目標檢測-SSD演演算法從零實現
2022-09-09 18:02:21
1. 幾個工具函數
def box_corner_to_center(boxes):
"""從(左上,右下)轉換到(中間,寬度,高度)"""
x1, y1, x2, y2 = boxes[:, 0], boxes[:, 1], boxes[:, 2], boxes[:, 3]
cx = (x1 + x2) / 2
cy = (y1 + y2) / 2
w = x2 - x1
h = y2 - y1
boxes = torch.stack((cx, cy, w, h), axis=-1)
return boxes
def box_center_to_corner(boxes):
"""從(中間,寬度,高度)轉換到(左上,右下)"""
cx, cy, w, h = boxes[:, 0], boxes[:, 1], boxes[:, 2], boxes[:, 3]
x1 = cx - 0.5 * w
y1 = cy - 0.5 * h
x2 = cx + 0.5 * w
y2 = cy + 0.5 * h
boxes = torch.stack((x1, y1, x2, y2), axis=-1)
return boxes
def bbox_to_rect(bbox, color):
# 將邊界框(左上x,左上y,右下x,右下y)格式轉換成matplotlib格式:
# ((左上x,左上y),寬,高)
return plt.Rectangle(
xy=(bbox[0], bbox[1]), width=bbox[2]-bbox[0], height=bbox[3]-bbox[1],
fill=False, edgecolor=color, linewidth=2)
# 顯示以影象中一個畫素為中心的所有錨框
def show_bboxes(axes, bboxes, labels=None, colors=None):
"""顯示所有邊界框"""
def _make_list(obj, default_values=None):
if obj is None:
obj = default_values
elif not isinstance(obj, (list, tuple)):
obj = [obj]
return obj
labels = _make_list(labels)
colors = _make_list(colors, ['b','g','r','m','c'])
for i, bbox in enumerate(bboxes):
color = colors[i % len(colors)]
rect = bbox_to_rect(bbox.detach().numpy(),color)
axes.add_patch(rect)
if labels and len(labels) > i:
text_color = 'k' if color == 'w' else 'w'
axes.text(rect.xy[0], rect.xy[1], labels[i], va='center',
ha='center', fontsize=9, color=text_color,
bbox=dict(facecolor=color, lw=0))
2. 生成錨框
def multibox_prior(img, sizes, ratios):
"""生成以每個畫素為中心具有不同形狀的錨框"""
in_height, in_width = img.shape[-2:]
device, num_sizes, num_ratios = img.device, len(sizes), len(ratios)
boxes_per_pixel = (num_sizes + num_ratios - 1)
size_tensor = torch.tensor(sizes, device=device)
ratio_tensor = torch.tensor(ratios, device=device)
# 生成錨框的所有中心點
# 這裡以0 1 2為例,中心點是0.5和1.5所以要加上0.5, /in_height是為了進行歸一化
center_h = (torch.arange(in_height, device=device) + 0.5) / in_height
center_w = (torch.arange(in_width, device=device) + 0.5) / in_width
shift_y, shift_x = torch.meshgrid(center_h, center_w, indexing='ij')
shift_y, shift_x = shift_y.reshape(-1), shift_x.reshape(-1)#此時shift_y和shift_x一對一地形成了所有中心點下標
# 生成「boxes_per_pixel」個高和寬,
# 之後用於建立錨框的四角座標(xmin,xmax,ymin,ymax)
# w為一行,其中每個元素為不同的錨框的寬度
w = torch.cat((sizes[0] * torch.sqrt(in_height * ratio_tensor[:] / in_width),
