作業系統學習筆記8 |段頁式記憶體管理
多程序影象中的CPU管理已經告一段落,接下來要介紹另一大方面——記憶體管理。首先我們也來看看記憶體是如何被使用起來的。最後介紹段頁式記憶體管理的實現過程。
參考資料:
-
課程:哈工大作業系統(本部分對應 L20 && L21 && L22 && L23)
-
這一部分的難度僅次於學習筆記5
1. 記憶體的使用與分段
1.1 記憶體管理的直觀想法
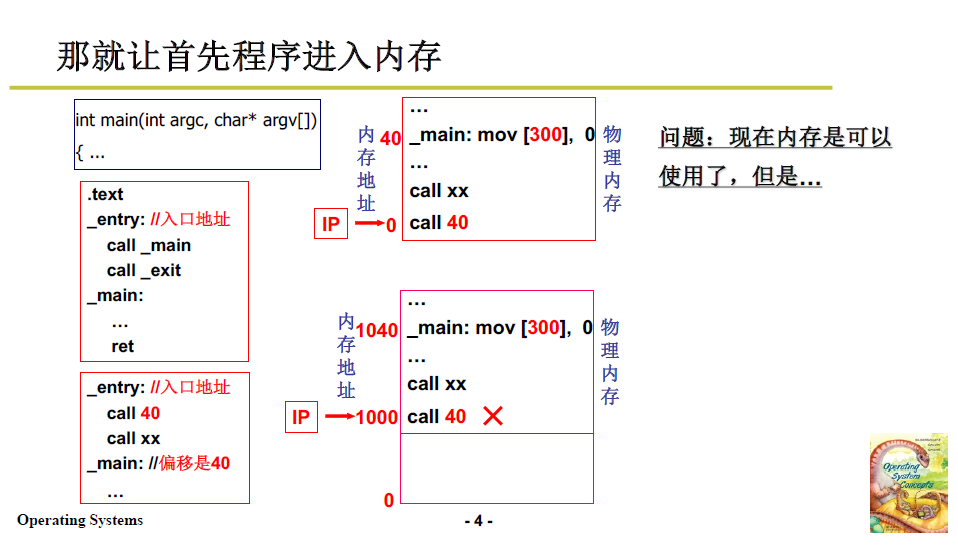
馮·諾依曼的儲存程式思想:取指執行。這種體系結構下的記憶體使用即程式放到記憶體中,PC指向開始地址。
下面從一段程式開始,如下圖:
程式編譯成組合後,裡面的標號偏移是從0開始的,例如 enrty 是 0,_main 的偏移是 40。而 40 就是 main函數開始的地方。
- 接下來需要將程式放入記憶體中。
總結梳理一下:
- 程式按照資料的不同用途分成多個段,每個段分別載入到記憶體的空閒區域,每個段的基址、長度等資訊存放在LDT表中
- 初始化好的 LDT 賦值給 PCB,可以通過 PCB 找到該程序的LDT表,接著在執行指令時通過 LDT 表查出段基址,加上指令本身的偏移就得到了實體地址
- 段基址+程式中的相對地址 = 實體記憶體地址
- ldtr暫存器是做什麼用的?
- 存放段編號,是查詢LDT表的索引 (相當於陣列下標)
- 之前講學習筆記5中拆解執行緒和記憶體管理的時候,提到的記憶體對映表,就是LDT表
1.7 補充:Linux 0.11 的分段處理方式
-
根據此前程序的相關學習,Linux0.11 下 TCB/PCB 的實現都是靠一個 task_struct 結構體;這個結構體裡面還有一個結構體 tss
-
tss裡面放的內容可以理解為是當前程序的CPU快照,儲存了CPU所有暫存器的值,也就儲存了當前程序的狀態。
-
由於程序切換,段暫存器的內容就放在task_struct 裡的 tss了
1.8 簡單總結
-
記憶體使用 -> 程式分段裝入記憶體 -> 重定位 -> 執行時重定位 -> LDT&GDT查表
-
對於其他程序,也是同樣的流程。
-
程序切換時,切換LDT表,這也就是此前提到過的記憶體對映表。
注意:LDT 是一個硬體概念,是一組暫存器。
這部分內容對應實驗六。
2. 記憶體分割區與分頁
- 上面從程式設計師視角、程式裝入記憶體的角度,我們將程式分成不同的段;
- 下面從記憶體的角度,看一看記憶體本身是怎麼分割區的。
2.1 記憶體使用過程
上面第一部分的學習角度,對於記憶體使用過程而言,還有缺陷;
-
編譯時,程式分成了多個段:程式碼段、資料段...
