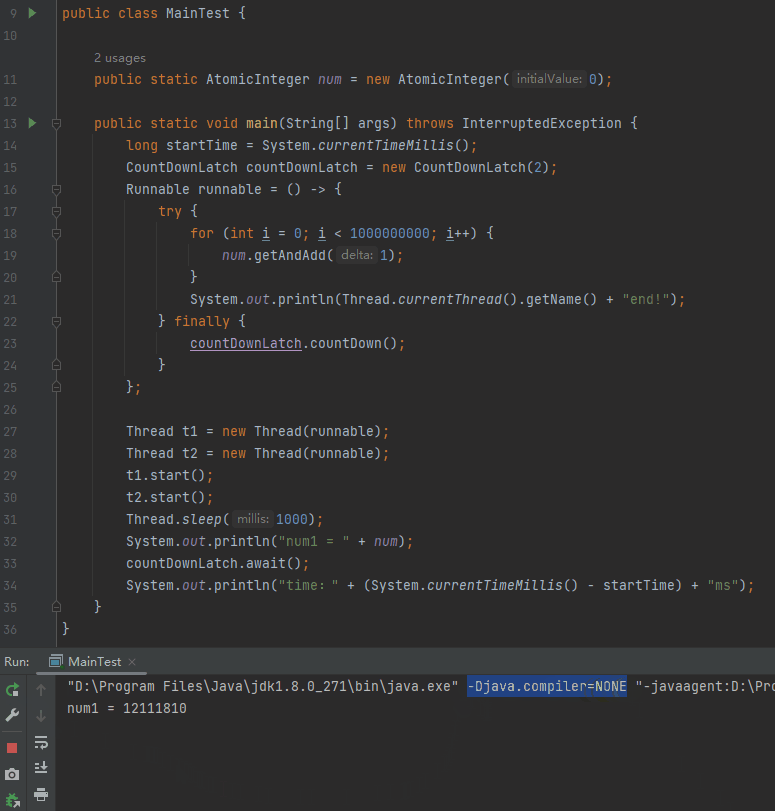
可以看到關閉 JIT 之後,主執行緒並沒有等待子執行緒執行結束後才輸出 num。效果等同於前面說的把 int 修改為 long,或者加入 Thread.sleep(0) 這樣的程式碼。
因此我前面的那兩點假設是不是就成立了?
好,那麼問題就來了,說好的是小心求證,但是我這裡只是用了一個引數關閉了 JIT,雖然看到了效果,但是總感覺中間還缺點東西。
缺什麼東西呢?
前面的程式我已經驗證了:經過 JIT 優化之後,把本來應該存在的安全點給乾沒了。
但是這句話其實還是太籠統了,經過 JIT 優化之前和之後,分別是長什麼樣子的呢,能不能從什麼地方看出來安全點確實是沒了?
不能我說沒了就沒了,這得眼見為實才行。
誒,你說巧不巧。
我剛好知道有個東西怎麼去看這個「優化之前和之後「。

有個工具叫做 JITWatch,它就能幹這個事兒。
https://github.com/AdoptOpenJDK/jitwatch
如果你之前沒用過這個工具的話,可以去查查教學。不是本文重點,我就不教了,一個工具而已,不復雜的。
我把程式碼貼到 JITWatch 的沙箱裡面:
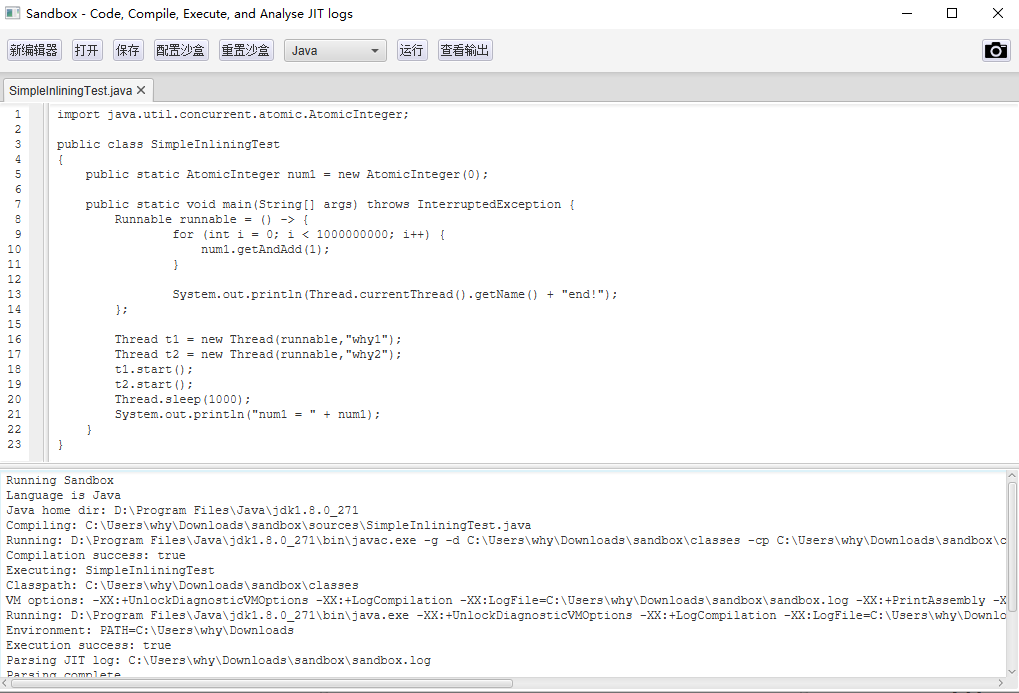
然後點選執行,最後就能得到這樣的一個介面。
左邊是 Java 原始碼,中間是 Java 位元組碼,右邊是 JIT 之後的組合指令:
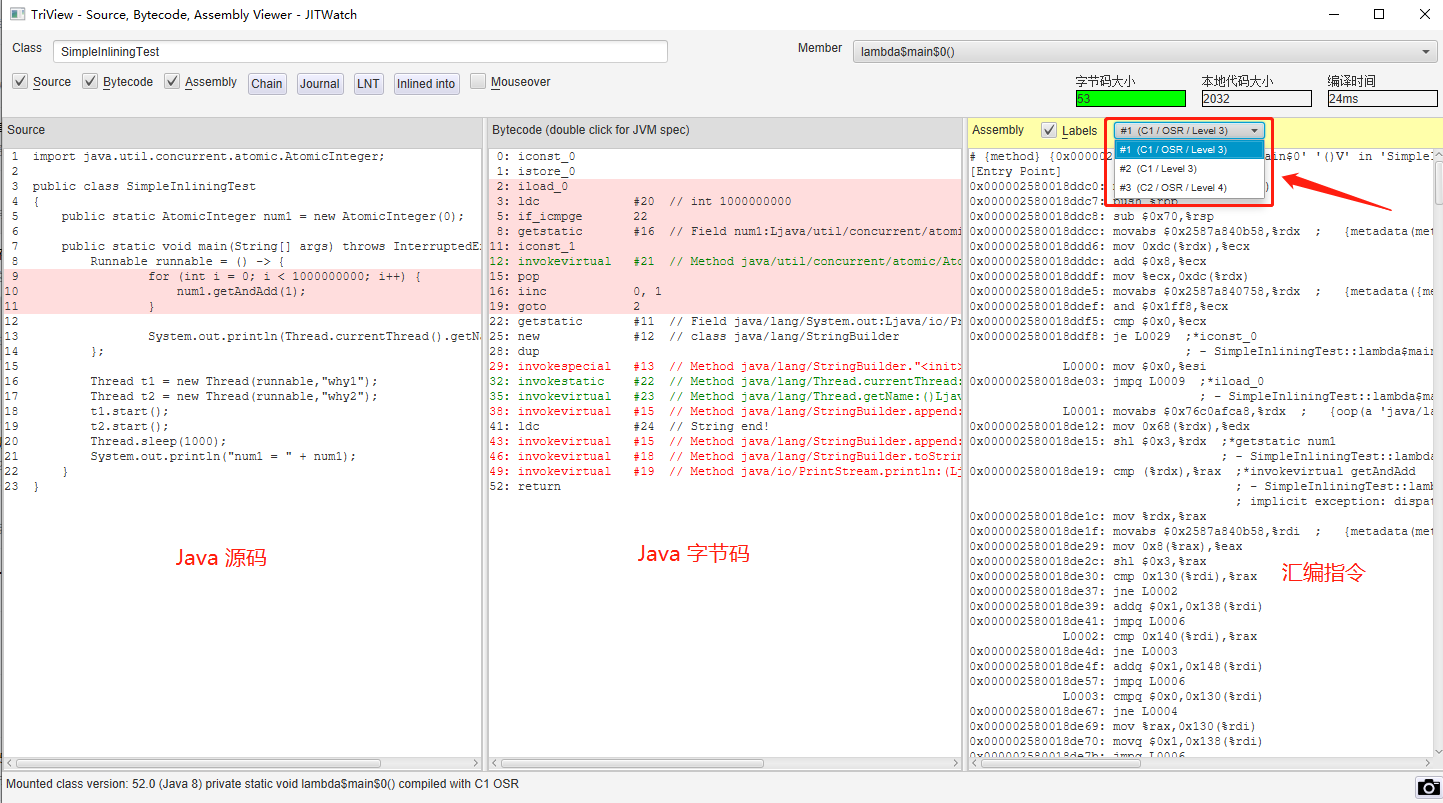
我框起來的部分就是 JIT 分層編譯後的不同的組合指令。
其中 C2 編譯就是經過充分編譯之後的高效能指令,它於 C1 編譯後的組合程式碼有很多不同的地方。
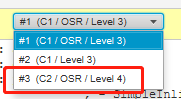
這一部分如果之前沒接觸過,看不懂沒關係,也很正常,畢竟面試也不會考。
我給你截這幾張的意思就是表明,你只要知道,我現在已經可以拿到優化之前和之後的組合指令了,但是他們自己的差異點很多,那麼我應該關注的差異點是什麼呢?
就像是給你兩個文字,讓你找出差異點,很容易。但是在眾多差異點中,哪個是我們關心的呢?
這個才是關鍵問題。
我也不知道,但是我找到了下面這一篇文章,帶領我走向了真相。
關鍵文章
好了,前面都是一些不痛不癢的東西,這裡的這篇文章才是關鍵點:
