Hive資料倉儲工具基本架構和入門部署詳解
@
概述
定義
Hive 官網 https://hive.apache.org/
Hive 官網Wiki檔案 https://cwiki.apache.org/confluence/display/Hive/
Hive GitHub原始碼地址 https://github.com/apache/hive
Apache Hive™資料倉儲軟體使用SQL對分散式儲存中的大型資料集進行讀寫和管理,結構可以對映到已儲存的資料上,也提供命令列工具和JDBC驅動連線使用者到Hive。目前最新版本為3.1.3
Hive由Facebook開源用於解決海量結構化紀錄檔的資料統計,基於Hadoop的一個資料倉儲工具,可以將結構化的資料檔案對映成一張表,並且提供類SQL的查詢功能,這套Hive SQL簡稱HQL。Hive僅僅是一個工具,本身不儲存資料只提供一種管理方式,同時也不涉及分散式概念;Hive不是為線上事務處理(OLTP)工作負載而設計的,它最適合用於對資料倉儲進行統計分析。
本質
Hive本質就是MapReduce,將類SQL(HQL)轉換成MapReduce程式,減少編寫MapReduce的複雜度,MapReduce對使用者來說雖然靈活,但需要使用者自己實現功能介面,不像Spark高層級應用提供各種運算元操作。hive支援了三種底層計算引擎包括mr、tez、spark,預設計算引擎mr,使用者可以指定具體使用哪個底層計算引擎(set hive.execution.engine=mr/tez/spark),當前前提得先完成Spark整合或安裝tez。
特點
- Hive提供了標準的SQL功能,通過SQL輕鬆存取資料的工具,從而支援資料倉儲任務,如提取/轉換/載入(ETL)、報告和資料分析。
- 一種將結構強加於各種資料格式的機制。
- 存取直接儲存在Apache HDFS™或其他資料儲存系統(如Apache HBase™)中的檔案。
- 通過Apache Tez™、Apache Spark™或MapReduce執行查詢。
- 使用HPL-SQL的過程語言。
- 通過Hive LLAP, Apache YARN和Apache Slider實現亞秒查詢檢索。
Hive與Hadoop關係
- Hive是基於Hadoop的。
- Hive本身其實沒有多少功能,hive就相當於在Hadoop上⾯加了⼀個外殼,就是對hadoop進⾏了⼀次封裝。
- Hive的儲存是基於HDFS的,hive的計算是基於MapReduce。
Hive與關係型資料庫區別
- Hive和關係型資料庫儲存檔案的系統不同, Hive使用的是HDFS(Hadoop的分散式檔案系統),關係型資料則是伺服器原生的檔案系統。
