數倉Hive和分散式計算引擎Spark多整合方式實戰和調優方向
@
概述
前面的文章都單獨熟悉Hive和Spark原理和應用,本篇則來進一步研究Hive與Spark之間整合的3種模式:
- Hive on Spark:在這種模式下,資料是以table的形式儲存在hive中的,使用者處理和分析資料,使用的是hive語法規範的 hql (hive sql)。 但這些hql,在使用者提交執行時(一般是提交給hiveserver2服務去執行),底層會經過hive的解析優化編譯,最後以spark作業的形式來執行。hive在spark 因其快速高效佔領大量市場後通過改造自身程式碼支援spark作為其底層計算引擎。這種方式是Hive主動擁抱Spark做了對應開發支援,一般是依賴Spark的版本釋出後實現。
- Spark on Hive:spark本身只負責資料計算處理,並不負責資料儲存。其計算處理的資料來源,可以以外掛的形式支援很多種資料來源,這其中自然也包括hive,spark 在推廣面世之初就主動擁抱hive,使用spark來處理分析儲存在hive中的資料時,這種模式就稱為為Spark on Hive。這種方式是是Spark主動擁抱Hive實現基於Hive使用。
- Spark + Spark Hive Catalog。這是spark和hive結合的一種新形勢,隨著資料湖相關技術的進一步發展,其本質是,資料以orc/parquet/delta lake等格式儲存在分散式檔案系統如hdfs或物件儲存系統如s3中,然後通過使用spark計算引擎提供的scala/java/python等api或spark 語法規範的sql來進行處理。由於在處理分析時針對的物件是table, 而table的底層對應的才是hdfs/s3上的檔案/物件,所以我們需要維護這種table到檔案/物件的對映關係,而spark自身就提供了 spark hive catalog來維護這種table到檔案/物件的對映關係。使用這種模式,並不需要額外單獨安裝hive。
Spark on Hive
# 啟動hiveserver2,兩種方式選一
hive --service hiveserver2 &
nohup hive --service hiveserver2 >> ~/hiveserver2.log 2>&1 &
# 啟動metastore,兩種方式選一
hive --service metastore &
nohup hive --service metastore >> ~/metastore.log 2>&1 &
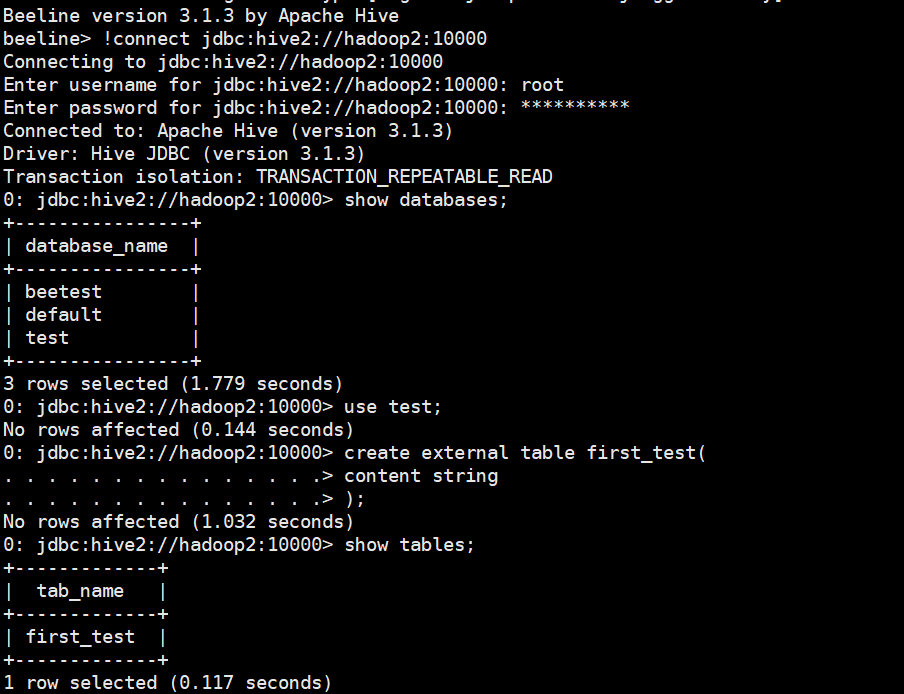
通過hive連線建立資料庫、表和匯入資料,Hive部署詳細檢視之前文章
# 測試beeline使用者端
beeline
!connect jdbc:hive2://hadoop2:10000
create database if not exists test;
use test;
create external table first_test(
content string
);
# 測試hive使用者端
hive
load data local inpath '/home/commons/apache-hive-3.1.3-bin/first_test.txt' into table first_test;
select * from first_test;
select count(*) from first_test;
# 將部署好的hive的路徑下的conf/hive-site.xml複製到spark安裝路徑下的conf/
cp /home/commons/apache-hive-3.1.3-bin/conf/hive-site.xml conf/
# 將部署好的hive的路徑下的lib/mysql驅動包,我的是(mysql-connector-java-8.0.15.jar)拷貝到spark安裝路徑下的jars/
cp /home/commons/apache-hive-3.1.3-bin/lib/mysql-connector-java-8.0.28.jar jars/
# 啟動park-shell的yarn client模式
bin/spark-shell \
--master yarn
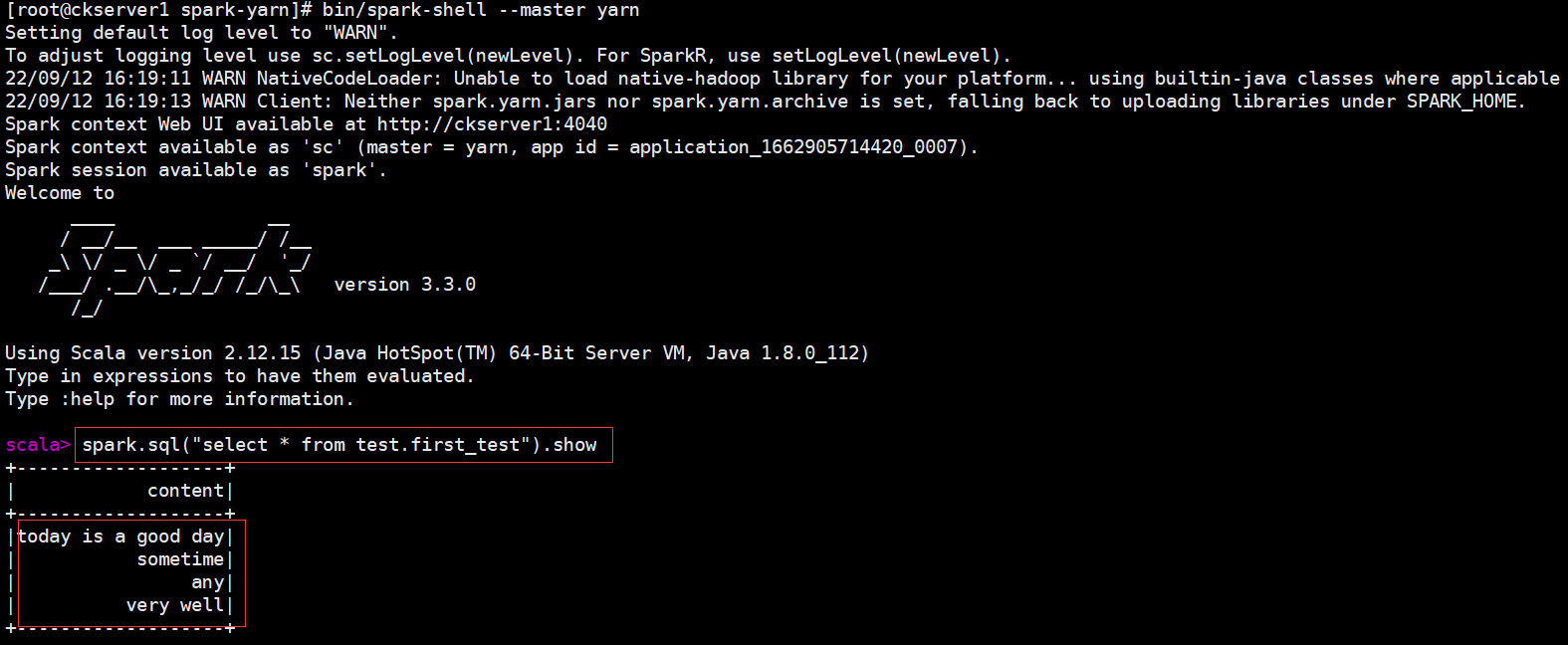
spark.sql("select * from test.first_test").show
經過上面簡單部署,Spark就可以操作Hive的資料,檢視Spark on Hive顯示結果如下
