紀錄檔:Redo Log 和 Undo Log
本篇文章主要介紹 Redo Log 和 Undo Log:
- 利用 Redo Log 和 Undo Log 實現本地事務的原子性、永續性
- Redo Log 的寫回策略
- Redo Log Buffer 的刷盤時機
紀錄檔:Redo Log 和 Undo Log · 語雀 (yuque.com)
通過寫入紀錄檔來保證原子性、永續性是業界的主流做法。
介紹 Redo Log 和 Undo Log
Redo Log 是什麼:Redo Log 被稱為重做紀錄檔。
Undo Log 是什麼:Undo Log 被稱為復原紀錄檔、回滾紀錄檔。
技術是為了解決問題而生的,通過 Redo Log 我們可以實現崩潰恢復,防止資料更新丟失,保證事務的永續性。也就是說,在機器故障恢復後,系統仍然能夠通過 Redo Log 中的資訊,持久化已經提交的事務的操作結果。
技術是為了解決問題而生的,Undo Log 的作用 / 功能:
- 事務回滾:可以對提前寫入的資料變動進行擦除,實現事務回滾,保證事務的原子性。
- 實現 MVCC 機制:Undo Log 也用於實現 MVCC 機制,儲存記錄的多個版本的 Undo Log,形成版本鏈。
Undo Log 中儲存了回滾需要的資料。在事務回滾或者崩潰恢復時,根據 Undo Log 中的資訊對提前寫入的資料變動進行擦除。
Redo Log 和 Undo Log 都是用於實現事務的特性,並且都是在儲存引擎層實現的。由於只有 InnoDB 儲存引擎支援事務,因此只有使用 InnoDB 儲存引擎的表才會使用 Redo Log 和 Undo Log。
實現本地事務的原子性、永續性
「Write-Ahead Log」紀錄檔方案
MySQL 的 InnoDB 儲存引擎使用「Write-Ahead Log」紀錄檔方案實現本地事務的原子性、永續性。
「提前寫入」(Write-Ahead),就是在事務提交之前,允許將變動資料寫入磁碟。與「提前寫入」相反的就是,在事務提交之前,不允許將變動資料寫入磁碟,而是等到事務提交之後再寫入。
「提前寫入」的好處是:有利於利用空閒 I/O 資源。但「提前寫入」同時也引入了新的問題:在事務提交之前就有部分變動資料被寫入磁碟,那麼如果事務要回滾,或者發生了崩潰,這些提前寫入的變動資料就都成了錯誤。「Write-Ahead Log」紀錄檔方案給出的解決辦法是:增加了一種被稱為 Undo Log 的紀錄檔,用於進行事務回滾。
