聊聊兩個Go即將過時的GC優化策略
轉載請宣告出處哦~,本篇文章釋出於luozhiyun的部落格:https://www.luozhiyun.com
這篇文章本來是要講 Go Memory Ballast 以及 Go GC Tuner 來調整 GC 的策略,實現原理怎麼樣,效果如何。但是在寫的過程中,發現 Go 1.19版本出了,有個新特性讓這兩個優化終究成為歷史。
概述
首先我們來簡單的看一下 Go GC中做了什麼事,以及它裡面比較耗時的地方是什麼,我們才能對它進行優化。
首先對於 GC 來說有這麼幾個階段:
- sweep termination(清理終止):會觸發 STW ,所有的 P(處理器) 都會進入 safe-point(安全點);
- the mark phase(標記階段):恢復程式執行,GC 執行根節點的標記,這包括掃描所有的棧、全域性物件以及不在堆中的執行時資料結構;
- mark termination(標記終止):觸發 STW,扭轉 GC 狀態,關閉 GC 工作執行緒等;
- the sweep phase(清理階段):恢復程式執行,後臺並行清理所有的記憶體管理單元;
在這幾個階段中,由於標記階段是要從根節點對堆進行遍歷,對存活的物件進行著色標記,因此標記的時間和目前存活的物件有關,而不是與堆的大小有關,也就是堆上的垃圾物件並不會增加 GC 的標記時間。
並且對於現代作業系統來說釋放記憶體是一個非常快的操作,所以 Go 的 GC 時間很大程度上是由標記階段決定的,而不是清理階段。
在什麼時候會觸發 GC ?
我在這篇文章 https://www.luozhiyun.com/archives/475 做原始碼分析的時候有詳細的講到過,我這裡就簡單的說下。
在 Go 中主要會在三個地方觸發 GC:
1、監控執行緒 runtime.sysmon 定時呼叫;
2、手動呼叫 runtime.GC 函數進行垃圾收集;
3、申請記憶體時 runtime.mallocgc 會根據堆大小判斷是否呼叫;
runtime.sysmon
Go 程式在啟動的時候會後臺執行一個執行緒定時執行 runtime.sysmon 函數,這個函數主要用來檢查死鎖、執行計時器、排程搶佔、以及 GC 等。
它會執行 runtime.gcTrigger中的 test 函數來判斷是否應該進行 GC。由於 GC 可能需要執行時間比較長,所以執行時會在應用程式啟動時在後臺開啟一個用於強制觸發垃圾收集的 Goroutine 執行 forcegchelper 函數。
不過 forcegchelper 函數在一般情況下會一直被 goparkunlock 函數一直掛起,直到 sysmon 觸發GC 校驗通過,才會將該被掛起的 Goroutine 放轉身到全域性排程佇列中等待被排程執行 GC。
runtime.GC
這個比較簡單,會獲取當前的 GC 迴圈次數,然後設值為 gcTriggerCycle 模式呼叫 gcStart 進行迴圈。
runtime.mallocgc
我在記憶體分配 https://www.luozhiyun.com/archives/434 這一節講過,物件在進行記憶體分配的時候會按大小分成微物件、小物件和大物件三類分別執行 tiny malloc、small alloc、large alloc。
Go 的記憶體分配採用了池化的技術,類似 CPU 這樣的設計,分為了三級快取,分別是:每個執行緒單獨的快取池mcache、中心快取 mcentral 、堆頁 mheap 。
tiny malloc、small alloc 都會先去 mcache 中找空閒記憶體塊進行記憶體分配,如果 mcache 中分配不到記憶體,就要到 mcentral 或 mheap 中去申請記憶體,這個時候就會嘗試觸發 GC;而對於 large alloc 一定會嘗試觸發 GC 因為它直接在堆頁上分配記憶體。
如何控制 GC 是否應該被執行?