http://psy-lob-saw.blogspot.com/2015/12/safepoints.html
因為我在這個文章中,找到了 JIT 優化之後,應該關注的「差異點」是什麼。
這篇文章的標題叫做《安全點的意義、副作用以及開銷》:

作者是一位叫做 nitsanw 的大佬,從他部落格里面的文章看,在 JVM 和效能優化方面有著很深的造詣,上面的文章就釋出於他的部落格。
這是他的 github 地址:
https://github.com/nitsanw
用的頭像是一頭犛牛,那我就叫他牛哥吧,畢竟是真的牛。
同時牛哥就職於 Azul 公司,和 R 大是同事:
他這篇文章算是把安全點扒了個乾淨,但是內容非常多,我不可能面面俱到,只能挑和本文相關度非常大的地方進行簡述,但是真的強烈建議你讀讀原文。文章也分為了上下兩集,這是下集的地址:
http://psy-lob-saw.blogspot.com/2016/02/wait-for-it-counteduncounted-loops.html
看完之後,你就知道,什麼叫做透徹,什麼叫做:

在牛哥的文章中分為了下面這幾個小節:
What's a Safepoint?(啥是安全點?) When is my thread at a safepoint?(執行緒啥時候處於安全點?) Bringing a Java Thread to a Safepoint。(將一個Java執行緒帶到一個安全點) All Together Now。(搞幾個例子跑跑) Final Summary And Testament。(總結和囑咐)
和本文重點相關的是「將一個Java執行緒帶到一個安全點」這個部分。
我給你解析一下:

這一段主要在說 Java 執行緒需要每隔一個時間間隔去輪詢一個「安全點標識」,如果這個標識告訴執行緒「請前往安全點」,那麼它就進入到安全點的狀態。
但是這個輪詢是有一定的消耗的,所以需要 keep safepoint polls to a minimum,也就是說要減少安全點的輪詢。因此,關於安全點輪詢觸發的時間就很有講究。
既然這裡提到輪詢了,那麼就得說一下我們範例程式碼裡面的這個 sleep 時間了:

有的讀者把時間改的短了一點,比如 500ms,700ms 之類的,發現程式正常結束了?