變動資料寫入磁碟前,必須先記錄 Undo Log,Undo Log 中儲存了回滾需要的資料。在事務回滾或者崩潰恢復時,根據 Undo Log 中的資訊對提前寫入的資料變動進行擦除。
「Write-Ahead Log」在崩潰恢復時,會經歷以下三個階段:
- 分析階段(Analysis):該階段從最後一次檢查點(Checkpoint,可理解為在這個點之前所有應該持久化的變動都已安全落盤)開始掃描紀錄檔,找出所有沒有 End Record 的事務,組成待恢復的事務集合(一般包括 Transaction Table 和 Dirty Page Table)。
- 重做階段(Redo):該階段依據分析階段中,產生的待恢復的事務集合來重演歷史(Repeat History),找出所有包含 Commit Record 的紀錄檔,將它們寫入磁碟,寫入完成後增加一條 End Record,然後移除出待恢復事務集合。
- 回滾階段(Undo):該階段處理經過分析、重做階段後剩餘的待恢復事務集合,此時剩下的都是需要回滾的事務(被稱為 Loser),根據 Undo Log 中的資訊回滾這些事務。
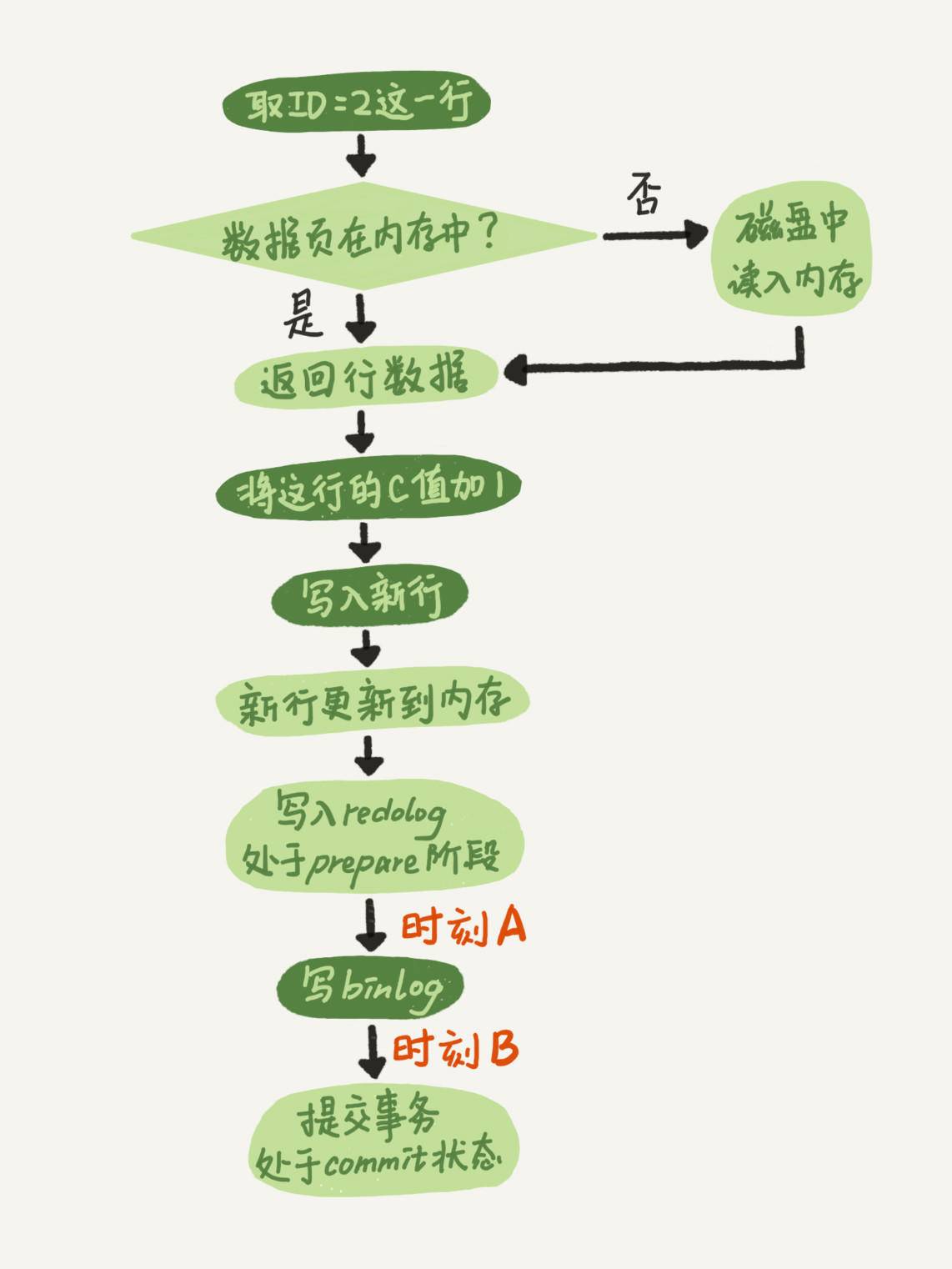
MySQL 中一條 SQL 更新語句的執行過程
以下的執行過程限定在,使用 InnoDB 儲存引擎的表
-
事務開始
-
申請加鎖:表鎖、MDL 鎖、行鎖、索引區間鎖(看情況加哪幾種鎖)
-
執行器找儲存引擎取資料。
-
- 如果記錄所在的資料頁本來就在記憶體(innodb_buffer_cache)中,儲存引擎就直接返回給執行器;
- 否則,儲存引擎需要先將該資料頁從磁碟讀取到記憶體,然後再返回給執行器。
-
執行器拿到儲存引擎給的行資料,進行更新操作後,再呼叫儲存引擎介面寫入這行新資料。
-
儲存引擎將回滾需要的資料記錄到 Undo Log,並將這個更新操作記錄到 Redo Log,此時 Redo Log 處於 prepare 狀態。並將這行新資料更新到記憶體(innodb_buffer_cache)中。同時,然後告知執行器執行完成了,隨時可以提交事務。
-
手動事務 commit:執行器生成這個操作的 Binary Log,並把 Binary Log 寫入磁碟。
-
執行器呼叫儲存引擎的提交事務介面,儲存引擎把剛剛寫入的 Redo Log 改成 commit 狀態。
-
事務結束
其中第 5 步,將這個更新操作記錄到 Redo Log。生成的 Redo Log 是儲存在 Redo Log Buffer 後就返回,還是必須寫入磁碟後才能返回呢?