上面這三個觸發 GC 的地方最終都會呼叫 gcStart 執行 GC,但是在執行 GC 之前一定會先判斷這次呼叫是否應該被執行,並不是每次呼叫都一定會執行 GC, 這個時候就要說一下 runtime.gcTrigger中的 test 函數,這個函數負責校驗本次 GC 是否應該被執行。
runtime.gcTrigger中的 test 函數最終會根據自己的三個策略,判斷是否應該執行GC:
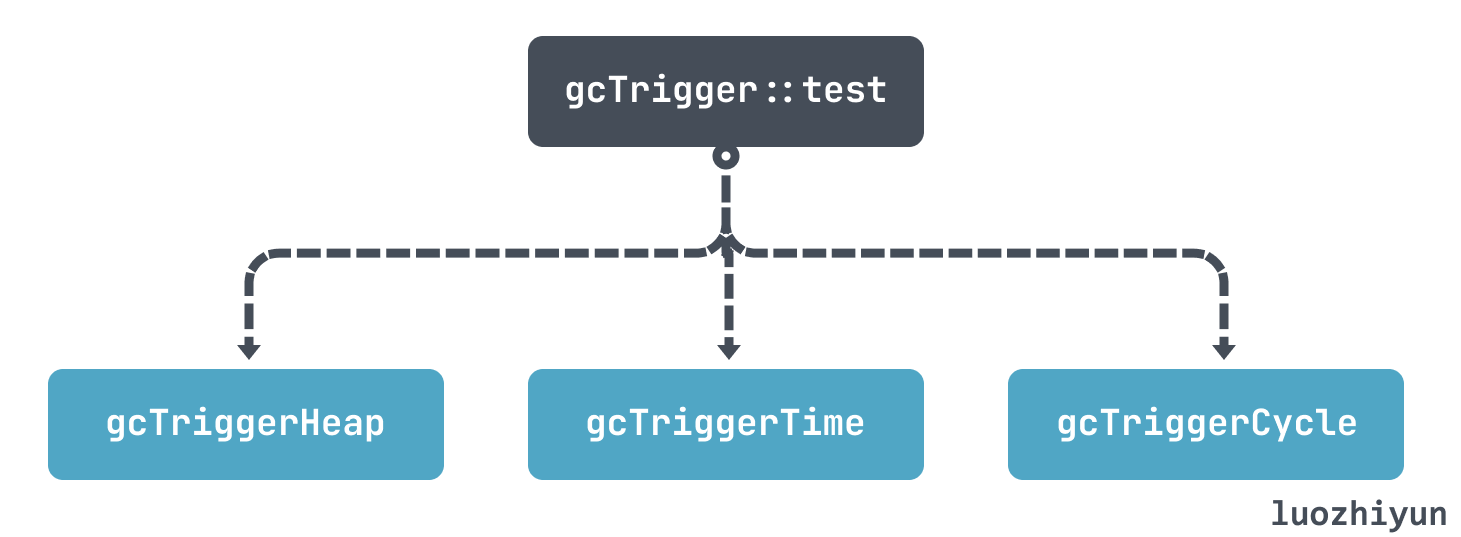
- gcTriggerHeap:按堆大小觸發,堆大小和上次 GC 時相比達到一定閾值則觸發;
- gcTriggerTime:按時間觸發,如果超過 forcegcperiod(預設2分鐘) 時間沒有被 GC,那麼會執行GC;
- gcTriggerCycle:沒有開啟垃圾收集,則觸發新的迴圈;
如果是 gcTriggerHeap 策略,那麼會根據 runtime.gcSetTriggerRatio 函數中計算的值來判斷是否要進行 GC,主要是由環境變數 GOGC(預設值為100 ) 決定閾值是多少。
我們可以大致認為,觸發 GC 的時機是由上次 GC 時的堆記憶體大小,和當前堆記憶體大小值對比的增長率來決定的,這個增長率就是環境變數 GOGC,預設是 100 ,計算公式可以大體理解為:
hard_target = live_dataset + live_dataset * (GOGC / 100).