size_tensor[1:] * torch.sqrt(in_height * ratio_tensor[0] / in_width)))
# h為一行,其中每個元素為不同的錨框的高度
h = torch.cat((sizes[0] * torch.sqrt(in_width / ratio_tensor[:] / in_height),
size_tensor[1:] * torch.sqrt(in_width / ratio_tensor[0] / in_height)))
# 除以2來獲得半高和半寬
anchor_manipulations = torch.stack((-w, -h, w, h)).T.repeat(in_height * in_width, 1) / 2
# 每個中心點都將有「boxes_per_pixel」個錨框,
# 所以生成含所有錨框中心的網格,重複了「boxes_per_pixel」次
out_grid = torch.stack([shift_x, shift_y, shift_x, shift_y],
dim=1).repeat_interleave(boxes_per_pixel, dim=0)
output = out_grid + anchor_manipulations
# 只能返回一張圖片的所有錨框
return output.unsqueeze(0) # 1 * 錨框個數 * 4(左上和右下下標)
3. 給錨框打標籤
- 首先提供一個計算錨框之間的交併比的函數
# 交併比(IoU)
def box_iou(boxes1,boxes2):
# 左上右下形式座標
# boxes1:(boxes1的數量,4),
# boxes2:(boxes2的數量,4),
"""計算兩個錨框或邊界框列表中成對的交併比"""
box_area = lambda boxes: ((boxes[:,2] - boxes[:,0]) *
(boxes[:,3] - boxes[:,1]))
areas1 = box_area(boxes1) # 錨框1的面積
areas2 = box_area(boxes2) # 錨框2的面積
inter_upperlefts = torch.max(boxes1[:,None,:2],boxes2[:,:2])
inter_lowerrights = torch.min(boxes1[:,None,2:],boxes2[:,2:])
inters = (inter_lowerrights - inter_upperlefts).clamp(min=0)
# inter_areasand and union_areas的形狀:(boxes1的數量,boxes2的數量)
inter_areas = inters[:,:,0] * inters[:,:,1] # 交集的面積
union_areas = areas1[:,None] + areas2 - inter_areas # 並集的面積
return inter_areas / union_areas # num_box1 * num_box2
- 為錨框分配真實邊界框,這樣之後才能打標籤,偏移量和類別,這裡只會把所有滿足和真實邊界框的iou值大於一定範圍的錨框分配,未分配的值為-1
# 將真實邊界框分配給錨框
def assign_anchor_to_bbox(anchors,ground_truth,device,iou_threshold=0.5):
"""將最接近的真實邊界框分配給錨框"""
num_anchors, num_gt_boxes = anchors.shape[0], ground_truth.shape[0]
jaccard = box_iou(anchors,ground_truth) # 計算所有的錨框和真實邊緣框的IOU
anchors_bbox_map = torch.full((num_anchors,), -1, dtype=torch.long, device=device)
max_ious, indices = torch.max(jaccard, dim=1)#indices為每一個錨框對應的真實的邊界框的標號, max_ious為每一個錨框對應的真實邊界框的iou
anc_i = torch.nonzero(max_ious >= iou_threshold).reshape(-1) #找到所有iou值>0.5的錨框的下標
box_j = indices[max_ious >= iou_threshold]#找到所有iou值>0.5的錨框對應的真實邊界框
anchors_bbox_map[anc_i] = box_j
#到現在上面的每一個iou>=0.5的錨框都分配了一個真實的邊界框,但是此時並不一定每個真實邊界框都分配到了一個錨框,
#所以下面的程式碼要對每一個真實邊界框進行遍歷,並未其分配一個錨框
col_discard = torch.full((num_anchors,),-1)
row_discard = torch.full((num_gt_boxes,),-1)
for _ in range(num_gt_boxes):
max_idx = torch.argmax(jaccard, dim=None) # 找IOU最大的錨框,找的是全域性最大的錨框