這就是 Redo Log 的寫入策略,Redo Log 的寫入策略由 innodb_flush_log_at_trx_commit 引數控制,該引數不同的值對應不同的寫入策略。
還有第 6 步,把 Binary Log 寫入磁碟和 Redo Log 一樣,也有相應的寫回策略,由引數 sync_binlog 控制。
通常我們說 MySQL 的「雙 1」設定,指的就是 sync_binlog 和 innodb_flush_log_at_trx_commit 都設定成 1。也就是說,一個事務提交前,需要等待兩次刷盤,一次是 Redo Log 刷盤(prepare 階段),一次是 Binary Log 刷盤。
Redo Log 的兩階段提交 & 崩潰恢復
在上面【MySQL 中一條 SQL 更新語句的執行過程】部分,最後將 Redo Log 的寫入拆成了兩個步驟:prepare 和 commit,這就是"兩階段提交"。
「兩階段提交」的作用 / 目的:
- 將事務設定為 prepare,為了在崩潰重啟時,能夠知道事務的狀態
- 保證兩份紀錄檔(Binary Log 和 Redo Log)之間的邏輯一致。
如果先寫 Redo Log,再寫 Binary Log 或者 先寫 Binary Log,再寫 Redo Log,寫入第一個紀錄檔後,如果此時發生了崩潰,那麼第二個紀錄檔沒有寫入,就造成了兩個紀錄檔的不一致。資料庫的狀態就有可能和用 Binary Log 恢復出來的庫的狀態不一致。備庫利用 Binary Log 進行資料同步,就會出現主備庫資料不一致的問題。具體的講解可以看極客時間的專欄《MySQL實戰45講》
而使用「兩階段提交」,遵守「崩潰恢復時,判斷事務該提交、還是該回滾的規則」,就可以保證兩份紀錄檔(Binary Log 和 Redo Log)之間的邏輯一致。
「崩潰恢復時,判斷事務該提交、還是該回滾的規則」如下:
- 如果 Redo Log 裡面的事務是完整的,也就是已經有了 commit 標識,那麼利用該 Redo Log 中的資訊,持久化事務的操作結果;
- 如果 Redo Log 裡面的事務只有完整的 prepare,則判斷對應事務的 Binary Log 是否存在並完整:
a. 如果是,利用該 Redo Log 中的資訊,持久化事務的操作結果;
b. 如果否,則回滾事務,根據 Undo Log 中的資訊對提前寫入的資料變動進行擦除。
如果事務寫入 Redo Log 處於 prepare 階段之後、寫 Binary Log 之前,發生了崩潰(也就是時刻 A 發生了崩潰),由於此時 Binary Log 還沒寫,Redo Log 也還沒處於 commit 狀態,所以崩潰恢復的時候,這個事務會回滾。這時 Binary Log 還沒寫,所以也不會傳到備庫。主庫和備庫的資料狀態一致。
