大規模資料分析統一引擎Spark最新版本3.3.0入門實戰
@
概述
定義
Spark 官網 https://spark.apache.org/
Spark 官網最新檔案檔案 https://spark.apache.org/docs/latest/
Spark GitHub原始碼地址 https://github.com/search?q=spark
Apache Spark™是一個開源的、分散式、多語言引擎,用於在單節點機器或叢集上執行資料工程、資料科學和機器學習,用於大規模資料分析的統一引擎。目前最新版本為3.3.0
- Spark是用於大規模資料處理的統一分析引擎,也可以說是目前用於可伸縮計算的最廣泛的引擎,成千上萬的公司包括財富500強中的80%都在使用。
- Spark生態系統整合了豐富的資料科學、機器學習、SQL分析和BI、儲存和基礎設施等框架,並將這個生態使用可以擴充套件到數千臺機器大規模資料使用。
- Spark提供了Java、Scala、Python和R的高階api,以及支援通用執行圖的優化引擎。
- Spark支援一系列豐富的高階工具,包括用於SQL和結構化資料處理的Spark SQL,用於pandas工作負載的Spark上的pandas API,用於機器學習的MLlib,用於圖形處理的GraphX,以及用於增量計算和流處理的Structured Streaming。
Hadoop與Spark的關係與區別
- 框架比較

- 處理流程比較
-
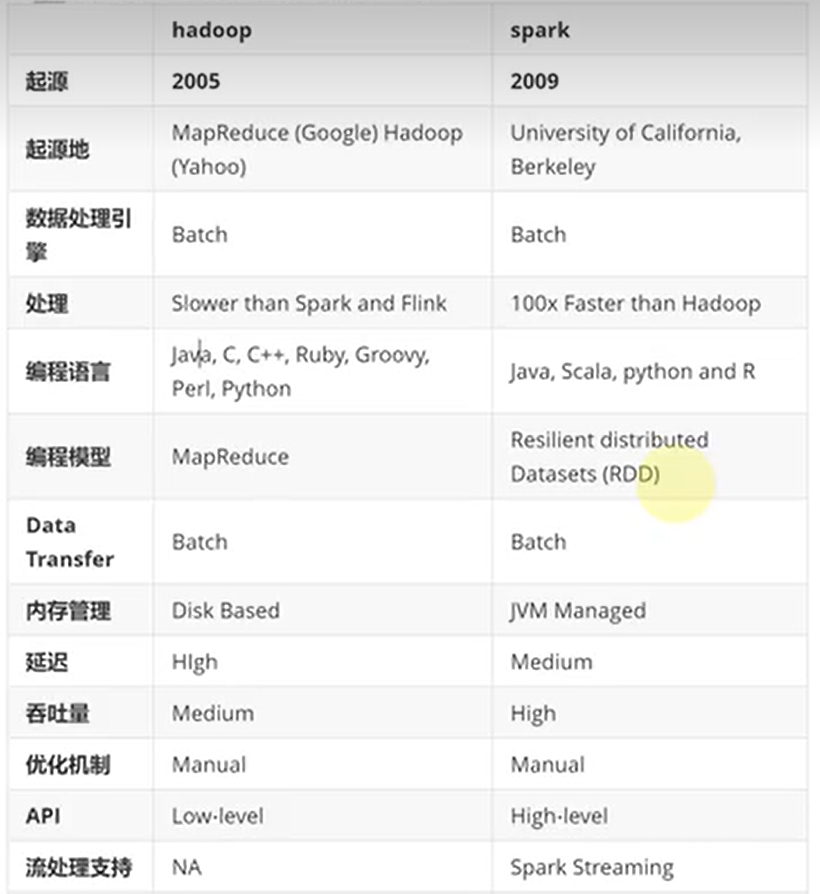
spark是借鑑了Mapreduce,並在其基礎上發展起來的,繼承了其分散式計算的優點並進行了改進,spark生態更為豐富,功能更為強大,效能更加適用範圍廣,mapreduce更簡單,穩定性好。主要區別:
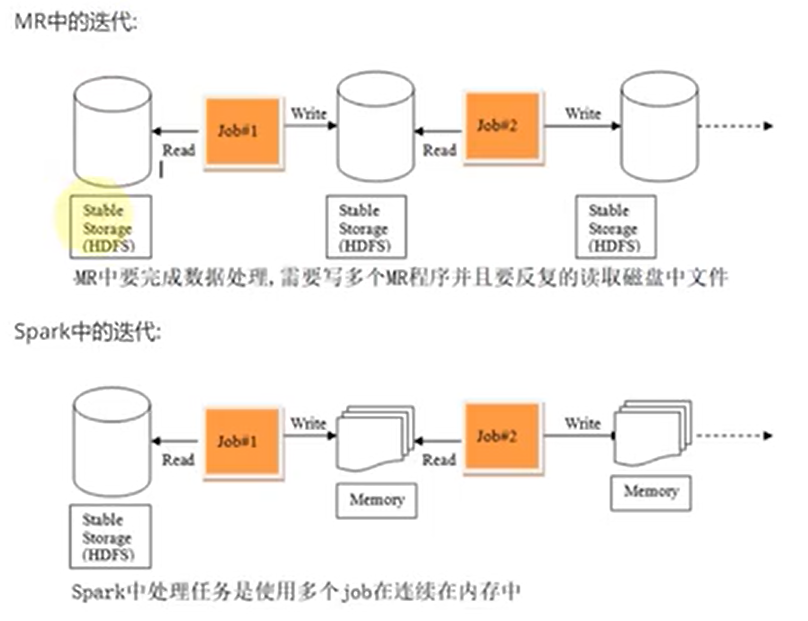
- spark把運算的中間資料(shuffle階段產生的資料)存放在記憶體,迭代計算效率更高,mapreduce的中間結果需要落地,儲存到磁碟;
- Spark容錯性高,它通過彈性分散式資料集RDD來實現高效容錯,RDD是一組分散式的儲存在節點記憶體中的唯讀性的資料集,這些集合石彈性的,某一部分丟失或者出錯,可以通過整個資料集的計算流程的血緣關係來實現重建,mapreduce的容錯只能重新計算;
- Spark更通用,提供了transformation和action這兩大類的多功能api,另外還有流式處理sparkstreaming模組、圖計算等等,mapreduce只提供了map和reduce兩種操作,流計算及其他的模組支援比較缺乏;
- Spark框架和生態更為複雜,有RDD,血緣lineage、執行時的有向無環圖DAG,stage劃分等,很多時候spark作業都需要根據不同業務場景的需要進行調優以達到效能要求,mapreduce框架及其生態相對較為簡單,對效能的要求也相對較弱,執行較為穩定,適合長期後臺執行;
- Spark計算框架對記憶體的利用和執行的並行度比mapreduce高,Spark執行容器為executor,內部ThreadPool中執行緒執行一個Task,mapreduce線上程內部執行container,container容器分類為MapTask和ReduceTask。Spark程式執行並行度高;
- Spark對於executor的優化,在JVM虛擬機器器的基礎上對記憶體彈性利用:storage memory與Execution memory的彈性擴容,使得記憶體利用效率更高;
-
特點與關鍵特性
Spark官網對其特點高度概括的四個單詞分為為:Simple-簡單、Fast-快、Scalable-可延伸、Unified-統一。
- 執行速度快。Spark使用先進的DAG(Directed Acyclic Graph,有向無環圖)執行引擎,以支援迴圈資料流與記憶體計算,基於記憶體的執行速度可比Hadoop MapReduce快上百倍,基於磁碟的執行速度也能快十倍。
- 簡單易使用。Spark支援使用Scala、Java、Python和R語言進行程式設計,簡潔的API設計有助於使用者輕鬆構建並行程式,並且可以通過Spark Shell進行互動式程式設計。
