範例詳解MySQL索引最左匹配原則

推薦學習:
準備
為了方面後續的說明,我們首先建立一個如下的表(MySQL5.7),表中共有5個欄位(a、b、c、d、e),其中a為主鍵,有一個由b,c,d組成的聯合索引,儲存引擎為InnoDB,插入三條測試資料。強烈建議自己在MySQL中嘗試本文的所有語句。
CREATE TABLE `test` ( `a` int NOT NULL AUTO_INCREMENT, `b` int DEFAULT NULL, `c` int DEFAULT NULL, `d` int DEFAULT NULL, `e` int DEFAULT NULL, PRIMARY KEY(`a`), KEY `idx_abc` (`b`,`c`,`d`) ) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_0900_ai_ci; INSERT INTO test(`a`, `b`, `c`, `d`, `e`) VALUES (1, 2, 3, 4, 5); INSERT INTO test(`a`, `b`, `c`, `d`, `e`) VALUES (2, 2, 3, 4, 5); INSERT INTO test(`a`, `b`, `c`, `d`, `e`) VALUES (3, 2, 3, 4, 5);
這時候,我們如果執行下面這個SQL語句,你覺得會走索引嗎?
SELECT b, c, d FROM test WHERE d = 2;
如果你按照最左匹配原則(簡述為在聯合索引中,從最左邊的欄位開始匹配,若條件中欄位在聯合索引中符合從左到右的順序則走索引,否則不走,可以簡單理解為(a, b, c)的聯合索引相當於建立了a索引、(a, b)索引和(a, b, c)索引),這句顯然是不符合這個規則的,它走不了索引,但是我們用EXPLAIN語句分析,會發現一個很有趣的現象,它的輸出如下是使用了索引的。

這就很奇怪了,最左匹配原則失效了嗎?事實上,並沒有,我們一步步來分析。
理論詳解
由於現在基本上以InnoDB引擎為主,我們以InnoDB為例進行主要說明。
聚集索引和非聚集索引
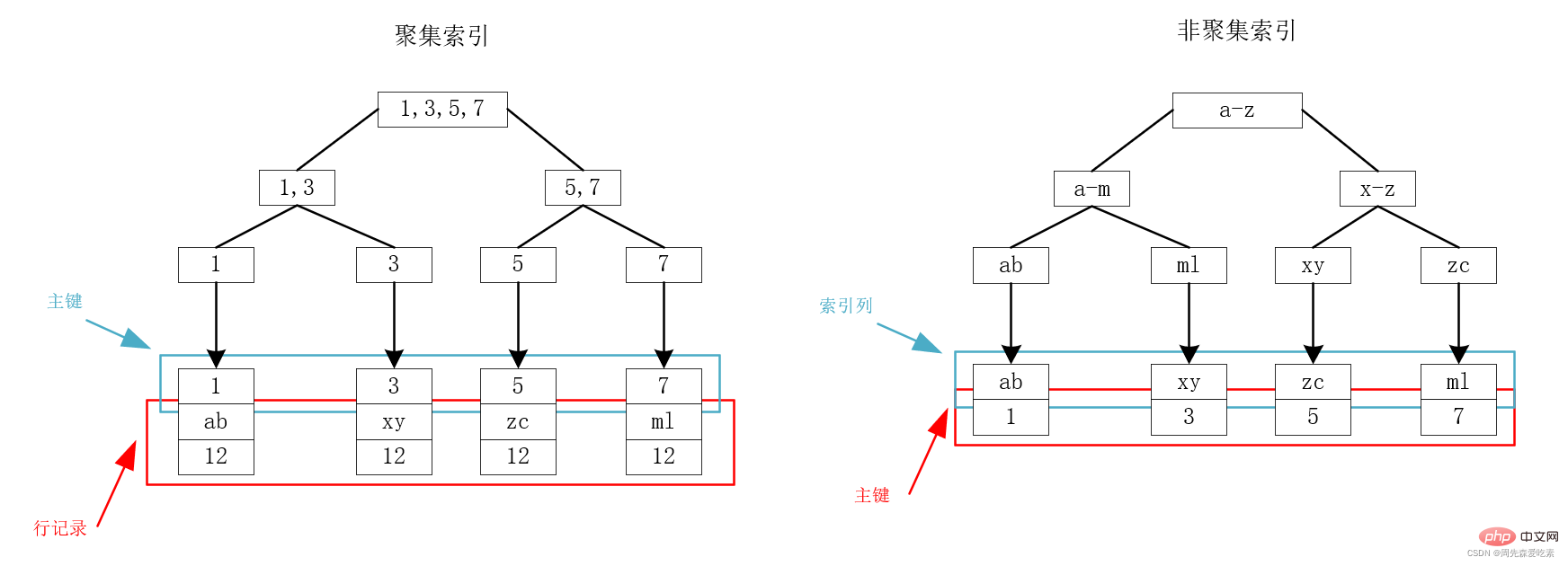
MySQL底層使用B+樹來儲存索引,資料均存在葉子節點上。對於InnoDB而言,主鍵索引和行記錄時儲存在一起的,因此叫做聚集索引(clustered index)。除了聚集索引,其他所有都叫做非聚集索引(secondary index),包括普通索引、唯一索引等。
在InnoDB中,只存在一個聚集索引:
- 若表存在主鍵,則主鍵索引就是聚集索引;
- 若表不存在主鍵,則會把第一個非空的唯一索引作為聚集索引;
- 否則,會隱式定義一個rowid作為聚集索引。
我們以下圖為例,假設現在有一個表,存在id、name、age三個欄位,其中id為主鍵,因此id為聚集索引,name建立索引為非聚集索引。關於id和name的索引,有如下的B+樹,可以看到,聚集索引的葉子節點儲存的是主鍵和行記錄,非聚集索引的葉子節點儲存的是主鍵。
回表查詢
從上面的索引儲存結構來看,我們可以看到,在主鍵索引樹上,通過主鍵就可以一次性查出我們所需要的資料,速度很快。這很直觀,因為主鍵就和行記錄儲存在一起,定位到了主鍵就定位到了所要找的包含所有欄位的記錄。
但是對於非聚集索引,如上面的右圖,我們可以看到,需要先根據name所在的索引樹找到對應主鍵,然後通過主鍵索引樹查詢到所要的記錄,這個過程叫做回表查詢。
索引覆蓋
上面的回表查詢無疑會降低查詢的效率,那麼有沒有辦法讓它不回表呢?這就是索引覆蓋。所謂索引覆蓋,就是說,在使用這個索引查詢時,使它的索引樹的葉子節點上的資料可以覆蓋你查詢的所有欄位,就可以避免回表了。我們回到一開始的例子,我們建立的(b,c,d)的聯合索引,因此當我們查詢的欄位在b、c、d中的時候,就不會回表,只需要檢視一次索引樹,這就是索引覆蓋。
最左匹配原則
指的是聯合索引中,優先走最左邊列的索引。對於多個欄位的聯合索引,也同理。如 index(a,b,c) 聯合索引,則相當於建立了 a 單列索引,(a,b)聯合索引,和(a,b,c)聯合索引。
我們可以執行下面的幾條語句驗證一下這個原則。
EXPLAIN SELECT * FROM test WHERE b = 1;

