Linux零拷貝原理
Linux零拷貝原理
前言
磁碟可以說是計算機系統最慢的硬體之一,讀寫速度相差記憶體 10 倍以上,所以針對優化磁碟的技術非常的多,比如零拷貝、直接 I/O、非同步 I/O 等等,這些優化的目的就是為了提高系統的吞吐量。
DMA技術
在沒有DMA技術之前,IO過程是這樣的:
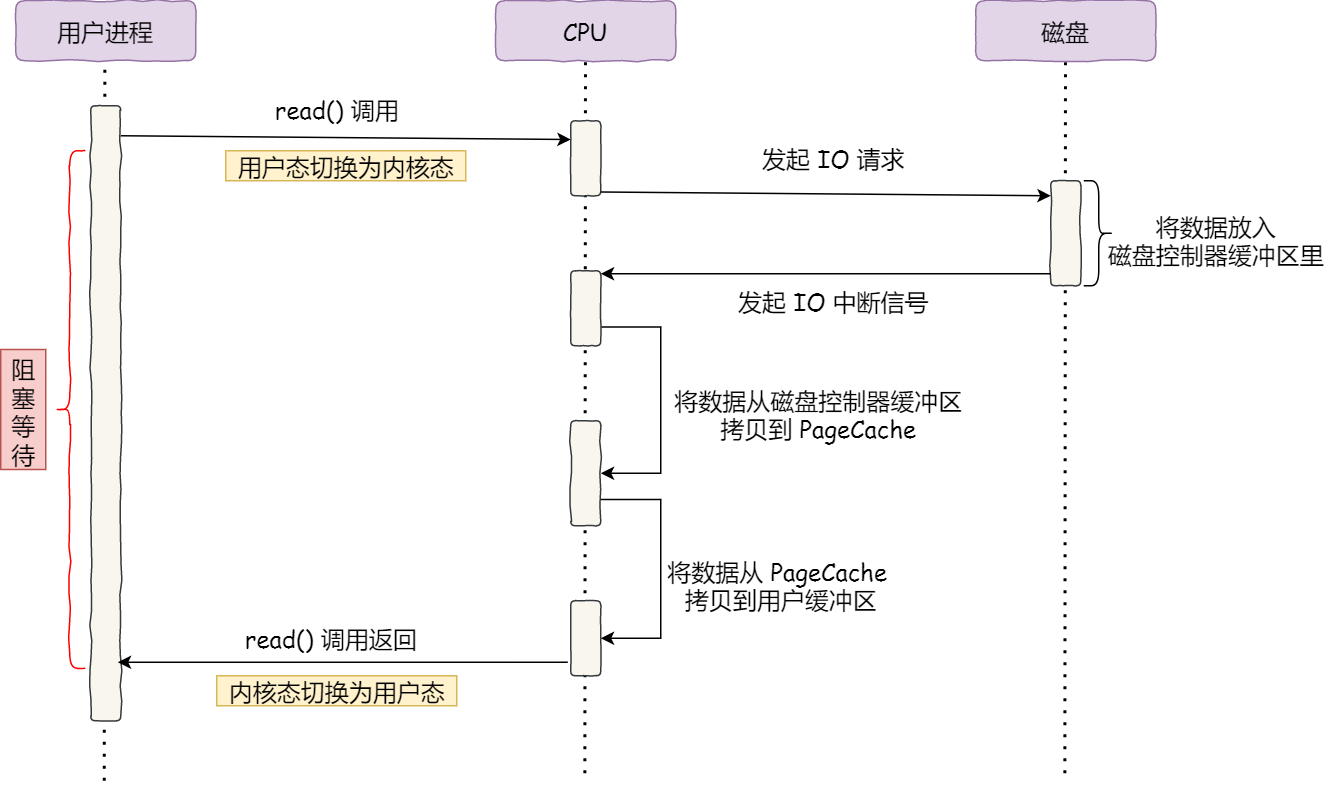
整個過程發生2次上下文切換和2次DMA拷貝,CPU只是在核心緩衝區和socket緩衝區之間建立管道。
kafka就使用了零拷貝技術,這也是 Kafka 在處理海量資料為什麼這麼快的原因之一。
kafka檔案傳輸的程式碼最終呼叫的是JAVA NIO庫裡的transferTo方法,如果 Linux 系統支援 sendfile() 系統呼叫,那麼 transferTo() 實際上最後就會使用到 sendfile() 系統呼叫函數。
nginx預設也是開啟零拷貝技術。
PageCache(核心緩衝區)作用
PageCache就是上面所說的核心緩衝區,它實際上是磁碟快取記憶體。
零拷貝技術是基於 PageCache 的,PageCache 會快取最近存取的資料,提升了存取快取資料的效能,同時,為了解決機械硬碟定址慢的問題,它還協助 I/O 排程演演算法實現了 IO 合併與預讀,這也是順序讀比隨機讀效能好的原因。這些優勢,進一步提升了零拷貝的效能。
用PageCache 來快取最近被存取的資料,讀磁碟資料的時候,優先在 PageCache 找,如果資料存在則可以直接返回;如果沒有,則從磁碟中讀取,然後快取 PageCache 中。
還有一點,讀取磁碟資料的時候,需要找到資料所在的位置,但是對於機械磁碟來說,就是通過磁頭旋轉到資料所在的磁區,再開始「順序」讀取資料,但是旋轉磁頭這個物理動作是非常耗時的,為了降低它的影響,PageCache 使用了「預讀功能」。
比如,假設 read 方法每次只會讀 32 KB 的位元組,雖然 read 剛開始只會讀 0 ~ 32 KB 的位元組,但核心會把其後面的 32~64 KB 也讀取到 PageCache,這樣後面讀取 32~64 KB 的成本就很低,如果在 32~64 KB 淘汰出 PageCache 前,程序讀取到它了,收益就非常大。
所以,PageCache 的優點主要是兩個:
- 快取最近被存取的資料;
- 預讀功能;
這兩個做法,將大大提高讀寫磁碟的效能。
但是,在傳輸大檔案(GB 級別的檔案)的時候,PageCache 會不起作用,那就白白浪費 DMA 多做的一次資料拷貝,造成效能的降低,即使使用了 PageCache 的零拷貝也會損失效能。