- Hive使用的計算模型是MapReduce,而關係型資料庫則是自己設計的計算模型。
- 關係型資料庫都是為實時查詢業務設計的,而Hive則是為海量資料做挖掘而設計的,實時性差;實時性的區別導致Hive的應用場景和關係型資料庫有很大區別。
- Hive很容易擴充套件自己的儲存能力和計算能力,這也是其寄託在Hadoop本身的優勢,而關係型資料庫在這方面要比Hive差很多。
優缺點
- 優點
- 學習成本低:提供了類SQL查詢語⾔HQL,使得熟悉SQL語⾔的開發⼈員⽆需關⼼細節,可以快速上⼿。
- 海量資料分析:底層是基於海量計算到MapReduce實現。
- 可延伸性:為超⼤資料集設計了計算/擴充套件能⼒(MR作為計算引擎,HDFS作為儲存系統),Hive可以⾃由的擴充套件叢集的規模,⼀般情況下不需要重啟服務。
- 延展性:Hive⽀持⽤戶⾃定義函數,⽤戶可以根據⾃⼰的需求來實現⾃⼰的函數。包括使用者定義函數(udf,一行輸入對應一行輸出,類似map)、使用者定義聚合(UDAFs,多行輸入對應一行輸出類似sum聚合函數)和使用者定義表函數(udtf,一行輸入對應多行輸出,類似explore)來擴充套件使用者程式碼。
- 良好的容錯性:某個資料節點出現問題HQL仍可完成執⾏。
- 統計管理:提供了統⼀的後設資料管理。
- 缺點
- Hive的HQL表達能⼒有限 。
- 迭代式演演算法⽆法表達。
- Hive的效率⽐較低。
- Hive⾃動⽣成的MapReduce作業,通常情況下不夠智慧化。
- Hive調優⽐較困難,粒度較粗。
其他說明
-
Hive資料儲存沒有單一的「Hive格式」。Hive內建了逗號和製表符分隔值(CSV/TSV)文字檔案、Apache Parquet™、Apache ORC™和其他格式的聯結器。使用者可以為Hive擴充套件其他格式的聯結器。
-
Hive支援檔案格式和壓縮:RCFile、Avro、ORC、Parquet、Compression、 LZO。
-
Hive的元件包括HCatalog和WebHCat
- HCatalog是Hadoop的一個表和儲存管理層,它允許使用者使用不同的資料處理工具(包括Pig和MapReduce)更容易地讀寫網格上的資料。
- WebHCat提供了一個服務,您可以使用它來執行Hadoop MapReduce(或YARN)、Pig、Hive任務。也可以通過HTTP (REST風格)介面對Hive後設資料進行操作。
架構
組成部分
下圖包含了Hive的主要元件及其與Hadoop的互動。Hive的主要元件有:
- UI(使用者介面):使用者向系統提交查詢和其他操作的使用者介面。包括Shell命令⾏ JDBC/ODBC:是指Hive的JAVA實現,與傳統資料庫JDBC類似。 WebUI:是指可通過瀏覽器存取Hive。
- DRIVER(驅動):接收查詢的元件,該元件實現了對談連線管理,並提供了以JDBC/ODBC介面為模型的執行和獲取api。
- Compiler(編譯器):解析查詢對不同的查詢塊和查詢表示式進行語意分析,並最終在metastore中查詢的表和分割區後設資料的幫助下生成執行計劃。
- Metastore(後設資料):儲存倉庫中各種表和分割區的所有結構資訊的元件,包括列和列型別資訊,讀寫資料所需的序列化器和反序列化器,以及儲存資料的對應HDFS檔案。Hive將後設資料儲存在資料庫中,如mysql、derby。Hive中的後設資料包括(表名、表所屬的資料庫名、表的擁有者、列/分割區欄位、表的型別(是否是外部表)、表的資料所在⽬錄等),如果規模大還可以儲存TiDB分散式關係型資料庫。

- Execution Engine(執行引擎):執行編譯器建立的執行計劃的元件。這個計劃是一個分階段的DAG。執行引擎管理計劃的這些不同階段之間的依賴關係,並在適當的系統元件上執行這些階段。例如將優化後的執⾏計劃提交給hadoop的yarn上執⾏提交job。
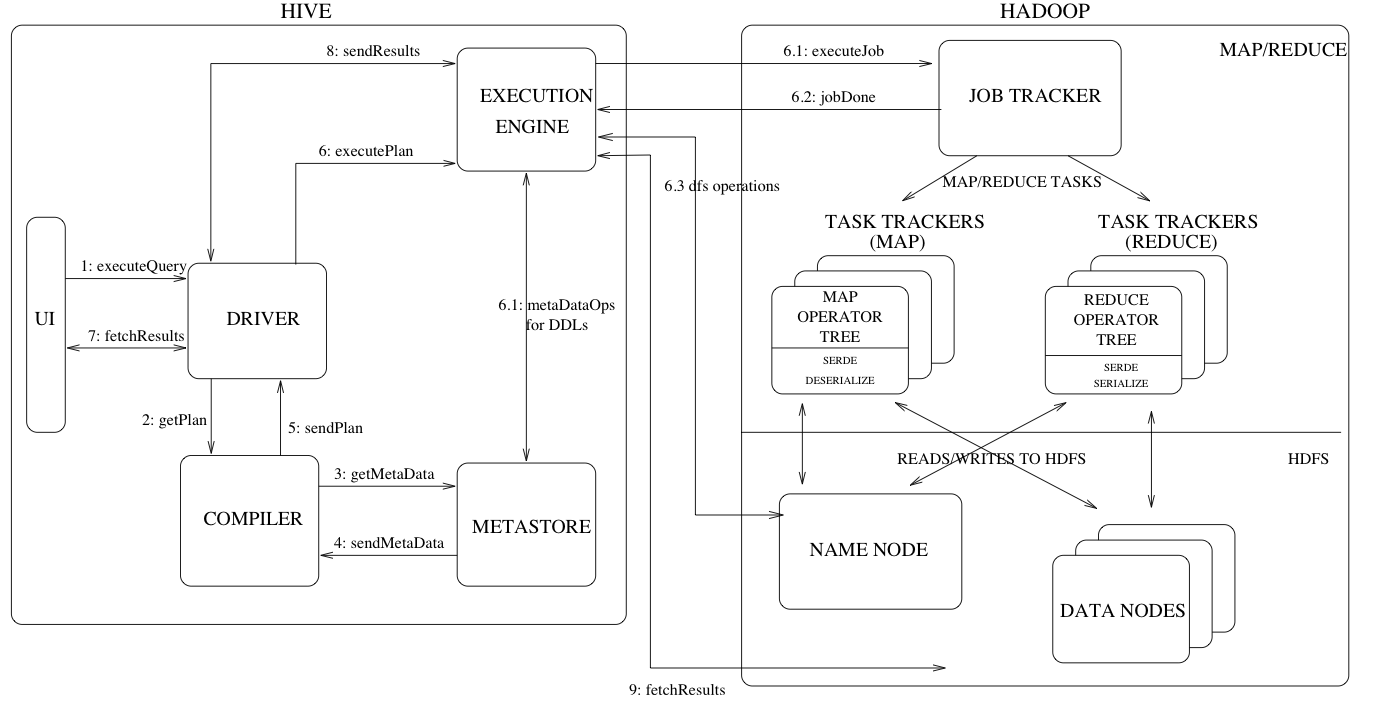
- UI呼叫驅動程式的執行介面(圖1中的步驟1)。
- 驅動程式為查詢建立對談控制程式碼,並將查詢傳送到編譯器以生成執行計劃(步驟2)。
- 編譯器從元儲存中獲取必要的後設資料(步驟3和4)。
- 該後設資料用於對查詢樹中的表示式進行型別檢查,並根據查詢謂詞修剪分割區。編譯器生成的計劃(步驟5)是階段的DAG,每個階段都是對映/還原作業、後設資料操作或HDFS操作。對於map/reduce階段,計劃包含map操作符樹(在對映器上執行的操作符樹)和reduce操作符樹(用於需要reducer的操作)。
- 執行引擎將這些階段提交給適當的元件(步驟6、6.1、6.2和6.3)。在每個任務(對映器/還原器)中,與表或中間輸出關聯的解串器用於從HDFS檔案中讀取行,這些行通過關聯的運運算元樹傳遞。生成輸出後,通過序列化程式將其寫入臨時HDFS檔案(如果操作不需要reduce,則會在對映器中發生)。臨時檔案用於向計劃的後續對映/還原階段提供資料。對於DML操作,最終的臨時檔案將移動到表的位置。該方案用於確保不讀取髒資料(檔案重新命名是HDFS中的原子操作)。
- 對於查詢,執行引擎直接從HDFS讀取臨時檔案的內容,作為來自驅動程式的提取呼叫的一部分(步驟7、8和9)。
資料模型(Hive資料組織形式)