# 這裡我們使用Standalone模式執行,啟動Spark Standalone叢集
./start-all.sh
# 建立scala maven專案
package cn.itxs
import org.apache.spark.sql.{DataFrame, Dataset, Row, SparkSession}
object SparkDemo {
def main(args: Array[String]): Unit = {
val spark = SparkSession.builder().enableHiveSupport().appName("spark-hive").master("spark://hadoop1:7077").getOrCreate()
spark.sql("select * from test.first_test").show()
}
}
maven pom依賴
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-core_2.13</artifactId>
<version>3.3.0</version>
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-sql_2.13</artifactId>
<version>3.3.0</version>
<scope>provided</scope>
</dependency>
<!-- SparkSQL ON Hive-->
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-hive_2.13</artifactId>
<version>3.3.0</version>
<scope>provided</scope>
</dependency>
<!--mysql依賴的jar包-->
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
<version>8.0.28</version>
</dependency>
<dependency>
<groupId>org.scala-lang</groupId>
<artifactId>scala-library</artifactId>
<version>2.12.16</version>
</dependency>
<dependency>
<groupId>org.apache.hive</groupId>
<artifactId>hive-exec</artifactId>
<version>3.1.3</version>
</dependency>
Hive on Spark
概述
Hive on Spark 官網檔案地址 https://cwiki.apache.org/confluence/display/Hive/Hive+on+Spark%3A+Getting+Started
hive支援了三種底層計算引擎包括mr、tez和spark。從hive的組態檔hive-site.xml中就可以看到
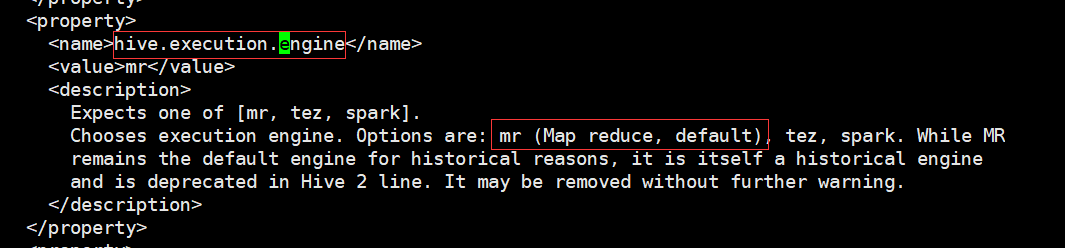
Hive on Spark為Hive提供了使用Apache Spark作為執行引擎的能力,可以指定具體使用spark計算引擎 set hive.execution.engine=spark;
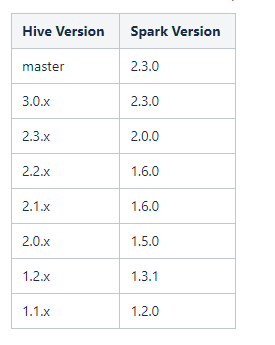
注意,一般來說hive版本需要與spark版本對應,官網有給出對應版本。這裡使用的hive版本,spark版本,hadoop版本都沒有使用官方推薦。只是我們學習研究,如生產使用的話建議按照官網版本。下面為官網的說明:Hive on Spark只在特定版本的Spark上進行測試,因此一個特定版本的Hive只能保證與特定版本的Spark一起工作。其他版本的Spark可能會與指定版本的Hive一起工作,但不能保證。以下是Hive的版本列表以及與之配套的Spark版本。
編譯Spark原始碼
# 下載Spark3.3.0的原始碼
wget https://github.com/apache/spark/archive/refs/tags/v3.3.0.zip
# 解壓
unzip v3.3.0.zip
# 進入原始碼根目錄
cd spark-3.3.0
