伺服器端掛了,使用者端的 TCP 連線還在嗎?
作者:小林coding
計算機八股文網站:https://xiaolincoding.com
大家好,我是小林。
如果「伺服器端掛掉」指的是「伺服器端程序崩潰」,伺服器端的程序在發生崩潰的時候,核心會傳送 FIN 報文,與使用者端進行四次揮手。
但是,如果「伺服器端掛掉」指的是「伺服器端主機宕機」,那麼是不會發生四次揮手的,具體後續會發生什麼?還要看使用者端會不會傳送資料?
- 如果使用者端會傳送資料,由於伺服器端已經不存在,使用者端的資料包文會超時重傳,當重傳次數達到一定閾值後,會斷開 TCP 連線;
- 如果使用者端一直不會傳送資料,再看使用者端有沒有開啟 TCP keepalive 機制?
- 如果有開啟,使用者端在一段時間後,檢測到伺服器端的 TCP 連線已經不存在,則會斷開自身的 TCP 連線;
- 如果沒有開啟,使用者端的 TCP 連線會一直存在,並不會斷開。
上面屬於精簡回答了,下面我們詳細聊聊。
伺服器端程序崩潰,使用者端會發生什麼?
TCP 的連線資訊是由核心維護的,所以當伺服器端的程序崩潰後,核心需要回收該程序的所有 TCP 連線資源,於是核心會傳送第一次揮手 FIN 報文,後續的揮手過程也都是在核心完成,並不需要程序的參與,所以即使伺服器端的程序退出了,還是能與使用者端完成 TCP四次揮手的過程。
我自己也做了實驗,使用 kill -9 命令來模擬程序崩潰的情況,發現在 kill 掉程序後,伺服器端會傳送 FIN 報文,與使用者端進行四次揮手。
伺服器端主機宕機後,使用者端會發生什麼?
當伺服器端的主機突然斷電了,這種情況就是屬於伺服器端主機宕機了。
當伺服器端的主機發生了宕機,是沒辦法和使用者端進行四次揮手的,所以在伺服器端主機發生宕機的那一時刻,使用者端是沒辦法立刻感知到伺服器端主機宕機了,只能在後續的資料互動中來感知伺服器端的連線已經不存在了。
因此,我們要分兩種情況來討論:
- 伺服器端主機宕機後,使用者端會傳送資料;
- 伺服器端主機宕機後,使用者端一直不會傳送資料;
伺服器端主機宕機後,如果使用者端會傳送資料
在伺服器端主機宕機後,使用者端傳送了資料包文,由於得不到響應,在等待一定時長後,使用者端就會觸發超時重傳機制,重傳未得到響應的資料包文。
當重傳次數達到達到一定閾值後,核心就會判定出該 TCP 連線有問題,然後通過 Socket 介面告訴應用程式該 TCP 連線出問題了,於是使用者端的 TCP 連線就會斷開。
那 TCP 的資料包文具體重傳幾次呢?
在 Linux 系統中,提供了一個叫 tcp_retries2 設定項,預設值是 15,如下圖:
 圖片
圖片
這個核心引數是控制,在 TCP 連線建立的情況下,超時重傳的最大次數。
不過 tcp_retries2 設定了 15 次,並不代表 TCP 超時重傳了 15 次才會通知應用程式終止該 TCP 連線,核心會根據 tcp_retries2 設定的值,計算出一個 timeout(如果 tcp_retries2 =15,那麼計算得到的 timeout = 924600 ms),如果重傳間隔超過這個 timeout,則認為超過了閾值,就會停止重傳,然後就會斷開 TCP 連線。
