索引優化
索引介紹
- 什麼是索引
索引是儲存引擎中的一種資料結構. 或者說是資料的一種組織方式. 又稱之為鍵key - 為什麼要用索引
為了優化查詢
ps: 建立完索引之後會降低增.刪.改的效率
好就好在讀寫比例是10: 1 - 如何正確看待索引:
開發人員最懂業務. 任何一個軟體都有吸引人的亮點. 亮點背後對應的就是熱資料. 這一點是開發人員最清楚的
開發人員最瞭解熱資料對飲的資料庫表欄位有哪些. 所以應該在開發軟體流程中就提前為軟體相應欄位加上索引.
而不是等到軟體上線後. 讓DBA發現慢查詢sql再做處理. 因為:- 一個軟體慢會影響使用者體驗. 但是慢的原因有很多. 你不能立即確定是sql的問題.
所以等定位到是sql的問題時. 可能已經被拖了很久. - 因為大多數DBA都是管理型DBA而不是開發型的. 所以即便是DBA從紀錄檔中看到慢查詢sql.
也會因為不懂業務而難分析出慢的原因. 最後這個鍋還是得扣在開發的腦袋上. 躲得了初一躲不了十五
- 一個軟體慢會影響使用者體驗. 但是慢的原因有很多. 你不能立即確定是sql的問題.
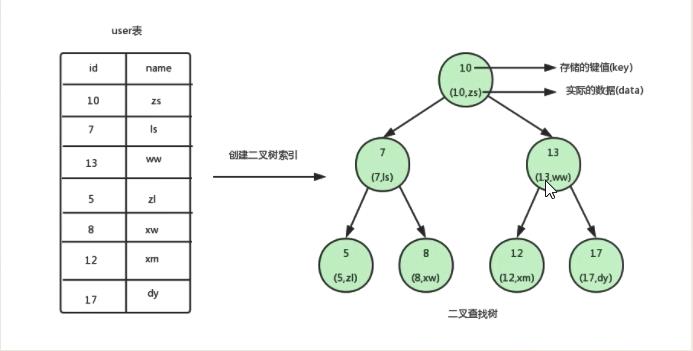
平衡二元樹
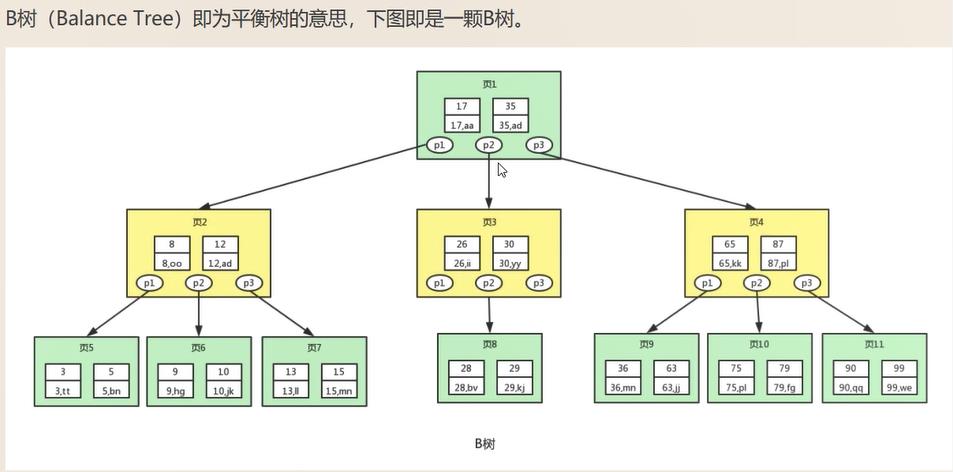
B樹
B+樹
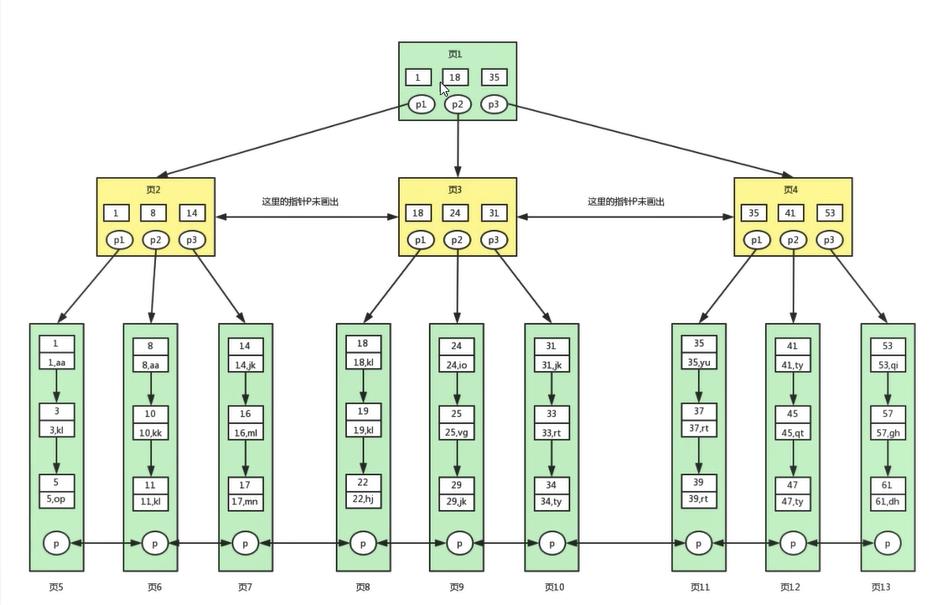
索引到底是個什麼樣子的結構: B+樹
二元樹. 平衡二元樹. B(balance)樹 -> B+數
表 -> 書
記錄 -> 一頁內容
索引 -> 書的目錄
select * from where id = 12; -- 命中索引
select * from where name = "xxx"; -- 無法命中索引
二元樹. 平衡二元樹 和 B數的區別:
二元樹: 每次io只能取一條記錄. 其排序規律是左邊排小. 右邊排大. 根節點常駐記憶體
B樹: 左右兩條資料. 進一步壓縮了高度. 且通過二分法分隔資料. 並且通過指標指向匹配頁的地址
B+樹做的優化
1. 並不是所有節點都放真正的資料. 只有葉子節點才放資料. B+數是高度是最低的
2. 天然排好了的順序. 右邊的值永遠比左邊的值要大. 且葉子節點之間都存在指向關係.
在範圍查詢中比B樹更高階(一旦找到按一個樹葉節點. 就不需要通過樹根再查起了)
innodb儲存引擎索引分類
1. hash索引: 更適合等值查詢. 不適合範圍查詢. 為什麼???最下面文章有解釋
2. B+數索引: 適合範圍查詢
聚集索引/聚簇索引 -> 以主鍵欄位為值作為key建立的索引(一張表中只有一個)
輔助索引 -> 針對非主鍵欄位建立的索引(一張表中可以有多個). 存索引欄位資料當key. values是主鍵欄位
innodb -> 索引組織表
select name, age, gender from user where id = 3; -- 聚集索引