如果事務寫入 Binary Log 之後,Redo Log 還沒處於 commit 狀態之前,發生了崩潰(也就是時刻 B 發生了崩潰),根據崩潰恢復時的判斷規則中第 2 條,Redo Log 處於 prepare 階段,Binary Log 完整,所以崩潰恢復的時候,會利用該 Redo Log 中的資訊,持久化事務的操作結果。這時 Binary Log 已經寫了,所以會傳到備庫。主庫和備庫的資料狀態一致。
Binary Log 的寫入在崩潰恢復時,判斷事務該提交還是該回滾時,起到了至關重要的作用,只有 Binary Log 寫入成功才能保證兩份紀錄檔(Binary Log 和 Redo Log)之間的邏輯一致,才能考慮提交。
Redo Log 設定的選項
- innodb_log_buffer_size:Redo Log Buffer 的記憶體大小
- innodb_log_file_size:單個 Redo Log 檔案的空間大小
- innodb_log_files_in_group:Redo Log 檔案的數量(預設值是 2)
- innodb_log_group_home_dir:Redo Log 檔案的儲存目錄(預設值是 .\ ,即資料目錄)
- innodb_flush_log_at_trx_commit:Redo Log 的寫入策略
Redo Log 的寫入策略
我們在【MySQL 中一條 SQL 更新語句的執行過程】部分的第 5 步中說:儲存引擎將這行新資料更新到記憶體(innodb_buffer_cache)中。同時,將這個更新操作記錄到 Redo Log,此時 Redo Log 處於 prepare 狀態。然後告知執行器執行完成了,隨時可以提交事務。
生成的 Redo Log 是儲存在 Redo Log Buffer 後就返回,還是必須寫入磁碟後才能返回呢?這就是 Redo Log 的寫入策略。Redo Log 的寫入策略由 innodb_flush_log_at_trx_commit 引數控制。
我們可以通過修改該引數的值,設定 Redo Log 的寫入策略,該引數可選的值有 3 個:
- 值為 0 :表示每次事務提交時,只是把 Redo Log 儲存到記憶體(Redo Log Buffer)就返回,不關心寫入檔案
- 值為 1 :表示每次事務提交時,將 Redo Log Buffer 中的內容寫入並同步到檔案後才能返回(write + fsync 才能返回,這是引數的預設值)
- 值為 2 :表示每次事務提交時,只是把 Redo Log Buffer 中的內容寫入核心緩衝區,但不對檔案進行同步,何時同步由作業系統來決定(write,fsync 的時機由作業系統決定)
Redo Log 檔案組
MySQL 的資料目錄(使用 show variables like 'datadir' 檢視)下預設有兩個名為 ib_logfile0 和
ib_logfile1 的檔案,Redo Log Buffer 中的 Redo Log 預設情況下就是重新整理到這兩個磁碟檔案中。
資料目錄的位置也可以通過以下命令檢視:select @@datadir;