box_idx = (max_idx % num_gt_boxes).long()
anc_idx = (max_idx / num_gt_boxes).long()
anchors_bbox_map[anc_idx] = box_idx
jaccard[:,box_idx] = col_discard # 把最大Iou對應的錨框在 錨框-類別 矩陣中的一列刪掉
jaccard[anc_idx,:] = row_discard # 把最大Iou對應的錨框在 錨框-類別 矩陣中的一行刪掉
return anchors_bbox_map#返回每一個分配了邊界框的錨框對應的真實邊界框的下標
- 接下來就可以給錨框打標籤了
def offset_boxes(anchors, assigned_bb, eps=1e-6):
"""對錨框偏移量的轉換"""
c_anc = box_corner_to_center(anchors)
c_assigned_bb = box_corner_to_center(assigned_bb)
offset_xy = 10 * (c_assigned_bb[:, :2] - c_anc[:, :2]) / c_anc[:, 2:]
offset_wh = 5 * torch.log(eps + c_assigned_bb[:, 2:] / c_anc[:, 2:])
offset = torch.cat([offset_xy, offset_wh], axis=1)
return offset # 儘量使得 offset 讓 machine learning 演演算法好預測
# 標記錨框的類和偏移量
def multibox_target(anchors, labels):
"""使用真實邊界框標記錨框"""
batch_size, anchors = labels.shape[0], anchors.squeeze(0)
batch_offset, batch_mask, batch_class_labels = [], [], []
device, num_anchors = anchors.device, anchors.shape[0]
for i in range(batch_size):
label = labels[i,:,:]
anchors_bbox_map = assign_anchor_to_bbox(anchors,label[:,1:],device)
class_labels = torch.zeros(num_anchors, dtype=torch.long,device=device)
assigned_bb = torch.zeros((num_anchors,4), dtype=torch.float32,device=device)
indices_true =torch.nonzero(anchors_bbox_map >= 0)# 分配了真實邊界框的錨框下標
bb_idx = anchors_bbox_map[indices_true] #分配了邊界框的錨框對應的真實邊界框的下標
class_labels[indices_true] = label[bb_idx,0].long() + 1 #所有錨框對應的類別,0表示背景,>0表示物體, (num_anchors,)
assigned_bb[indices_true] = label[bb_idx, 1:] #所有錨框對應的真實的邊界框的座標,num_anchors * 4
bbox_mask = ((anchors_bbox_map >= 0).float().unsqueeze(-1)).repeat(1,4) # num_anchors * 4,沒有分配真實邊界框的錨框對應4個0,分配的對應4個1
offset = offset_boxes(anchors, assigned_bb) * bbox_mask#乘上bbox_mask是因為有的錨框對應的真實邊界框座標全是0,為了把這部分去掉, num_anchors*4
batch_offset.append(offset.reshape(-1))
batch_mask.append(bbox_mask.reshape(-1))
batch_class_labels.append(class_labels)
bbox_offset = torch.stack(batch_offset) #batch_size * (num_anchors*4)
bbox_mask = torch.stack(batch_mask) #batch_size * (num_anchors*4)
class_labels = torch.stack(batch_class_labels) #batch_size * num_anchors
# bbox_offset返回每一個錨框到真實標註框的offset偏移
# bbox_mask為0表示背景錨框,就不用了,>0表示對應真實的物體
# class_labels為錨框對應類的編號
return (bbox_offset, bbox_mask, class_labels)
4. 接下來準備模型
- 首先提供用來預測錨框類別和偏移量的層