-
在記憶體中找到若干塊空閒的區域,用於存放多個段;
段可以不連續。
問題是記憶體為什麼可以一塊一塊的被找到呢(記憶體怎麼分割)?如何找到空閒的區域呢?這就是第二部分記憶體分割區要解決的問題。
-
將程式的各個段從磁碟中載入到找到的空閒記憶體區域中,並初始化LDT表,與PCB關聯起來
這部分涉及磁碟管理和裝置驅動,需要後續講。
初始化 LDT 以及與 PCB 關聯,就是第一部分後半截講到的內容。
2.2 記憶體分割區
2.2.1 分割區策略
記憶體分割區有兩種思路:固定分割區 和 可變分割區:
- 固定分割區:在作業系統初始化時將可用記憶體等長劃分,但很顯然不合適,因為程式各不相同,每個程式的段也有大有小;
- 可變分割區:根據段請求的需求進行記憶體劃分。
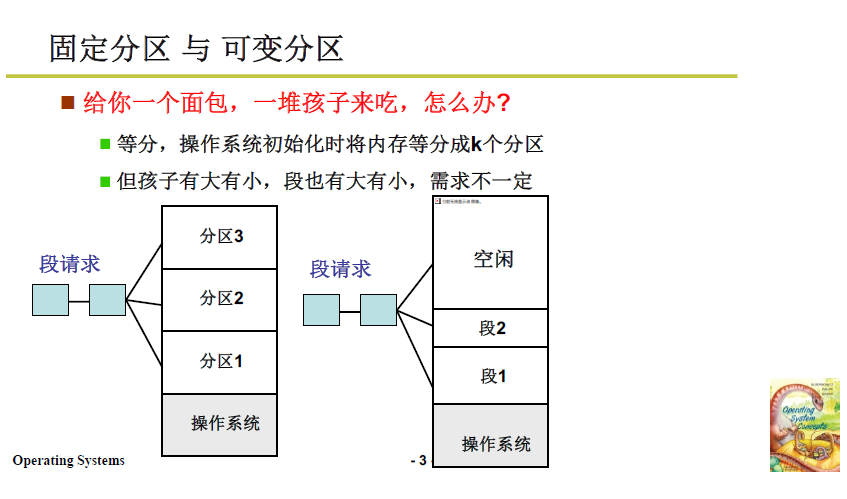
2.2.2 可變分割區的管理思路
想法其實非常簡單,對已分配和未分配的區域分別進行打表(資料結構),每次段請求時就查閱表格,分出相應記憶體時再將表格進行對應的修改。整個過程就跟 記賬取物 差不多。
- 首先是用已分配分割區表記錄 被佔用記憶體區域的起始地址和長度。
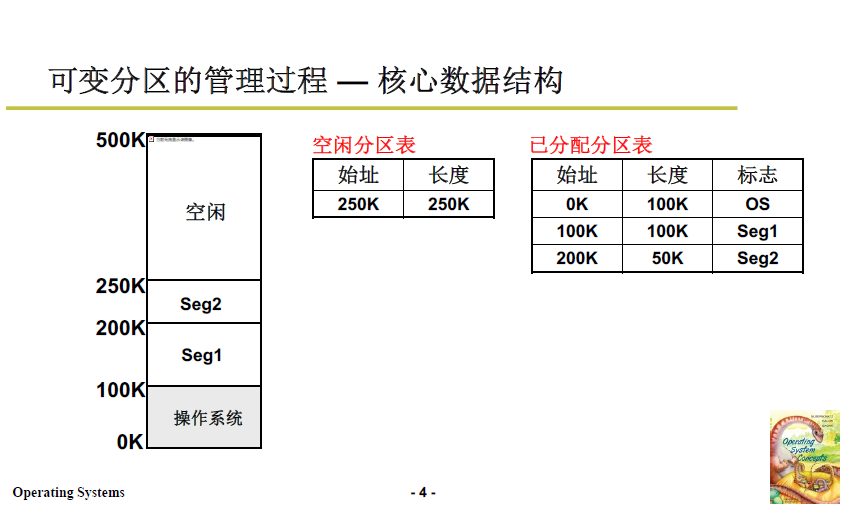
- 當段請求到來,根據請求從空閒記憶體劃分相應區域;並修改空閒分割區表和已分配分割區表;
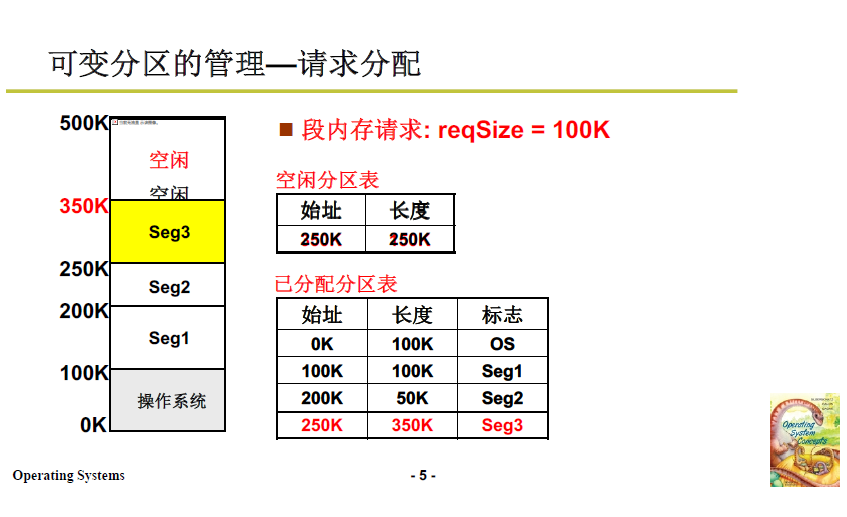
- 當某段程式不再需要,如下圖段2(200K到250K),則在空閒分割區表增加一項,在已分配分割區表中去除第三項。
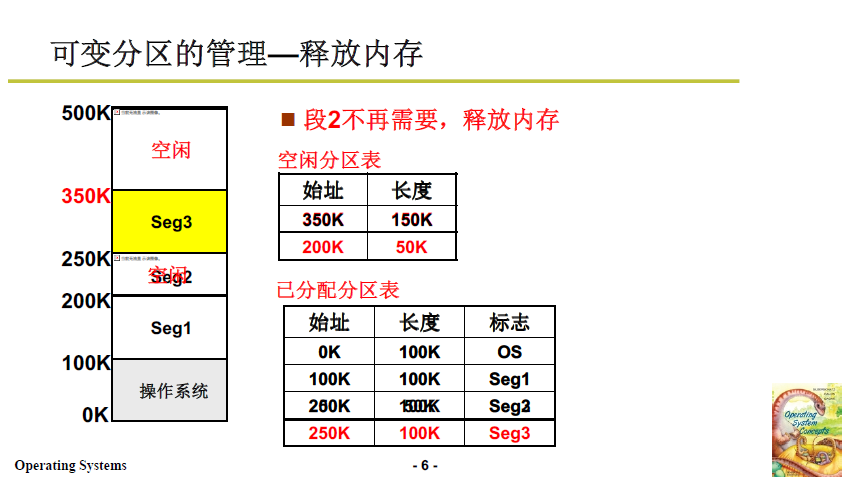
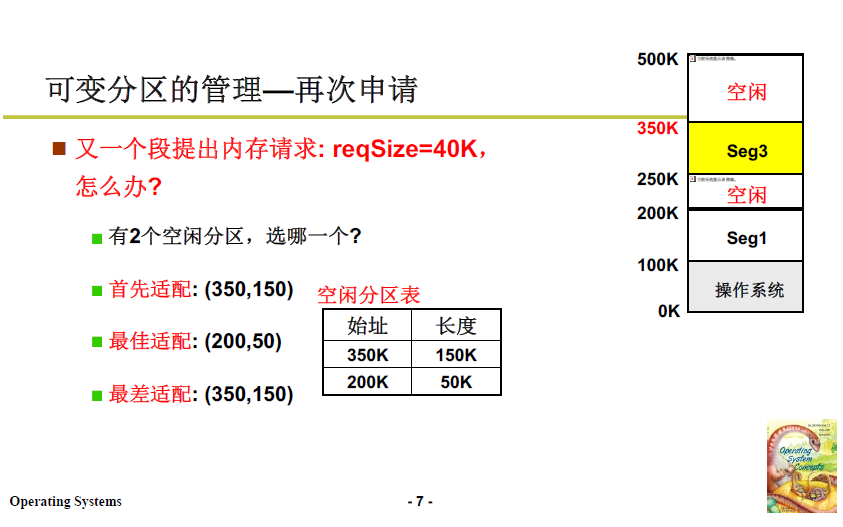
當段請求再次到來 reqSize = 40K,此時有兩個空閒區域,且都能滿足需要,應該分配到哪一塊中?接下來就涉及演演算法了。
2.2.3 空閒分割區選擇演演算法
