Grafana Mimir:支援亂序的指標採集
Grafana Mimir:支援亂序的指標採集
譯自:New in Grafana Mimir: Introducing out-of-order sample ingestion
很早之前在使用thanos和多範例的Prometheus時經常會在thanos紀錄檔中看到時序資料亂序的問題。當時唯一的辦法就是從物件儲存中手動刪除這部分資料,非常不方便。Grafana Mimir中對亂序資料的支援是一個很大的改進。
傳統的Prometheus TSDB僅支援接收1小時內的有序取樣,然後丟棄其他樣本。這種方式可以讓Prometheus高效地儲存樣本。但在實際中,Prometheus的拉取模式(以一定節奏從被觀察的目標中提取資料)也給使用者的使用帶來了很多限制。
在一些使用場景下可能會存在亂序資料,如:
- 非同步啟動並寫入指標的IoT裝置
- 使用訊息匯流排(如使用隨機分片的Kafka)的複雜傳遞架構,可能存在擁塞延遲。
- 某些情況下受網路連線而孤立的Prometheus範例會嘗試推播老的樣本。
支援亂序的設計方案
我們和Dieter Plaetinck編寫了一個設計檔案來解決亂序問題。
資料的攝取
Prometheus TSDB有一個記憶體區域,稱為head block。我們通過共用該head block來避免產生重複的記憶體索引,同時可以減低記憶體消耗。對於head block中的每個時序,我們在記憶體中儲存了過去30個未壓縮的亂序樣本,並將其與有序樣本完全隔離開來。當記憶體chunk中的亂序樣本達到30個之後,它將會被壓縮並重新整理到磁碟,並從head block開始記憶體對映。
這一點類似head block處理有序樣本的方式:記憶體中的有序樣本會儲存在一個壓縮的chunk中,最大可以儲存120個樣本。由於需要儲存到記憶體中,且亂序的chunk是未壓縮的,因此我們將樣本數限制為30,防止消耗過多的記憶體。