- 統一通用性。Spark提供了完整而強大的技術棧,包括SQL查詢、流式計算、機器學習和圖演演算法元件,這些元件可以無縫整合在同一個應用中,足以應對複雜的計算。
- 執行模式多樣。Spark可執行於獨立的叢集模式中,或者執行於Hadoop中,也可執行於Amazon EC2等雲環境中,並且可以存取HDFS、Cassandra、HBase、Hive等多種資料來源。
Spark關鍵特性包括:
- 批/串流媒體資料:使用多種語言:Python、SQL、Scala、Java或R來統一批次和實時流處理資料。
- SQL分析:為儀表板和特別報告執行快速的分散式ANSI SQL查詢。執行速度比大多數資料倉儲都快。
- 大規模資料科學:對pb級資料進行探索性資料分析(EDA),而不需要進行降取樣。
- 機器學習:在筆記型電腦上訓練機器學習演演算法,並使用相同的程式碼來擴充套件到由數千臺機器組成的容錯叢集。
元件

- Spark Core:為Spark的核心元件,實現了Spark的基本功能,包含任務排程、記憶體管理、錯誤恢復、與儲存系統互動等模組。Spark Core中還包含了對彈性分散式資料集(Resilient Distributed Datasets,RDD)的API定義,RDD是唯讀的分割區記錄的集合,只能基於在穩定物理儲存中的資料集和其他已有的RDD上執行確定性操作來建立;為其他 Spark 功能模組提供了核心層的支撐,可類比 Spring 框架中的 Spring Core。
- Spark SQL:用來操作結構化資料的核心元件,通過Spark SQL可以直接查詢Hive、 HBase等多種外部資料來源中的資料。Spark SQL的重要特點是能夠統一處理關係表和RDD在處理結構化資料時,開發人員無須編寫 MapReduce程式,直接使用SQL命令就能完成更加複雜的資料查詢操作。Spark SQL 適用於結構化表和非結構化資料的查詢,並且可以在執行時自適配執行計劃,支援 ANSI SQL(即標準的結構化查詢語言)。
- Spark Streaming:Spark提供的流式計算框架,支援高吞吐量、可容錯處理的實時流式資料處理,其核心原理是將流資料分解成一系列短小的批次處理作業,每個短小的批次處理作業都可以使用 Spark Core進行快速處理。Spark Streaming支援多種資料來源,如 Kafka以及TCP通訊端等。最為使用DStreams處理資料流的老的API。
- Structured Streaming:使用關係查詢處理結構化資料流(使用資料集和DataFrames,比DStreams更新的API);是從 spark2.0 開始引入了一套新的流式計算模型,基於 Spark SQl 引擎具有彈性和容錯的流式處理引擎. 使用 Structure Streaming 處理流式計算的方式和使用批次處理計算靜態資料(表中的資料)的方式是一樣的。
- MLlib:Spark提供的關於機器學習功能的演演算法程式庫,包括分類、迴歸、聚類、協同過濾演演算法等,還提供了模型評估、資料匯入等額外的功能,開發人員只需瞭解一定的機器學習演演算法知識就能進行機器學習方面的開發,降低了學習成本。
- GraphX: Spark提供的分散式圖處理框架,擁有圖計算和圖挖掘演演算法的API介面以及豐富的功能和運運算元,極大地方便了對分散式圖的處理需求,能在海量資料上執行復雜的圖演演算法。
叢集概述
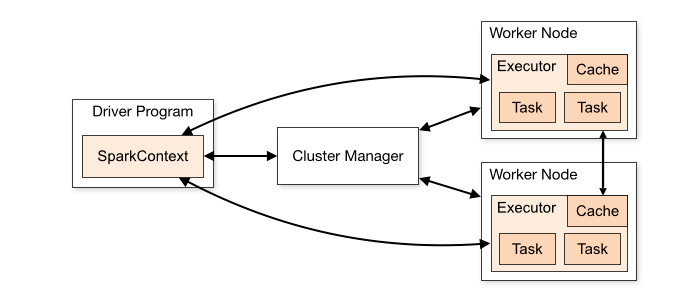
Spark應用程式在叢集中作為獨立的程序集執行,由主程式(稱為驅動程式)中的SparkContext物件協調。
- 執行在一個叢集上,SparkContext可以連線到幾種型別的叢集管理器(Spark自己獨立的叢集管理器,Mesos, YARN或Kubernetes),這些管理器在應用程式之間分配資源。
- 一旦連線上,Spark將獲得叢集中節點上的executor,這些executor是為應用程式執行計算和儲存資料的程序。
- 接下來將應用程式程式碼(由傳遞給SparkContext的JAR或Python檔案定義)傳送給執行器。
- 最後,SparkContext將任務傳送給執行器執行。
- 提交應用程式:可以使用spark-submit指令碼將應用程式提交到任何型別的叢集。
- 監控:Driver程式都有一個web UI,通常在4040埠上,顯示關於正在執行的任務、執行器和儲存使用的資訊。只需在web瀏覽器中存取http://