假設目前是 100M 記憶體佔用,那麼根據上面公式,會到 200M 的時候才會觸發 GC。
觸發 GC 的時機其實並不只是 GOGC 單一變數決定的,在程式碼 runtime.gcSetTriggerRatio 裡面我們可以看到它控制的是一個範圍:
func gcSetTriggerRatio(triggerRatio float64) {
// gcpercent 由環境變數 GOGC 決定
if gcpercent >= 0 {
// 預設是 1
scalingFactor := float64(gcpercent) / 100
// 最大的 maxTriggerRatio 是 0.95
maxTriggerRatio := 0.95 * scalingFactor
if triggerRatio > maxTriggerRatio {
triggerRatio = maxTriggerRatio
}
// 最大的 minTriggerRatio 是 0.6
minTriggerRatio := 0.6 * scalingFactor
if triggerRatio < minTriggerRatio {
triggerRatio = minTriggerRatio
}
} else if triggerRatio < 0 {
triggerRatio = 0
}
memstats.triggerRatio = triggerRatio
trigger := ^uint64(0)
if gcpercent >= 0 {
// 當前標記存活的大小乘以1+係數triggerRatio
trigger = uint64(float64(memstats.heap_marked) * (1 + triggerRatio))
...
}
memstats.gc_trigger = trigger
...
}
具體閾值計算是比較複雜的,從 gcControllerState.endCycle 函數中可以看到執行 GC 的時機還要看以下幾個因素:
- 當前 CPU 佔用率,GC 標記階段最高不能超過整個應用的 25%;
- 輔助 GC 標記物件 CPU 佔用率;
- 目標增長率(預估),該值等於:(下次 GC 完後堆大小 - 堆存活大小)/ 堆存活大小;
- 堆實際增長率:堆總大小/上次標記完後存活大小-1;
- 上次GC時觸發的堆增長率大小;
這些綜合因素計算之後得到的一個值就是本次的觸發 GC 堆增長率大小。這些都可以通過 GODEBUG=gctrace=1,gcpacertrace=1 列印出來。
下面我們看看一個具體的例子:
package main
import (
"fmt"
)
func allocate() {
_ = make([]byte, 1<<20)
}
func main() {
fmt.Println("start.")
fmt.Println("> loop.")
for {
allocate()
}
fmt.Println("< loop.")
}
使用 gctrace 跟蹤 GC 情況:
[root@localhost gotest]# go build main.go
[root@localhost gotest]# GODEBUG=gctrace=1 ./main
start.
> loop.
...
gc 1409 @0.706s 14%: 0.009+0.22+0.076 ms clock, 0.15+0.060/0.053/0.033+1.2 ms cpu, 4->6->2 MB, 5 MB goal, 16 P
gc 1410 @0.706s 14%: 0.007+0.26+0.092 ms clock, 0.12+0.050/0.070/0.030+1.4 ms cpu, 4->7->3 MB, 5 MB goal, 16 P
gc 1411 @0.707s 14%: 0.007+0.36+0.059 ms clock, 0.12+0.047/0.092/0.017+0.94 ms cpu, 5->7->2 MB, 6 MB goal, 16 P
...
< loop.