我們還引入了一個新的方式,稱為Write-Behind-Log (WBL)。WBL類似Prometheus TSDB中的Write-Ahead-Log (WAL)。在WBL中,當在TSDB中新增樣本之後才會寫資料,而WAL是在TSDB資料變更前寫資料。我們使用WBL來記錄攝取的亂序樣本,因為在攝取樣本前,我們並不知道樣本是有序的還是亂序的。
下圖展示了該過程。注意亂序chunk之前可能會重疊(下圖中:OOO = Out of Order)。
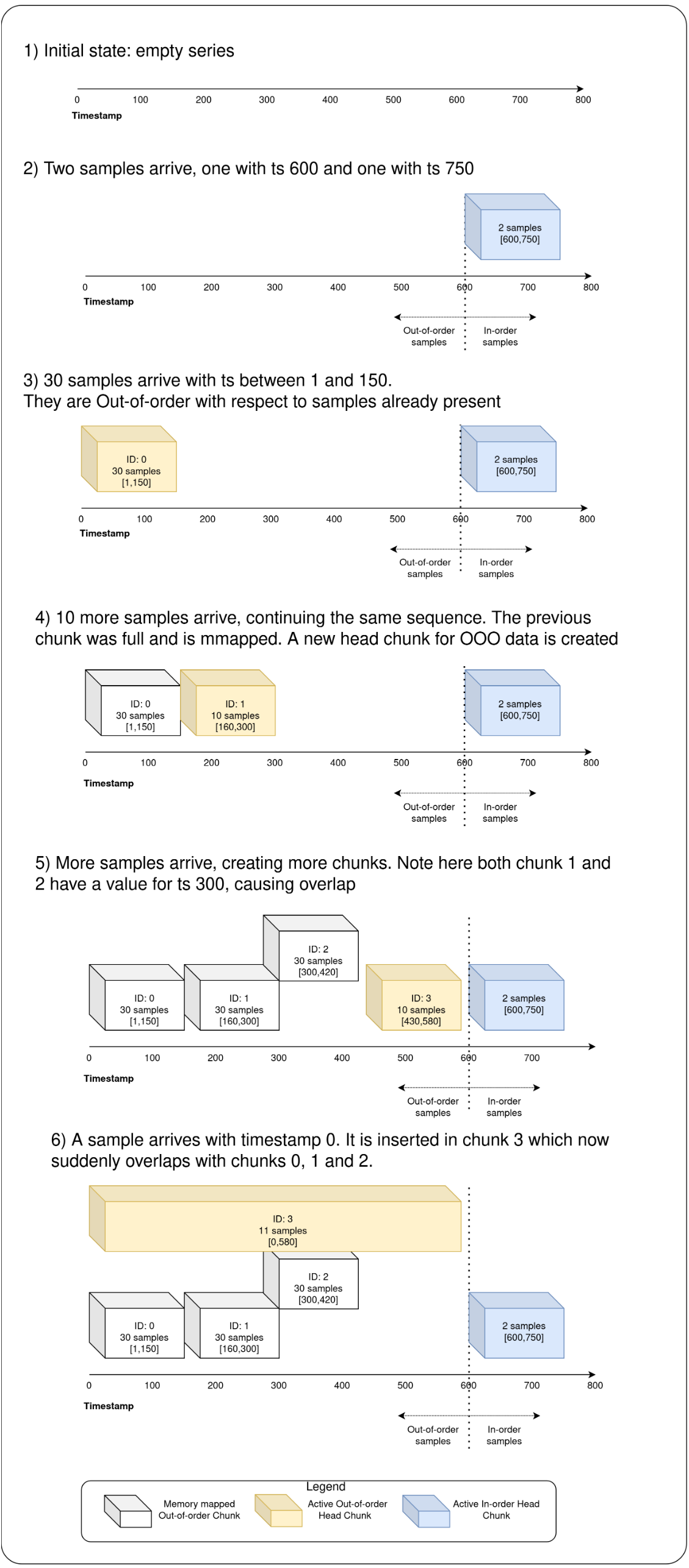
白色表示記憶體對映的亂序chunk,黃色表示活動狀態(表示新來的樣本,活動狀態的樣本可能會被合併)的亂序Head Chunk,而藍色表示有序的Head Chunk,可以看到上述過程如下:
- 一開始記憶體中沒有任何時序資料
- 此時來了兩個樣本,一個是時序為600的樣本,另一個是時序為750的樣本,它們作為一個有序的chunk
- 來了30個時序為1到150之間的亂序樣本
- 來了10個樣本,由於前面的chunk已經滿了,因此需要為亂序資料建立一個新的chunk
- 隨著樣本的增加,需要建立更多的chunks。注意chunk1和chunk2有一個重疊的值,300
- 來了一個新的以時序0開始的樣本,它被插入了chunk3,此時chunk3與chunk0、1、2重疊
查詢
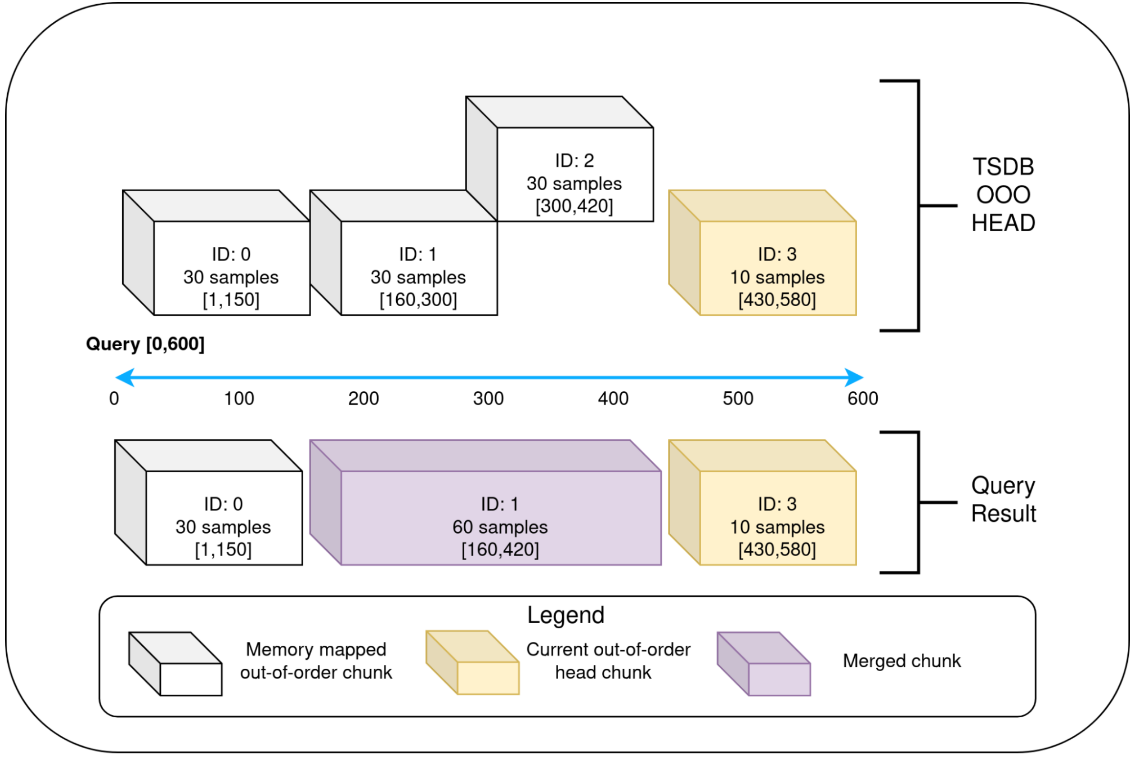
Prometheus TSDB有一個有用的抽象-查詢器,它將head block和磁碟的持久塊上的所有內容視為「塊讀取器」。TSDB使用一個head block包裝器來讀取固定時間範圍內的有序資料。類似地,我們實現了另一個圍繞head block且僅讀取亂序chunk的包裝器。這樣,head block可以體現為兩種塊讀取器:僅讀取有序資料的,和僅讀取亂序資料的。