這是因為如果你有很多 GB 級別檔案需要傳輸,每當使用者存取這些大檔案的時候,核心就會把它們載入 PageCache 中,於是 PageCache 空間很快被這些大檔案佔滿。
另外,由於檔案太大,可能某些部分的檔案資料被再次存取的概率比較低,無法享受快取帶來的優勢。
所以,針對大檔案的傳輸,不應該使用 PageCache,也就是說不應該使用零拷貝技術,因為可能由於 PageCache 被大檔案佔據,而導致「熱點」小檔案無法利用到 PageCache,反而由於多做一次的資料拷貝損失效能。這樣在高並行的環境下,會帶來嚴重的效能問題。
大檔案傳輸實現方式
前面說到的所有方式都有一個特點:就是使用者程序需要阻塞等待,因此,這種操作被稱為同步阻塞IO。
對於阻塞的問題,可以用非同步 I/O 來解決。
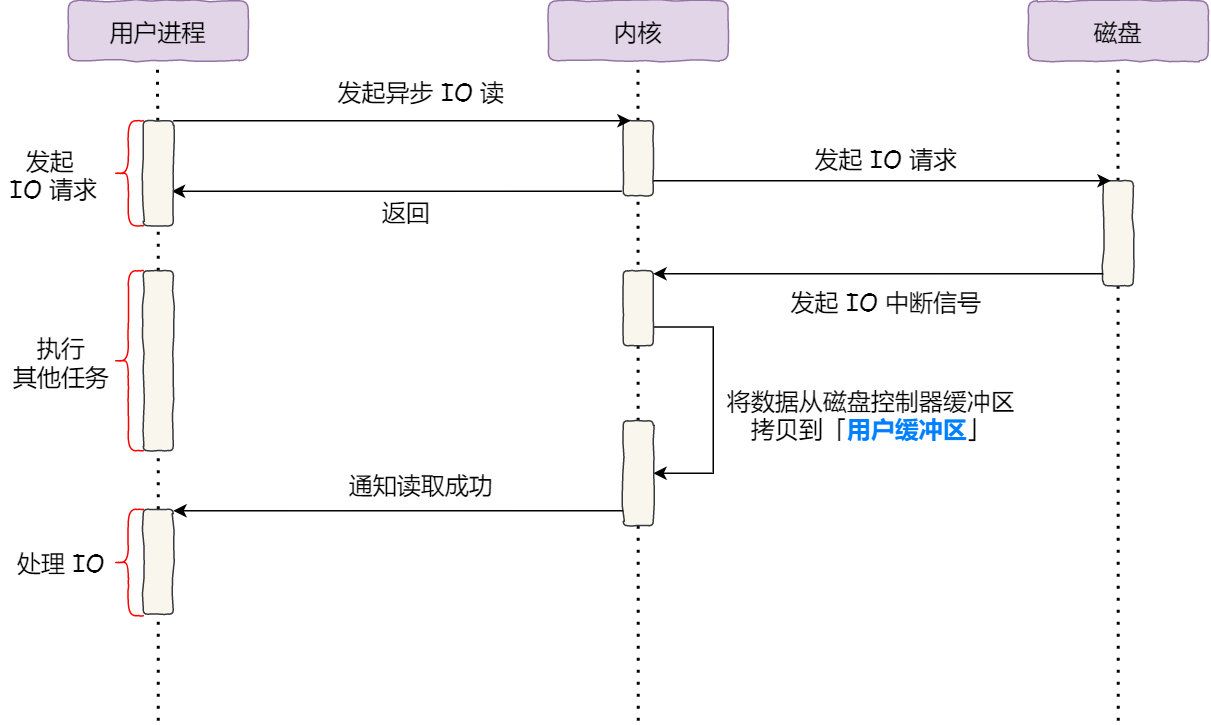
使用者程序向核心發起IO請求後直接返回,處理其他任務。
而核心將磁碟控制器緩衝區的資料直接拷貝到使用者緩衝區,然後通知使用者程序來讀。
非同步IO沒有涉及到PageCache,這種繞開PageCache的IO也叫直接IO,使用PageCache的IO叫做快取IO。
由於 CPU 和磁碟 I/O 之間的執行時間差距,會造成大量資源的浪費,因此直接IO一般都是和非同步IO結合才有意義。
前面也提到,大檔案的傳輸不應該使用 PageCache,因為可能由於 PageCache 被大檔案佔據,而導致「熱點」小檔案無法利用到 PageCache。
於是,在高並行的場景下,針對大檔案的傳輸的方式,應該使用「非同步 I/O + 直接 I/O」來替代零拷貝技術。
而傳輸小檔案時,使用零拷貝技術。
知識點回顧
虛擬記憶體
虛擬記憶體為每個程序提供了一個一致的、私有的地址空間,它讓每個程序產生了一種自己在獨享主記憶體的錯覺(每個程序擁有一片連續完整的記憶體空間)。
虛擬記憶體通常是被分隔成多個實體記憶體碎片,還有部分暫時儲存在外部磁碟記憶體上,在需要時進行資料交換,載入到實體記憶體中來。 每個程序所能使用的虛擬地址大小和 CPU 位數有關。在 32 位的系統上,虛擬地址空間大小是 2 ^ 32 = 4G。
虛擬記憶體的好處:
- 更大的地址空間,並且地址空間時連續的,使得程式編寫連結更簡單
- 地址隔離:程序之間不會影響
- 資料保護:每塊虛擬記憶體都有相應的讀寫屬性,保護程式程式碼不被修改,增加系統安全性
- 記憶體對映:不同的虛擬記憶體可以對映到同一塊實體記憶體上,可以實現程序之間相互共用資料