select name, id from where name = "maxs_hu"; -- 覆蓋索引
select name, age, gender from user where name = "maxs_hu"; -- 需`要先查到id. 在聚集索引查詢. 屬於回表查詢
回表查詢: 通過輔助索引拿到主鍵值. 然後再回到聚集索引從根再查一下
覆蓋索引: 不需要回表就能拿到你要的全部資料
索引使用
250萬條記錄 -> ibd檔案為167M
索引的簡單使用
create table t1(
id int,
name varchar(16)
);
create index idx_id on t1(id); -- 新增索引
drop index idx_id on t1(id); -- 刪除索引
命中索引也未必能起到很好的提速效果
1. 對區分度高和且佔用空間小的欄位建立索引
2. 針對範圍查詢命中了索引. 如果範圍很大. 查詢速度依然很低. 如何提速:
-> 縮小範圍
-> 分段取值. 一段一段取值最後將值全部取完
-
索引下推技術(預設開啟)
-
不要把欄位放到函數中或者參與運算
select * from t1 where id * 12 = 24; -- 錯誤用法. 每個都要計算
select * from t1 where id = 24/12; -- 這樣預算可以提速
-
索引覆蓋: 輔助索引不包含所有的欄位. 其大小要遠遠小於聚集索引. 因此可以減少大量io操作
-
最左字首匹配原則
create index idx_id_name_gender on s1(id, name, gender);
當我們建立一個聯合索引的時候,如(id, name, gender),相當於建立了(id)、(id, name)和(id, name, gender)三個索引,這就是最左匹配原則。
- 限制索引的數目. 不要每列都建立索引
每列建立索引都需要佔用磁碟空間. 索引越多. 需要的磁碟空間越大.
修改表時. 對索引的重構和更新很麻煩. 越多的索引. 會使更新表變得很浪費時間
慢查詢優化的基本步驟
0.先執行看看是否真的很慢,注意設定SQL_NO_CACHE
1.where條件單表查,鎖定最小返回記錄表。這句話的意思是把查詢語句的where都應用到表中返回的記錄數最小的表開始查起,單表每個欄位分別查詢,看哪個欄位的區分度最高
2.explain檢視執行計劃,是否與1預期一致(從鎖定記錄較少的表開始查詢)
3.order by limit 形式的sql語句讓排序的表優先查
4.瞭解業務方使用場景
5.加索引時參照建索引的幾大原則
6.觀察結果,不符合預期繼續從0分析
推薦文章
https://www.cnblogs.com/linhaifeng/protected/articles/14425413.html
本文來自部落格園,作者:{Max},僅供學習和參考