Hive的基本知識與操作
Hive的基本知識與操作
Hive的基本概念
Hive本質是將SQL轉換為MapReduce的任務進行運算,底層由HDFS來提供資料儲存,說白了hive可以理解為一個將SQL轉換為MapReduce的任務的工具,甚至更近一步說hive就是一個MapReduce使用者端。
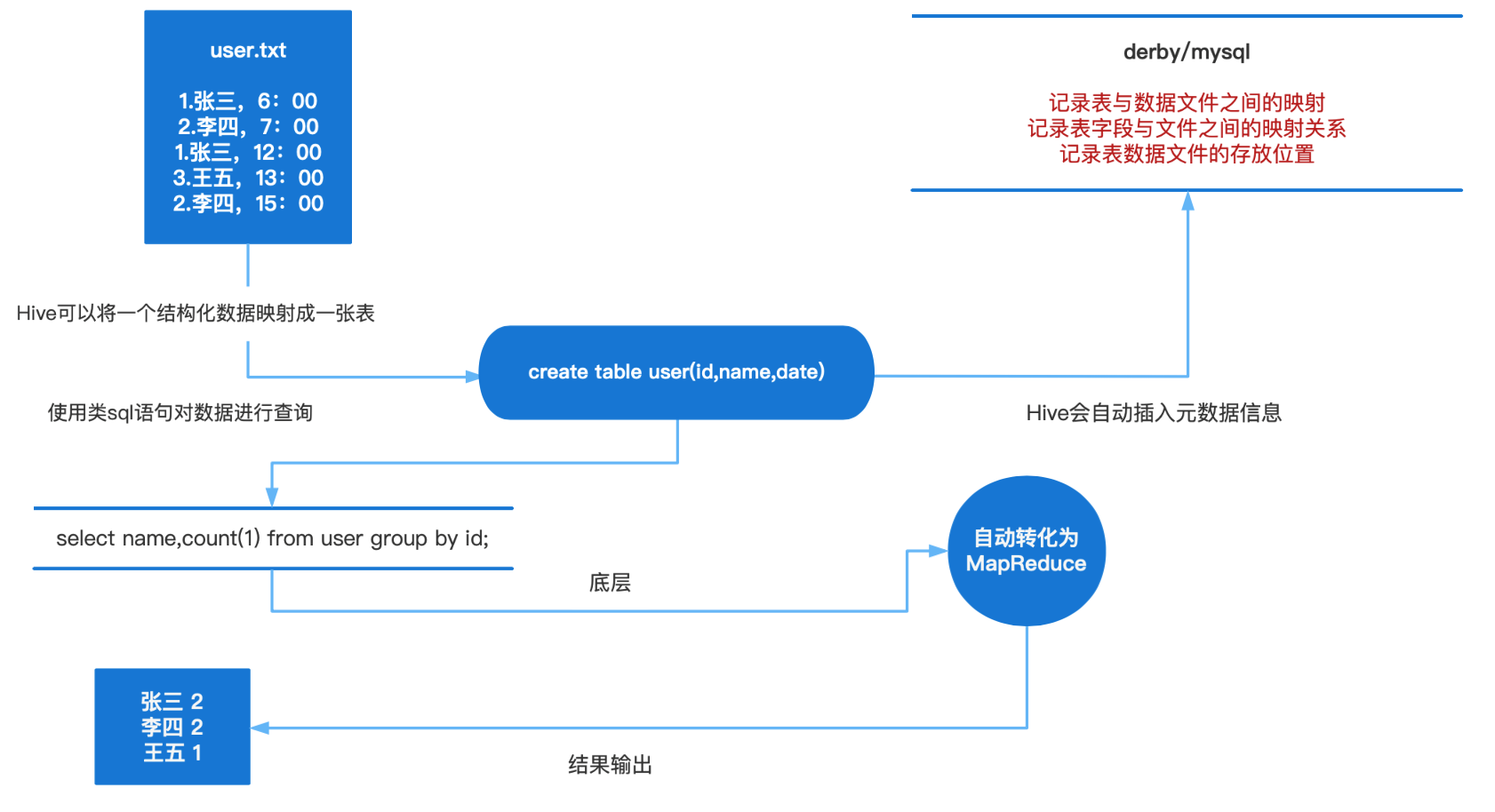
為什麼使用Hive?