為什麼?
因為輪詢的時間由 -XX:GuaranteedSafepointInterval 選項控制,該選項預設為 1000ms:

所以,當你的睡眠時間比 1000ms 小太多的時候,安全點的輪詢還沒開始,你就 sleep 結束了,當然觀察不到主執行緒等待的現象了。
好了,這個只是隨口提一句,回到牛哥的文章中,他說綜合各種因素,關於安全點的輪詢,可以在以下地方進行:
第一個地方:
Between any 2 bytecodes while running in the interpreter (effectively)
在直譯器模式下執行時,在任何 2 個位元組碼之間都可以進行安全點的輪詢。
要理解這句話,就需要了解直譯器模式了,上個圖:
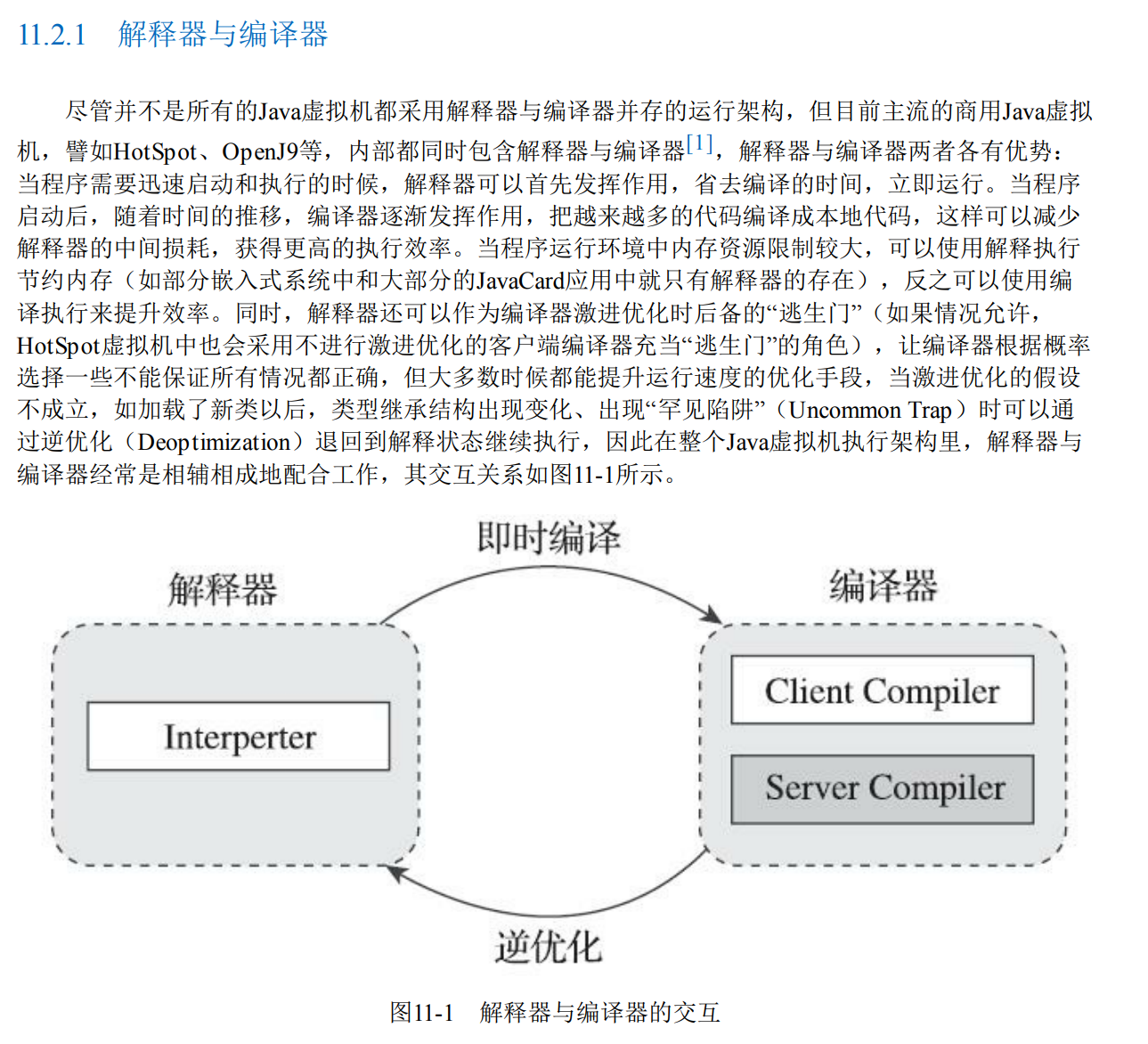
從圖上可以知道,直譯器和編譯器之間是相輔相成的關係。
另外,可以使用 -Xint 啟動引數,強制虛擬機器器執行於「解釋模式」:

我們完全可以試一試這個引數嘛:
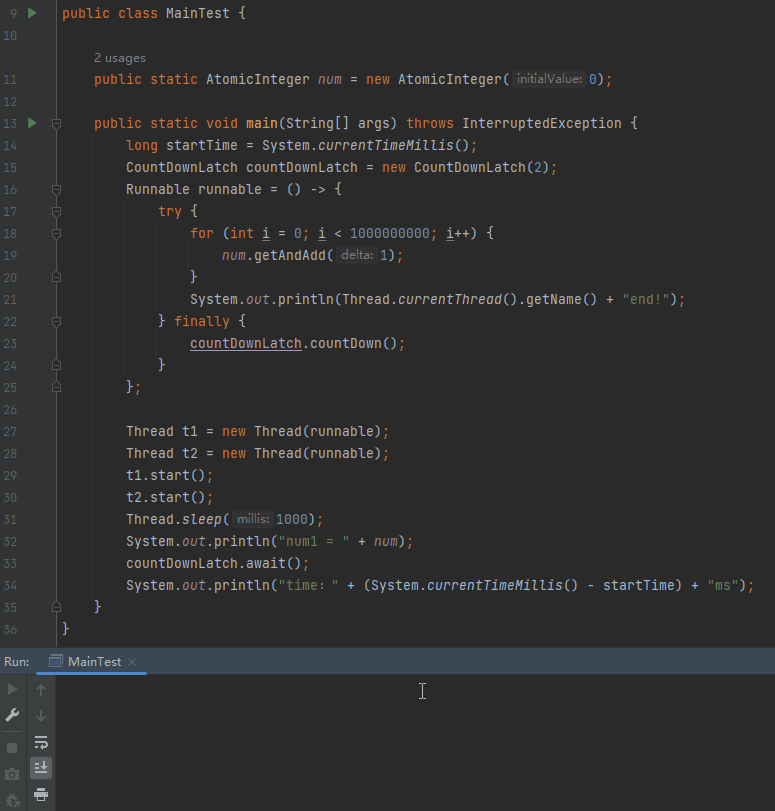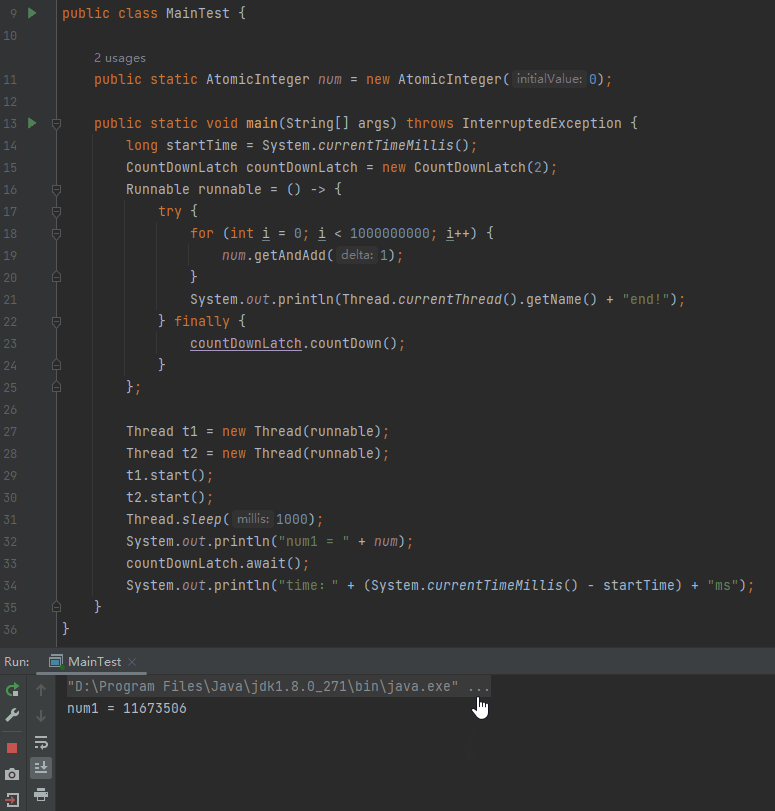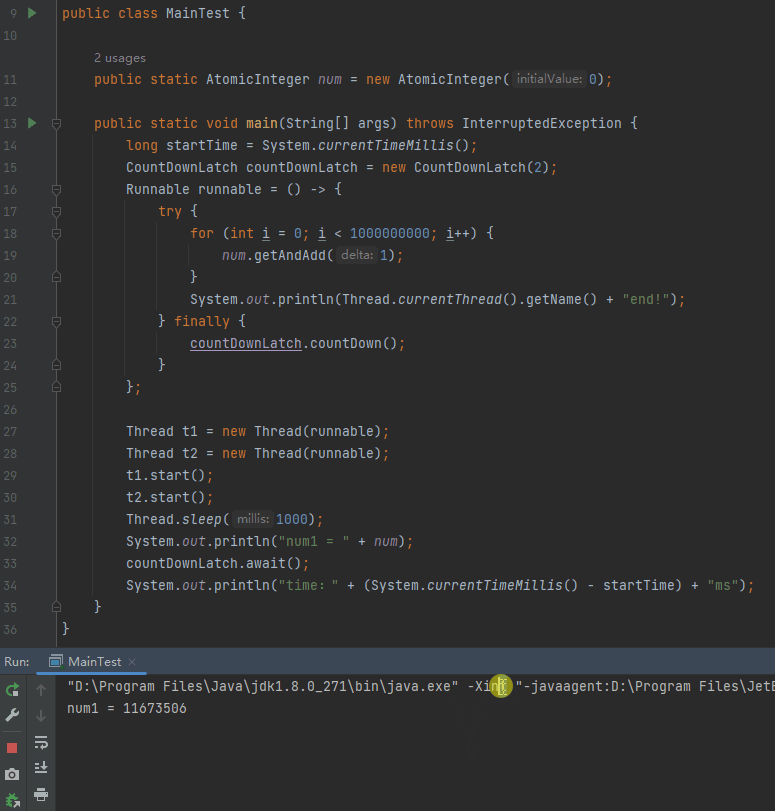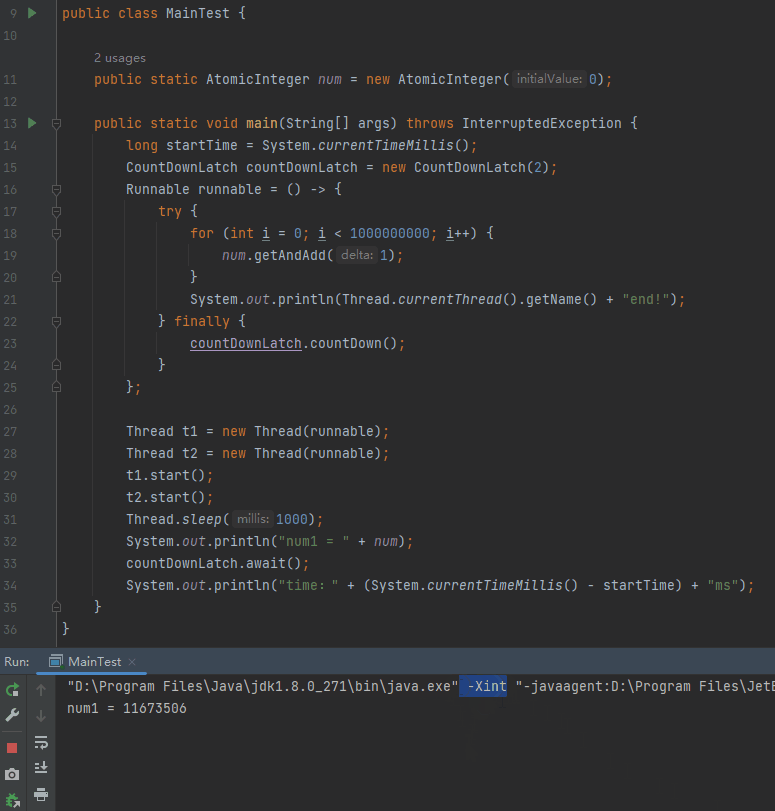
程式正常停下來了,為什麼?