- Table(表):這些類似於關聯式資料庫中的表。可以對錶進行篩選、投影、聯接和聯合。另外,一個表的所有資料都儲存在HDFS的一個目錄中。Hive還支援外部表的概念,通過為表建立DDL提供適當的位置,可以在HDFS中預先存在的檔案或目錄上建立表。表中的行被組織成類似於關係型資料庫的型別化列
- Partition(分割區):每個表可以有一個或多個分割區鍵來決定資料的儲存方式,例如一個帶有日期分割區列ds的表T有一些特定日期的檔案儲存在HDFS的< Table location>/ds=
目錄中。進一步加快資料檢索效率。 - Buckets(桶):每個分割區中的資料可以根據表中某個列的雜湊值依次劃分為Buckets。每個桶以檔案的形式儲存在分割區目錄中。bucket可以高效地評估依賴於資料樣本的查詢(如使用表上的sample子句查詢)。
Metastore(後設資料)
- Metastore是一個具有資料庫或檔案支援儲存的物件儲存,資料庫支援的儲存利用物件關係對映(ORM)實現,將其儲存在關聯式資料庫中的主要是用於後設資料的查詢。MetaSore 是 Hive 後設資料儲存的地方。Hive 資料庫、表、函數等的定義都儲存在 MetaStore 中。根據系統設定方式,統計資訊和授權記錄也可以儲存在這。Hive 或者其他執行引擎在執行時可以使用這些資料來確定如何解析,授權以及有效執行使用者的查詢。MetaStore 分為兩個部分:服務和後臺資料的儲存。
- Metastore提供了一個可選元件Thrift介面來操作和查詢設定單元后設資料,Thrift提供了許多流行語言套件括Java、C++、Ruby的繫結,可以通過程式設計的⽅式遠端存取Hive;第三方工具可以使用此介面將設定單元后設資料整合到其他業務後設資料儲存庫中。
Compiler(編譯器)
編譯器對hql語句進⾏詞法、語法、語意的編譯(需要跟後設資料關聯),編譯完成後會⽣成⼀個執⾏計劃。hive上就是編譯成mapreduce的job
- 解析器:將查詢字串轉換為解析樹表示。將HQL字串轉換成抽象語法樹AST,這⼀步⼀般都⽤第三⽅⼯具庫完成,⽐如 antlr;對AST進⾏語法 分析,⽐如表是否存在、欄位是否存在、SQL語意是否有誤。
- 語意分析器:將解析樹轉換為內部查詢表示,它仍然是基於塊的,而不是運運算元樹。作為該步驟的一部分,將驗證列名並執行類似*的擴充套件。在此階段還執行型別檢查和任何隱式型別轉換。例如分割區表則會收集該表的所有表示式,以便以後可以使用它們來修剪不需要的分割區。如果查詢指定了取樣,則也會收集該取樣以供後續使用。