因為錨框個數太多,如果把每個錨框都拿出來做迴歸和分類會導致計算量太大,這裡採用的方式是利用通道數作為每一個畫素點生成的所有錨框的預測,錨框的標籤是利用上面的方式標記的,損失便是由這兩者產生的,根據損失的梯度下降,網路便可以學會通道便是錨框的預測結果。
def cls_predictor(num_input_channels, num_anchors, num_classes):
"""類別預測層
這裡折積核用的是高寬不變的,因為如果每一個畫素點都生成多個錨框,在進行分類會導致引數過大,
所以這裡省略了這個步驟,直接通過把每一個畫素點生成num_anchors*num_classes個通道,就代替了上面的步驟
Args:
num_input_channels (_type_):特徵圖的輸入通道
num_anchors (_type_):每一個畫素生成多少錨框,num_sizes+num_ratios-1
num_classes (_type_):類別數,要包含背景的
"""
return nn.Conv2d(num_input_channels, num_anchors*num_classes, kernel_size=3, padding=1)
def offset_predictor(num_input_channels, num_anchors):
"""邊界框預測層
這裡折積核用的是高寬不變的,因為如果每一個畫素點都生成多個錨框,在進行預測4個偏移量導致引數過大,
所以這裡省略了這個步驟,直接通過把每一個畫素點生成num_anchors*4個通道,就代替了上面的步驟
Args:
num_input_channels (_type_):特徵圖的輸入通道
num_anchors (_type_):每一個畫素生成多少錨框,num_sizes+num_ratios-1
"""
return nn.Conv2d(num_input_channels, num_anchors*4, kernel_size=3, padding=1)
- 接下來提供網路模型的結構,總共有5層
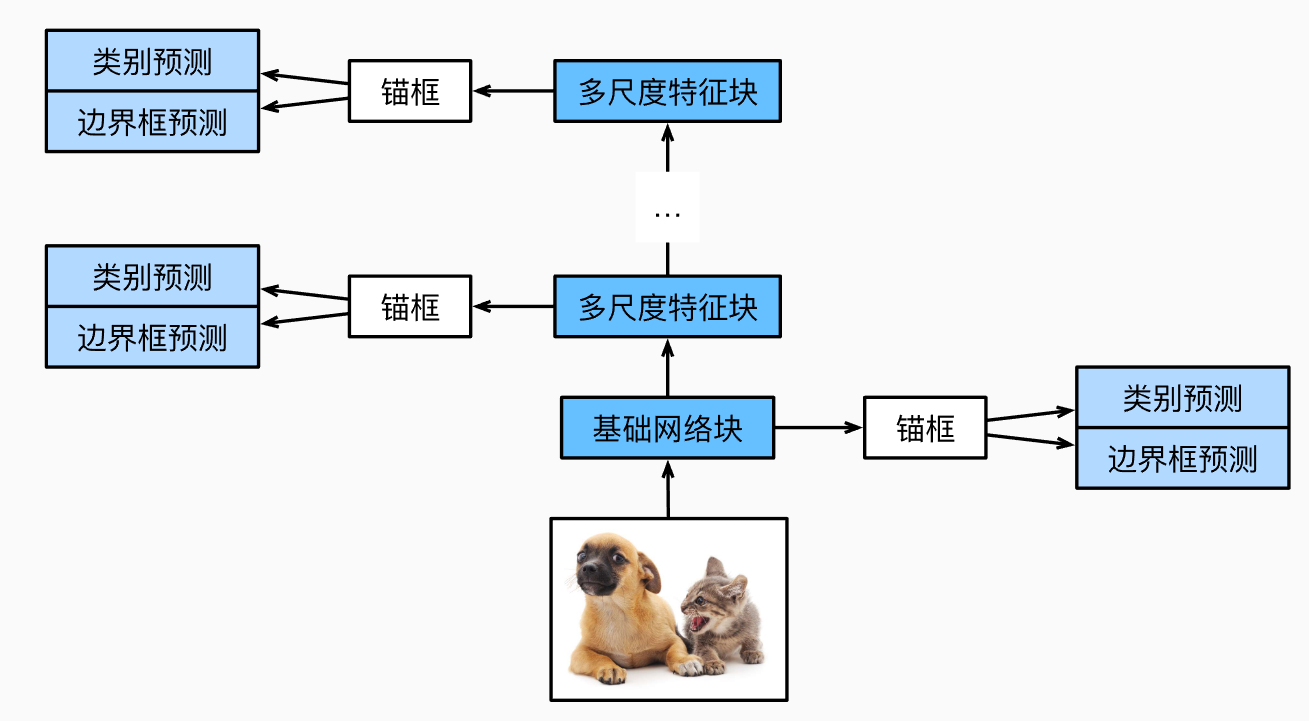
def down_sample_blk(in_channels, out_channels):
# 高寬減半
blk = []
for _ in range(2):
blk.append(nn.Conv2d(in_channels, out_channels, kernel_size=3, padding=1))
blk.append(nn.BatchNorm2d(out_channels))
blk.append(nn.ReLU())
in_channels = out_channels
blk.append(nn.MaxPool2d(kernel_size=2))
return nn.Sequential(*blk)
def base_net():
# 從輸入影象中抽取特徵的網路
# channels:3 -> 64
# 高寬減小了8倍
blk = []
num_filters = [3, 16, 32, 64]
for i in range(len(num_filters)-1):
blk.append(down_sample_blk(num_filters[i], num_filters[i+1]))
return nn.Sequential(*blk)
def get_blk(i):
if i == 0:
blk = base_net()
elif i == 1:
blk = down_sample_blk(64, 128)
elif i == 4:
blk = nn.AdaptiveMaxPool2d((1, 1))
else:
blk = down_sample_blk(128, 128)
return blk
- 定義網路中的每層的前向傳播函數
def blk_forward(x, blk, size, ratio, cls_predictor, offset_predictor):
"""為每個塊定義前向傳播
Args:
x (_type_):輸入的特徵圖,batch * channel * h * w
blk (_type_):網路
size (_type_):生成錨框的尺寸
ratio (_type_):生成錨框的高寬比
cls_predictor (_type_):用於分類的conv
offset_predictor (_type_):用於迴歸的conv
Returns:
CNN特徵圖y;在當前尺度下根據y生成的錨框;預測的這些錨框的類別和偏移量(基於y)
"""
y = blk(x)
# 以下兩個預測相當於生成錨框再進行的預測
cls_preds = cls_predictor(y)
offset_preds = offset_predictor(y)
# 生成錨框
anchors = mb.multibox_prior(y, sizes=size, ratios=ratio)
return (y, anchors, cls_preds, offset_preds)
- 定義網路
class TinySSD(nn.Module):
def __init__(self, num_classes):
super().__init__()
self.num_classes = num_classes
idx_to_in_channels = [64, 128, 128, 128, 128]