在發生超時重傳的過程中,每一輪的超時時間(RTO)都是倍數增長的,比如如果第一輪 RTO 是 200 毫秒,那麼第二輪 RTO 是 400 毫秒,第三輪 RTO 是 800 毫秒,以此類推。
而 RTO 是基於 RTT(一個包的往返時間) 來計算的,如果 RTT 較大,那麼計算出來的 RTO 就越大,那麼經過幾輪重傳後,很快就達到了上面的 timeout 值了。
舉個例子,如果 tcp_retries2 =15,那麼計算得到的 timeout = 924600 ms,如果重傳總間隔時長達到了 timeout 就會停止重傳,然後就會斷開 TCP 連線:
- 如果 RTT 比較小,那麼 RTO 初始值就約等於下限 200ms,也就是第一輪的超時時間是 200 毫秒,由於 timeout 總時長是 924600 ms,表現出來的現象剛好就是重傳了 15 次,超過了 timeout 值,從而斷開 TCP 連線
- 如果 RTT 比較大,假設 RTO 初始值計算得到的是 1000 ms,也就是第一輪的超時時間是 1 秒,那麼根本不需要重傳 15 次,重傳總間隔就會超過 924600 ms。
最小 RTO 和最大 RTO 是在 Linux 核心中定義好了:
#define TCP_RTO_MAX ((unsigned)(120*HZ))
#define TCP_RTO_MIN ((unsigned)(HZ/5))
Linux 2.6+ 使用 1000 毫秒的 HZ,因此TCP_RTO_MIN約為 200 毫秒,TCP_RTO_MAX約為 120 秒。
如果tcp_retries設定為15,且 RTT 比較小,那麼 RTO 初始值就約等於下限 200ms,這意味著它需要 924.6 秒才能將斷開的 TCP 連線通知給上層(即應用程式),每一輪的 RTO 增長關係如下表格:

伺服器端主機宕機後,如果使用者端一直不發資料
在伺服器端主機傳送宕機後,如果使用者端一直不傳送資料,那麼還得看是否開啟了 TCP keepalive 機制 (TCP 保活機制)。
如果沒有開啟 TCP keepalive 機制,在伺服器端主機傳送宕機後,如果使用者端一直不傳送資料,那麼使用者端的 TCP 連線將一直保持存在,所以我們可以得知一個點,在沒有使用 TCP 保活機制,且雙方不傳輸資料的情況下,一方的 TCP 連線處在 ESTABLISHED 狀態時,並不代表另一方的 TCP 連線還一定是正常的。
而如果開啟了 TCP keepalive 機制,在伺服器端主機傳送宕機後,即使使用者端一直不傳送資料,在持續一段時間後,TCP 就會傳送探測報文,探測伺服器端是否存活:
- 如果對端是正常工作的。當 TCP 保活的探測報文傳送給對端, 對端會正常響應,這樣 TCP 保活時間會被重置,等待下一個 TCP 保活時間的到來。
- 如果對端主機崩潰,或對端由於其他原因導致報文不可達。當 TCP 保活的探測報文傳送給對端後,石沉大海,沒有響應,連續幾次,達到保活探測次數後,TCP 會報告該 TCP 連線已經死亡。
所以,TCP keepalive 機制可以在雙方沒有資料互動的情況,通過探測報文,來確定對方的 TCP 連線是否存活。
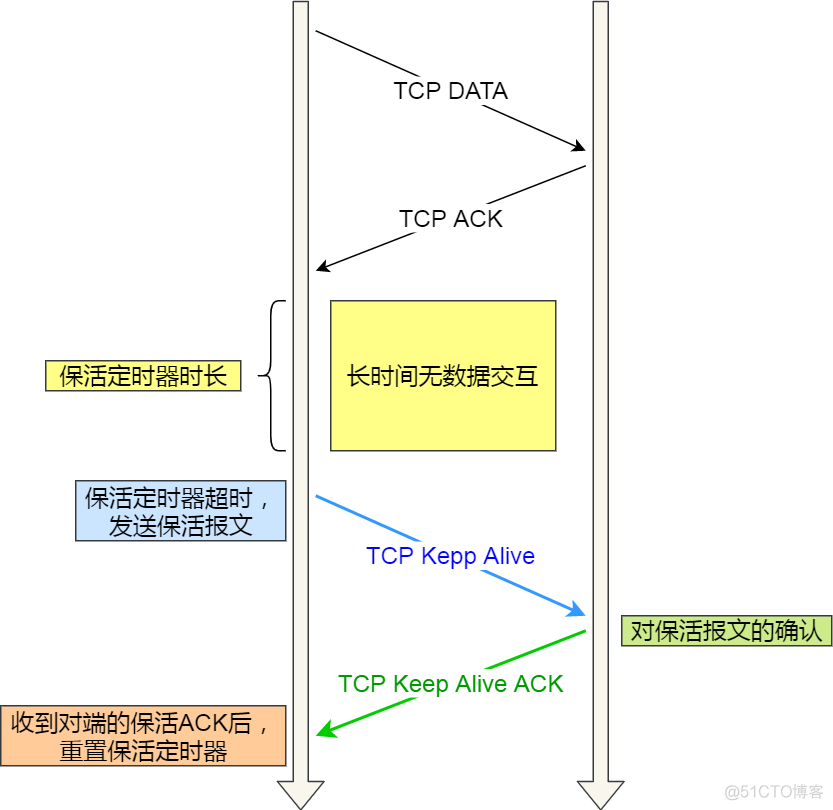
TCP keepalive 機制具體是怎麼樣的?