如果我們對預設的 Redo Log 檔案組不滿意,可以通過下邊幾個啟動引數來調節:
- innodb_log_buffer_size:每個 Redo Log 檔案的空間大小
- innodb_log_file_size:每個 Redo Log 檔案的最大空間大小
- innodb_log_files_in_group:Redo Log 檔案組中所有 Redo Log 檔案的數量(預設值是 2,最大值是 100)
- innodb_log_group_home_dir:Redo Log 檔案的儲存目錄(預設值是 .\ ,即 MySQL 的資料目錄)
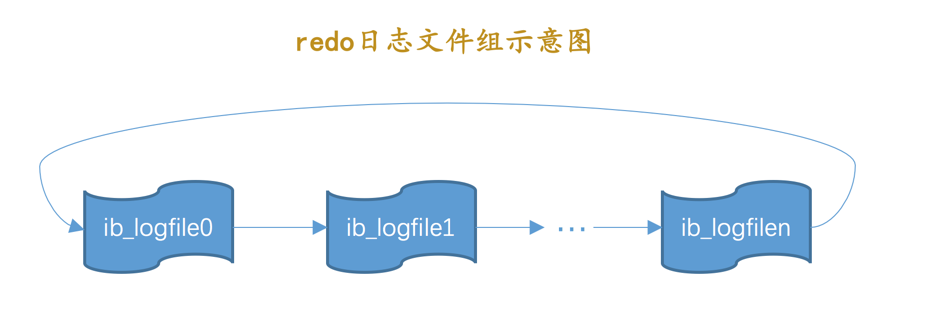
從上邊的描述中可以看到,磁碟上的 Redo Log 檔案不只一個,而是以一個 紀錄檔檔案組 的形式出現的。這些檔案
以 ib_logfile[數位] ( 數位 可以是 0 、 1 、 2 ...)的形式進行命名。
在將 Redo Log 寫入 紀錄檔檔案組 時,是從 ib_logfile0 開始寫,如果 ib_logfile0 寫滿了,就接著 ib_logfile1 寫,同理, ib_logfile1 寫滿了就去寫 ib_logfile2 ,依此類推。
如果寫到最後一個檔案該怎麼辦呢?那就重新轉到 ib_logfile0 繼續寫,所以整個過程如下圖所示:
總共的 Redo Log 檔案空間大小其實就是:innodb_log_file_size × innodb_log_files_in_group 。(單個檔案的空間大小 * 檔案組中的檔案個數)
如果採用迴圈使用的方式向 Redo Log 檔案組裡寫資料的話,那就會造成追尾,也就是後寫入的 Redo Log 覆蓋掉前邊寫的 Redo Log。為了解決 Redo Log 的覆蓋寫入問題,InnoDB 的設計者提出了 checkpoint 的概念。
Redo Log 寫入 Redo Log Buffer
Redo Log 的格式
InnoDB 的設計者為 Redo Log 定義了多種型別,以應對事務對資料庫的不同修改場景,但是絕大部分型別的 Redo Log 都有下邊這種通用的結構:

各個部分的詳細釋義如下:
- type:該條 Redo Log 的型別
- space ID :表空間ID
- page number :頁號
- data :該條 Redo Log 的具體內容
在 MySQL 5.7.21 這個版本中,InnoDB 的設計者一共為 Redo Log 設計了 53 種不同的型別。各種型別的 Redo Log 的不同之處在於 data 的具體結構不同。
Redo Log 的具體格式可以看掘金小冊《MySQL 是怎樣執行的:從根兒上理解 MySQL》
這些型別的 Redo Log 既包含 物理 層面的意思,也包含 邏輯 層面的意思,具體指:
- 物理層面看,這些紀錄檔都指明瞭對哪個表空間的哪個頁進行了什麼修改。