:4040就可以存取這個WEB UI。 - 作業排程:Spark提供了跨應用程式(在叢集管理器級別)和應用程式內部(如果多個計算髮生在同一個SparkContext上)的資源分配控制。
叢集術語
-
Application 基於Spark構建的使用者程式。由叢集上的驅動程式和執行程式組成。 Application jar 使用者的Spark應用程式Jar,包含他們的應用程式及其依賴項。使用者的jar包不應該包含Hadoop或Spark庫(這些庫會在執行時新增)。 Driver program 執行應用程式main()函數並建立SparkContext的程序 Cluster manager 獲取叢集資源的外部服務(例如standalone manager, Mesos, YARN, Kubernetes) Deploy mode 區分驅動程序執行的位置。在「叢集」模式下,框架在叢集內部啟動驅動程式。在「使用者端」模式下,提交者在叢集外啟動驅動程式。 Worker node 可以在叢集中執行應用程式程式碼的任何節點 Executor 在工作節點上為應用程式啟動的程序,它執行任務並跨任務將資料儲存在記憶體或磁碟儲存中。每個應用程式都有自己的執行器。 Task 將被傳送到一個執行程式的工作單元 Job 由多個任務組成的平行計算,這些任務響應Spark操作(例如 save,collect)Stage 每個任務被分成更小的任務集,稱為相互依賴的階段(類似於MapReduce中的map和reduce階段);
部署
概述
Spark作為一個資料處理框架和計算引擎,被設計在所有常見的叢集環境中執行, 在國內工作中主流的環境為Yarn,不過逐漸容器式環境也慢慢流行起來。
容器式環境:發現叢集規模不足夠,會自動化生成所需要的環境,不需要多餘叢集機器時,也會自動刪除。
Spark執行環境 = Java環境(JVM) + 叢集環境(Yarn) + Spark環境(lib)
[外連圖片轉存失敗,源站可能有防盜鏈機制,建議將圖片儲存下來直接上傳(img-WJRyiUk1-1662907653703)(http://www.itxiaoshen.com:3001/assets/1662907244159WcYf6J10.png)]
Spark既可以單獨執行,也可以通過多個現有的叢集管理器執行。目前它提供了幾種部署選項
- Local模式:多用於本地測試,如在Idea中編寫程式執行測試,本機提供資源 Spark提供計算。
- Standalone:Spark中自帶的一個簡單的資源排程框架,支援完全分散式。
- Apache Mesos:一個通用的資源管理和排程框架,也可以執行Hadoop MapReduce和服務應用程式。(棄用)
- Hadoop YARN:Hadoop 2和Hadoop 3中的資源管理器。Spark On Yarn是目前生產系統使用最多的部署方式
- Kubernetes:一個用於自動化部署、擴充套件和管理容器化應用程式的開源系統。Spark On K8s是未來的趨勢
環境準備
由於前面的文章已經搭建過Hadoop,環境預準備條件是類似,比如至少3臺機器的互通互聯、免密登入、時間同步、JDK如1.8版本安裝,這裡就不再說明了。
Local模式
所謂的Local模式,就是不需要其他任何節點資源就可以在本地執行Spark程式碼的環境
# 下載最新版本3.3.0
wget --no-check-certificate https://dlcdn.apache.org/spark/spark-3.3.0/spark-3.3.0-bin-hadoop3.tgz
# 解壓
tar -xvf spark-3.3.0-bin-hadoop3.tgz
# 拷貝一個部署spark-local目錄
spark-3.3.0-bin-hadoop3 spark-local
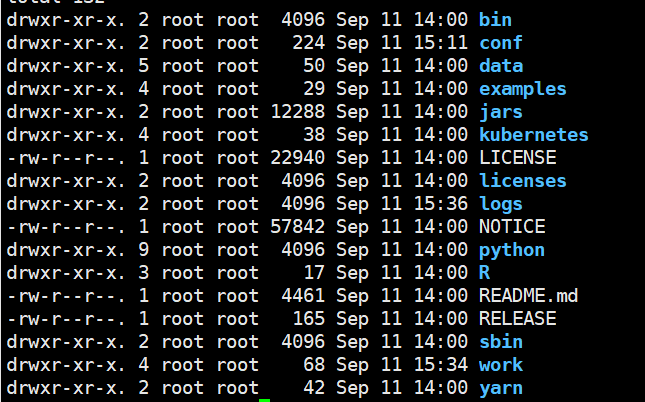
spark檔案目錄說明
- bin:可執行的二進位制命令檔案,指令碼檔案
- conf:組態檔,其中以.template字尾結尾的檔案不會起作用,稱為模板檔案
- data:官方提供的教學資料
- examples:官方案例
- jars:官方案例的jar包
- src:官方案例的原始碼