- 最佳適配:
- 找到跟請求大小最接近的區域,即下圖中的50K大小的區域;
- 空閒分割區會越割越細,越割越碎。
- 最差適配:
- 找到跟請求大小最不適配的區域,即下圖長度150K的區域;
- 空閒分割區會趨於均勻。
- 首先適配:
- 找到第一個滿足請求大小的區域就放入;
- 這樣時間複雜度很低。
可見這幾種演演算法個有特點,很難說哪個更為優秀,只能講合不合適。
這裡 2.3 和 2.4 就是 資料結構(表) + 演演算法(選擇演演算法) 的結合
現代作業系統並不是通過記憶體分割區來做的,而是通過記憶體分頁。分割區演演算法實際上是虛擬記憶體的劃分方式,這個留待後話。
段對應的虛擬記憶體中的分割區,虛擬記憶體又要對應的分頁的實體記憶體上,這個後面講了段頁結合的記憶體管理就理解了
2.3 記憶體分頁
2.3.1 分割區的問題
記憶體分割區帶來的問題也顯而易見,無論哪種分割區選擇演演算法,最後都會帶來「破碎」的記憶體,如若最後到來一個大小為160K的段請求,就會出現沒有一個空閒分割區能夠適配的情況,但實際上空閒分割區加起來能夠超過160K。
當然也是可以解決的:移動記憶體分割區,使記憶體緊縮,讓記憶體空閒分割區擴大。
但是記憶體緊縮這種方法花費時間較大;並且移動過程要考慮到每個程序的 LDT 修改,記憶體移動過程中CPU不能執行上層使用者程式,相當於宕機了。
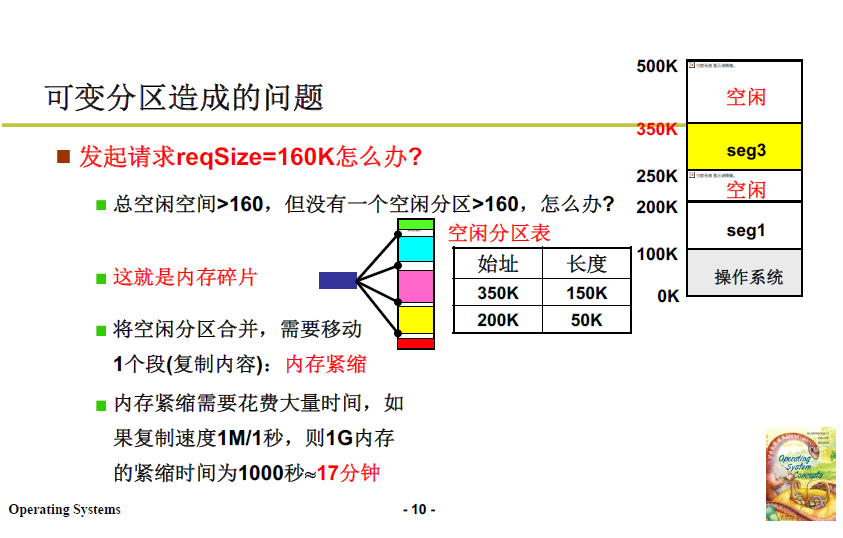
所以還有一種想法,即將請求大小 160K 打散。
2.3.2 分頁的處理方法
上面分割區的方法中,記憶體就像麵包,被切碎,最後剩下了誰都不想要的碎屑;而分頁的考慮就是,將麵包切成片,將記憶體分成頁。
-
作業系統初始化時,將實體記憶體分為大小一定的頁;
- 實際上就是限制最小可劃分的記憶體單元,避免過小碎片的產生;
- 在 學習筆記1的main.c部分 中的 mem_map 就是完成上述的初始化工作,將記憶體打成 4k 為單位的頁,若被使用則為1,空閒則為0.