- 邏輯層面看,在系統奔潰重啟時,並不能直接根據 Redo Log 中的資訊,將頁面內的某個偏移量處恢復成某個資料,而是需要呼叫一些事先準備好的函數,執行完這些函數後才可以將頁面恢復成系統奔潰前的樣子。
總結來說,Redo Log 中記錄的是該操作對哪個表空間的哪個頁的哪個偏移量進行了什麼修改。
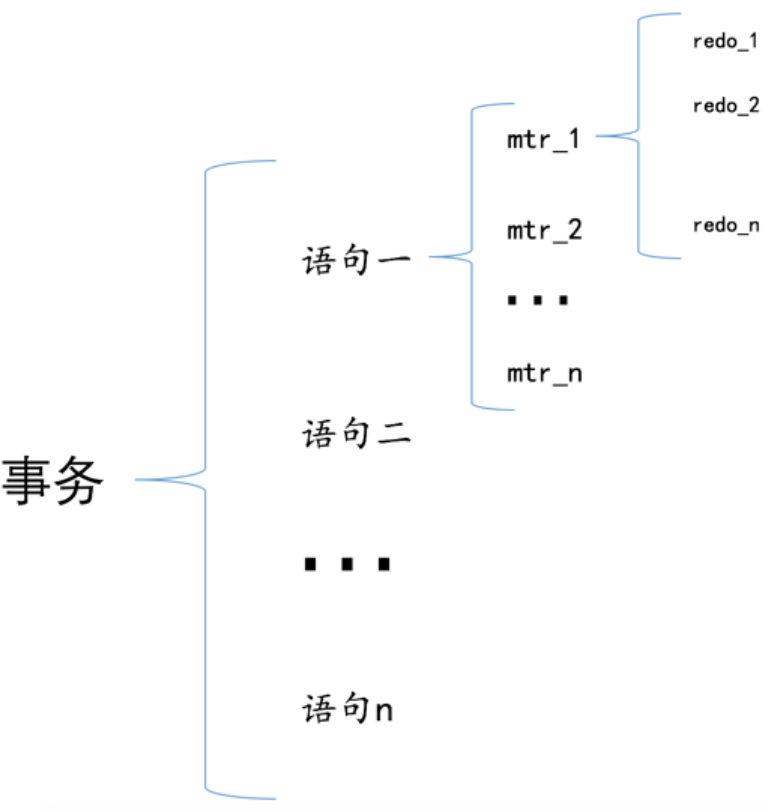
Mini-Transaction
一個事務可能包含多條 SQL 語句,每一條 SQL 語句可能包含多個「對底層頁面的操作」,每個「對底層頁面的操作」可能包含多個 Redo Log。這樣的一個「對底層頁面的操作」的過程被稱為 Mini-Transaction,簡稱 mtr。
「對底層頁面的操作」比如說:
- 向聚簇索引對應的 B+ 樹的某個頁面中插入一條記錄,插入一條記錄這個操作可能包含多個 Redo Log
我們需要保證一個「對底層頁面的操作」對應的多個 Redo Log 不可分割,即一個「對底層頁面的操作」是原子的,這個操作對應的 Redo Log 要麼都寫入磁碟,要麼都不寫入磁碟。所以 InnoDB 的設計者規定在執行這些需要保證原子性的操作時必須以 組 的形式來記錄 Redo Log,在進行奔潰恢復時,針對某個組中的 Redo Log,要麼把全部的 Redo Log 都恢復掉,要麼一個 Redo Log 也不恢復。
那麼 InnoDB 的設計者是怎麼做到分組的呢?InnoDB 的設計者在一個「對底層頁面的操作」的最後一個 Redo Log 後面加上一個特殊型別的 Redo Log。相當於某個需要保證原子性的操作產生的一系列 Redo Log 必須要以一個特殊型別的 Redo Log 結尾,這樣在奔潰恢復時:
- 只有當解析到特殊型別的 Redo Log 時,才認為解析到了一組完整的 Redo Log,才會進行恢復。
- 否則的話直接放棄前邊解析到的 Redo Log。
Redo Log Buffer
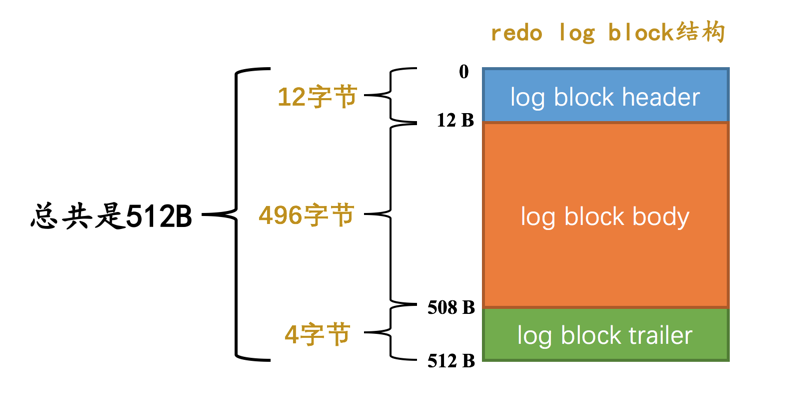
Redo Log Buffer 就是在伺服器啟動時,向作業系統申請的大一片連續的記憶體空間。
這片連續的記憶體空間被劃分為若干個連續的用來儲存 Redo Log 的資料頁。
用來儲存 Redo Log 的資料頁被稱為 Redo Log Block。
我們可以通過啟動引數 innodb_log_buffer_size 來指定 Redo Log Buffer 的大小。
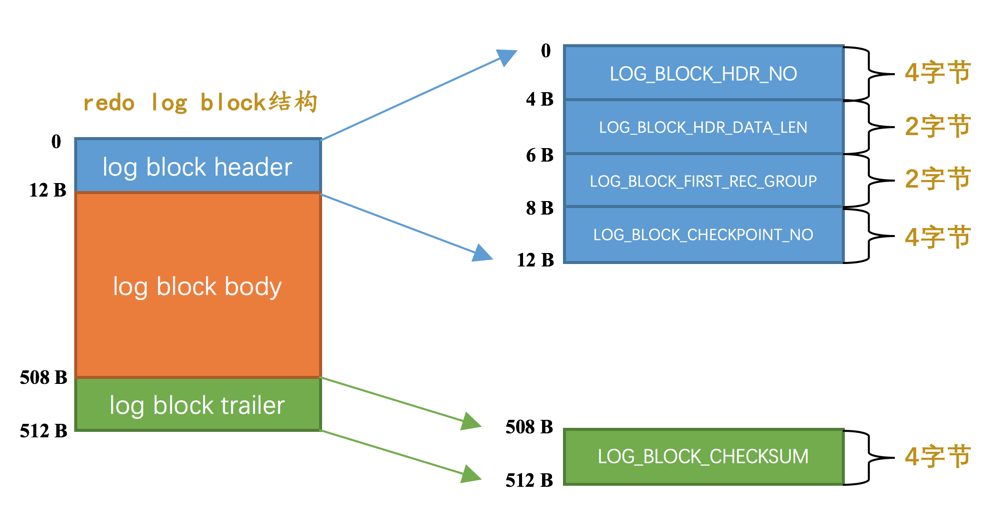
- LOG_BLOCK_CHECKPOINT_NO :表示 checkpoint 的序號
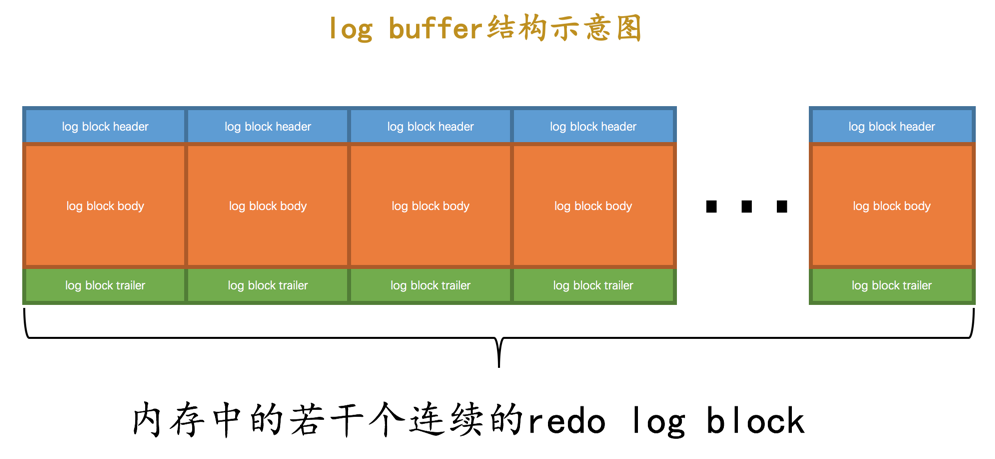
Redo Log 寫入 Redo Log Buffer