剛剛才說了:
在直譯器模式下執行時,在任何 2 個位元組碼之間都可以進行安全點的輪詢。
第二個地方:
On 'non-counted' loop back edge in C1/C2 compiled code
在 C1/C2 編譯程式碼中的 "非計數 "迴圈的每次迴圈體結束之後。
關於這個「計數迴圈」和「非計算迴圈」我在上集裡面已經說過了,也演示過了,就是把 int 修改為 long,讓「計數迴圈」變成「非計算迴圈」,就不贅述了。
反正我們知道這裡說的沒毛病就行。
第三個地方:
這是前半句:Method entry/exit (entry for Zing, exit for OpenJDK) in C1/C2 compiled code.
在 C1/C2 編譯程式碼中的方法入口或者出口處(Zing 為入口,OpenJDK 為出口)。
前半句很好理解,對於我們常用的 OpenJDK 來說,即使經過了 JIT 優化,但是在方法的入口處還是設定了一個可以進行安全點輪詢的地方。
主要是關注後半句:
Note that the compiler will remove these safepoint polls when methods are inlined.
當方法被內聯時編譯器會刪除這些安全點輪詢。
這不就是我們範例程式碼的情況嗎?
本來有安全點,但是被優化沒了。說明這種情況是真實存在的。

然後我們接著往下看,就能看到我一直在找的「差異點」了:

牛哥說,如果有人想看到安全點輪詢,那麼可以加上這個啟動引數:
-XX:+PrintAssembly
然後在輸出裡面找下面的關鍵詞:
如果是 OpenJDK,就找 {poll} 或 {poll return} ,這就是對應的安全點指令。 如果是 Zing,就找 tls.pls_self_suspend 指令
實操一把就是這樣的:
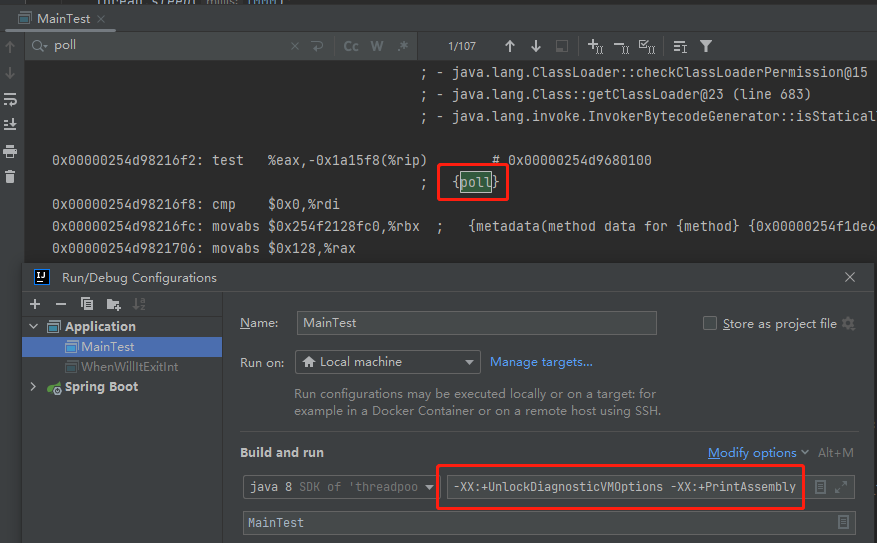
確實找到了類似的關鍵字,但是在控制檯輸出的組合太多了,根本沒法分析。
沒關係,這不重要,重要的是我到了這個關鍵的指令:{poll}
也就是說,如果在初始的組合中有 {poll} 指令,但是在經過 JIT 充分優化之後的程式碼,也就是前面說的 C2 階段的組合指令裡面,找不到 {poll} 這個指令,就說明安全點確實是被幹掉了。
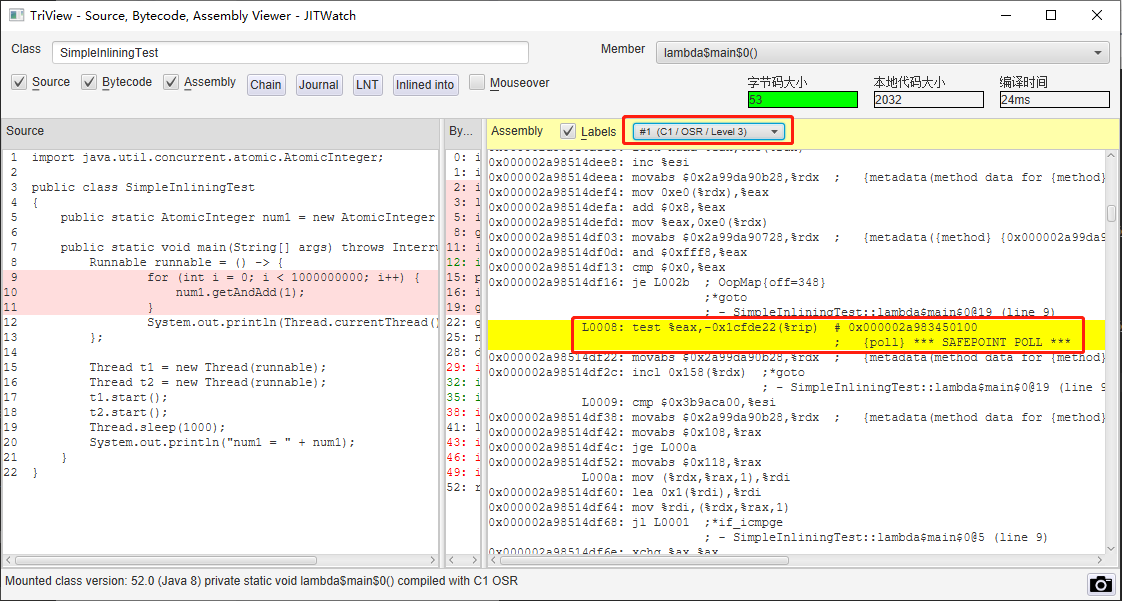
所以,在 JITWatch 裡面,當我選擇檢視 for 迴圈(熱點程式碼)在 C1 階段的編譯結果的時候,可以看看有 {poll} 指令:
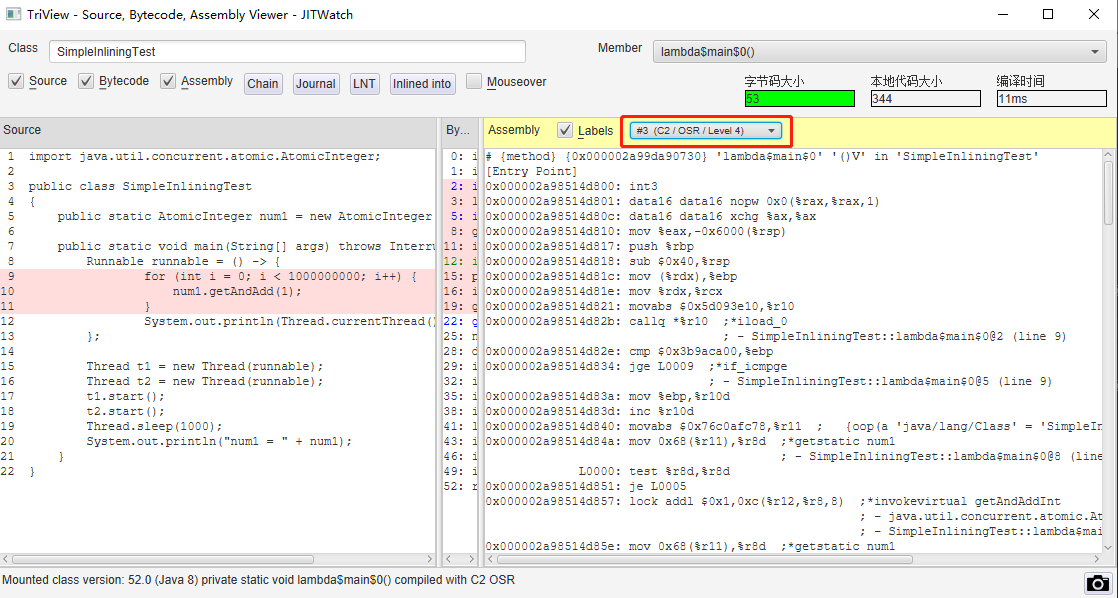
但是,當我選擇 C2 階段的編譯結果的時候,{poll} 指令確實都找不到了:
接著,如果我把程式碼修改為這樣,也就是前面說的會正常結束的程式碼:
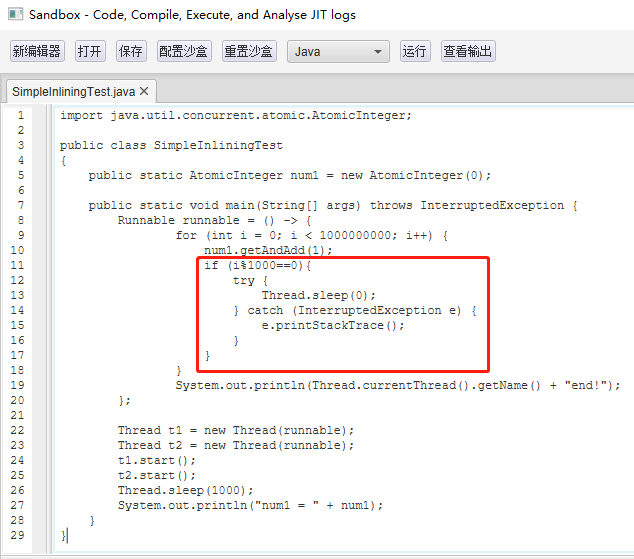
正常結束,說明迴圈體內可以進入安全點,也就是說明有 {poll} 指令。
所以,再次通過 JITWarch 檢視 C2 的組合,果然看到了它:
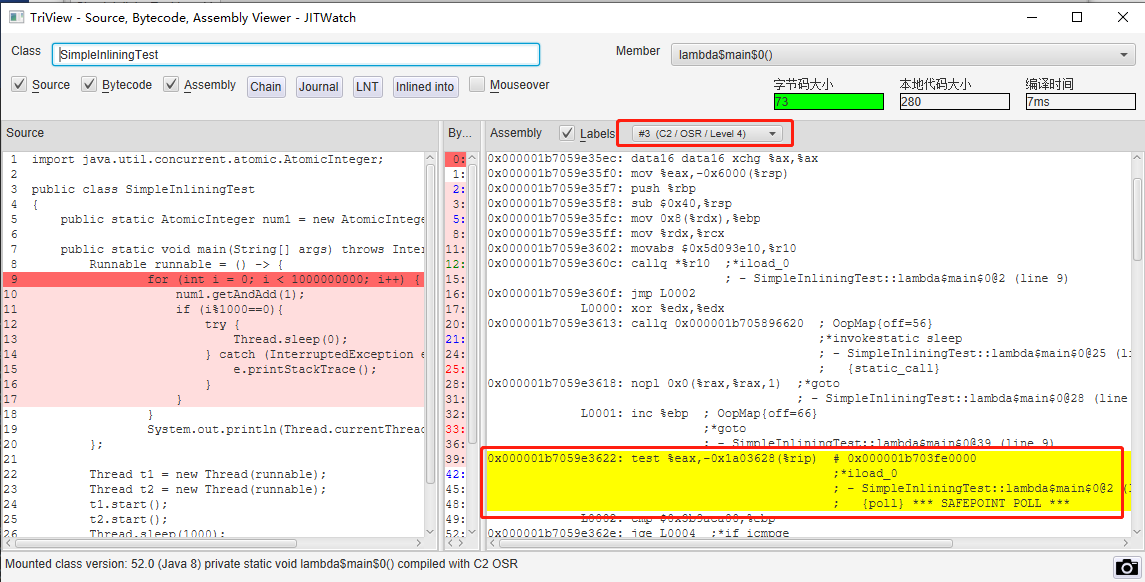
為什麼呢?