-
針對每個段的記憶體請求,系統一頁一頁地分配給這個段,並向上取整。
-
這樣就避免了記憶體分割區效率低的問題,並且不需要記憶體緊縮。由於設定了最小可分單元--頁,一個程式最多浪費 4K-1 的記憶體空間。

實體記憶體的角度要求記憶體浪費盡可能少,而使用者/程式設計師 角度更能理解分段的思想。所以後續會繼續介紹分頁和分段結合起來的綜合辦法。
2.3.3 定址方式
段被打散為頁,但跟分割區一樣,程式在以頁為單位的記憶體中同樣需要被定址才能被執行。
-
比如,我們需要執行一個
jmp 40這個指令,我們需要知道 40 被分配到了哪一頁上。 -
假設頁的大小為100,那麼40在第0頁;
同段的頁共用一套邏輯地址,因為是同一個程式中的地址。比如頁1的地址就是從100~199
-
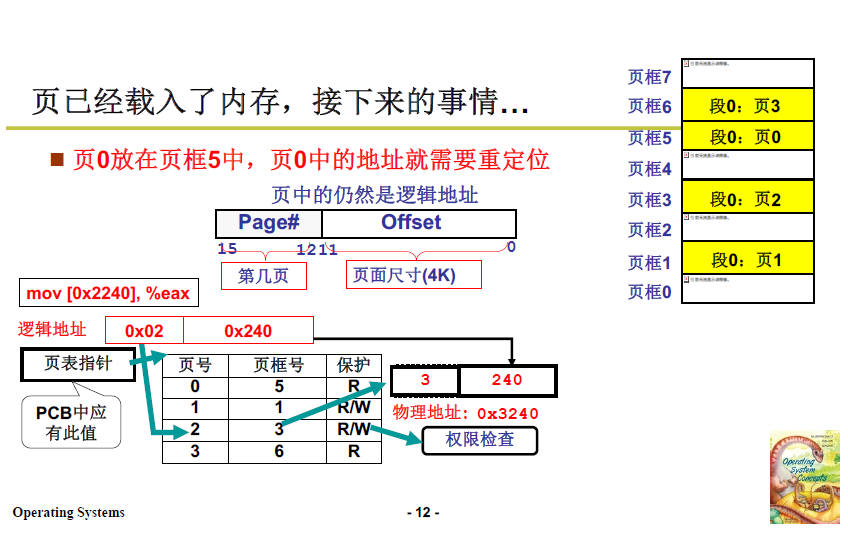
實體地址怎麼算?第0頁放在第5頁框(實體記憶體度量),所以實際上應當是540.
邏輯地址結構如下圖所示:一共16位元,高4位元表示查詢頁表的索引,低12位元是偏移量,也意味著頁的大小(最大偏移)為 4K。
4K 的設計在16進位制中正好是3位,對於一個地址來說,右移3位即可得到它所在的頁。
定址過程如下圖所示:
頁表索引暫存器 cr3 儲存頁表相關資訊(之前的段表索引暫存器是ldtr),同樣的,PCB 關聯了頁表(有指向頁表的指標),在切換程序時,用 PCB 指向的頁表對 CR3 進行賦值。
頁表索引暫存器 CR3 儲存 頁號、頁框號和許可權檢查。
表用來建立邏輯地址與實體地址的聯絡。
實際的實體地址=物理頁框號對應的物理基地址+邏輯地址的低12位元。
範例:
-
對於指令
mov [0x2240],%eax,首先定址 [0x2240]; -
0x2240 右移3位(4k)得到0x2,餘數為 0x240,這表示地址所在的頁號為2,頁內偏移為240;
-
拿著頁號 2 查詢頁表索引,得到頁框號 3;
還是注意區分頁號和頁框號。頁號是邏輯地址的分頁,頁框號是實體地址的分塊單元(也意味著首地址)。
-
3*4k + 240 即為真實實體地址 3240。
-
上述定址過程由 MMU,記憶體管理單元 在硬體層面完成。
2.4 簡單總結
程式分段,如果按段放入記憶體,記憶體會出現無法利用的大量碎片,所以建立最小記憶體劃分單元--頁,按照頁響應段請求。頁的定址需要建立頁表,頁表與 PCB 關聯。
3. 多級頁表與快表
3.1 問題
上述思路,已經趨於完善,但是在實際系統中還是存在問題:
- 為了提高記憶體空間利用率,頁應當小,但是頁小的話數量增加,據此建立的頁表就會變大。
- 頁太多了的話,頁表太大 維護和查詢頁表的開銷就大了:
- 比如32位元程式(4G記憶體),如果頁大小為4K,則有1M / 220個頁。
- 這裡的1M僅是頁號,與之相應的頁表項還有 頁框號 和 保護位,每個頁表項4個位元組。頁表整體就佔用4M記憶體。