for i in range(5):
setattr(self, f'blk_{i}', get_blk(i))
setattr(self, f'cls_{i}', cls_predictor(idx_to_in_channels[i], num_anchors, self.num_classes))
setattr(self, f'offset_{i}', offset_predictor(idx_to_in_channels[i], num_anchors))
def flatten_pred(self, pred):
"""把四維的pred展平成二維
先把通道放到最後一維是因為這樣對於每一個畫素點的預測後面都是連續的值
Args:
pred (_type_):一個batch的預測
Returns:
展平後的張量
"""
return torch.flatten(pred.permute(0, 2, 3, 1), start_dim=1)
def concat_preds(self, preds):
return torch.cat([self.flatten_pred(p) for p in preds], dim=1)
def forward(self, x):
anchors, cls_preds, offset_preds = [None] * 5, [None] * 5, [None] * 5
for i in range(5):
x, anchors[i], cls_preds[i], offset_preds[i] = blk_forward(
x, getattr(self, f'blk_{i}'), sizes[i], ratios[i], getattr(self, f'cls_{i}'), getattr(self, f'offset_{i}'))
# 注意以下的num_all_anchors指的是一個樣本在所有特徵圖上生成的錨框
anchors = torch.cat(anchors, dim=1)# 1*num_all_anchors*4
cls_preds = self.concat_preds(cls_preds)# batch*(num_all_anchors*num_classes)
cls_preds = cls_preds.reshape(cls_preds.shape[0], -1, self.num_classes)
offset_preds = self.concat_preds(offset_preds)# batch*(num_all_anchors*4)
return anchors, cls_preds, offset_preds
- 定義損失函數
cls_loss = nn.CrossEntropyLoss(reduction='none')
offset_loss = nn.L1Loss(reduction='none')
def calc_loss(cls_preds, cls_labels, offset_preds, offset_labels, offset_masks):
batch_size, num_classes = cls_preds.shape[0], cls_preds.shape[2]
l1 = cls_loss(cls_preds.reshape(-1, num_classes), cls_labels.reshape(-1))
l1 = l1.reshape(batch_size, -1).mean(dim=1)
l2 = offset_loss(offset_preds*offset_masks, offset_labels*offset_masks).mean(dim=1)
return l1 + l2
- 定義評測的函數
# 分類準確率函數
def cls_eval(cls_preds, cls_labels):
# 返回這個batch中所有錨框預測正確的個數
return float((cls_preds.argmax(dim=-1).type(cls_labels.dtype) == cls_labels).sum())
def offset_eval(offset_preds, offset_labels, offset_mask):
# 返回這個batch中的所有的錨框預測的偏移量的損失
return float((torch.abs((offset_preds - offset_labels) * offset_mask)).sum())
5. 訓練
- 定義訓練函數和一些初始化引數
device, net = mb.try_gpu(), TinySSD(num_classes = 2)
updater = torch.optim.SGD(net.parameters(), lr = 0.2, weight_decay=0)
num_epochs = 10
animator = mb.Animator(xlabel='epoch', xlim=[1, num_epochs], legend=['class error', 'offset mae'])
net = net.to(device)
#blk_forward中會呼叫sizes和ratios,用來生成錨框用