從最終輸出的組合上來看,因為 Thread.sleep(0) 這行程式碼的存在,阻止了 JIT 做過於激進的優化。
那麼為什麼 sleep 會阻止 JIT 做過於激進的優化呢?
好了,
別問了,
就到這吧,
再問,
就不禮貌了。

牛哥的案例
牛哥的文章中給了下面五個案例,每個案例都有對應的程式碼:
Example 0: Long TTSP Hangs Application Example 1: More Running Threads -> Longer TTSP, Higher Pause Times Example 2: Long TTSP has Unfair Impact Example 3: Safepoint Operation Cost Scale Example 4: Adding Safepoint Polls Stops Optimization
我主要帶大家看看第 0 個和第 4 個,老有意思了。
第 0 個案例
它的程式碼是這樣的:
public class WhenWillItExit {
public static void main(String[] argc) throws InterruptedException {
Thread t = new Thread(() -> {
long l = 0;
for (int i = 0; i < Integer.MAX_VALUE; i++) {
for (int j = 0; j < Integer.MAX_VALUE; j++) {
if ((j & 1) == 1)
l++;
}
}
System.out.println("How Odd:" + l);
});
t.setDaemon(true);
t.start();
Thread.sleep(5000);
}
}
牛哥是這樣描述這個程式碼的:
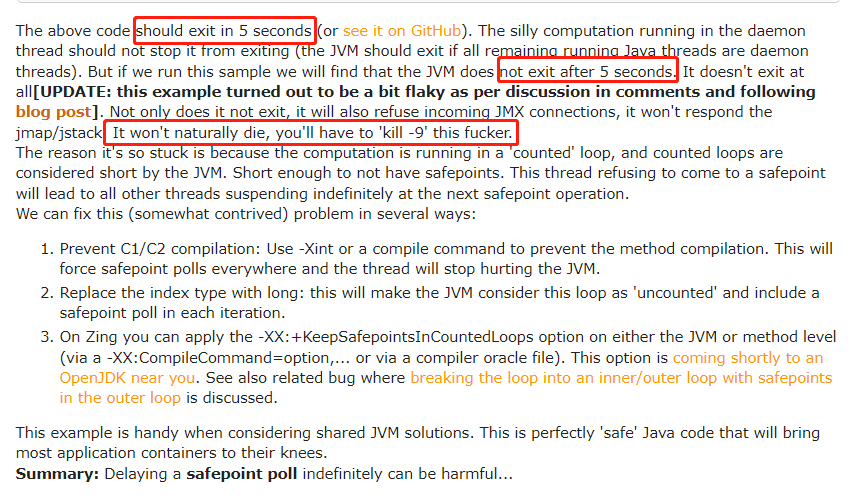
他說這個程式碼應該是在 5 秒之後結束,但是實際上它會一直執行下去,除非你用 kill -9 命令強行停止它。
但是當我把程式碼貼上到 IDEA 裡面執行起來,5 秒之後,程式停了,就略顯尷尬。
我建議你也粘出來跑一下。
這裡為什麼和牛哥說的執行結果不一樣呢?
評論區也有人問出了這個問題:
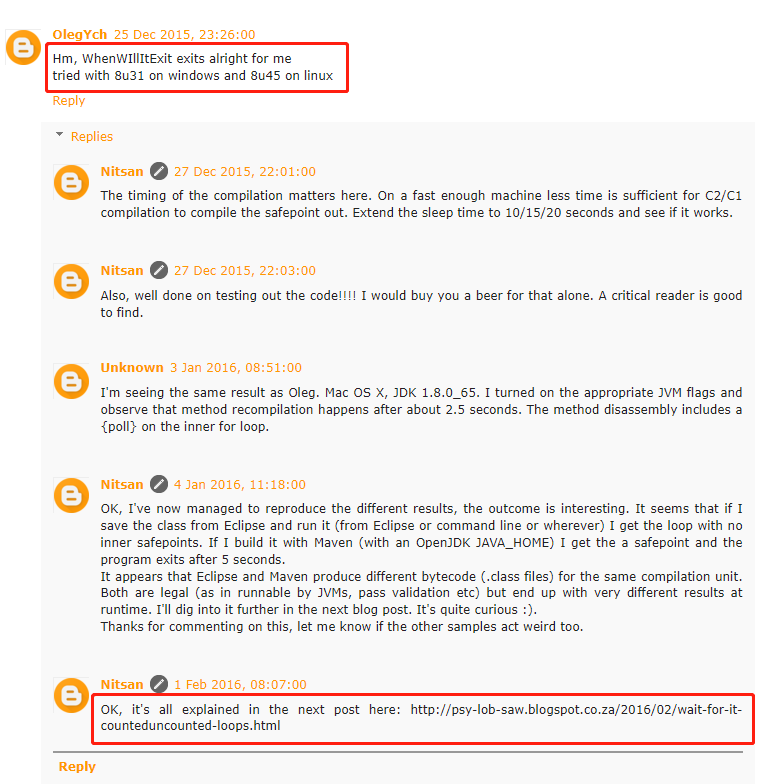
於是牛哥又寫了一篇下集,詳細的解釋了為什麼:
http://psy-lob-saw.blogspot.co.za/2016/02/wait-for-it-counteduncounted-loops.html