上面展示了 3 次 GC 的情況,下面我們看看:
gc 1410 @0.706s 14%: 0.007+0.26+0.092 ms clock, 0.12+0.050/0.070/0.030+1.4 ms cpu, 4->7->3 MB, 5 MB goal, 16 P
記憶體
4 MB:標記開始前堆佔用大小 (in-use before the Marking started)
7 MB:標記結束後堆佔用大小 (in-use after the Marking finished)
3 MB:標記完成後存活堆的大小 (marked as live after the Marking finished)
5 MB goal:標記完成後正在使用的堆記憶體的目標大小 (Collection goal)
可以看到這裡標記結束後堆佔用大小是7 MB,但是給出的目標預估值是 5 MB,你可以看到回收器超過了它設定的目標2 MB,所以它這個目標值也是不準確的。
在 1410 次 GC 中,最後標記完之後堆大小是 3 MB,所以我們可以大致根據 GOGC 推測下次 GC 時堆大小應該不超過 6MB,所以我們可以看看 1411 次GC:
gc 1411 @0.707s 14%: 0.007+0.36+0.059 ms clock, 0.12+0.047/0.092/0.017+0.94 ms cpu, 5->7->2 MB, 6 MB goal, 16 P
記憶體
5 MB:標記開始前堆佔用大小 (in-use before the Marking started)
7 MB:標記結束後堆佔用大小 (in-use after the Marking finished)
2 MB:標記完成後存活堆的大小 (marked as live after the Marking finished)
6 MB goal:標記完成後正在使用的堆記憶體的目標大小 (Collection goal)
可以看到在 1411 次GC啟動時堆大小是 5 MB 是在控制範圍之內。
說了這麼多 GC 的機制,那麼有沒有可能 GC 的速度趕不上製造垃圾的速度呢?這就引出了 GC 中的另一種機制:Mark assist。
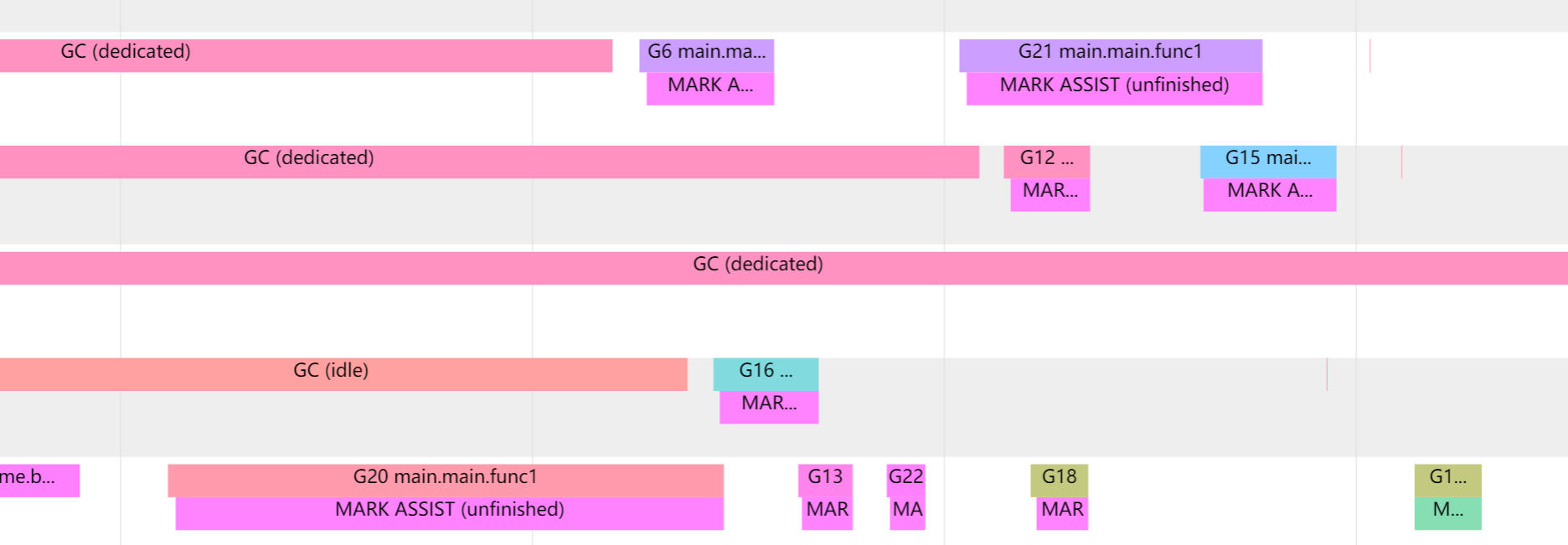
如果收集器確定它需要減慢分配速度,它將招募應用程式 Goroutines 來協助標記工作。這稱為 Mark assist 標記輔助。這也就是為什麼在分配記憶體的時候還需要判斷要不要執行 mallocgc 進行 GC。
在進行 Mark assist 的時候 Goroutines 會暫停當前的工作,進行輔助標記工作,這會導致當前 Goroutines 工作的任務有一些延遲。
而我們的 GC 也會盡可能的消除 Mark assist ,所以會讓下次的 GC 時間更早一些,也就會讓 GC 更加頻繁的觸發。
我們可以通過 go tool trace 來觀察到 Mark assist 的情況:
Go Memory Ballast
上面我們熟悉了 Go GC 的策略之後,我們來看看 Go Memory Ballast 是怎麼優化 GC 的。下面先看一個例子:
func allocate() {
_ = make([]byte, 1<<20)
}
func main() {
ballast := make([]byte, 200*1024*1024) // 200M
for i := 0; i < 10; i++ {
go func() {
fmt.Println("start.")