- 邏輯計劃生成器:將內部查詢表示轉換為邏輯計劃,該計劃由運運算元樹組成。一些運運算元是關係代數運運算元,如「filter」、「join」等。但一些運運算元是特定於設定單元的,稍後將用於將此計劃轉換為一系列對映還原作業。一個這樣的運算元是發生在對映-還原邊界處的還原連結運算元。這一步還包括優化器轉換計劃以提高效能——其中一些轉換包括:將一系列連線轉換為單個多路連線,對分組依據執行對映端部分聚合,分兩個階段執行分組依據,以避免在分組金鑰存在傾斜資料時,單個縮減器可能成為瓶頸的情況。每個運運算元包括一個描述符,該描述符是可序列化物件。
- 查詢計劃生成器(物理計劃):將邏輯計劃轉換為一系列對映縮減任務。操作符樹被遞迴遍歷,被分解為一系列map-reduce可序列化任務,這些任務可以稍後提交給Hadoop分散式檔案系統的map-reduce框架。ReduceLink操作符是對映-還原邊界,其描述符包含還原鍵。ReduceLink描述符中的縮減鍵用作對映縮減邊界中的縮減金鑰。如果查詢指定,則計劃包含所需的樣本/分割區。計劃被序列化並寫入檔案。
Optimizer(優化器)
將執⾏計劃進⾏優化,減少不必要的列、使⽤分割區、使⽤索引等,優化job。
- 優化器將執行更多的計劃轉換。優化器是一個不斷髮展的元件。列修剪和謂詞下推、mapjoin。
- 優化器可以增強為基於CBO(Cost-based optimization in Hive)。輸出表的排序性質也可以保留,查詢可以在小樣本資料上執行以猜測資料分佈,可以用於生成更好的執行計劃。
安裝
Hive的安裝方式或者說是MetaStore安裝 分為三種部署模式:內嵌模式、本地模式以及遠端模式。Hive自動監測是否有Hadoop的環境變數。
# 下載hive最新版本3.1.3
wget --no-check-certificate https://dlcdn.apache.org/hive/hive-3.1.3/apache-hive-3.1.3-bin.tar.gz
# 解壓
tar -xvf apache-hive-3.1.3-bin.tar.gz
# 進入目錄
cd apache-hive-3.1.3-bin
內嵌模式
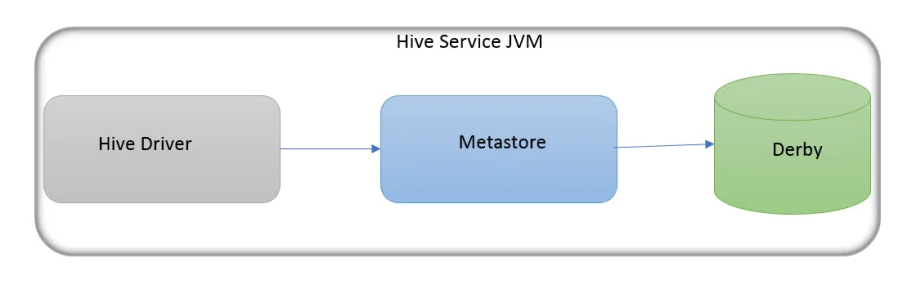
預設情況下,MetaStore 服務和 Hive 服務執行在同一個 JVM 中,包含一個內嵌的以本地磁碟作為儲存的 Derby 資料庫範例。使用內嵌的 MetaStore 是 Hive 入門最簡單的方法。但是每次只有一個內嵌的 Derby 資料庫可以存取某個磁碟上的資料庫檔案,這就意味著一次只能為每個 MetaStore 開啟一個 Hive 對談。如果試著啟動第二個對談,在它試圖連線 MetaStore 時,會得到錯誤資訊。因此它並不是一個實際的解決方案,並不適合在生產環境使用,常用於測試。