簡單來說就是他是在 Eclipse 裡面跑的,而 Eclipse 並不是用的 javac 來編譯,而是用的自己的編譯器。
編譯器差異導致位元組碼的差異,從而導致執行結果的差異:
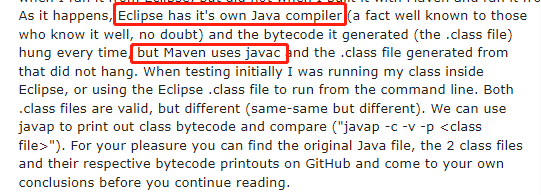
然後牛哥通過一頓分析,給出了這樣的一段程式碼,
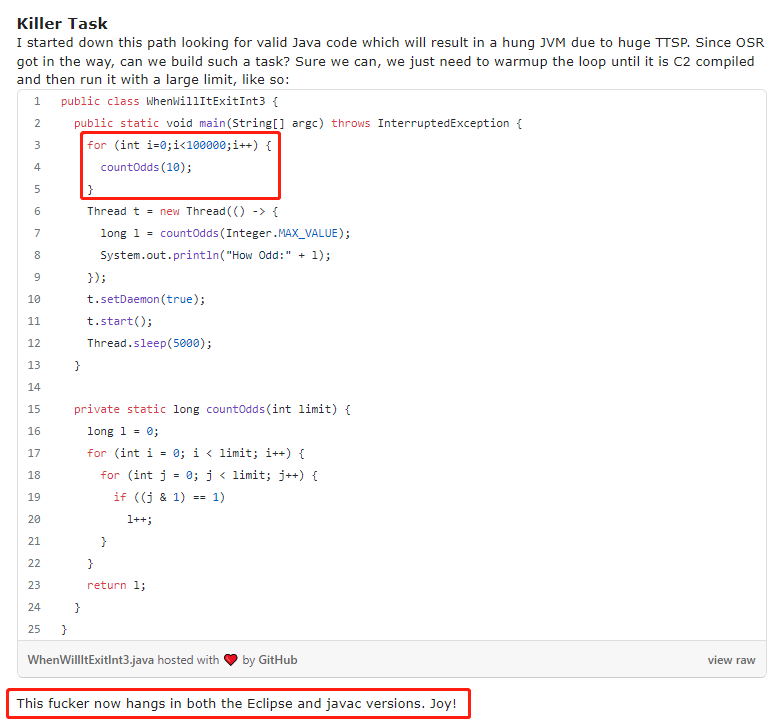
和之前的程式碼唯一不一樣的地方,就是在子執行緒裡面呼叫 countOdds 方法之前,在主執行緒裡面先進行了 10w 次的執行呼叫。
這樣改造之後程式碼執行起來就不會在 5 秒之後停止了,必須要強行 kill 才行。
為什麼呢?
別問,問就是答案就在他的下集裡面,自己去翻,寫的非常詳細。
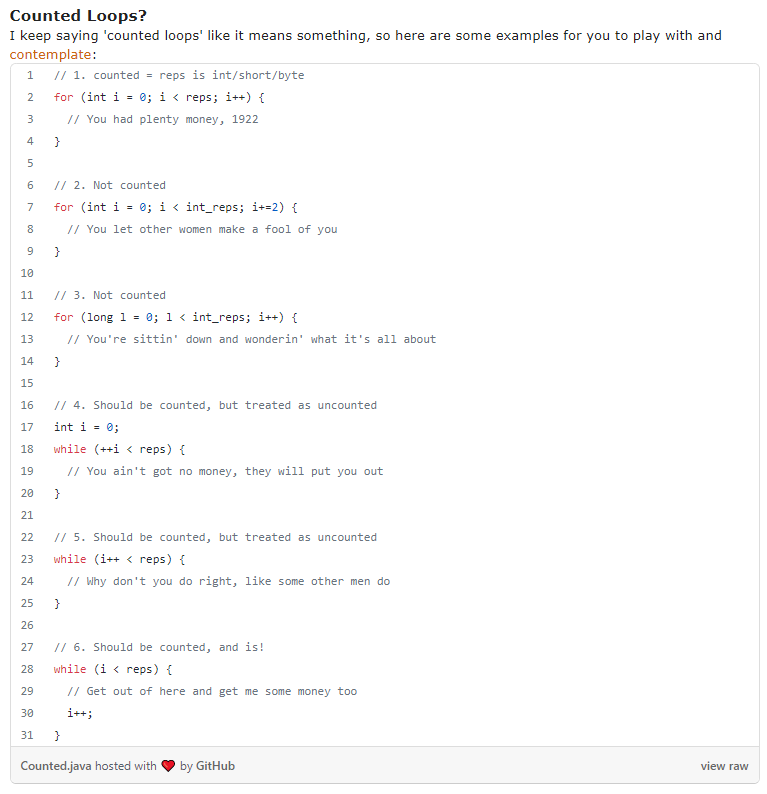
同時在下集中,牛哥還非常貼心的給你貼出了他總結的六種迴圈的寫法,那些算是「counted Loops」,建議仔細辨別:
第 4 個案例
這個案例是一個基準測試,牛哥說它是來自 Netty 的一個 issue:
這裡怎麼突然提到 Netty 了呢?
牛哥給了一個超連結:
https://github.com/netty/netty/pull/3969#issuecomment-132559757
這個 pr 裡面討論的內容非常的多,其中一個爭論的點就是迴圈到底用 int 還是 long。
這個哥們寫了一個基準測試,測試結果顯示用 int 和 long 似乎沒啥差別:

需要說明的是,為了截圖方便,我截圖的時候把這個老哥的基準測試刪除了。如果你想看他的基準測試程式碼,可以通過前面說的連結去找到。
然後這個看起來頭髮就很茂盛的老哥直接用召喚術召喚了牛哥:
等了一天之後,牛哥寫了一個非常非常詳細的回覆,我還是隻擷取其中一部分:

他上來就說前面的老哥的基準測試寫的有點毛病,所以看起來差不多。你看看我寫的基準測試跑出來的分,差距就很大了。
牛哥這裡提到的基準測試,就是我們的第四個案例。
所以也可以結合著 Netty 的這個特別長的 pr 去看這個案例,看看什麼叫做專業。

最後,再說一次,文中提到的牛哥的兩篇文章,建議仔細閱讀。
另外,關於安全點的原始碼,我之前也分享過這篇文章,建議一起食用,味道更佳:《關於安全點的那點破事兒》
我只是給你指個路,剩下的路就要你自己走了,天黑路滑,燈火昏暗,小心腳下,不要深究,及時回頭,阿彌陀佛!
最後,感謝你閱讀我的文章。歡迎關注公眾號【why技術】,文章全網首發哦。