fmt.Println("> loop.")
for {
allocate()
}
fmt.Println("< loop.")
}()
}
runtime.KeepAlive(ballast)
我們執行上面的程式碼片段,然後我們對資源利用的情況進行簡單的統計:
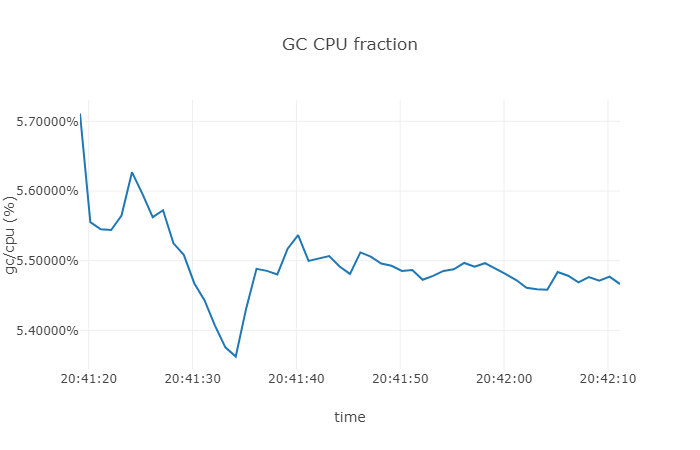
從上面的結果我們可以直到,GC 的 CPU 利用率大約在 5.5 % 左右。
下面我們把 ballast 記憶體佔用去掉,看看會是多少:
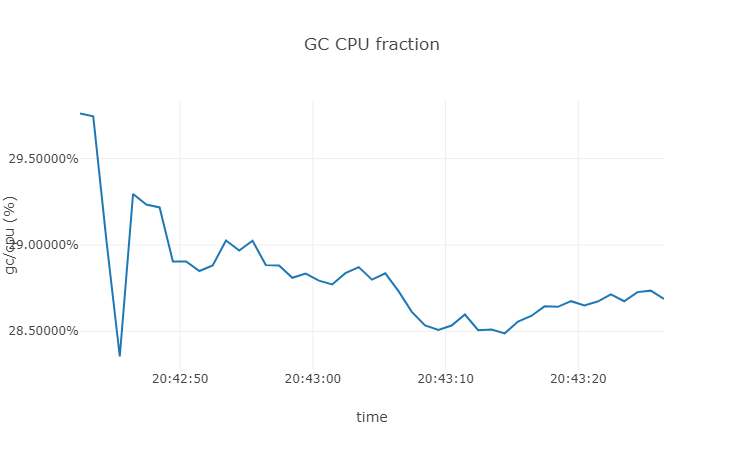
可以看到在沒有 ballast 的時候 GC 的 CPU佔用在 28% 左右。對 GC 的其他資訊感興趣的朋友可以使用 runtime.Memstats 定期抓取 GC 的資訊進行列印。
那麼為什麼在申請了一個空的陣列之後 CPU 佔用會低這麼多?首先我們在概述也講到了,GC 會根據環境變數 GOGC 來決定下次 GC 的執行時機,所以如果我們申請了200M的陣列,那麼下次 GC 的時候大約會在 400M。由於我們上面的例子中,allocate 函數申請的物件都是臨時物件,在 GC 之後會被再次減少到 200M 左右,所以下次執行 GC 的時機會被再次設定到 400M 。
但是如果沒有 ballast 陣列,感興趣的可以自行去測試一下,大約會在 4M 左右的時候會觸發 GC,這無疑對於臨時變數比較多的系統來說會造成相當頻繁的 GC。
總之,通過設定 ballast 陣列我們達到了延遲 GC 的效果,但是這種效果只會在臨時變數比較多的系統中有用,對於全域性變數多的系統,用處不大。
那麼還有一個問題,在系統中無故申請 200M 這麼大的記憶體會不會對記憶體造成浪費?畢竟記憶體這麼貴。其實不用擔心,只要我們沒有對 ballast 陣列進行讀寫,是不會真正用到實體記憶體佔用的,我們可以用下面的例子看一下:
func main() {
_ = make([]byte, 100<<20)
<-time.After(time.Duration(math.MaxInt64))
}
$ ps -eo pmem,comm,pid,maj_flt,min_flt,rss,vsz --sort -rss | numfmt --header --to=iec --field 4-5 | numfmt --header --from-unit=1024 --to=iec --field 6-7 | column -t | egrep "[t]est|[P]ID"
%MEM COMMAND PID MAJFL MINFL RSS VSZ
0.0 test_alloc 31248 0 1.1K 7.4M 821M
可以看到虛擬記憶體VSZ佔用很大,但是RSS 程序分配的記憶體大小很小。
func main() {
ballast := make([]byte, 100<<20)
for i := 0; i < len(ballast)/2; i++ {
ballast[i] = byte('A')