- 優點:使用簡單,不用進行設定。
- 缺點:只支援單Session。Session可以簡單的理解為同一路徑下不允許開兩個hive。
# 設定環境變數
vi /etc/profile
export HIVE_HOME=/home/commons/apache-hive-3.1.3-bin
export PATH=$HIVE_HOME/bin:$PATH
# 生效環境變數
source /etc/profile
# 設定hive-env環境變數
cp conf/hive-env.sh.template conf/hive-env.sh
vi conf/hive-env.sh
export HADOOP_HOME=/home/commons/hadoop
export HIVE_CONF_DIR=/home/commons/apache-hive-3.1.3-bin/conf
export HIVE_AUX_JARS_PATH=/home/commons/apache-hive-3.1.3-bin/lib
# 複製hive-default.xml
cp conf/hive-default.xml.template conf/hive-site.xml
# 替換{system:java.io.tmpdir}
vi conf/hive-site.xml
# 在vi裡替換,一共替換4處地方,4 substitutions on 4 lines
:%s#${system:java.io.tmpdir}#/home/commons/apache-hive-3.1.3-bin/iotmp#g
# 在vi裡替換,一共替換3處地方,3 substitutions on 3 lines
:%s#${system:user.name}#root#g
# 初始化derby後設資料
schematool -initSchema -dbType derby
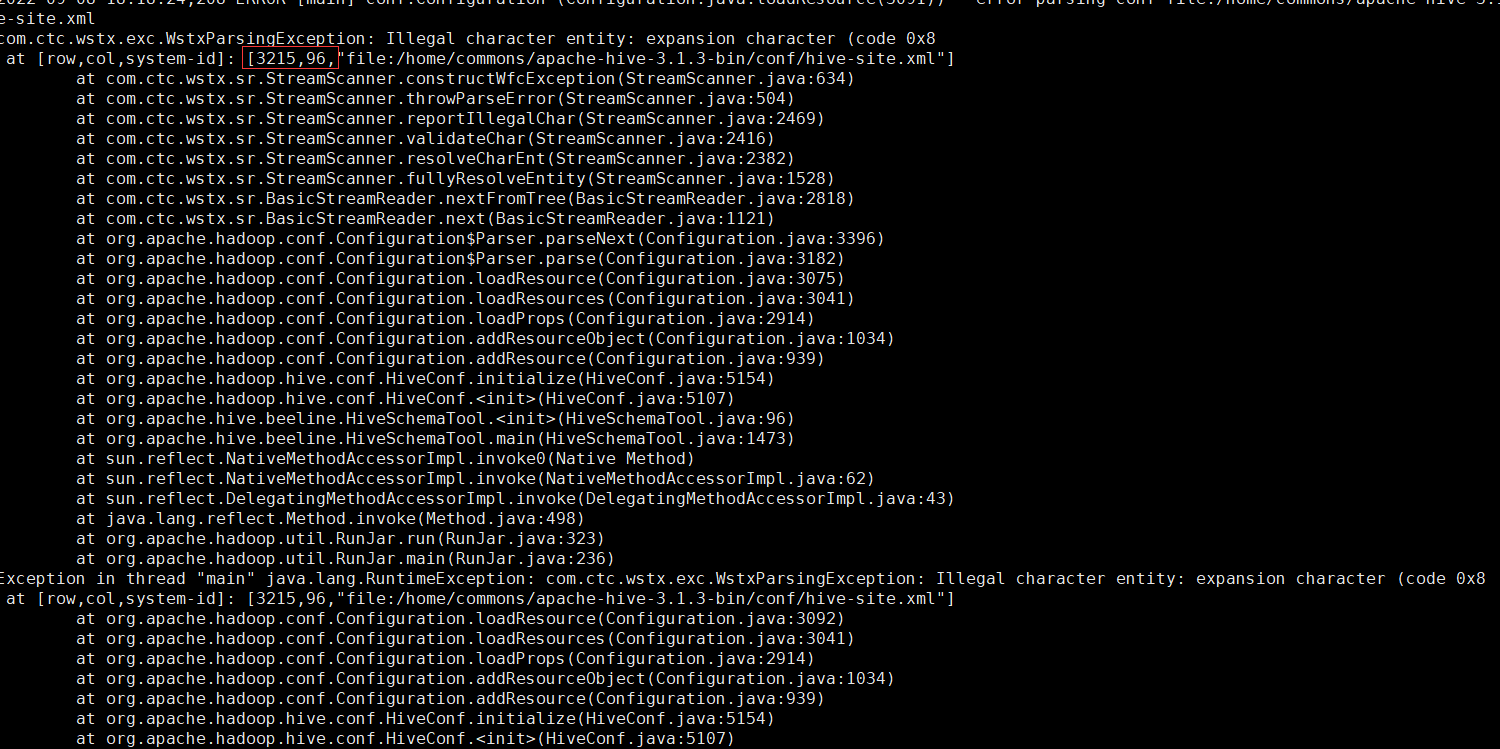
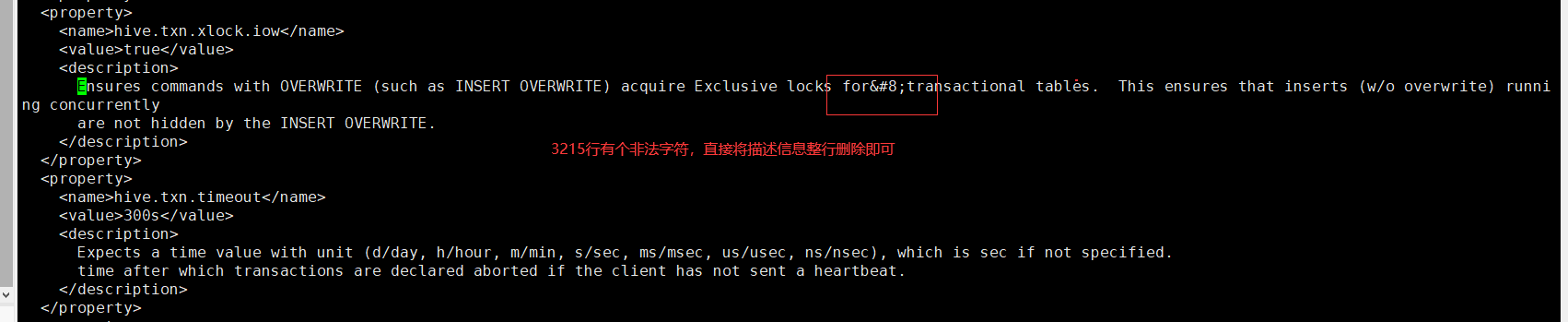
# 找到3215行的位置,將description整行內容刪除儲存
vi conf/hive-site.xml
重新執行初始化後顯示完成

初始化完後會在執行初始化指令碼當前路徑生成metastore_db的目錄,hive內嵌模式啟動就是讀當前路徑下這個目錄,這也意味著在其他目錄執行hive就沒法共用內嵌Derby後設資料資訊。
本地 MetaStore