- 每個程序都需要同樣的頁表,如果有 100 個程序,則佔用 400M 記憶體。
3.2 嘗試1:去除無用表項
但實際上 每張頁表可能並不需要 4M 這麼大的記憶體。因為單個程序並不會把 4G 記憶體全用上,也就是說 1M 個頁表項並不會全部派上用場。
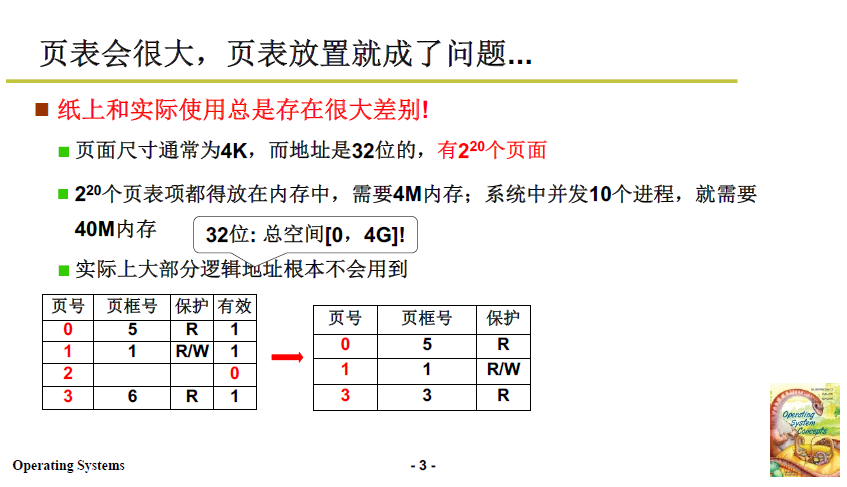
所以一種自然的想法就是:只對使用到的邏輯頁建立頁表項。
-
但隨之而來的就是頁號不連續,如下圖右上角。
-
此前上文中本來用硬體索引,只需要對號入座,很快查到對應的表項,現在不連續了,就不能這麼做了。
參見上面2.3.3 定址方式,我們先拿到的是2240這樣的地址,上文方法右移三位就可以拿到 2 這個頁號,這樣做的依據是,頁是連續的,我們可以根據頁的大小推算頁的號碼,而頁不連續,就不能說2240在第2頁,我們需要去查表匹配。
-
必須逐一比較、順序查詢 / 二分查詢。
-
而記憶體存取本身就很慢,每一次訪存都需要額外的查詢操作(也是訪存操作),會降低指令的訪存效率。
所以不連續的演演算法複雜度高於上文提到的連續存放( O(1) ),但是連續存放的頁表佔用記憶體太大,會產生浪費。
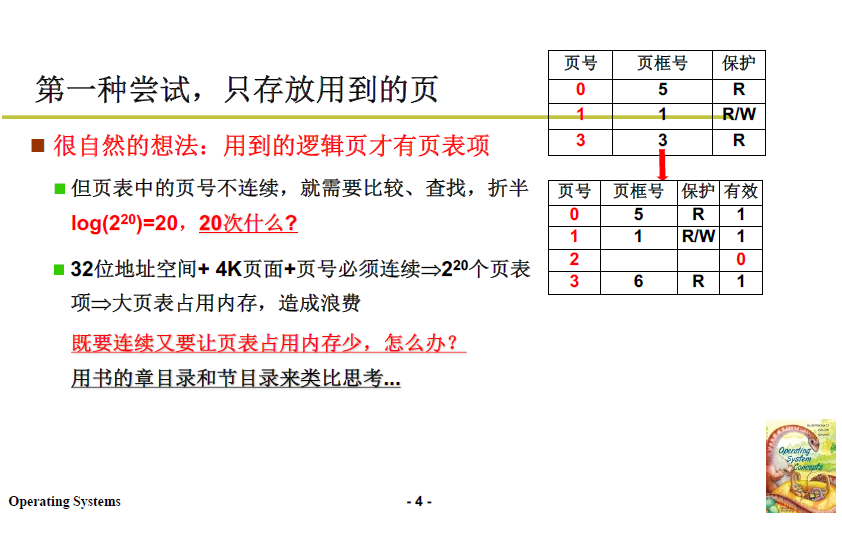
3.3 嘗試2:多級頁表
解決上述問題,可以參考生活中的書籍的章節目錄,我們要查詢第五章的第三節(在書中是第20節)就不必查詢前四章的目錄,直接跳到第五章的目錄下繼續向下查,大大節約了搜尋開銷。
在記憶體管理中,"不必查詢" 對應的就是 這些區域 在該程序中不被使用,既減少了無用表項,也保證了大章連續,單節之間也連續。這個嘗試是成功的。
具體細節如下圖:
-
頁目錄號 10 位(相當於章),頁號10位(相當於節),頁內偏移 12 位 / 4k。
-
查詢流程就是,找到對應章,在對應章下找對應節,對應節得到物理頁框號和偏移量,得到最終真實實體地址。
由於多級頁表的連續性,這其中的每一步查詢都是O(1),可以直接索引得到。
-
分析:
-
章有10位,也就是頁目錄號有210個表項,每個表項 4 位元組,正好是 4k / 一頁;
-
同理,節(頁號/二級頁)也有 210 個表項,每個表項 4 位元組,也是 4k / 一頁;
-
一個章/頂級頁目錄,管理 210個節/二級頁,每個節(表項)是4K,所以 一章 管理 4M 空間,下圖程式使用了 3 章就使用了 12M 記憶體。
-
注意:
-
下圖程式隨意的使用了記憶體中的三個部分,如果不採用多級頁表,則需要將4G空間整體打表才能使用,此時頁表的儲存需要4M,而其中有許多記憶體不需要打表(因為不會被用到,下圖空白處)。
-
而採用多級頁表的頁表項使用的空間是 210 個目錄項 × 4位元組地址 = 4K,總共需要16K遠小於4M.