- jars:當前spark的lib,類庫
- kubernetes:容器式部署環境
- sbin:啟動關閉的指令碼命令
- python,R,yarn
# 提交應用
bin/spark-submit \
--class org.apache.spark.examples.SparkPi \
--master local[2] \
./examples/jars/spark-examples_2.12-3.3.0.jar \
10
引數說明:
- –class表示要執行程式的主類,此處可以更換為自己寫的應用程式。
- –master local[2] 部署模式,預設為本地模式,數位表示分配的虛擬CPU核數量。
- spark-examples_2.12-3.0.0.jar 執行的應用類所在的jar包,實際使用時,可以設定為自己打的jar包。
- 數位10表示程式的入口引數,用於設定當前應用的任務數量
Standalone部署
Standalone模式
Spark自身節點執行的叢集模式,也就是我們所謂的獨立部署(Standalone)模式,Spark的Standalone模式體現了經典的master-slave模式。
# 拷貝一個部署spark-standalone目錄
cp -r spark-3.3.0-bin-hadoop3 spark-standalone
# 進入目錄
cd spark-standalone/
cd conf
# 準備workers組態檔
mv workers.template workers
# 修改workers內容為
vi workers
hadoop1
hadoop2
hadoop3
# 準備spark-env.sh組態檔
mv spark-env.sh.template spark-env.sh
# spark-env.sh新增如下內容
vi spark-env.s
export JAVA_HOME=/home/commons/jdk8
SPARK_MASTER_HOST=hadoop1
SPARK_MASTER_PORT=7077
# 分發到其他兩臺上
scp -r /home/commons/spark-standalone hadoop2:/home/commons/
scp -r /home/commons/spark-standalone hadoop3:/home/commons/
# 進入根目錄下sbin執行目錄和啟動
cd sbin/
./start-all.sh

當前機器有Master和Worker程序,而另外其他兩臺上有worker程序
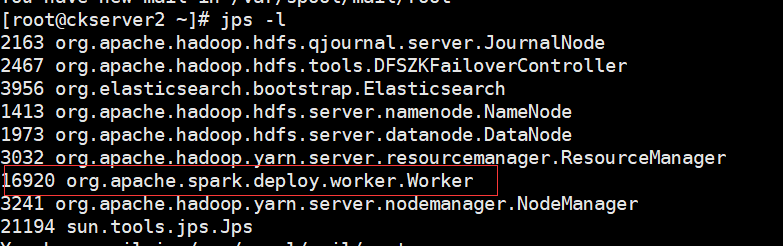
存取WebUi頁面:http://hadoop1:8080/ ,如果8080埠有其他服務使用,可以存取8081埠也能正常存取到當前這個Master的頁面(預設8081是Worker的)
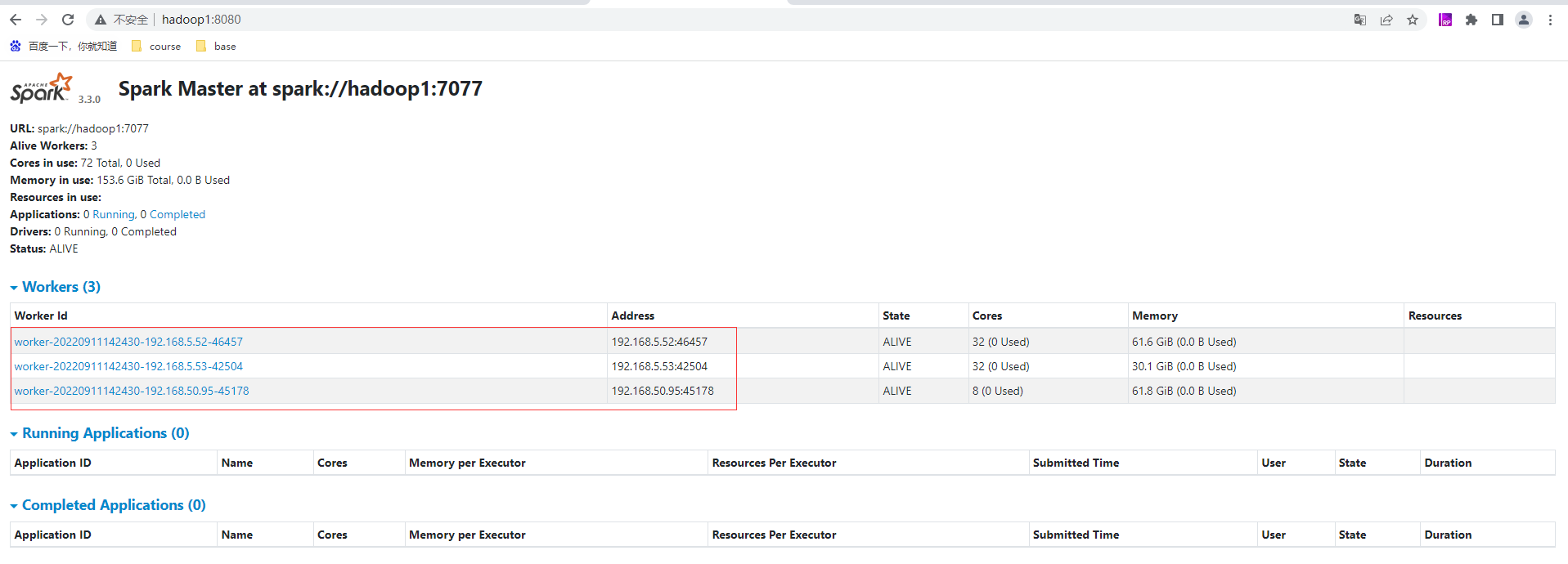
設定歷史服務
由於spark-shell 停止掉後,叢集監控頁面就看不到歷史任務的執行情況,所以開發時都設定歷史伺服器記錄任務執行情況。
# 先停止前面啟動的叢集
./stop-all.sh
# 準備spark-defaults.conf
cd ../conf
mv spark-defaults.conf.template spark-defaults.conf
# 修改spark-defaults.conf
vim spark-defaults.conf
spark.eventLog.enabled true
spark.eventLog.dir hdfs://myns:8020/sparkhis
# 需要啟動Hadoop叢集,HDFS上的目錄需要提前存在
hadoop fs -mkdir /sparkhis
# 修改spark-env.sh檔案,新增如下設定:
vi spark-env.sh
export SPARK_HISTORY_OPTS="
-Dspark.history.ui.port=18080
-Dspark.history.fs.logDirectory=hdfs://myns:8020/sparkhis
-Dspark.history.retainedApplications=30"