如果要支援多對談(以及多租戶),需要使用一個獨立的資料庫。這種設定方式成為本地設定,因為 MetaStore 服務仍然和 Hive 服務執行在同一個程序中,但連線的卻是另一個程序中執行的資料庫,在同一臺機器上或者遠端機器上。對於本地模式來說使用者端和伺服器端在同一個節點上,啟動hive後自動啟動後設資料服務並連線。
- 優點:支援多Session。
- 缺點:需要設定,還需要關聯式資料庫如MySQL。
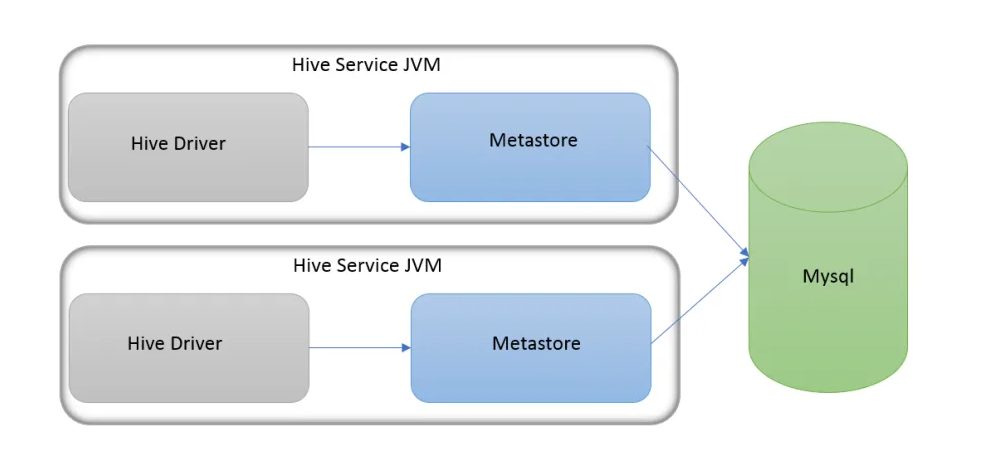
在本地模式下不需要設定 hive.metastore.uris,預設為空表示是本地模式。如果選擇 MySQL 作為 MetaStore 儲存資料庫,需要提前將 MySQL 的驅動包拷貝到 $HIVE_HOME/lib目錄下。JDBC 連線驅動類視情況決定選擇 com.mysql.cj.jdbc.Driver 還是 com.mysql.jdbc.Driver。
<property>
<name>javax.jdo.option.ConnectionURL</name>
<value>jdbc:mysql://192.168.50.95:3308/hive_meta?createDatabaseIfNotExist=true</value>
</property>
<property>
<name>javax.jdo.option.ConnectionDriverName</name>
<value>com.mysql.cj.jdbc.Driver</value>
</property>
<property>
<name>javax.jdo.option.ConnectionUserName</name>
<value>root</value>
</property>
<property>
<name>javax.jdo.option.ConnectionPassword</name>
<value>123456</value>
</property>
然後執行初始化操作,初始化成功後檢視hive_meta資料庫自動建立且有相關表
show databases;後顯示資料有default預設資料庫了

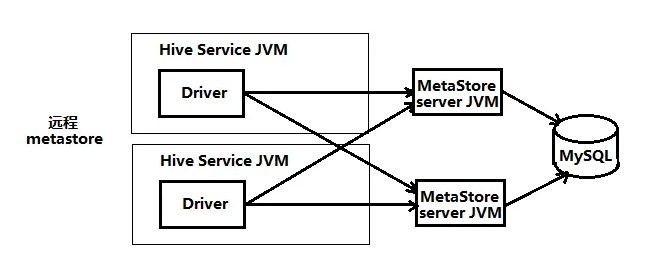
遠端 MetaStore
hiveserver2
將hive中的相關程序比如hiveserver2或者metastore這樣的程序單獨開啟,使用使用者端工具或者命令進行遠端連線這樣的服務。即遠端模式。使用者端可以在任何機器上,只要連線到這個server,就可以操作,使用者端可以不需要密碼。
修改hadoop的core-site.xml
<property>