}
<-time.After(time.Duration(math.MaxInt64))
}
$ ps -eo pmem,comm,pid,maj_flt,min_flt,rss,vsz --sort -rss | numfmt --header --to=iec --field 4-5 | numfmt --header --from-unit=1024 --to=iec --field 6-7 | column -t | egrep "[t]est|[P]ID"
%MEM COMMAND PID MAJFL MINFL RSS VSZ
0.4 test_alloc 31692 0 774 60M 821M
但是如果我們要對它進行寫入操作,RSS 程序分配的記憶體大小就會變大,剩下的可以自己去驗證。
對於 Go Ballast 的討論其實很早就有人提過 issue ,其實官方只需要加一個最小堆大小的引數即可,但是一直沒有得到實現。相比之下 Java 就好很多GC 的調優引數,InitialHeapSize 就可以設定堆的初始值。
這也導致了很多對效能要求比較高的專案如: tidb,cortex 都在程式碼里加了一個這樣的空陣列實現。
Go GC Tuner
這個方法其實是來自 uber 的這篇文章裡面介紹的。根本問題還是因為 Go 的 GC 太頻繁了,導致標記佔用了很高的 CPU,但是 Go 也提供了 GOGC 來調整 GC 的時機,那麼有沒有一種辦法可以動態的根據當前的記憶體調整 GOGC 的值,由此來控制 GC 的頻率呢?
在 Go 中其實提供了 runtime.SetFinalizer 函數,它會在物件被 GC 的時候最後回撥一下。在 Go 中 它是這麼定義的:
type any = interface{}
func SetFinalizer(obj any, finalizer any)
obj 一般來說是一個物件的指標;finalizer 是一個函數,它接受單個可以直接用 obj 型別值賦值的引數。也就是說 SetFinalizer 的作用就是將 obj 物件的解構函式設定為 finalizer,當垃圾收集器發現 obj 不能再直接或間接存取時,它會清理 obj 並呼叫 finalizer。
所以我們可以通過它來設定一個勾點,每次 GC 完之後檢查一下記憶體情況,然後設定 GOGC 值:
type finalizer struct {
ref *finalizerRef
}
type finalizerRef struct {
parent *finalizer
}
func finalizerHandler(f *finalizerRef) {
// 為 GOGC 動態設值
getCurrentPercentAndChangeGOGC()
// 重新設定回去,否則會被真的清理
runtime.SetFinalizer(f, finalizerHandler)
}
func NewTuner(options ...OptFunc) *finalizer {
// 處理傳入的引數
...