# 引數1含義:WEBUI存取的埠號為18080
# 引數2含義:指定歷史伺服器紀錄檔儲存路徑(讀)
# 引數3含義:指定儲存Application歷史記錄的個數,如果超過這個值,舊的應用程式資訊將被刪除,這個是記憶體中的應用數,而不是頁面上顯示的應用數。
由於hadoop是HA模式因此設定為hdfs-site.xml下的dfs.nameservices的value值
<property>
<name>dfs.nameservices</name>
<value>myns</value> <!--core-site.xml的fs.defaultFS使用該屬性值-->
</property>
# 分發設定到另外兩臺上
scp spark-defaults.conf spark-env.sh hadoop2:/home/commons/spark-standalone/conf/
scp spark-defaults.conf spark-env.sh hadoop3:/home/commons/spark-standalone/conf/
# 啟動叢集
./start-all.sh
# 啟動歷史服務
./start-history-server.sh
存取歷史服務的WebUI地址,http://hadoop1:18080/
高可用(HA)
所謂的高可用是因為當前叢集中的 Master 節點只有一個,所以會存在單點故障問題。所以為了解決單點故障問題,需要在叢集中設定多個 Master 節點,一旦處於活動狀態的 Master發生故障時,由備用 Master 提供服務,保證作業可以繼續執行。這裡的高可用一般採用Zookeeper 設定。這裡使用前面搭建Zookeeper 。
# 停止叢集
./stop-all.sh
# 停止歷史服務
./stop-history-server.sh
# 修改Spark中的 spark-env.sh 檔案,修改如下設定
# 註釋如下內容
#SPARK_MASTER_HOST=hadoop1
#SPARK_MASTER_PORT=7077
# 新增如下內容
export SPARK_DAEMON_JAVA_OPTS="
-Dspark.deploy.recoveryMode=ZOOKEEPER
-Dspark.deploy.zookeeper.url=zk1,zk2,zk3
-Dspark.deploy.zookeeper.dir=/spark"
# 分發設定到另外兩臺上
scp spark-env.sh hadoop2:/home/commons/spark-standalone/conf/
scp spark-env.sh hadoop3:/home/commons/spark-standalone/conf/
# 啟動叢集
./start-all.sh
# 在另外伺服器如hadoop2上啟動master
./start-master.sh
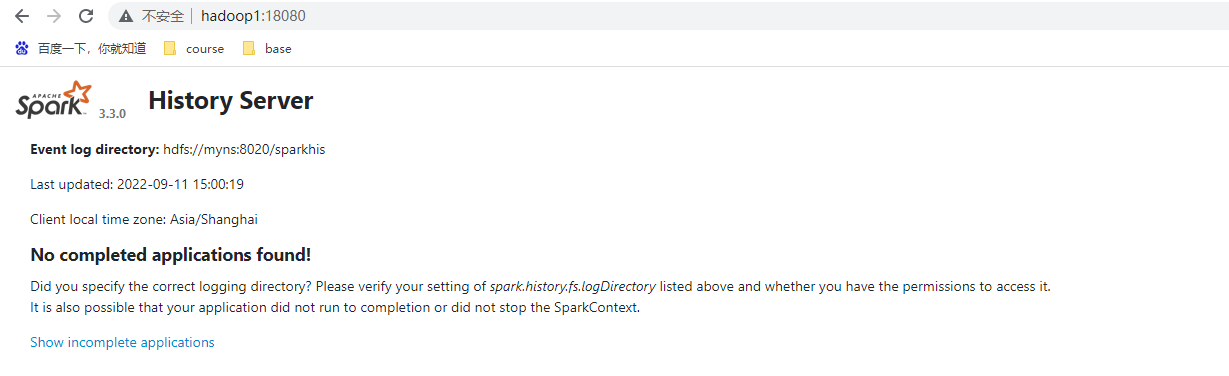
hadoop1的master為ALIVE狀態

hadoop2的master為STANDBY狀態
[外連圖片轉存失敗,源站可能有防盜鏈機制,建議將圖片儲存下來直接上傳(img-NVmFWDEw-1662907653726)(http://www.itxiaoshen.com:3001/assets/1662907298952BdHwc0Bh.png)]
提交應用到高可用叢集,注意提交master要填寫多個master地址
bin/spark-submit \
--class org.apache.spark.examples.SparkPi \
--master spark://hadoop1:7077,hadoop2:7077 \
./examples/jars/spark-examples_2.12-3.3.0.jar \
10
# 停止mALIVE狀態hadoop1的master
./stop-master.sh
hadoop2的master由原來的STANDBY狀態轉變為ALIVE狀態,實現高可用的切換
提交流程
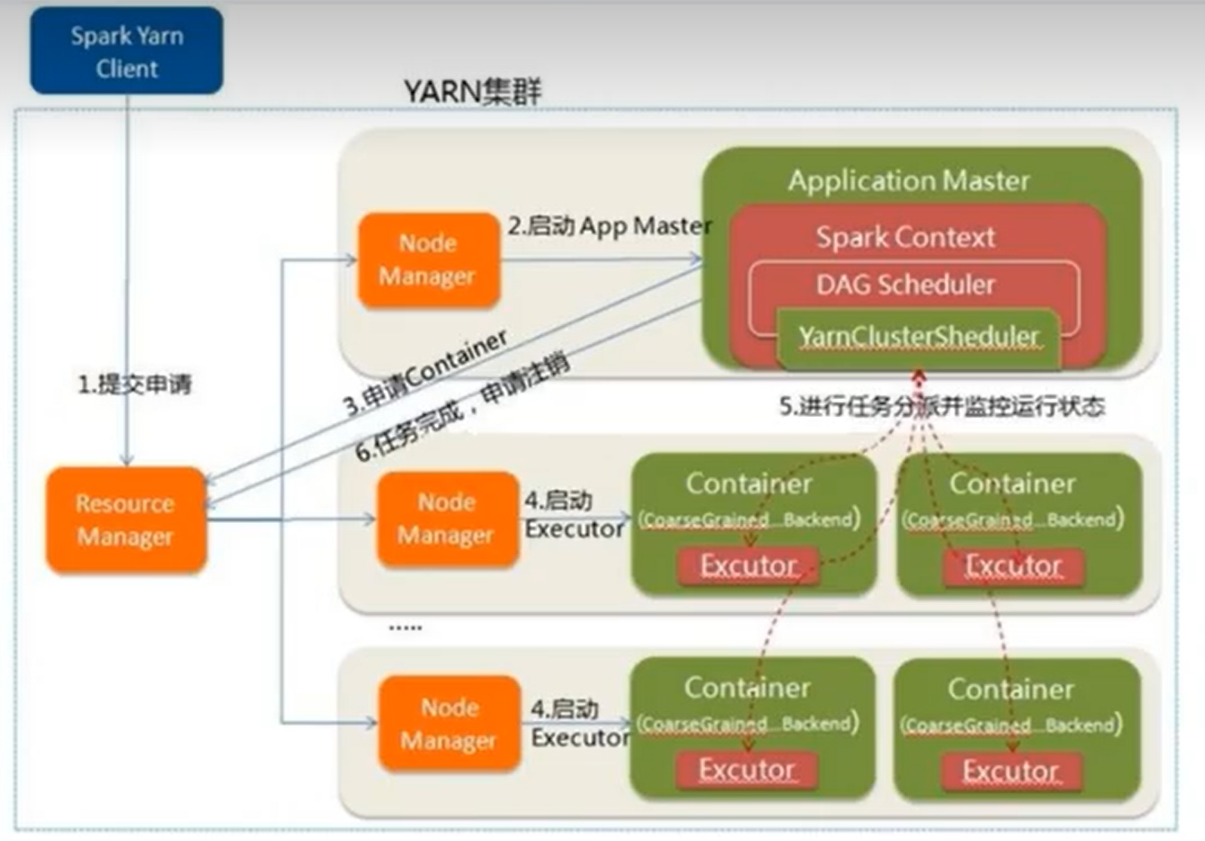
作業提交原理