# 執行編譯,主要不包含hive的依賴,當前需要以前安裝好maven
./dev/make-distribution.sh --name "hadoop3-without-hive" --tgz "-Pyarn,hadoop-3.3,scala-2.12,parquet-provided,orc-provided" -Dhadoop.version=3.3.4 -Dscala.version=2.12.15 -Dscala.binary.version=2.12
編譯需要等待一段時間,下載相關依賴包執行編譯步驟

編譯完成後在根目錄下生成spark-3.3.0-bin-hadoop3-without-hive.tgz打包檔案
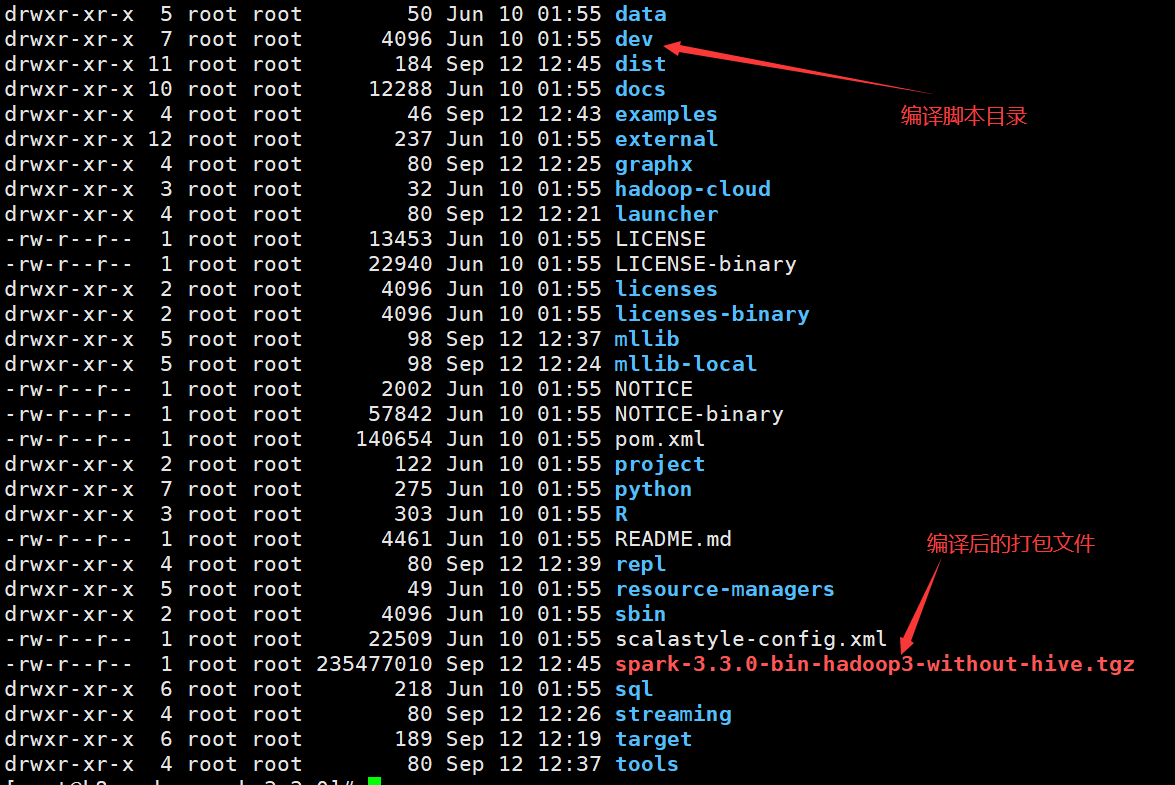
之前在官網下載Spark3.3.0的大小要比剛才大,其差異就是去除Hive的依賴

設定
# 將spark-3.3.0-bin-hadoop3-without-hive.tgz拷貝到安裝目錄
tar -xvf spark-3.3.0-bin-hadoop3-without-hive.tgz
# spark-3.3.0-bin-hadoop3-without-hive
- 全域性設定置Hive執行引擎使用Spark,在hive-site.sh中設定
<property> <name>spark.executor.cores</name> <value>3</value></property>
- 區域性設定Hive執行引擎使用Spark,如在命令列中設定
set hive.execution.engine=spark;hive -e "hive.execution.engine=spark"
設定Hive的Spark-application設定,可以通過新增一個帶有這些屬性的檔案「spark-defaults.conf」到Hive類路徑中,或者通過在Hive組態檔(Hive -site.xml)中設定它們來實現。在hive-site.sh增加Spark的設定如下
<property>
<name>spark.serializer</name>
<value>org.apache.spark.serializer.KryoSerializer</value>
<description>設定spark的序列化類</description>
</property>
<property>
<name>spark.eventLog.enabled</name>
<value>true</value>
</property>
<property>
<name>spark.eventLog.dir</name>
<value>hdfs://myns:8020/hive/log</value>
</property>
<property>
<name>spark.executor.instances</name>
<value>3</value>
</property>
<property>
<name>spark.executor.cores</name>
<value>3</value>
</property>
<property>
<name>spark.yarn.jars</name>
<value>hdfs://myns:8020/spark/jars-hive/*</value>
</property>
<property>
<name>spark.home</name>
<value>/home/commons/spark-3.3.0-bin-hadoop3-without-hive</value>
</property>
<property>
<name>spark.master</name>
<value>yarn</value>
<description>設定spark on yarn</description>
</property>
<property>
<name>spark.executor.extraClassPath</name>
<value>/home/commons/apache-hive-3.1.3-bin/lib</value>
<description>設定spark 用到的hive的jar包</description>
</property>
<property>
<name>spark.eventLog.enabled</name>
<value>true</value>
</property>
<property>
<name>spark.executor.memory</name>
<value>4g</value>
</property>
<property>
<name>spark.yarn.executor.memoryOverhead</name>
<value>2048m</value>