章 / 頂級頁目錄中,共有 3 個表項是有效的,分別指向3個節 / 二級頁目錄,所以頂級頁目錄+3個二級頁目錄共16K.
-
-
頂級頁目錄的前兩個表項是在低地址空間,後一個表項是在高地址空間,對於這種不連續的邏輯地址的使用也是完美處理的;
也就是說,程式可以使用不連續的邏輯地址空間,但是多級頁表仍然是連續的,查詢的時間複雜度是O(1)的
-
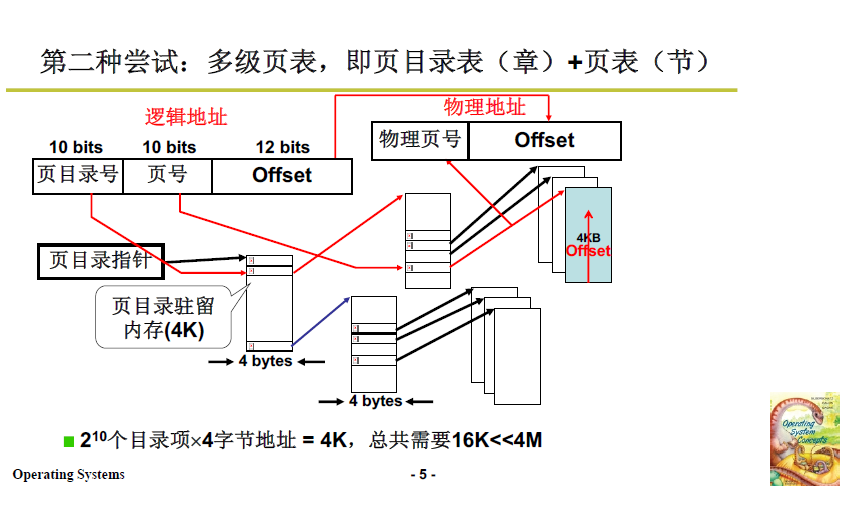
3.4 多級頁表的時空複雜度
多級頁表增加了訪存的次數。每多一級,記憶體空間的節省越多,但也會多存取一次記憶體。32位元系統或許不太明顯,64位元系統可能是五、六級的頁表,這時時間消耗就會很大,效率降低。
3.5 優化:快表
上述多級頁表降低了空間複雜度,但時間複雜度依舊不理想,這裡引入了 TLB,快表。
TLB 是一組相聯快速儲存(快表),是CPU內的暫存器;可以非常快的找到最近使用的邏輯頁對應的物理頁框號。
TLB: Translation Lookaside Buffer.直譯可以翻譯為旁路轉換緩衝,常稱之為快表。
這部分在計組的Cache有講過,這裡相當於是另一種角度來看這個問題。
工作過程:
-
TLB中存放從虛擬地址到實體地址的轉換表;項由兩部分組成:邏輯地址頁號+偏移
-
CPU 需要訪存時,優先在TLB中定址,並且通過硬體組相聯的設計,在硬體電路上進行比對,可以達到 近似 O(1) 的查詢效果。
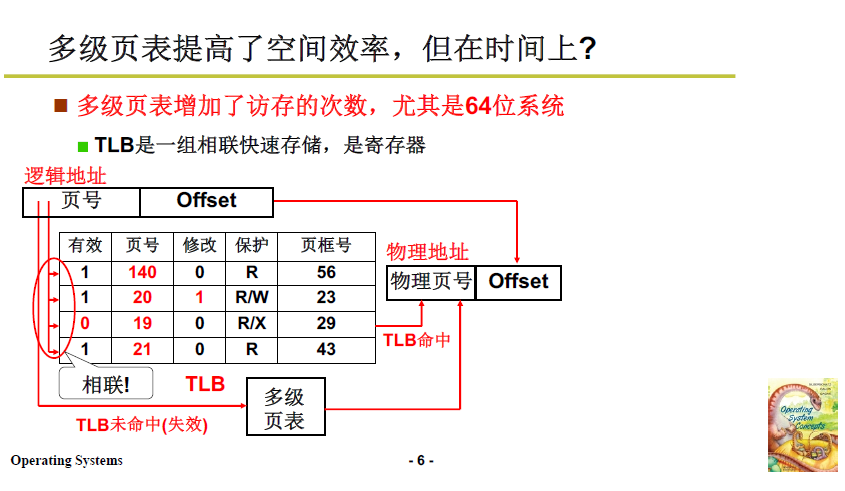
TLB能夠降低時間開銷的原因:
-
公式如下圖所示,想辦法增加TLB的命中率,就能使有效訪存時間降低至近似訪存1次;
簡單講就是減少了存取實體記憶體的次數。
-
下圖公式是 TLB + 單級頁表的計算公式。

頁的個數通常很多,而TLB可以容納的索引很少,TLB可以有效工作的原理是:
- 程式的地址存取存在區域性性,
- 空間區域性性:比如程式的迴圈、順序結構使得被存取地址周邊的地址也很快被存取;
- 時間區域性性:有一些變數和語句經常被存取;