f := &finalizer{}
f.ref = &finalizerRef{parent: f}
runtime.SetFinalizer(f.ref, finalizerHandler)
// 設定為 nil,讓 GC 認為原 f.ref 函數是垃圾,以便觸發 finalizerHandler 呼叫
f.ref = nil
return f
}
上面的這段程式碼就利用了 finalizer 特性,在 GC 的時候會呼叫 getCurrentPercentAndChangeGOGC 重新設定 GOGC 值,由於 finalizer 會延長一次物件的生命週期,所以我們可以在 finalizerHandler 中設定完 GOGC 之後再次呼叫 SetFinalizer 將物件重新系結在 Finalizer 上。
這樣構成一個迴圈,每次 GC 都會有一個 finalizerRef 物件在動態的根據當前記憶體情況改變 GOGC 值,從而達到調整 GC 次數,節約資源的目的。
上面我們也提到過,GC 基本上根據本次 GC 之後的堆大小來計算下次 GC 的時機:
hard_target = live_dataset + live_dataset * (GOGC / 100).
比如本次 GC 完之後堆大小 live_dataset 是 100 M,對於 GOGC 預設值 100 來說會在堆大小 200M 的時候觸發 GC。
為了達到最大化利用記憶體,減少 GC 次數的目的,那麼我們可以將 GOGC 設定為:
(可使用記憶體最大百分比 - 當前佔記憶體百分比)/當前佔記憶體百分比 * 100
也就是說如果有一臺機器,全部記憶體都給我們應用使用,應用當前佔用 10%,也就是 100M,那麼:
GOGC = (100%-10%)/10% * 100 = 900
然後根據上面 hard_target 計算公式可以得知,應用將在堆佔用達到 1G 的時候開始 GC。當然我們生產當中不可能那麼極限,具體的最大可使用記憶體最大百分比還需要根據當前情況進行調整。
那麼換算成程式碼,我們的 getCurrentPercentAndChangeGOGC 就可以這麼寫:
var memoryLimitInPercent float64 = 100
func getCurrentPercentAndChangeGOGC() {
p, _ := process.NewProcess(int32(os.Getpid()))
// 獲取當前應用佔用百分比
memPercent, _ := p.MemoryPercent()
// 計算 GOGC 值
newgogc := (memoryLimitInPercent - float64(memPercent)) / memPercent * 100.0
// 設定 GOGC 值
debug.SetGCPercent(int(newgogc))
}
上面這段程式碼我省去了很多例外處理,預設處理,以及 memoryLimitInPercent 寫成了一個固定值,在真正使用的時候,程式碼還需要再完善一下。
寫到這裡,上面 Go Memory Ballast 和 Go GC Tuner 已經達到了我們的優化目的,但是在我即將提稿的時候,曹春暉大佬發了一篇文章中,說到最新的 Go 版本中 1.19 beta1版本中新加了一個 debug.SetMemoryLimit 函數。
Soft Memory Limit
這一個優化來自 issue#48409,在 Go 1.19 版本中被加入,優化原理實際上和上面差不多,通過內建的 debug.SetMemoryLimit 函數我們可以調整觸發 GC 的堆記憶體目標值,從而減少 GC 次數,降低GC 時 CPU 佔用的目的。
在上面我們也講了,Go 實現了三種策略觸發 GC ,其中一種是 gcTriggerHeap,它會根據堆的大小設定下次執行 GC 的堆目標值。 1.19 版的程式碼正是對 gcTriggerHeap 策略做了修改。
通過程式碼呼叫我們可以知道在 gcControllerState。heapGoalInternal 計算 HeapGoal 的時候使用了兩種方式,一種是通過 GOGC 值計算,另一種是通過 memoryLimit 值計算,然後取它們兩個中小的值作為 HeapGoal。
func (c *gcControllerState) heapGoalInternal() (goal, minTrigger uint64) {
// Start with the goal calculated for gcPercent.
goal = c.gcPercentHeapGoal.Load() //通過 GOGC 計算 heapGoal
// 通過 memoryLimit 計算 heapGoal,並和 goal 比較大小,取小的
if newGoal := c.memoryLimitHeapGoal(); go119MemoryLimitSupport && newGoal < goal {
goal = newGoal
} else {
...