</property>
<property>
<name>spark.driver.memory</name>
<value>2g</value>
</property>
<property>
<name>spark.yarn.driver.memoryOverhead</name>
<value>400m</value>
</property>
<property>
<name>spark.executor.cores</name>
<value>3</value>
</property>
# HDFS建立/hive/log目錄hdfs dfs -mkdir -p /hive/log# HDFS建立/spark/jars-hiveg目錄hdfs dfs -mkdir -p /spark/jars-hivehdfs dfs -mkdir -p /hive/loghis# 進入jars目錄cd spark-3.3.0-bin-hadoop3-without-hive/jars# 上傳hdfs dfs -put *.jar /spark/jars-hive
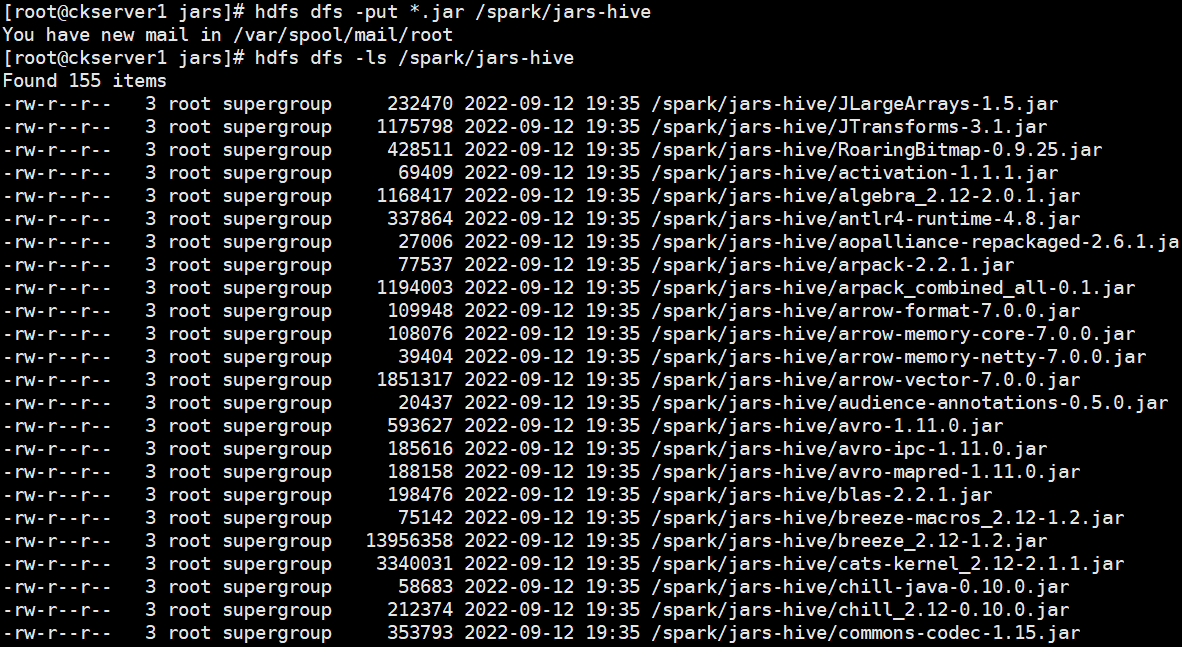
# 從Hive 2.2.0開始,Hive on Spark執行在Spark 2.0.0及以上版本,沒有assembly jar。要使用YARN模式(YARN -client或YARN -cluster)執行,請將以下jar檔案連結到HIVE_HOME/lib。scala-library、spark-core、spark-network-commoncp scala-library-2.12.15.jar /home/commons/apache-hive-3.1.3-bin/lib/cp spark-core_2.12-3.3.0.jar /home/commons/apache-hive-3.1.3-bin/lib/cp spark-network-common_2.12-3.3.0.jar /home/commons/apache-hive-3.1.3-bin/lib/# 拷貝組態檔到spark conf目錄mv spark-env.sh.template spark-env.shcp /home/commons/hadoop/etc/hadoop/core-site.xml ./cp /home/commons/hadoop/etc/hadoop/hdfs-site.xml ./cp /home/commons/apache-hive-3.1.3-bin/conf/hive-site.xml ./
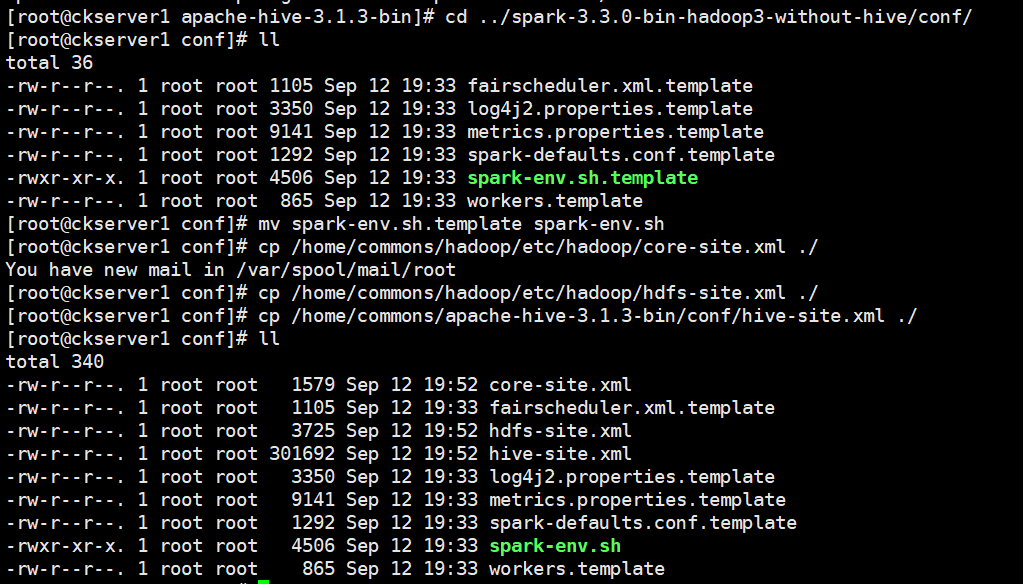
# spark-env.sh增加如下內容
vi spark-env.sh
SPARK_CONF_DIR=/home/commons/spark-3.3.0-bin-hadoop3-without-hive/conf
HADOOP_CONF_DIR=/home/commons/hadoop/etc/hadoop
YARN_CONF_DIR=//home/commons/hadoop/etc/hadoop
SPARK_EXECUTOR_CORES=3
SPARK_EXECUTOR_MEMORY=4g
SPARK_DRIVER_MEMORY=2g
# spark-defaults.conf增加增加如下內容
spark.yarn.historyServer.address=hadoop1:18080
spark.yarn.historyServer.allowTracking=true
spark.eventLog.dir=hdfs://myns:8020/hive/log
spark.eventLog.enabled=true
spark.history.fs.logDirectory=hdfs://myns:8020/hive/loghis
spark.yarn.jars=hdfs://myns:8020/spark/jars-hive/*
# 分發到其他機器
scp spark-env.sh hadoop2:/home/commons/spark-3.3.0-bin-hadoop3-without-hive/conf/
scp spark-env.sh hadoop2:/home/commons/spark-3.3.0-bin-hadoop3-without-hive/conf/
# 將Spark分發到其他兩臺上
scp -r /home/commons/spark-3.3.0-bin-hadoop3-without-hive/ hadoop2:/home/commons/