我們前邊說過一個 mtr 執行過程中可能產生若干個 Redo Log ,這些 Redo Log 是一個不可分割的組,所以其實並不是每生成一個 Redo Log,就將其插入到 Redo Log Buffer 中,而是每個 mtr 執行過程中產生的紀錄檔先暫時存到一個地方,當該 mtr 結束的時候,將過程中產生的一組 Redo Log 再全部複製到 Redo Log Buffer 中。
不同的事務可能是並行執行的,所以不同事務的 mtr 可能是交替執行的。每當一個 mtr 執行完成時,伴隨
該 mtr 生成的一組 Redo Log 就需要被複制到 Redo Log Buffer 中,也就是說不同事務的 mtr 可能是交替寫入 Redo Log Buffer 的。
Redo Log Buffer 中 Redo Log 的刷盤時機
mtr 執行過程中產生的一組 Redo Log 在 mtr 結束時會被複制到 Redo Log Buffer 中,在一些情況下 Redo Log Buffer 中的 Redo Log 會被寫回磁碟,Redo Log 的刷盤時機如下:
- Redo Log Buffer 的空間不足時,執行刷盤操作
- 一個事務提交時,執行刷盤操作(需要設定指定引數)
- 將某個髒頁重新整理到磁碟前,會先保證該髒頁對應的 Redo Log 重新整理到磁碟中(Redo Log 是順序寫入的,因此在將某個髒頁對應的 Redo Log 從 Redo Log Buffer 重新整理到磁碟時,也會保證將在其之前產生的 Redo Log 也重新整理到磁碟中。
- 後臺執行緒不停的執行刷盤操作
- 正常關閉伺服器時,執行刷盤操作
- 做 checkpoint 時,執行刷盤操作
Redo Log Buffer 的空間不足時,執行刷盤操作
Redo Log Buffer 的空間是有限的,空間大小由 innodb_log_buffer_size 來指定。
InnoDB 的設計者認為:如果 Redo Log Buffer 的記憶體被佔用 1 / 2,就需要把 Redo Log Buffer 中的 Redo Log 重新整理到磁碟。
一個事務提交時,執行刷盤操作
在前面【Redo Log 的寫入策略】部分,講到我們可以通過設定 innodb_flush_log_at_trx_commit 引數的值,在事務提交時執行刷盤操作後才能返回。
事務提交時執行刷盤操作後才能返回是 Redo Log 的預設寫入策略。
後臺執行緒不停的執行刷盤操作
後臺有一個執行緒,每秒都會執行一次刷盤操作。後臺執行緒執行刷盤操作的頻率可以通過引數設定。
具體通過哪個引數設定,我也不清楚。
正常關閉伺服器時,執行刷盤操作
做 checkpoint 時,執行刷盤操作
等等
Undo Log 的寫回策略
MySQL中的 Undo Log 嚴格的講不是 Log,而是資料,因此它的管理和落盤都跟資料是一樣的:
- Undo 的磁碟結構並不是順序的,而是像資料一樣按 Page 管理
- Undo 寫入時,也像資料一樣產生對應的 Redo Log