sizes = [[0.2, 0.272], [0.37, 0.447], [0.54, 0.619], [0.71, 0.79], [0.88, 0.961]]
ratios = [[1, 2, 0.5]]*5
num_anchors = len(sizes[0]) + len(ratios[0]) - 1
for epoch in range(num_epochs):
metric = mb.Accumulator(4)
net.train()
for x, y in train_iter:
x, y = x.to(device), y.to(device)
y = y / 256 #因為原圖就是256*256的,為了把標籤歸一化
anchors, cls_preds, offset_preds = net(x) #得到批次預測結果和錨框
offset_labels, offset_mask, cls_labels = mb.multibox_target(anchors, y) #得到批次anchors的標籤
l = calc_loss(cls_preds, cls_labels, offset_preds, offset_labels, offset_mask)
updater.zero_grad()
l.mean().backward()
updater.step()
metric.add(cls_eval(cls_preds, cls_labels), cls_labels.numel(),
offset_eval(offset_preds, offset_labels, offset_mask), offset_labels.numel())
cls_err = 1 - metric[0] / metric[1]
offset_mae = metric[2] / metric[3]
animator.add(epoch+1, (cls_err, offset_mae))
6. 預測
- 首先定義非極大抑制函數
非極大抑制就是把所有的預測框按照置信度從大到小排序,把和最大的預測框的iou值大於一定閾值的預測框設定為背景
def nms(boxes, scores, iou_threshold):
#boxes為所有的預測框, scores為每個預測框對應的預測類別概率最大的值
#對預測邊界框的置信度進行排序
B = torch.argsort(scores, dim = -1, descending=True)#得到從大到小的預測概率所對應的預測框下標
keep = []
while B.numel()>0: # 直到把所有框都存取過了,再退出迴圈
i = B[0] # B中的預測概率最大值的下標(對應著相應的預測框)
keep.append(i)
if B.numel() == 1: break
# 所有的iou大於閾值的全部去掉
iou = box_iou(boxes[i,:].reshape(-1,4),
boxes[B[1:],:].reshape(-1,4)).reshape(-1)
inds = torch.nonzero(iou <= iou_threshold).reshape(-1) #得到所有<閾值的下標
B = B[inds + 1]#+1是因為得到這些與最大概率預測框的iou小於閾值的預測框的在B中的下標,然後把B更新成小於閾值的預測框
return torch.tensor(keep, dtype=torch.long, device=boxes.device)#返回未被抑制的預測框的下標
# 將非極大值抑制應用於預測邊界框
def multibox_detection(cls_probs,offset_preds,anchors,nms_threshold=0.5,pos_threshold=0.009999999):
#cls_probs:每一個預測框對每一類的預測概率,batch * num_classes * num_predicted_bb
#offset_preds:batch * num_anchors * 4
device, batch_size = cls_probs.device, cls_probs.shape[0]
anchors = anchors.squeeze(0)
num_classes, num_anchors = cls_probs.shape[1], cls_probs.shape[2]
out = []
for i in range(batch_size):
cls_prob, offset_pred = cls_probs[i], offset_preds[i].reshape(-1,4) # num_anchors * 4
predicted_bb = offset_inverse(anchors,offset_pred) # 把預測框拿出來
#下面conf得到不考率背景的每一個預測框的對每一類物體的最大概率值和相應的下標,classid這裡變成用0代表第一類物體了
#不考慮背景是因為在抑制的時候防止因為背景框把物體檢測的框抑制了
conf, class_id = torch.max(cls_prob ,dim = 0)
background_indices = torch.nonzero(class_id == 0).reshape(-1)# 背景預測框的下標