}
return
}
gcPercentHeapGoal 的計算方式如下:
func (c *gcControllerState) commit(isSweepDone bool) {
...
gcPercentHeapGoal := ^uint64(0)
if gcPercent := c.gcPercent.Load(); gcPercent >= 0 {
// HeapGoal = 存活堆大小 + (存活堆大小+棧大小+全域性變數大小)* GOGC/100
gcPercentHeapGoal = c.heapMarked + (c.heapMarked+atomic.Load64(&c.lastStackScan)+atomic.Load64(&c.globalsScan))*uint64(gcPercent)/100
}
c.gcPercentHeapGoal.Store(gcPercentHeapGoal)
...
}
和我們上面提到的 hard_target 計算差別不大,可以理解為:
HeapGoal = live_dataset + (live_dataset+棧大小+全域性變數大小)* GOGC/100
我們再看看memoryLimitHeapGoal計算:
func (c *gcControllerState) memoryLimitHeapGoal() uint64 {
var heapFree, heapAlloc, mappedReady uint64
heapFree = c.heapFree.load()
heapAlloc = c.totalAlloc.Load() - c.totalFree.Load()
mappedReady = c.mappedReady.Load()
memoryLimit := uint64(c.memoryLimit.Load())
nonHeapMemory := mappedReady - heapFree - heapAlloc
...
goal := memoryLimit - nonHeapMemory
...
return goal
}
上面這段程式碼基本上可以理解為:
goal = memoryLimit - 非堆記憶體
所以正因為 Go GC 的觸發是取上面兩者計算結果較小的值,那麼原本我們使用 GOGC 填的太大怕導致 OOM,現在我們可以加上 memoryLimit 引數限制一下;或者直接 GOGC = off ,然後設定 memoryLimit 引數,通過它來調配我們的 GC。
總結
我們這篇主要通過講解 Go GC 的觸發機制,然後引出利用這個機制可以比較 hack 的方式減少 GC 次數,從而達到減少 GC 消耗。
Go Memory Ballast 主要是通過預設一個大陣列,讓 Go 在啟動的時候提升 Go 下次觸發 GC 的堆記憶體閾值,從而避免在記憶體夠用,但是應用內臨時變數較多時不斷 GC 所產生的不必要的消耗。
Go GC Tuner 主要時通過 Go 提供的 GC 勾點,設定 Finalizer 在 GC 完之後通過當前的記憶體使用情況動態設定 GOGC,從而達到減少 GC 的目的。
Soft Memory Limit 是1.19版本的新特性,通過內建的方式實現了 GC 的控制,通過設定 memoryLimit 控制 GC 記憶體觸發閾值達到減少 GC 的目的,原理其實和上面兩種方式沒有本質區別,但是由於內建在 GC 環節,可以更精細化的檢查當前的非堆記憶體佔用情況,從而實現更精準控制。
Reference
https://github.com/golang/go/issues/23044
https://www.cnblogs.com/457220157-FTD/p/15567442.html
https://github.com/golang/go/issues/42430
https://eng.uber.com/how-we-saved-70k-cores-across-30-mission-critical-services/
https://xargin.com/dynamic-gogc/
https://github.com/cch123/gogctuner
https://golang.design/under-the-hood/zh-cn/part2runtime/ch08gc/pacing/
https://medium.com/a-journey-with-go/go-finalizers-786df8e17687
https://draveness.me/golang/docs/part3-runtime/ch07-memory/golang-garbage-collector
https://xargin.com/the-new-api-for-heap-limit/
https://pkg.go.dev/runtime/debug@master
https://tip.golang.org/doc/go1.19
https://github.com/golang/go/issues/48409