如果直接使用hadoop的話,人員學習成本太高,專案要求週期太短,MapReduce實現複雜查詢邏輯開發難度太大。如果使用hive的話,可以操作介面採用類SQL語法,提高開發能力,免去了寫MapReduce,減少開發人員學習成本,功能擴充套件很方便(比如:開窗函數)。
Hive的特點:
1、可延伸性
Hive可以自由的擴充套件叢集的規模,一般情況下不需要重啟服務
2、延申性
Hive支援自定義函數,使用者可以根據自己的需求來實現自己的函數
3、容錯
即使節點出現錯誤,SQL仍然可以完成執行
Hive的優缺點:
優點:
1、操作介面採用類sql語法,提供快速開發的能力(簡單、容易上手)
2、避免了去寫MapReduce,減少開發人員的學習成本
3、Hive的延遲性比較高,因此Hive常用於資料分析,適用於對實時性要求不高的場合
4、Hive 優勢在於處理巨量資料,對於處理小資料沒有優勢,因為 Hive 的執行延遲比較高。(不斷地開關JVM虛擬機器器)
5、Hive 支援使用者自定義函數,使用者可以根據自己的需求來實現自己的函數。
6、叢集可自由擴充套件並且具有良好的容錯性,節點出現問題SQL仍可以完成執行
缺點:
1、Hive的HQL表達能力有限
(1)迭代式演演算法無法表達 (反覆呼叫,mr之間獨立,只有一個map一個reduce,反覆開關)
(2)資料探勘方面不擅長
2、Hive 的效率比較低
(1)Hive 自動生成的 MapReduce 作業,通常情況下不夠智慧化
(2)Hive 調優比較困難,粒度較粗 (hql根據模板轉成mapreduce,不能像自己編寫mapreduce一樣精細,無法控制在map處理資料還是在reduce處理資料)
Hive應用場景
紀錄檔分析:大部分網際網路公司使用hive進行紀錄檔分析,如百度、淘寶等。
統計一個網站一個時間段內的PV(頁面瀏覽量)UV(統計一天內某站點的使用者數)SKU ,SPU
Hive架構
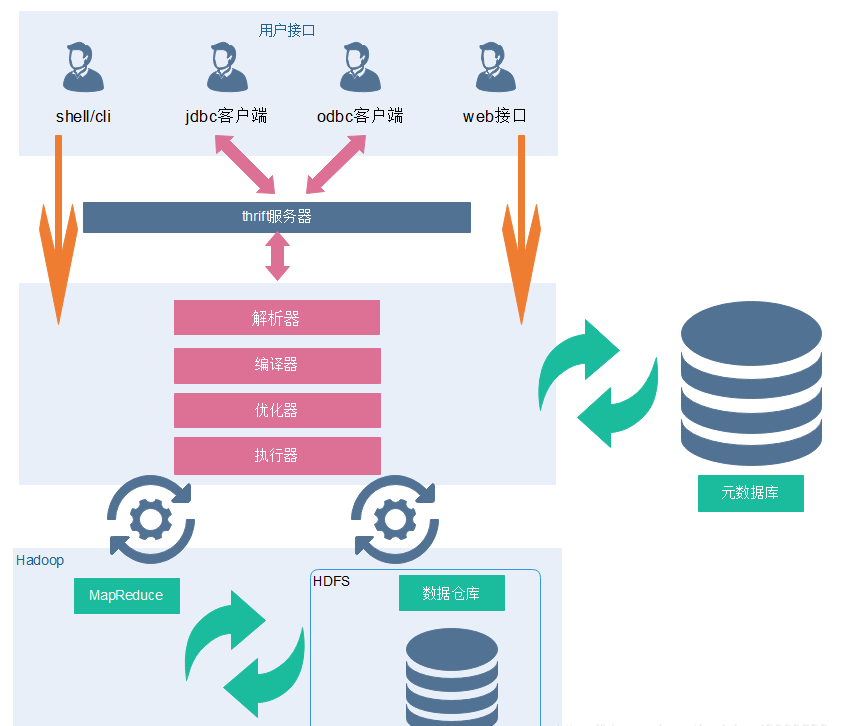
Client
Hive允許client連線的方式有三個CLI(hive shell)、JDBC/ODBC(java存取hive)、WEBUI(瀏覽器存取 hive)。JDBC存取時中介軟體Thrift軟體框架,跨語言服務開發。DDL DQL DML,整體仿寫一套SQL語句。
1)client–需要下載安裝包
2)JDBC/ODBC 也可以連線到Hive
現在主流都在倡導第二種 HiveServer2/beeline
做基於使用者名稱和密碼安全的一個校驗
3)Web Gui
hive給我們提供了一套簡單的web頁面
我們可以通過這套web頁面存取hive 做的太簡陋了
Metastore(後設資料)
後設資料包括表名、表所屬的資料庫(預設是default)、表的擁有者、列/分割區欄位、表的型別(是否是 外部表)、表的資料所在目錄等。
一般需要藉助於其他的資料載體(資料庫)
主要用於存放資料庫的建表語句等資訊
推薦使用Mysql資料庫存放資料
連線資料庫需要提供:uri username password driver
sql語句是如何轉化成MR任務的?