[外連圖片轉存失敗,源站可能有防盜鏈機制,建議將圖片儲存下來直接上傳(img-GqM7w3Qz-1662907653730)(http://www.itxiaoshen.com:3001/assets/1662907304666dPiztcT6.png)]
Standalone-client 提交任務方式
# --deploy-mode client 可以省略,預設為client
bin/spark-submit \
--class org.apache.spark.examples.SparkPi \
--master spark://hadoop1:7077,hadoop2:7077 \
--deploy-mode client \
./examples/jars/spark-examples_2.12-3.3.0.jar \
10
# 其他引數提交應用
bin/spark-submit \
--master spark://hadoop1:7077 \
--class org.apache.spark.examples.SparkPi \
--driver-memory 500m \
--driver-cores 1 \
--executor-memory 800m \
--executor-cores 1 \
./examples/jars/spark-examples_2.12-3.3.0.jar \
10
引數說明:
- --class:表示要執行程式的主類,Spark程式中包含主函數的類
- --master:Spark程式執行的模式(環境) 模式:local[*]、spark://hadoop101:7077、 Yarn,spark://hadoop101:7077 獨立部署模式,連線到Spark叢集,Mater的地址和埠號。
- --executor-memory 1G 指定每個executor可用記憶體為1G 符合叢集記憶體設定即可,具體情況具體分析。
- --total-executor-cores 2 指定所有executor使用的cpu核數為2個。
- --executor-cores 指定每個executor使用的cpu核數。
- application-jar:打包好的應用jar,包含依賴。這個URL在叢集中全域性可見。 比如hdfs:// 共用儲存系統,如果是file:// path,那麼所有的節點的path都包含同樣的jar,spark-examples_2.12-3.0.0.jar 執行類所在的jar包
- application-arguments:數位10表示程式的入口引數,用於設定當前應用的任務數量
檢視WebUI後可以看到剛剛提交的任務app-20220911213322-0000資訊

執行任務時,會產生多個Java程序(用於計算)執行完成就會釋放掉。其中Master和Worker是資源,預設採用伺服器叢集節點的總核數,每個節點記憶體1024M。
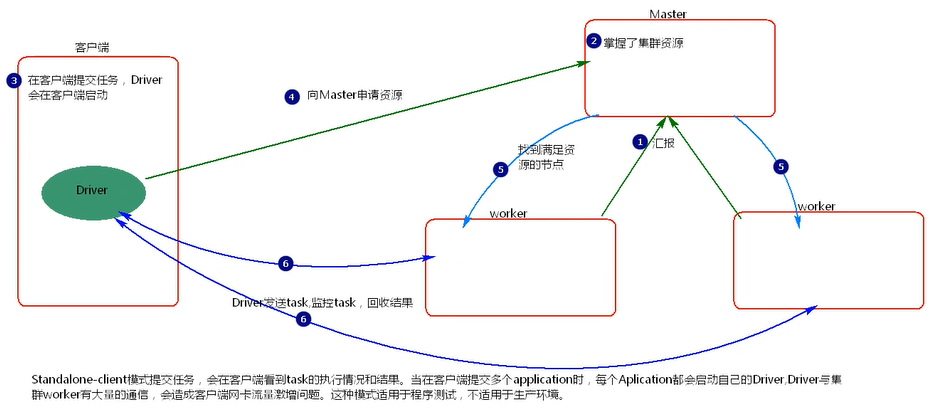
- client 模式提交任務後,會在使用者端啟動 Driver 程序。
- Driver 會向 Master 申請啟動 Application 啟動的資源。
- Master 收到請求之後會在對應的 Worker 節點上啟動 Executor
- Executor 啟動之後,會註冊給 Driver 端,Driver 掌握一批計算 資源。
- Driver 端將 task 傳送到 worker 端執行。worker 將 task 執行結 果返回到 Driver 端。
當在使用者端提交多個Spark application時,每個application都會啟動一個Driver。lient 模式適用於測試偵錯程式。Driver 程序是在使用者端啟動的,這裡的客 戶端就是指提交應用程式的當前節點。在 Driver 端可以看到 task 執行的情 況。生產環境下不能使用 client 模式,是因為:假設要提交 100 個,application 到叢集執行,Driver 每次都會在 client 端啟動,那麼就會導致 使用者端 100 次網路卡流量暴增的問題。client 模式適用於程式測試,不適用 於生產環境,在使用者端可以看到 task 的執行和結果
Standalone-cluster 提交任務方式
bin/spark-submit \
--class org.apache.spark.examples.SparkPi \