<name>hadoop.proxyuser.root.hosts</name>
<value>*</value>
</property>
<property>
<name>hadoop.proxyuser.root.groups</name>
<value>*</value>
</property>
# 啟動hiveserver2
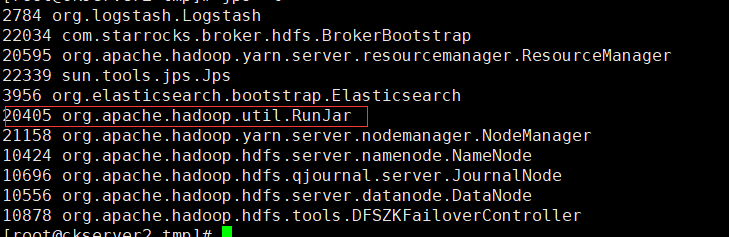
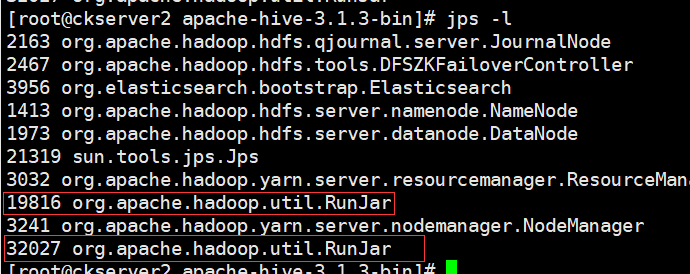
hive --service hiveserver2 &
檢視程序和上面執行hive可執行檔案的程序都是org.apache.hadoop.util.RunJar
# 將hive目錄傳送其他機器上
scp -r ../apache-hive-3.1.3-bin hadoop1:/home/commons
# 修改hive-site.xml內容
vi hive-site.xml
<property>
<name>hive.server2.thrift.bind.host</name>
<value>hadoop2</value>
<description>Bind host on which to run the HiveServer2 Thrift service.</description>
</property>
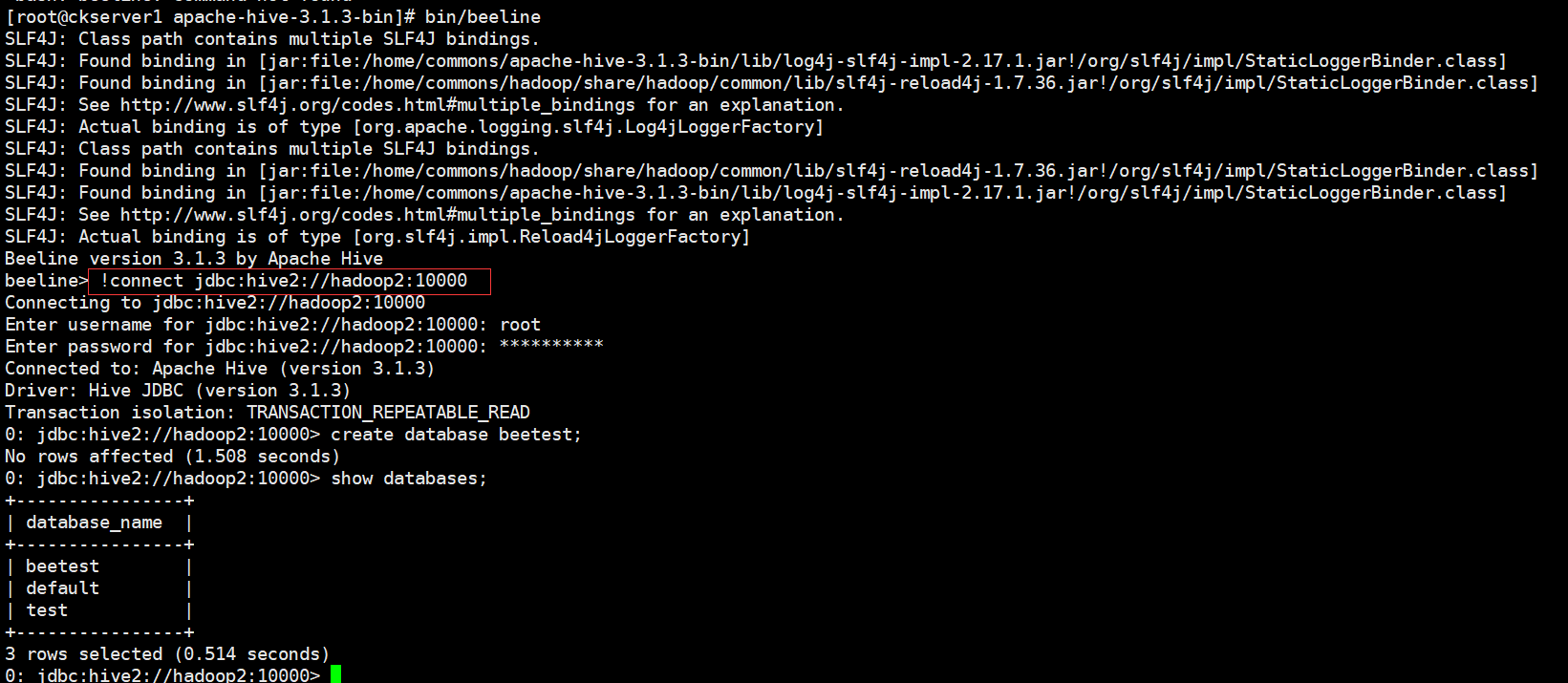
# 啟動beeline使用者端
bin/beeline
# 連線jdbc,使用者名稱和密碼就是你啟動hiveserver2機器使用者名稱密碼
!connect jdbc:hive2://hadoop2:10000
metastore
# 啟動metastore
hive --service metastore &
啟動後檢視程序可以看到比剛才增多一個RunJar程序
修改hive-site.xml內容
vi hive-site.xml <property> <name>hive.metastore.uris</name> <value>thrift://hadoop2:9083</value> <description>Thrift URI for the remote metastore. Used by metastore client to connect to remote metastore.</description> </property>
# 執行hive就可以連線到遠端9083的後設資料服務bin/hive
**本人部落格網站 **IT小神 www.itxiaoshen.com