後設資料儲存在資料庫中,預設存在自帶的derby資料庫(單使用者侷限性)中,推薦使用Mysql進行儲存。
1) 解析器(SQL Parser):將SQL字串轉換成抽象語法樹AST,這一步一般都用第三方工具庫完 成,比如ANTLR;對AST進行語法分析,比如表是否存在、欄位是否存在、SQL語意是否有誤。
2) 編譯器(Physical Plan):將AST編譯生成邏輯執行計劃。
3) 優化器(Query Optimizer):對邏輯執行計劃進行優化。
4) 執行器(Execution):把邏輯執行計劃轉換成可以執行的物理計劃。對於Hive來說,就是 MR/Spark。
資料處理
Hive的資料儲存在HDFS中,計算由MapReduce完成。HDFS和MapReduce是原始碼級別上的整合,兩者結合最佳。直譯器、編譯器、優化器完成HQL查詢語句從詞法分析、語法分析、編譯、優化以及查詢計劃的生成。
Hive的三種互動方式
第一種互動方式
shell互動Hive,用命令hive啟動一個hive的shell命令列,在命令列中輸入sql或者命令來和Hive互動。
伺服器端啟動metastore服務(後臺啟動):nohup hive --service metastore >/dev/null &
進入命令:hive
退出命令列:quit;
第二種互動方式
Hive啟動為一個伺服器,對外提供服務,其他機器可以通過使用者端通過協定連線到伺服器,來完成存取操作,這是生產環境用法最多的
伺服器端啟動hiveserver2服務:
nohup hive --service metastore >/dev/null &
nohup hiveserver2 >/dev/null &
需要稍等一下,啟動服務需要時間:
進入命令:1)先執行: beeline ,再執行: !connect jdbc:hive2://master:10000
2)或者直接執行: beeline -u jdbc:hive2://master:10000 -n root
退出命令列:!exit
第三種互動方式
使用 –e 引數來直接執行hql的語句
bin/hive -e "show databases;"
使用 –f 引數通過指定文字檔案來執行hql的語句
特點:執行完sql後,回到linux命令列。
建立一個sql檔案:vim hive.sql
裡面寫入要執行的sql命令
use myhive;
select * from test;
hive -f hive.sql
Hive後設資料
Hive後設資料庫中一些重要的表結構及用途,方便Impala、SparkSQL、Hive等元件存取後設資料庫的理解。
1、儲存Hive版本的後設資料表(VERSION),該表比較簡單,但很重要,如果這個表出現問題,根本進不來Hive-Cli。比如該表不存在,當啟動Hive-Cli的時候,就會報錯「Table 'hive.version' doesn't exist」
2、Hive資料庫相關的後設資料表(DBS、DATABASE_PARAMS)
DBS:該表儲存Hive中所有資料庫的基本資訊。
DATABASE_PARAMS:該表儲存資料庫的相關引數。
3、Hive表和檢視相關的後設資料表
主要有TBLS、TABLE_PARAMS、TBL_PRIVS,這三張表通過TBL_ID關聯。
TBLS:該表中儲存Hive表,檢視,索引表的基本資訊。
TABLE_PARAMS:該表儲存表/檢視的屬性資訊。
TBL_PRIVS:該表儲存表/檢視的授權資訊。
4、Hive檔案儲存資訊相關的後設資料表
主要涉及SDS、SD_PARAMS、SERDES、SERDE_PARAMS,由於HDFS支援的檔案格式很多,而建Hive表時候也可以指定各種檔案格式,Hive在將HQL解析成MapReduce時候,需要知道去哪裡,使用哪種格式去讀寫HDFS檔案,而這些資訊就儲存在這幾張表中。
SDS:該表儲存檔案儲存的基本資訊,如INPUT_FORMAT、OUTPUT_FORMAT、是否壓縮等。TBLS表中的SD_ID與該表關聯,可以獲取Hive表的儲存資訊。
SD_PARAMS: 該表儲存Hive儲存的屬性資訊。
SERDES:該表儲存序列化使用的類資訊。
SERDE_PARAMS:該表儲存序列化的一些屬性、格式資訊,比如:行、列分隔符。
5、Hive表欄位相關的後設資料表
主要涉及COLUMNS_V2:該表儲存表對應的欄位資訊。
Hive的基本操作
建立資料庫
資料庫在hdfs上的預設路徑是/hive/warehouse/*.db
create database testdb;
避免要建立的資料庫已經存在錯誤,增加if not exists判斷。(標準寫法)
create database if not exists testdb;
建立資料庫並指定位置
create database if not exists testdb location '/testdb.db';
修改資料庫
資料庫的其他後設資料資訊都是不可更改的,包括資料庫名和資料庫所在的目錄位置。
alter database dept set dbproperties('createtime'='20220531');為資料庫的DBPROPERTIES設定鍵值對屬性值
檢視資料庫詳細資訊
顯示資料庫
show databases;
通過like過濾顯示資料庫
show datebases like '*t*';(這裡是*,sql裡是%)
檢視資料庫詳情
desc database testdb;
切換資料庫
use testdb;
刪除資料庫
最簡寫法
drop database testdb;