--master spark://hadoop1:7077,hadoop2:7077 \
--deploy-mode cluster \
./examples/jars/spark-examples_2.12-3.3.0.jar \
10
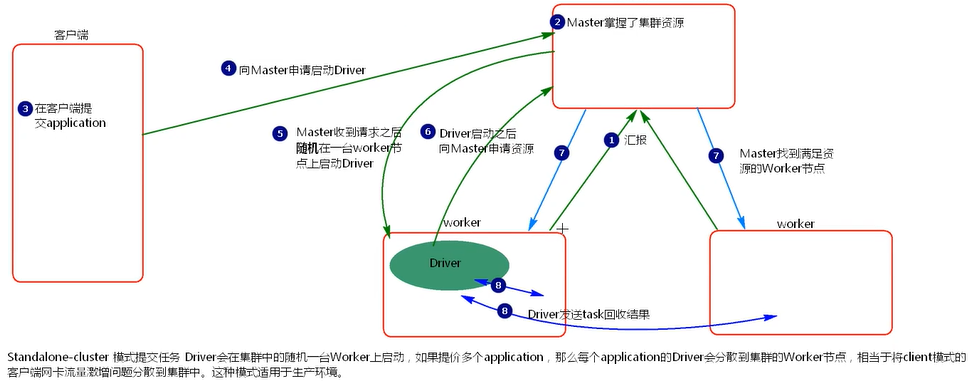
- cluster 模式提交應用程式後,會向 Master 請求啟動 Driver
- Master 接受請求,隨機在叢集一臺節點啟動 Driver 程序。
- Driver 啟動後為當前的應用程式申請資源。
- Driver 端傳送 task 到 worker 節點上執行。
- worker 將執行情況和執行結果返回給 Driver 端。
Driver 程序是在叢集某一臺 Worker 上啟動的,在使用者端是無法檢視 task 的執行情況的。假設要提交 100 個 application 到叢集執行,每次 Driver 會 隨機在叢集中某一臺 Worker 上啟動,那麼這 100 次網路卡流量暴增的問題 就散佈在叢集上。
Yarn部署
獨立部署(Standalone)模式由Spark自身提供計算資源,無需其他框架提供資源。這種方式降低了和其他第三方資源框架的耦合性,獨立性非常強。但是也要記住,Spark主要是計算框架,而不是資源排程框架,所以本身提供的資源排程並不是它的強項,所以還是和其他專業的資源排程框架整合會更靠譜一些。所以接下來需要學習在強大的Yarn環境下Spark是如何工作的(其實是因為在國內工作中,Yarn使用的非常多)。
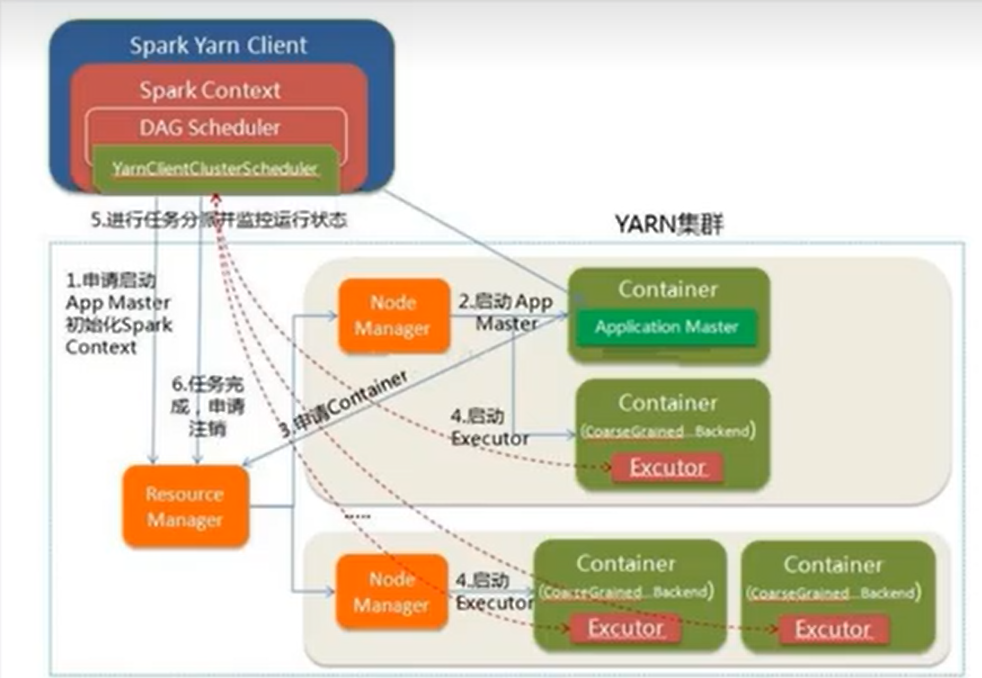
Yarn Client模式
# 重新拷貝一個目錄
cp -r spark-3.3.0-bin-hadoop3 spark-yarn
# 修改hadoop組態檔/home/commons/hadoop/etc/hadoop/yarn-site.xml,
<!--是否啟動一個執行緒檢查每個任務正使用的實體記憶體量,如果任務超出分配值,則直接將其殺掉,預設是true -->
<property>
<name>yarn.nodemanager.pmem-check-enabled</name>
<value>false</value>
</property>
<!--是否啟動一個執行緒檢查每個任務正使用的虛擬記憶體量,如果任務超出分配值,則直接將其殺掉,預設是true -->
<property>
<name>yarn.nodemanager.vmem-check-enabled</name>
<value>false</value>
</property>
# yarn-site.xml並分發到其他兩臺機器
scp /home/commons/hadoop/etc/hadoop/yarn-site.xml hadoop2:/home/commons/hadoop/etc/hadoop/
scp /home/commons/hadoop/etc/hadoop/yarn-site.xml hadoop3:/home/commons/hadoop/etc/hadoop/
# 重啟Hadoop
cd /home/commons/hadoop/sbin
./stop-all.sh
./start-all.sh
# 修改conf目錄三個組態檔,跟前面的類似稍微修改
mv workers.template workers
# 修改workers內容為
vi workers
hadoop1
hadoop2
hadoop3
# 準備spark-env.sh組態檔
mv spark-env.sh.template spark-env.sh
# 增加下面設定
vi spark-env.sh
export JAVA_HOME=/home/commons/jdk8
HADOOP_CONF_DIR=/home/commons/hadoop/etc/hadoop
YARN_CONF_DIR=/home/commons/hadoop/etc/hadoop
export SPARK_HISTORY_OPTS="
-Dspark.history.ui.port=18080
-Dspark.history.fs.logDirectory=hdfs://myns:8020/sparkhis