現有的查詢邏輯可以無縫地處理塊讀取器和其他持久塊資料的合併結果。但查詢器要求塊讀取器按排序提供非重疊的塊。這樣,head block的亂序塊讀取器需要在查詢時合併重疊的chunks(如下圖)。當存取樣本時,會發生合併,但不會重新建立塊。
壓縮
TSDB中的持久塊會與2小時Unix時間戳對齊。對於有序資料,每過2小時,我們會獲取head block中的2小時內的老資料,並將其轉變為持久塊,這個稱為head block的壓縮過程。在壓縮完有序資料後,也會對亂序資料進行壓縮。
由於亂序資料的特點,其可能包含跨2個小時塊的樣本。因此,根據需要,我們在單次亂序資料的壓縮過程中會生成多個持久塊,如下所示。該持久塊與其他持久塊類似。在壓縮之後,會根據需要清理WBL和其他內容。這些塊可能會與磁碟中已有的塊或head block中的有序資料重疊。
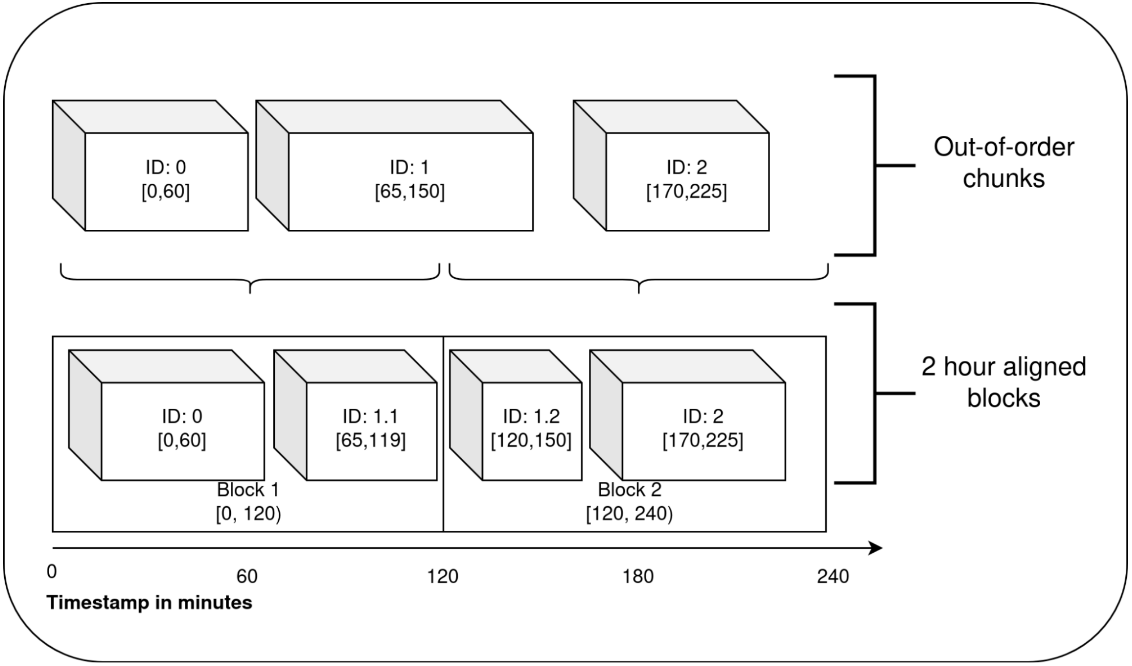
一旦產生了這些塊,就完成了亂序程式碼的處理。TSDB能夠從重疊的塊中請求資料,並在需要時合併重疊的塊。
Grafana Mimir 和 Grafana Cloud中的亂序樣本攝取
我們引入了一個名為out_of_order_time_window的設定引數來指定可以支援多老的亂序樣本。預設為0,即不支援亂序樣本。如果設定為1小時,則Grafana Mimir 會攝取過去1小時內的所有亂序樣本。
效能特徵
效能取決於:
- 攝取亂序樣本的模式
- 亂序樣本的數目
- 攝取的亂序樣本率
在很多情況下,所有上述條件都會導致攝取器的CPU使用率增加。在有限驗證的條件下,我們發現除處理亂序樣本的攝取器(攝取和查詢)上的CPU利用率為50%外,其他元件沒有看到CPU變動。
在我們的環境中,記憶體的增加並不明顯。但當時間序列的很大比率為亂序樣本時會導致記憶體變化,但總體增長應該仍然很小。
本文來自部落格園,作者:charlieroro,轉載請註明原文連結:https://www.cnblogs.com/charlieroro/p/16678430.html