如果刪除的資料庫不存在,最好使用if exists判斷資料庫是否存在。否則會報錯:FAILED: SemanticException [Error 10072]: Database does not exist: db_hive
drop database if exists testdb;
如果資料庫不為空,使用cascade命令進行強制刪除。報錯資訊如下FAILED: Execution Error, return code 1 from org.apache.hadoop.hive.ql.exec.DDLTask. InvalidOperationException(message:Database db_hive is not empty. One or more tables exist.)
drop database if exists testdb cascade;
Hive的資料型別
基礎資料型別
| 型別 | Java資料型別 | 描述 |
|---|---|---|
| TINYINT | byte | 8位元有符號整型。取值範圍:-128~127。 |
| SMALLINT | short | 16位元有符號整型。取值範圍:-32768~32767。 |
| INT | int | 32位元有符號整型。取值範圍:-2 31 ~2 31 -1。 |
| BIGINT | long | 64位元有符號整型。取值範圍:-2 63 +1~2 63 -1。 |
| BINARY | 二進位制資料型別,目前長度限制為8MB。 | |
| FLOAT | float | 32位元二進位制浮點型。 |
| DOUBLE | double | 64位元二進位制浮點型。 |
| DECIMAL(precision,scale) | 10進位制精確數位型別。precision:表示最多可以表示多少位的數位。取值範圍:1 <= precision <= 38。scale:表示小數部分的位數。取值範圍: 0 <= scale <= 38。如果不指定以上兩個引數,則預設為decimal(10,0)。 | |
| VARCHAR(n) | 變長字元型別,n為長度。取值範圍:1~65535。 | |
| CHAR(n) | 固定長度字元型別,n為長度。最大取值255。長度不足則會填充空格,但空格不參與比較。 | |
| STRING | string | 字串型別,目前長度限制為8MB。 |
| DATE | 日期型別,格式為yyyy-mm-dd。取值範圍:0000-01-01~9999-12-31。 |
|
| DATETIME | 日期時間型別。取值範圍:0000-01-01 00:00:00.000~9999-12-31 23.59:59.999,精確到毫秒。 | |
| TIMESTAMP | 與時區無關的時間戳型別。取值範圍:0000-01-01 00:00:00.000000000~9999-12-31 23.59:59.999999999,精確到納秒。說明 對於部分時區相關的函數,例如cast( as string),要求TIMESTAMP按照與當前時區相符的方式來展現。 | |
| BOOLEAN | boolean | BOOLEAN型別。取值:True、False。 |
複雜的資料型別
| 型別 | 定義方法 | 構造方法 |
|---|---|---|
| ARRAY | array<int>``array<struct<a:int, b:string>> |
array(1, 2, 3)``array(array(1, 2), array(3, 4)) |
| MAP | map<string, string>``map<smallint, array<string>> |
map(「k1」, 「v1」, 「k2」, 「v2」)``map(1S, array(‘a’, ‘b’), 2S, array(‘x’, ‘y’)) |
| STRUCT | struct<x:int, y:int>struct<field1:bigint, field2:array<int>, field3:map<int, int>> named_struct(‘x’, 1, ‘y’, 2)named_struct(‘field1’, 100L, ‘field2’, array(1, 2), ‘field3’, map(1, 100, 2, 200)) |
Hive有三種複雜資料型別ARRAY、MAP 和 STRUCT。ARRAY和MAP與Java中的Array和Map類似,而STRUCT與C語言中的Struct類似,它封裝了一個命名欄位集合,複雜資料型別允許任意層次的巢狀。還有一個uniontype< 所有型別,所有型別… > 。
陣列:array< 所有型別 >;
Map < 基本資料型別,所有資料型別 >;
struct < 名:所有型別[註釋] >;
uniontype< 所有型別,所有型別… >
Hive的檔案格式
Hive沒有專門的資料檔案格式,常見的有以下幾種:
TEXTFILE:Hive預設檔案儲存格式
SEQUENCEFILE
AVRO
RCFILE:列檔案格式,能夠很好的壓縮和快速查詢效能
ORCFILE:很高的壓縮比,能很大程度的節省儲存和計算資源,但它在讀寫時候需要消耗額外的CPU資源來壓縮和解壓縮
PARQUET
Hive的表操作
建立表
CREATE [EXTERNAL] TABLE [IF NOT EXISTS] table_name
[(col_name data_type [COMMENT col_comment], ...)]