scp -r /home/commons/spark-3.3.0-bin-hadoop3-without-hive/ hadoop3:/home/commons/
# 分發hive的設定或目錄到另外一臺
scp -r apache-hive-3.1.3-bin hadoop2:/home/commons/
# 啟動hiveserver2,兩種方式選一
nohup hive --service hiveserver2 >> ~/hiveserver2.log 2>&1 &
# 啟動metastore,兩種方式選一
nohup hive --service metastore >> ~/metastore.log 2>&1 &
通過hive提交任務
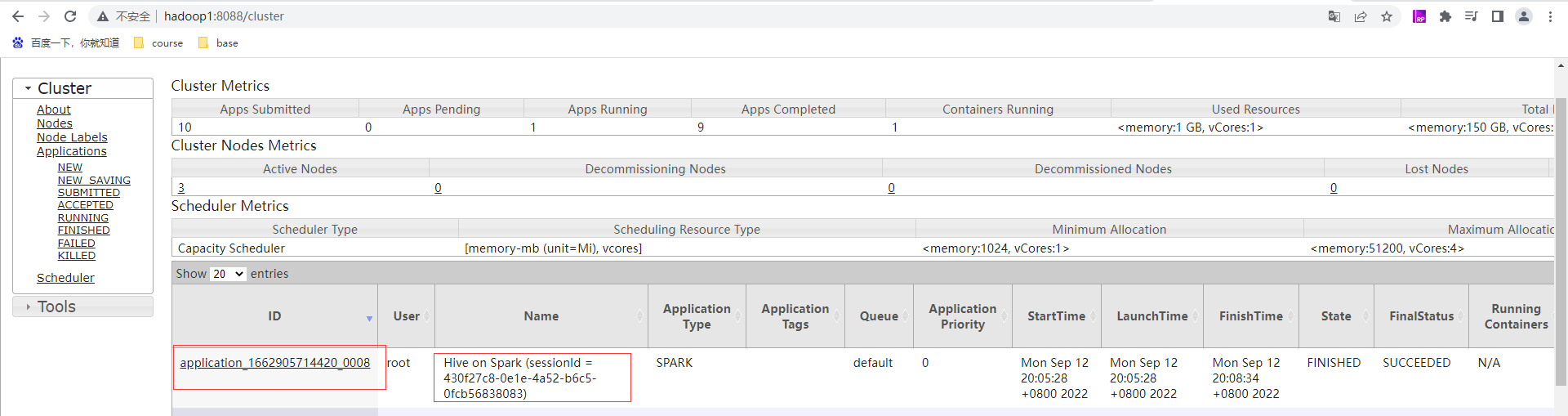
調優思路
程式設計方向
分組聚合優化
優化思路為map-side聚合。所謂map-side聚合,就是在map端維護一個hash table,利用其完成分割區內的、部分的聚合,然後將部分聚合的結果,傳送至reduce端,完成最終的聚合。map-side聚合能有效減少shuffle的資料量,提高分組聚合運算的效率。map-side 聚合相關的引數如下:--啟用map-side聚合set hive.map.aggr=true;--hash map佔用map端記憶體的最大比例set hive.map.aggr.hash.percentmemory=0.5;
join優化
參與join的兩表一大一小,可考慮map join優化。Map Join相關引數如下:--啟用map join自動轉換set hive.auto.convert.join=true;--common join轉map join小表閾值set hive.auto.convert.join.noconditionaltask.size
資料傾斜
group導致資料傾斜map-side聚合skew groupby優化其原理是啟動兩個MR任務,第一個MR按照亂數分割區,將資料分散傳送到Reduce,完成部分聚合,第二個MR按照分組欄位分割區,完成最終聚合。相關引數如下:--啟用分組聚合資料傾斜優化set hive.groupby.skewindata=true; join導致資料傾斜使用map join啟動skew join相關引數如下:--啟用skew join優化set hive.optimize.skewjoin=true;--觸發skew join的閾值,若某個key的行數超過該引數值,則觸發set hive.skewjoin.key=100000;需要注意的是,skew join只支援Inner Join
任務並行度
對於一個分散式的計算任務而言,設定一個合適的並行度十分重要。在Hive中,無論其計算引擎是什麼,所有的計算任務都可分為Map階段和Reduce階段。所以並行度的調整,也可從上述兩個方面進行調整。
Map階段並行度
Map端的並行度,也就是Map的個數。是由輸入檔案的切片數決定的。一般情況下,Map端的並行度無需手動調整。Map端的並行度相關引數如下:
--可將多個小檔案切片,合併為一個切片,進而由一個map任務處理
set hive.input.format=org.apache.hadoop.hive.ql.io.CombineHiveInputFormat;
--一個切片的最大值
set mapreduce.input.fileinputformat.split.maxsize=256000000;
Reduce階段並行度
Reduce端的並行度,相對來說,更需要關注。預設情況下,Hive會根據Reduce端輸入資料的大小,估算一個Reduce並行度。但是在某些情況下,其估計值不一定是最合適的,此時則需要人為調整其並行度。
Reduce並行度相關引數如下:
--指定Reduce端並行度,預設值為-1,表示使用者未指定
set mapreduce.job.reduces;
--Reduce端並行度最大值
set hive.exec.reducers.max;
--單個Reduce Task計算的資料量,用於估算Reduce並行度
set hive.exec.reducers.bytes.per.reducer;
Reduce端並行度的確定邏輯為,若指定引數mapreduce.job.reduces的值為一個非負整數,則Reduce並行度為指定值。否則,Hive會自行估算Reduce並行度,估算邏輯如下:
假設Reduce端輸入的資料量大小為totalInputBytes