non_background_indices = torch.nonzero(class_id != 0).reshape(-1)# 非背景預測框的下標
non_back_predictbb = predicted_bb[non_background_indices]
non_back_conf = conf[non_background_indices]
keep = nms(non_back_predictbb, non_back_conf, nms_threshold)
# 獲取被抑制的預測框
non_keep = []
for idx, _ in enumerate(non_back_predictbb):
if idx not in keep:
non_keep.append(idx)
# 將被抑制的預測框的類別設定為0
class_id[non_background_indices[non_keep]] = 0
# 下面就是把所有預測框重新排列了一下,前面放的沒有被抑制的,後面放的被抑制的
all_sorted_indices = torch.cat((non_background_indices[keep], #非背景框
non_background_indices[non_keep],#背景框
background_indices), dim=0)#背景框
class_id = class_id[all_sorted_indices]
conf = conf[all_sorted_indices]
predicted_bb = predicted_bb[all_sorted_indices]
# pos_threshold是一個用於非背景預測的閾值, 如果有預測目標概率小於pos那個值則被視為背景
below_min_idx = (conf < pos_threshold)
class_id[below_min_idx] = 0
conf[below_min_idx] = 1 - conf[below_min_idx] # 增加背景的置信度
# 返回預測的資訊,共num_anchors行,每一行6個資訊,分別為:類別,預測概率值,4個左上右下座標
pred_info = torch.cat((class_id.unsqueeze(1), conf.unsqueeze(1), predicted_bb), dim=1)
out.append(pred_info)
return torch.stack(out)#batch*(共num_anchors行,每一行6個資訊,分別為:類別,預測概率值,4個左上右下座標)
- 定義預測函數
x, y = next(iter(train_iter))
x = x[0]
img = x.permute(1, 2, 0)
x = x.unsqueeze(0)
def predict(X):
net.eval()
net.to(device)
X = X.to(device)
anchors, cls_preds, offset_preds = net(X)
cls_probs = F.softmax(cls_preds, dim=2).permute(0, 2, 1)
output = mb.multibox_detection(cls_probs, offset_preds, anchors)
idx = [i for i, row in enumerate(output[0]) if row[0] != 0]
return output[0, idx]#第0個樣本,idx下表對應的錨框
output = predict(x)
def display(img, output, threshold):
fig = mb.plt.imshow(img)
for row in output:
score = float(row[1])
if score < threshold:
continue
h, w = img.shape[0:2]
bbox = [row[2:6] * torch.tensor((w, h, w, h), device=row.device)]
mb.show_bboxes(fig.axes, bbox, '%.2f' % score, 'w')
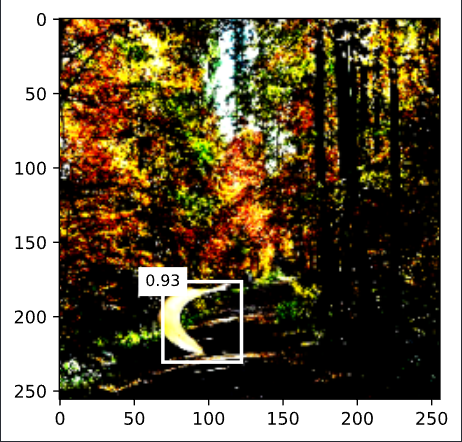
display(img, output.cpu(), threshold=0.9)
- 結果
7. SSD原理性分析
SSD通過多尺度的特徵圖實現對不同大小目標的檢測,處在深層的特徵圖的感受野比較大,所以設定的錨框的sizes較大,折積核通過對特徵圖中每一個位置做折積進而生成該位置處所對應的錨框們的預測,因為在該位置處折積核的感受野足夠大(包含了該位置對應的錨框),所以可以通過該位置的折積(這個折積和全連線其實是一樣的,把折積的元素展平就是做的向量內積\(w^T*x\),所以這裡相當於用折積去實現區域性全連線)去做錨框的預測,因為有錨框的資訊在裡面,由於感受野很大,所以可以更加準確的預測距離真實邊界框的距離(因為折積核可以看到錨框核真實框的距離資訊)
(以上內容完全來自個人理解,不足請不吝指出)
本文來自部落格園,作者:SXQ-BLOG,轉載請註明原文連結:https://www.cnblogs.com/sxq-blog/p/16672884.html