EXPLAIN SELECT * FROM test WHERE b = 1 and c = 2;

EXPLAIN SELECT * FROM test WHERE b = 1 and c = 2 and d = 3;

接著,我們嘗試一條不符合最左原則的查詢,它也如圖預期一樣,走了全表掃描。
EXPLAIN SELECT * FROM test WHERE d = 3;

詳細規則
我們先來看下面兩個語句,他們的輸出如下。
EXPLAIN SELECT b, c from test WHERE b = 1 and c = 1; EXPLAIN SELECT b, d from test WHERE d = 1;
id|select_type|table|partitions|type|possible_keys|key |key_len|ref |rows|filtered|Extra | --+-----------+-----+----------+----+-------------+-------+-------+-----------+----+--------+-----------+ 1|SIMPLE |test | |ref |idx_bcd |idx_bcd|10 |const,const| 1| 100.0|Using index| i d|select_type|table|partitions|type |possible_keys|key |key_len|ref|rows|filtered|Extra | --+-----------+-----+----------+-----+-------------+-------+-------+---+----+--------+------------------------+ 1|SIMPLE |test | |index|idx_bcd |idx_bcd|15 | | 3| 33.33|Using where; Using index|
顯然第一條語句是符合最左匹配的,因此type為ref,但是第二條並不符合最左匹配,但是也不是全表掃描,這是因為此時這表示掃描整個索引樹。
具體來看,index 代表的是會對整個索引樹進行掃描,如例子中的,列 d,就會導致掃描整個索引樹。ref 代表 mysql 會根據特定的演演算法查詢索引,這樣的效率比 index 全掃描要高一些。但是,它對索引結構有一定的要求,索引欄位必須是有序的。而聯合索引就符合這樣的要求,聯合索引內部就是有序的,你可以理解為order by b,c,d這種排序規則,先根據欄位b排序,再根據欄位c排序,以此類推。這也解釋了,為什麼需要遵守最左匹配原則,當最左列有序才能保證右邊的索引列有序。
因此,我們總結最後的原則為,若符合最左覆蓋原則,則走ref這種索引;若不符合最左匹配原則,但是符合覆蓋索引(index),就可以掃描整個索引樹,從而找到覆蓋索引對應的列,避免回表;若不符合最左匹配原則,也不符合覆蓋索引(如本例的select *),則需要掃描整個索引樹,並且回表查詢行記錄,此時,查詢優化器認為這樣兩次查詢索引樹,還不如全表掃描來得快(因為聯合索引此時不符合最左匹配原則,要不普通索引查詢慢得多),因此,此時會走全表掃描。
補充:為什麼要使用聯合索引
減少開銷。建一個聯合索引(col1,col2,col3),實際相當於建了(col1),(col1,col2),(col1,col2,col3)三個索引。每多一個索引,都會增加寫操作的開銷和磁碟空間的開銷。對於大量資料的表,使用聯合索引會大大的減少開銷!
覆蓋索引。對聯合索引(col1,col2,col3),如果有如下的sql: select col1,col2,col3 from test where col1=1 and col2=2。那麼MySQL可以直接通過遍歷索引取得資料,而無需回表,這減少了很多的隨機io操作。減少io操作,特別的隨機io其實是dba主要的優化策略。所以,在真正的實際應用中,覆蓋索引是主要的提升效能的優化手段之一。
效率高。索引列越多,通過索引篩選出的資料越少。有1000W條資料的表,有如下sql:select from table where col1=1 and col2=2 and col3=3,假設假設每個條件可以篩選出10%的資料,如果只有單值索引,那麼通過該索引能篩選出1000W10%=100w條資料,然後再回表從100w條資料中找到符合col2=2 and col3= 3的資料,然後再排序,再分頁;如果是聯合索引,通過索引篩選出1000w10% 10% *10%=1w,效率提升可想而知!
推薦學習:
前端(vue)入門到精通課程:
以上就是範例詳解MySQL索引最左匹配原則的詳細內容,更多請關注TW511.COM其它相關文章!