- 把這些經常被使用的放入TLB,並採用合適的替換策略,就能夠保證TLB的命中率較高,降低訪存時間。
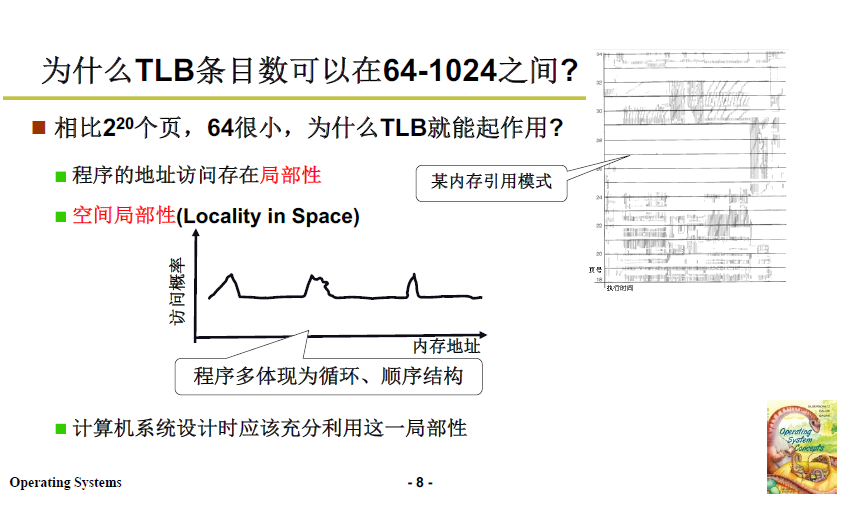
採用 TLB+多級頁表 的方法,首先在TLB中定址存,如果 TLB 未命中,則對多級頁表定址,這樣就降低了訪存的時空複雜度。
4. 段頁結合的記憶體管理
4.1 虛擬記憶體
在真實的作業系統中,通常採用段頁式儲存管理,段面向使用者,頁面向硬體記憶體。這一部分就講解一下第 1 部分的 段 和 第 2 部分的 頁 如何結合在一起。
簡單的想法是:
-
程式編譯為段,段被裝入記憶體分割區(這裡的記憶體並不是實體記憶體,因為前面論證過時空效率不高),依據段表定址;
分段:程式碼分段+記憶體分割區+段表,程式碼對映到程式設計師眼中的記憶體
-
而面向實體記憶體,劃分為頁,並根據頁表/多級頁表定址;
分頁:記憶體分頁 + 多級頁表
-
在前者和後者之間建立對映關係,即將程式設計師眼中的記憶體與實體記憶體建立對映,就完成了 段 和 頁 的結合。
-
這裡程式設計師眼中的記憶體 就是 虛擬記憶體。
4.2 段頁結合的構成機理
一個很好的參考資料:關於邏輯地址、線性地址、虛擬地址、實體地址的理解
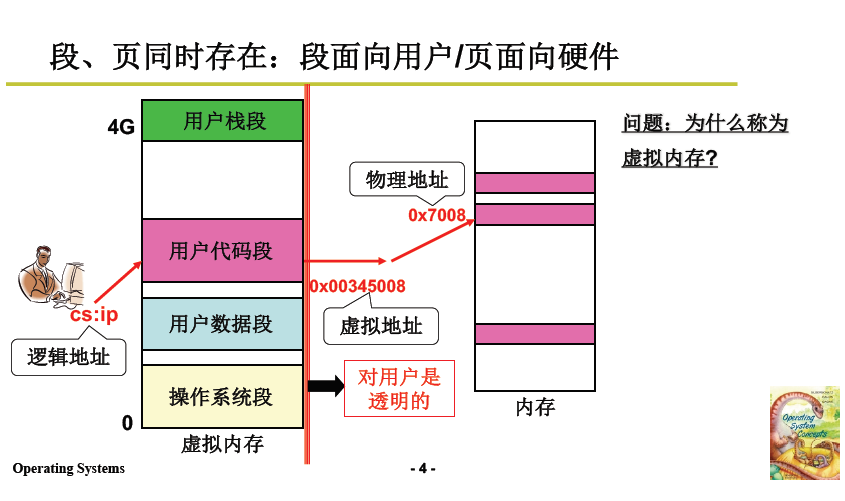
4.2.1 程式放入實體記憶體
首先是程式放入實體記憶體的過程。
- 如下圖所示,程式的程式碼段在虛擬記憶體上按照 2.2 記憶體分割區的方法,找到空閒區域並放入;
- 將虛擬記憶體上的地址對映到實體記憶體上。
- 舉例:將左側使用者程式碼段再次打碎放入記憶體頁中。
- 0x00345008 對映為 0x7008,再到實體記憶體取址;
- 這個對映對使用者不可見/透明,所以使用者眼中看到的就是下圖左側的虛擬記憶體。
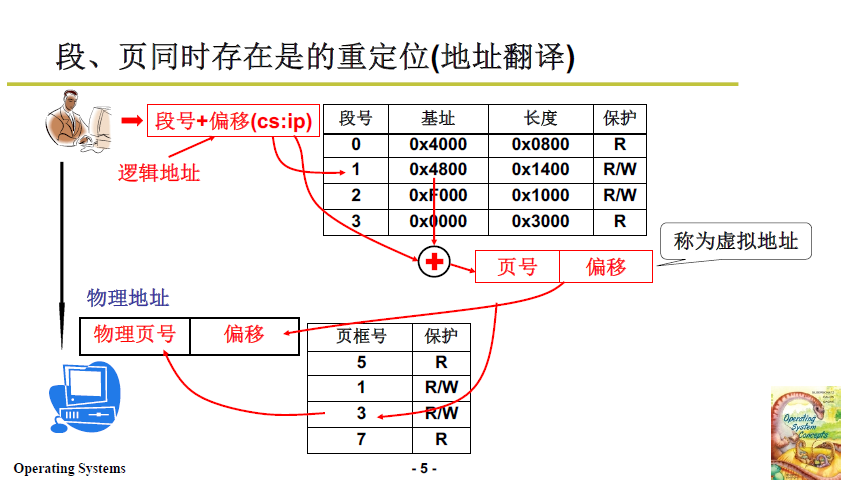
4.2.2 程式如何訪存執行
這時的訪存問題也就是 段頁同時存在時的重定位 / 地址翻譯。