引數hive.exec.reducers.bytes.per.reducer的值為bytesPerReducer
引數hive.exec.reducers.max的值為maxReducers
則Reduce端的並行度為:
min(ceil2×totalInputBytesbytesPerReducer,maxReducers)
其中,Reduce端輸入的資料量大小,是從Reduce上游的Operator的Statistics(統計資訊)中獲取的。為保證Hive能獲得準確的統計資訊,需設定如下引數:
--執行DML語句時,收集表級別的統計資訊
set hive.stats.autogather=true;
--執行DML語句時,收集欄位級別的統計資訊
set hive.stats.column.autogather=true;
--計算Reduce並行度時,從上游Operator統計資訊獲得輸入資料量
set hive.spark.use.op.stats=true;
--計算Reduce並行度時,使用列級別的統計資訊估算輸入資料量
set hive.stats.fetch.column.stats=true;
小檔案合併
Map端輸入檔案合併
合併Map端輸入的小檔案,是指將多個小檔案劃分到一個切片中,進而由一個Map Task去處理。目的是防止為單個小檔案啟動一個Map Task,浪費計算資源。
相關引數為:
--可將多個小檔案切片,合併為一個切片,進而由一個map任務處理
set hive.input.format=org.apache.hadoop.hive.ql.io.CombineHiveInputFormat;
Reduce輸出檔案合併
合併Reduce端輸出的小檔案,是指將多個小檔案合併成大檔案。目的是減少HDFS小檔案數量。
相關引數為:
--開啟合併Hive on Spark任務輸出的小檔案
set hive.merge.sparkfiles=true;
CBO
開啟CBO可以自動調整join順序相關引數為:--是否啟用cbo優化set hive.cbo.enable=true;
謂詞下推
將過濾操作前移相關引數為:--是否啟動謂詞下推(predicate pushdown)優化set hive.optimize.ppd = true;需要注意的是:CBO優化也會完成一部分的謂詞下推優化工作,因為在執行計劃中,謂詞越靠前,整個計劃的計算成本就會越低。
向量化查詢
Hive的向量化查詢,可以極大的提高一些典型查詢場景(例如scans, filters, aggregates, and joins)下的CPU使用效率。相關引數如下:set hive.vectorized.execution.enabled=true;
Yarn設定推薦
需要調整的Yarn引數均與CPU、記憶體等資源有關,核心設定引數如下
yarn.nodemanager.resource.memory-mb 64
yarn.nodemanager.resource.cpu-vcores 16
yarn.scheduler.minmum-allocation-mb 512
yarn.sheduler.maximum-allocation-vcores 16384
yarn.scheduler.minimum-allocation-vcores 1
yarn.sheduler.maximum-allocation-vcores 2-4
yarn.nodemanager.resource.memory-mb該引數的含義是,一個NodeManager節點分配給Container使用的記憶體。該引數的設定,取決於NodeManager所在節點的總記憶體容量和該節點執行的其他服務的數量。考慮上述因素,此處可將該引數設定為64G,如下:<property>
<name>yarn.nodemanager.resource.memory-mb</name>
<value>65536</value>
</property>
yarn.nodemanager.resource.cpu-vcores該引數的含義是,一個NodeManager節點分配給Container使用的CPU核數。該引數的設定,同樣取決於NodeManager所在節點的總CPU核數和該節點執行的其他服務。考慮上述因素,此處可將該引數設定為16。<property>
<name>yarn.nodemanager.resource.cpu-vcores</name>
<value>16</value>
</property>