-Dspark.history.retainedApplications=30"
# 修改spark-defaults.conf.template檔名為spark-defaults.conf
mv spark-defaults.conf.template spark-defaults.conf
# 修改spark-default.conf檔案,設定紀錄檔儲存路徑
spark.eventLog.enabled true
spark.eventLog.dir hdfs://myns:8020/sparkhis
spark.yarn.historyServer.address=hadoop1:18080
spark.history.ui.port=18080
# 啟動歷史服務
sbin/start-history-server.sh
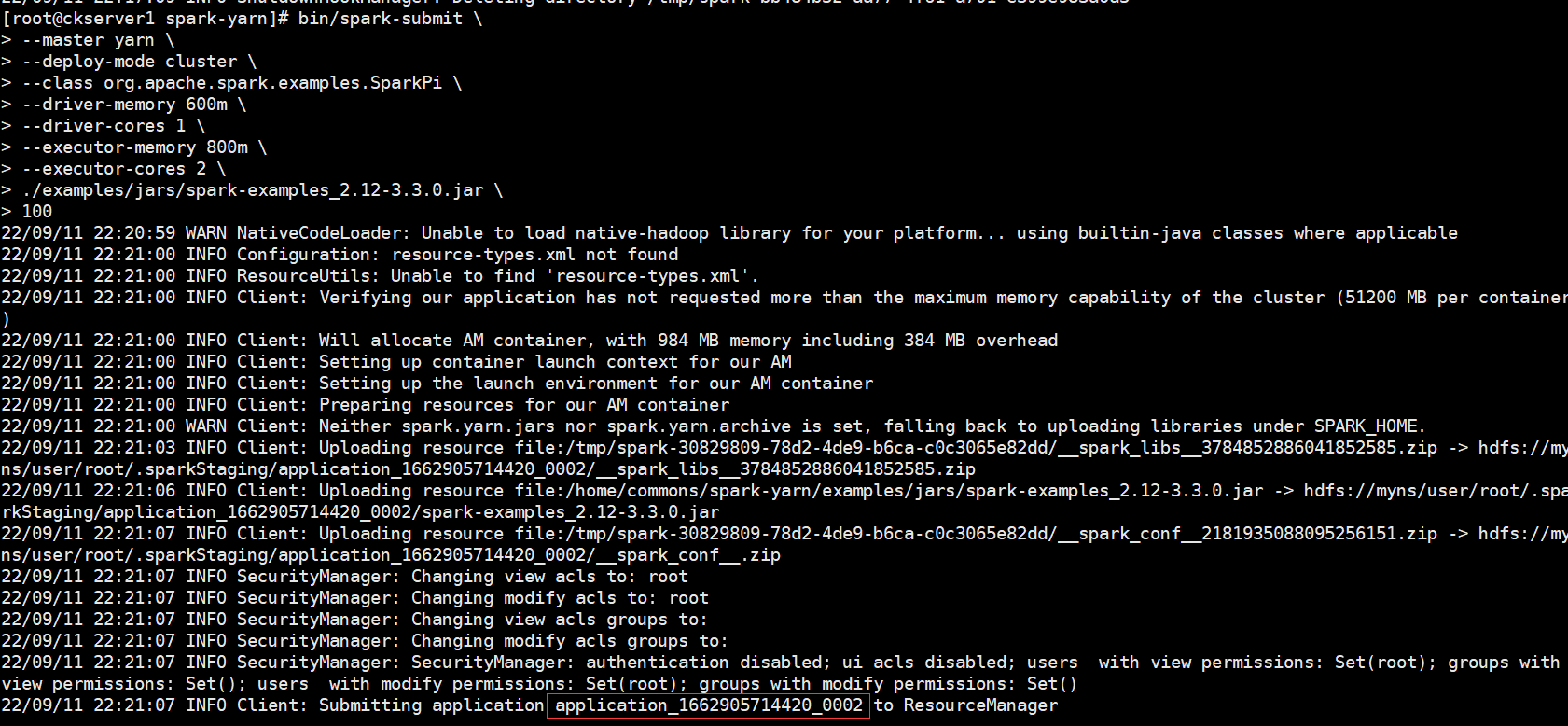
提交yarn client任務
bin/spark-submit \
--master yarn \
--deploy-mode client \
--class org.apache.spark.examples.SparkPi \
--driver-memory 600m \
--driver-cores 1 \
--executor-memory 800m \
--executor-cores 2 \
./examples/jars/spark-examples_2.12-3.3.0.jar \
100
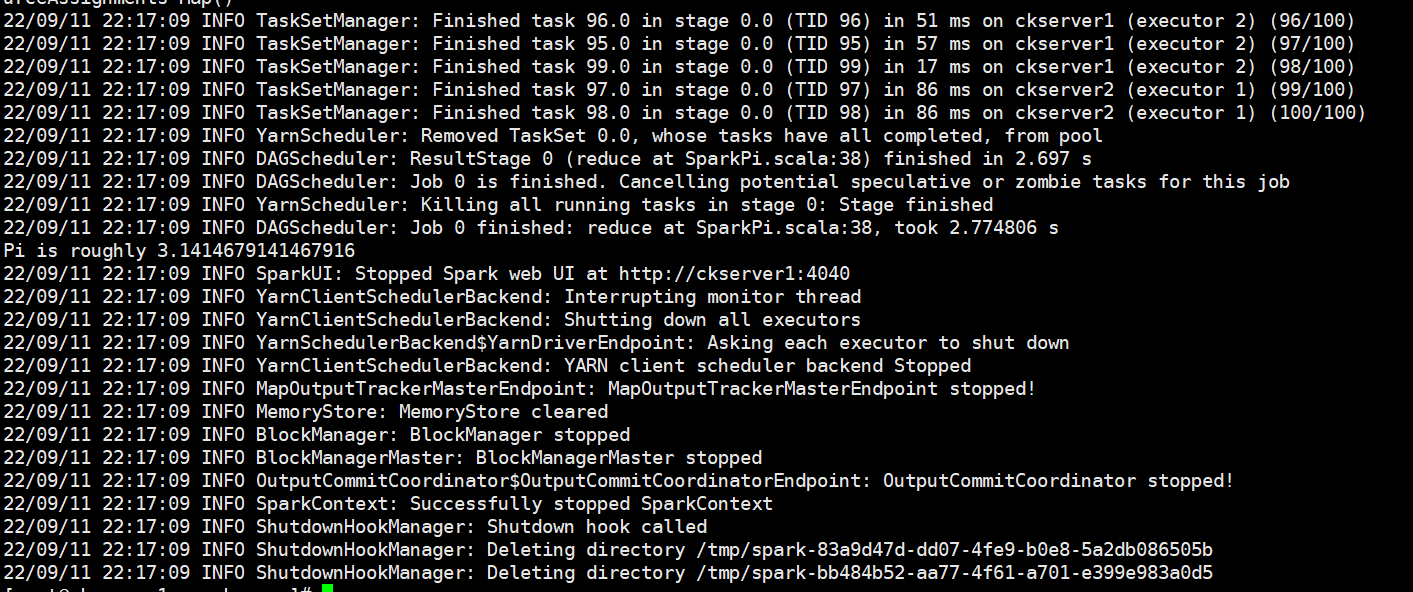
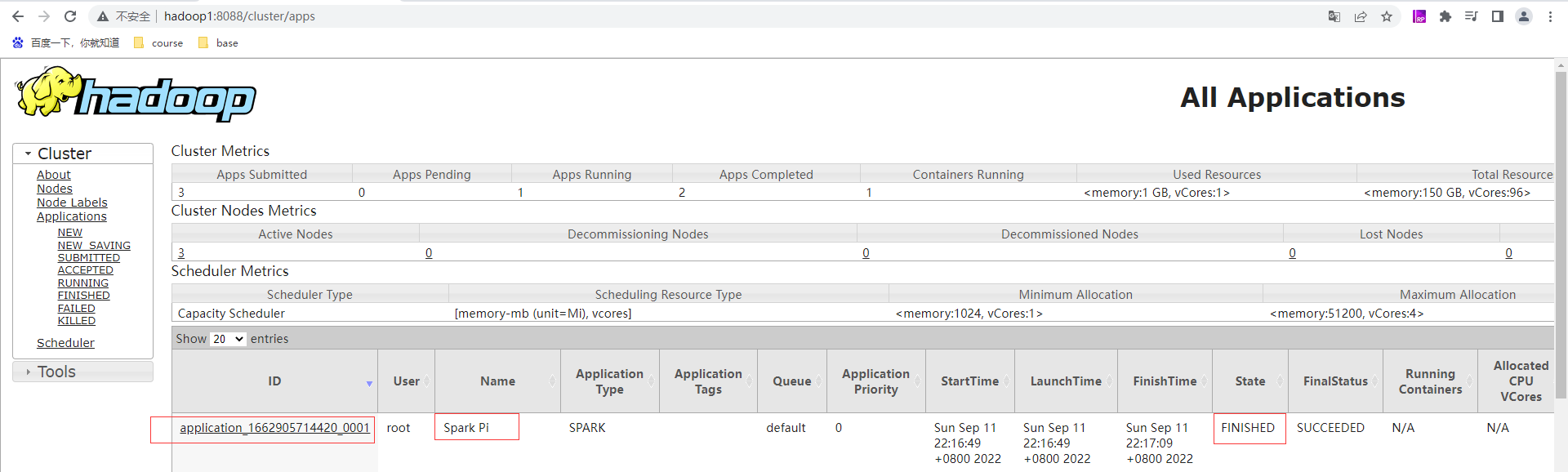
檢視yarn的頁面:http://hadoop1:8088/cluster 有剛才提交的應用application_1662905714420_0001為狀態成功且已完成
Yarn Cluster模式
bin/spark-submit \
--master yarn \
--deploy-mode cluster \
--class org.apache.spark.examples.SparkPi \
--driver-memory 600m \
--driver-cores 1 \
--executor-memory 800m \
--executor-cores 2 \
./examples/jars/spark-examples_2.12-3.3.0.jar \
100
檢視yarn的頁面:http://hadoop1:8088/cluster 有剛才提交的應用application_1662905714420_0002為狀態成功且已完成
Spark-Shell
在Spark Shell中,已經在名為sc的變數中為您建立了一個特殊的SparkContext,如果您自己建立SparkContext會不生效。您可以使用--master引數設定SparkContext連線到哪個主節點,並且可以通過--jars引數來設定新增到CLASSPATH的JAR包,多個JAR包時使用逗號(,)分隔。更多引數資訊,您可以通過命令./bin/spark-shell --help獲取。
- local模式
bin/spark-shell
# 啟動成功後,可以輸入網址進行Web UI監控頁面存取
# http://虛擬機器器地址:4040
# 在解壓縮資料夾下的data目錄中,新增word.txt檔案。在命令列工具中執行如下程式碼指令(和IDEA中程式碼簡化版一致)
sc.textFile("data/word.txt").flatMap(_.split(" ")).map((_,1)).reduceByKey(_+_).collect
# 退出本地模式,儘量用命令退出
:quit
- Standalone模式
bin/spark-shell \
--master spark://hadoop1:7077
- Yarn Client模式,由於shell屬於互動式方式,因此只有Yarn Client模式,沒有Yarn Cluster模式
bin/spark-shell \
--master yarn
**本人部落格網站 **IT小神 www.itxiaoshen.com