- Undo 的 Page 也像資料一樣快取在 Buffer Pool 中,跟資料 Page 一起做 LRU 換入換出,以及刷髒。Undo Page 的刷髒也像資料一樣要等到對應的 Redo Log 落盤之後
之所以這樣實現,首要的原因是 MySQL 中的 Undo Log 不只是承擔 Crash Recovery 時保證 Atomic 的作用,更需要承擔 MVCC 對歷史版本的管理的作用,設計目標是高事務並行,方便的管理和維護。因此當做資料更合適。
但既然還叫 Log,就還是需要有 Undo Log 的責任,那就是保證 Crash Recovery 時,如果看到資料的修改,一定要能看到其對應 Undo 的修改,這樣才有機會通過事務的回滾保證 Crash Atomic。標準的 Undo Log 這一步是靠 WAL 實現的,也就是要求 Undo 寫入先於資料落盤。而 InnoDB 中 Undo Log 作為一種特殊的資料,這一步是通過 redo 的 min-transaction 保證的,簡單的說就是資料的修改和對應的 Undo 修改,他們所對應的 Redo Log 被放到同一個 min-transaction 中,同一個 min-transaction 中的所有 Redo Log 在 Crash Recovery 時以一個整體進行重放,要麼全部重放,要麼全部丟棄。
作者:CatKang
連結:https://www.zhihu.com/question/267595935/answer/2204949497
來源:知乎
Undo Log 設定的選項
- innodb_max_undo_log_size:值為,單個 Undo Log 最大可佔用的位元組儲存空間;單位為,位元組(預設值是 1 G)。
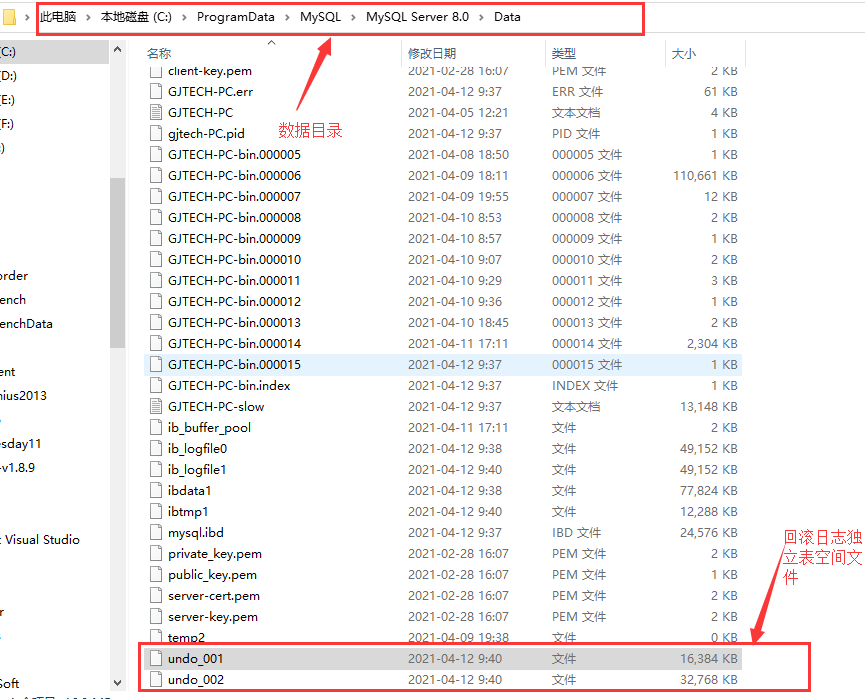
- innodb_undo_directory:Undo Log 檔案的儲存目錄(預設值是 .\ ,即資料目錄)表示回滾紀錄檔的儲存目錄是資料目錄,資料目錄的位置可以通過查詢變數「datadir」來檢視。
- innodb_undo_log_encrypt:Undo Log 是否加密(預設值是 off,即不加密)。
- innodb_undo_log_truncate:Undo Log 是否自動截斷回收(預設值是 on,即自動截斷回收)。這個變數有效的前提是設定了使用獨立表空間。
- innodb_undo_tablespaces:值為 Undo Log 的獨立表空間的數量(預設值是 0,即 Undo Log 沒有獨立的表空間,預設記錄到共用表空間 ibdata 檔案中)
參考資料
20 | 紀錄檔(下):系統故障,如何恢復資料? (geekbang.org)
MySQL 是怎樣執行的:從根兒上理解 MySQL - 小孩子4919 - 掘金課程 (juejin.cn)
本文來自部落格園,作者:真正的飛魚,轉載請註明原文連結:https://www.cnblogs.com/feiyu2/p/16672433.html