[COMMENT table_comment]
[PARTITIONED BY (col_name data_type [COMMENT col_comment], ...)]
[CLUSTERED BY (col_name, col_name, ...)
[SORTED BY (col_name [ASC|DESC], ...)] INTO num_buckets BUCKETS]
[ROW FORMAT row_format]
[STORED AS file_format]
[LOCATION hdfs_path]
欄位解釋說明:
- CREATE TABLE
建立一個指定名字的表。如果相同名字的表已經存在,則丟擲異常;使用者可以用 IF NOT EXISTS 選項來忽略這個異常。
- EXTERNAL
關鍵字可以讓使用者建立一個外部表,在建表的同時指定一個指向實際資料的路徑(LOCATION)
建立內部表時,會將資料移動到資料倉儲指向的路徑(預設位置);
建立外部表時,僅記錄資料所在的路徑,不對資料的位置做任何改變。在
刪除表的時候,內部表的後設資料和資料會被一起刪除,而外部表只刪除後設資料,不刪除資料。
- COMMENT:
為表和列新增註釋。
- PARTITIONED BY
建立分割區表
- CLUSTERED BY
建立分桶表
- SORTED BY
不常用
- ROW FORMAT
DELIMITED [FIELDS TERMINATED BY char] [COLLECTION ITEMS TERMINATED BY char] [MAP KEYS TERMINATED BY char] [LINES TERMINATED BY char] | SERDE serde_name [WITH SERDEPROPERTIES (property_name=property_value, property_name=property_value, ...)]
使用者在建表的時候可以自定義SerDe或者使用自帶的SerDe。
如果沒有指定ROW FORMAT 或者ROW FORMAT DELIMITED,將會使用自帶的SerDe。
在建表的時候,使用者還需要為表指定列,使用者在指定表的列的同時也會指定自定義的SerDe,Hive通過SerDe確定表的具體的列的資料。
SerDe是Serialize/Deserilize的簡稱,目的是用於序列化和反序列化。
- STORED AS指定儲存檔案型別
常用的儲存檔案型別:SEQUENCEFILE(二進位制序列檔案)、TEXTFILE(文字)、RCFILE(列式儲存格式檔案)
如果檔案資料是純文字,可以使用STORED AS TEXTFILE。
如果資料需要壓縮,使用 STORED AS SEQUENCEFILE。
- LOCATION :
指定表在HDFS上的儲存位置。
- LIKE
允許使用者複製現有的表結構,但是不復制資料。
預設建表方式
create table students
(
id bigint,
name string,
age int,
gender string,
clazz string
)
ROW FORMAT DELIMITED FIELDS TERMINATED BY ','; // 必選,指定列分隔符
指定location
create table students2
(
id bigint,
name string,
age int,
gender string,
clazz string
)
ROW FORMAT DELIMITED FIELDS TERMINATED BY ','
LOCATION '/input1'; // 指定Hive表的資料的儲存位置,一般在資料已經上傳到HDFS,想要直接使用,會指定Location,通常Locaion會跟外部表一起使用,內部表一般使用預設的location
指定儲存格式
create table students3
(
id bigint,
name string,
age int,
gender string,
clazz string
)
ROW FORMAT DELIMITED FIELDS TERMINATED BY ','
STORED AS rcfile; // 指定儲存格式為rcfile
如果不指定,預設為textfile,注意:除textfile以外,其他的儲存格式的資料都不能直接載入,需要使用從表載入的方式。
建立表並載入另一張表的所有資訊
create table students4 as select * from students2;
只建表,不需要載入資料,相當於建表語句一樣
create table students5 like students;
複雜人員資訊表建立
create table IF NOT EXISTS t_person(
name string,
friends array<string>,
children map<string,int>,
address struct<street:string ,city:string>
)
row format delimited fields terminated by ','
collection items terminated by '_'
map keys terminated by ':'
lines terminated by '\n';
songsong,bingbing_lili,xiao song:18_xiaoxiao song:19,beng bu_anhui
yangyang,caicai_susu,xiao yang:18_xiaoxiao yang:19,he fei_anhui