- 實體記憶體管理:應用程式申請和釋放的空間操作都是針對虛擬記憶體的,實際的實體記憶體管理是由作業系統完成,從而可以更好的利用記憶體,平衡程序間對記憶體的需求。
核心態和使用者態
作業系統的核心是核心,獨立於普通的應用程式,可以存取受保護的記憶體空間,也有存取底層硬體裝置的許可權。為了避免使用者程序直接操作核心,保證核心安全,作業系統將虛擬記憶體劃分為兩部分,一部分是核心空間(Kernel-space),一部分是使用者空間(User-space)。 核心程序和使用者程序所佔的虛擬記憶體比例是 1:3
在 Linux 系統中,核心模組執行在核心空間,對應的程序處於核心態;核心空間總是駐留在記憶體中,它是為作業系統的核心保留的。核心態可以執行任意命令,呼叫系統的一切資源。
而使用者程式執行在使用者空間,對應的程序處於使用者態。處於使用者態的程序不能存取核心空間中的資料,也不能直接呼叫核心函數的 ,因此要進行系統呼叫的時候,就要將程序切換到核心態才行。使用者態只能執行簡單的運算,不能直接呼叫系統資源。使用者態必須通過系統介面(System Call),才能向核心發出指令。
寫時複製
在某些情況下,核心緩衝區可能被多個程序所共用,如果某個程序想要這個共用區進行 write 操作,由於 write 不提供任何的鎖操作,那麼就會對共用區中的資料造成破壞,寫時複製的引入就是 Linux 用來保護資料的。
寫時複製指的是當多個程序共用同一塊資料時,如果其中一個程序需要對這份資料進行修改,那麼就需要將其拷貝到自己的程序地址空間中。這樣做並不影響其他程序對這塊資料的操作,每個程序要修改的時候才會進行拷貝,所以叫寫時拷貝。這種方法在某種程度上能夠降低系統開銷,如果某個程序永遠不會對所存取的資料進行更改,那麼也就永遠不需要拷貝。
BIO、NIO、AIO
這些是網路程式設計模型,由於socket也是一種特殊的檔案,從網路中收到資料和從磁碟讀取資料過程差不多,所以被稱為IO模型,一個IO請求就可以看成一個網路連線。
同步:同步是使用者執行緒需要等待核心IO操作完成,才能繼續執行;
非同步:非同步不需要等核心完成,核心完成後會通知使用者執行緒來讀取。
阻塞:阻塞時使用者執行緒需要等IO操作徹底完成後才能返回使用者空間。
非阻塞:非阻塞是IO操作被呼叫後立即返回使用者狀態值。
BIO(Blocking IO):同步阻塞模型,傳統的IO模型,每個IO操作對應一個Thread,上面我們舉的例子都是傳統IO。
NIO(NonBlocking IO):同步非阻塞模型,雖然可以立即返回使用者空間,但使用者執行緒需要輪詢來讀取資料。
AIO:非同步非阻塞模型。