yarn.scheduler.maximum-allocation-mb該引數的含義是,單個Container能夠使用的最大記憶體。由於Spark的yarn模式下,Driver和Executor都執行在Container中,故該引數不能小於Driver和Executor的記憶體設定,推薦設定如下:<property>
<name>yarn.scheduler.maximum-allocation-mb</name>
<value>16384</value>
</property>
yarn.scheduler.minimum-allocation-mb該引數的含義是,單個Container能夠使用的最小記憶體,推薦設定如下:<property>
<name>yarn.scheduler.minimum-allocation-mb</name>
<value>512</value>
</property>
yarn排程策略使用容量排程,設定多個佇列如小任務佇列、大任務佇列、臨時需求佇列
根據設定佇列容量,在使用者端提交任務指定佇列
Spark設定推薦
Executor CPU核數設定
單個Executor的CPU核數,由spark.executor.cores引數決定,建議設定為4-6,具體設定為多少,視具體情況而定,原則是儘量充分利用資源。如單個節點共有16個核可供Executor使用,則spark.executor.core設定為4最合適。原因是,若設定為5,則單個節點只能啟動3個Executor,會剩餘1個核未使用;若設定為6,則只能啟動2個Executor,會剩餘4個核未使用。
spark.executor-cores 4
Executor CPU記憶體設定
spark.executor.memory用於指定Executor程序的堆記憶體大小,這部分記憶體用於任務的計算和儲存;spark.executor.memoryOverhead用於指定Executor程序的堆外記憶體,這部分記憶體用於JVM的額外開銷,作業系統開銷等。兩者的和才算一個Executor程序所需的總記憶體大小。預設情況下spark.executor.memoryOverhead的值等於spark.executor.memory*0.1。先按照單個NodeManager的核數和單個Executor的核數,計算出每個NodeManager最多能執行多少個Executor。在將NodeManager的總記憶體平均分配給每個Executor,最後再將單個Executor的記憶體按照大約10:1的比例分配到spark.executor.memory和spark.executor.memoryOverhead。
spark.executor-memory 14G
spark.executor.memoryOverhead 2G
Executor 個數設定
一個Spark應用Executor個數設定:executor個數是指分配給一個Spark應用的Executor個數,Executor個數對於Spark應用的執行速度有很大的影響,所以Executor個數的確定十分重要。一個Spark應用的Executor個數的指定方式有兩種,靜態分配和動態分配。
靜態分配可通過spark.executor.instances指定一個Spark應用啟動的Executor個數。這種方式需要自行估計每個Spark應用所需的資源,併為每個應用單獨設定Executor個數。
動態分配動態分配可根據一個Spark應用的工作負載,動態的調整其所佔用的資源(Executor個數)。這意味著一個Spark應用程式可以在執行的過程中,需要時,申請更多的資源(啟動更多的Executor),不用時,便將其釋放。在生產叢集中,推薦使用動態分配。
動態分配相關引數如下:
#啟動動態分配
spark.dynamicAllocation.enabled true
#啟用Spark shuffle服務
spark.shuffle.service.enabled true
#Executor個數初始值
spark.dynamicAllocation.initialExecutors 1
#Executor個數最小值
spark.dynamicAllocation.minExecutors 1
#Executor個數最大值
spark.dynamicAllocation.maxExecutors 12
#Executor空閒時長,若某Executor空閒時間超過此值,則會被關閉
spark.dynamicAllocation.executorIdleTimeout 60s
#積壓任務等待時長,若有Task等待時間超過此值,則申請啟動新的Executor