- 首先要知道 程式段 在 虛擬記憶體 上的位置;
- 使用者發出的邏輯地址:段號 + 段內偏移
- 基址:如下圖在段表中,根據段號找到 基址 4800
- 虛擬地址:段內偏移+基址
- 虛擬地址向實體記憶體進行對映,考慮分頁機制,再計算真實實體地址;
- 作業系統把真實實體地址發到地址匯流排,訪存完成。
這樣,從使用者角度看,完全是段的概念,同一程式碼段是連續的。但從作業系統角度講,這個段是虛擬的,需要再對映到實體地址上。從實體記憶體角度講,虛擬記憶體的段被打散在不同頁上,並且使用了多級頁表,提高了時空效率。
幾個疑問的解答:
前文第2部分提到過,記憶體分割區會有越分越碎的問題,為什麼這裡還能用分割區的思路來劃分虛擬記憶體呢?
- 答:虛擬記憶體放在磁碟上,這樣使用者眼中就會有比實際大得多的記憶體空間。
引入虛擬記憶體的優越性,為什麼不直接對段分頁?
每個使用者程式碼都有多個段,如果直接給段分頁,程序的每一個段需要都維護一個頁表;
經過虛擬記憶體的中介,只需要給虛擬記憶體維護一個頁表;
優化碎片問題,進一步提高空間利用效率。
假設一個程式共有2047KB,分為兩個段,1個段是1025KB,一個段是1022KB;
如果經過虛擬記憶體的中介,只需要放到兩頁上;如果直接給段分頁,就要放到3頁上
從使用者角度看, 能夠使用所有的虛擬地址空間。 從實體記憶體上看, 使用者僅僅使用了一些記憶體頁。
4.3 一個段頁式記憶體管理範例
實驗6. 下面開始看程式碼啦。
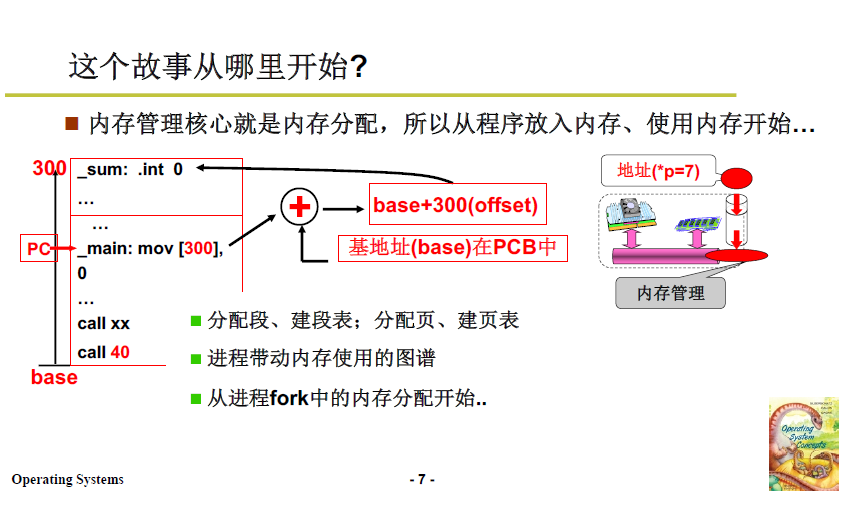
4.3.1 程式放入記憶體
- 為程式/程序分配記憶體:分配段、頁,建立段、頁表;程序可以帶動記憶體;
- 程序有了自己的記憶體,程式放入記憶體:從程序 fork 中的記憶體分配開始說。
-
段頁式記憶體下程式如何載入記憶體?
-
需要從虛擬記憶體中分出空閒區域,將程式段放入
-
對虛擬記憶體進行分割區,使用 2.2.3 中的分割區選擇演演算法,對程式的各個段進行適配,建立段表;
-
-------------------
-