顯示錶
show tables;
show tables like 'u';
desc t_person;
desc formatted t_person;
載入資料
1、使用 Hadoop fs -put '本地資料地址' 'hive表對應的HDFS目錄下'
load data inpath '/input1/students.txt' into table students;
將HDFS上的/input1目錄下面的資料 移動至 students表對應的HDFS目錄下,注意是 移動、移動、移動
2、將Linux本地目錄下的檔案 上傳到 hive表對應HDFS 目錄下 原檔案不會被刪除
load data local inpath '/usr/local/soft/data/students.txt' into table students;
3、覆蓋載入overwrite
load data local inpath '/usr/local/soft/data/students.txt' overwrite into table students;
清空表
truncate table students;
插入表資料insert into table xxxx SQL語句 (沒有as)
將 students表的資料插入到students2 這是複製 不是移動 students表中的表中的資料不會丟失
insert into table students2 select * from students;
覆蓋插入
覆蓋插入 把into 換成 overwrite
insert overwrite table students2 select * from students;
修改列
查詢表結構
desc students2;
新增列
alter table students2 add columns (education string);
查詢表結構
desc students2;
更新列
alter table stduents2 change education educationnew string;
刪除表
drop table students2;
Hive內部表
建立好表的時候,HDFS會在當前表所屬的庫中建立一個資料夾
當load資料的時候,就會將資料檔案存放到表對應的資料夾中
資料一旦被load,就不能被修改
刪除表的時候,表對應的資料夾會被刪除,同時資料也會被刪除
預設建表的型別就是內部表
Hive外部表
外部表因為是指定其他的hdfs路徑的資料載入到表中來,所以hive會認為自己不完全獨佔這份資料
刪除hive表的時候,資料仍然儲存在hdfs中,不會刪除。
外部表關鍵字external
一般在公司中,使用外部表多一點,因為資料可以需要被多個程式使用,避免誤刪,通常外部表會結合location一起使用
外部表還可以將其他資料來源中的資料 對映到 hive中,比如說:hbase,ElasticSearch......
設計外部表的初衷就是 讓 表的後設資料 與 資料 解耦
Hive匯出資料
將表中的資料備份
- 將查詢結果存放到本地
//建立存放資料的目錄
mkdir -p /usr/local/soft/shujia
//匯出查詢結果的資料(匯出到Node01上)
insert overwrite local directory '/usr/local/soft/shujia/person_data' select * from t_person;
- 按照指定的方式將資料輸出到本地
-- 建立存放資料的目錄
mkdir -p /usr/local/soft/shujia
-- 匯出查詢結果的資料
insert overwrite local directory '/usr/local/soft/shujia/person'
ROW FORMAT DELIMITED fields terminated by ','
collection items terminated by '-'
map keys terminated by ':'
lines terminated by '\n'
select * from t_person;
- 將查詢結果輸出到HDFS
-- 建立存放資料的目錄
hdfs dfs -mkdir -p /shujia/bigdata17/copy
-- 匯出查詢結果的資料
insert overwrite local directory '/usr/local/soft/shujia/students_data2' ROW FORMAT DELIMITED FIELDS TERMINATED BY ',' select * from students
- 直接使用HDFS命令儲存表對應的資料夾
// 建立存放資料的目錄
hdfs dfs -mkdir -p /shujia/bigdata17/person
// 使用HDFS命令拷貝檔案到其他目錄
hdfs dfs -cp /hive/warehouse/t_person/* /shujia/bigdata17/person
-
將表結構和資料同時備份
將資料匯出到HDFS
//建立存放資料的目錄 hdfs dfs -mkdir -p /shujia/bigdata17/copy //匯出查詢結果的資料 export table t_person to '/shujia/bigdata17/copy'; 刪除表結構
drop table t_person; 恢復表結構和資料
import from '/shujia/bigdata17';注意:時間不同步,會導致匯入匯出失敗