spark.dynamicAllocation.schedulerBacklogTimeout 1s
spark.shuffle.useOldFetchProtocol true
說明:Spark shuffle服務的作用是管理Executor中的各Task的輸出檔案,主要是shuffle過程map端的輸出檔案。由於啟用資源動態分配後,Spark會在一個應用未結束前,將已經完成任務,處於空閒狀態的Executor關閉。Executor關閉後,其輸出的檔案,也就無法供其他Executor使用了。需要啟用Spark shuffle服務,來管理各Executor輸出的檔案,這樣就能關閉空閒的Executor,而不影響後續的計算任務了。
Driver設定
Driver主要設定記憶體即可,相關的引數有
spark.driver.memory和spark.driver.memoryOverhead。
spark.driver.memory用於指定Driver程序的堆記憶體大小
spark.driver.memoryOverhead用於指定Driver程序的堆外記憶體大小。
預設情況下,兩者的關係如下:
spark.driver.memoryOverhead=spark.driver.memory*0.1。兩者的和才算一個Driver程序所需的總記憶體大小。
一般情況下,按照如下經驗進行調整即可:
假定yarn.nodemanager.resource.memory-mb設定為X,
若X>50G,則Driver可設定為12G,
若12G<X<50G,則Driver可設定為4G。
若1G<X<12G,則Driver可設定為1G。
yarn.nodemanager.resource.memory-mb為64G,則Driver的總記憶體可分配12G,所以上述兩個引數可設定為
spark.driver.memory 10G
spark.yarn.driver.memoryOverhead 2G
整體設定
修改spark-defaults.conf檔案
修改$HIVE_HOME/conf/spark-defaults.confspark.master yarn
spark.eventLog.enabled true
spark.eventLog.dir hdfs://myNameService1/spark-history
spark.executor.cores 4
spark.executor.memory 14g
spark.executor.memoryOverhead 2g
spark.driver.memory 10g
spark.driver.memoryOverhead 2g
spark.dynamicAllocation.enabled true
spark.shuffle.service.enabled true
spark.dynamicAllocation.executorIdleTimeout 60s
spark.dynamicAllocation.initialExecutors 1
spark.dynamicAllocation.minExecutors 1
spark.dynamicAllocation.maxExecutors 12
spark.dynamicAllocation.schedulerBacklogTimeout 1s
設定Spark shuffle服務Spark Shuffle服務的設定因Cluster Manager(standalone、Mesos、Yarn)的不同而不同。此處以Yarn作為Cluster Manager。
拷貝$SPARK_HOME/yarn/spark-3.0.0-yarn-shuffle.jar
到$HADOOP_HOME/share/hadoop/yarn/lib
$HADOOP_HOME/share/hadoop/yarn/lib/yarn/spark-3.0.0-yarn-shuffle.jar
修改$HADOOP_HOME/etc/hadoop/yarn-site.xml檔案
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle,spark_shuffle</value>
</property>
<property>
<name>yarn.nodemanager.aux-services.spark_shuffle.class</name>
<value>org.apache.spark.network.yarn.YarnShuffleService</value>
</property>
**本人部落格網站 **IT小神 www.itxiaoshen.com