TCP keepalive 機制機制的原理是這樣的:
定義一個時間段,在這個時間段內,如果沒有任何連線相關的活動,TCP 保活機制會開始作用,每隔一個時間間隔,傳送一個探測報文,該探測報文包含的資料非常少,如果連續幾個探測報文都沒有得到響應,則認為當前的 TCP 連線已經死亡,系統核心將錯誤資訊通知給上層應用程式。
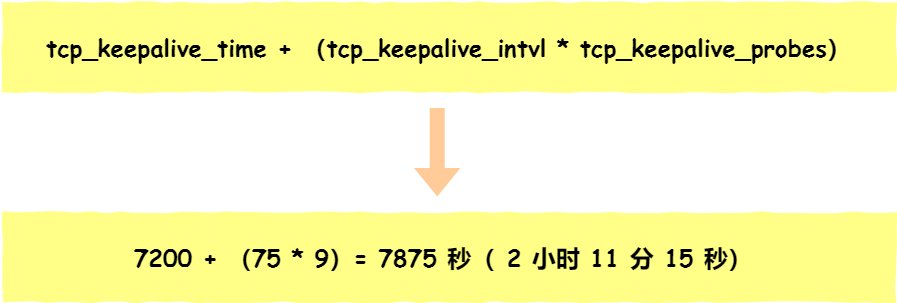
在 Linux 核心可以有對應的引數可以設定保活時間、保活探測的次數、保活探測的時間間隔,以下都為預設值:
net.ipv4.tcp_keepalive_time=7200
net.ipv4.tcp_keepalive_intvl=75
net.ipv4.tcp_keepalive_probes=9
每個引數的意思,具體如下:
- tcp_keepalive_time=7200:表示保活時間是 7200 秒(2小時),也就 2 小時內如果沒有任何連線相關的活動,則會啟動保活機制
- tcp_keepalive_intvl=75:表示每次檢測間隔 75 秒;
- tcp_keepalive_probes=9:表示檢測 9 次無響應,認為對方是不可達的,從而中斷本次的連線。
也就是說在 Linux 系統中,最少需要經過 2 小時 11 分 15 秒才可以發現一個「死亡」連線。
注意,應用程式如果想使用 TCP 保活機制,需要通過 socket 介面設定 SO_KEEPALIVE 選項才能夠生效,如果沒有設定,那麼就無法使用 TCP 保活機制。
TCP keepalive 機制探測的時間也太長了吧?
對的,是有點長。
TCP keepalive 是 TCP 層(核心態) 實現的,它是給所有基於 TCP 傳輸協定的程式一個兜底的方案。
實際上,我們應用層可以自己實現一套探測機制,可以在較短的時間內,探測到對方是否存活。
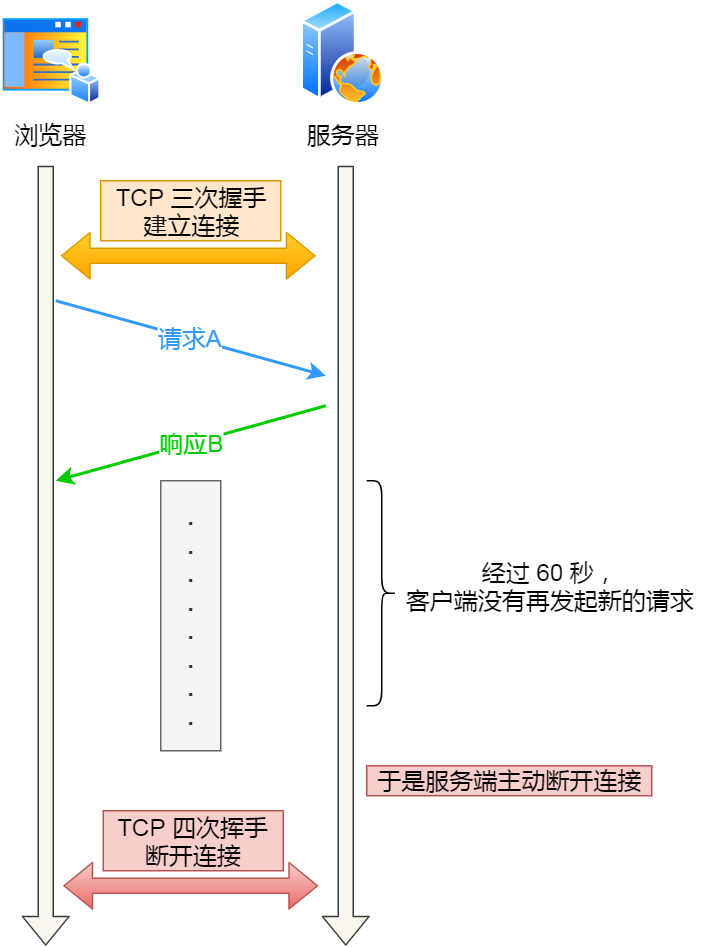
比如,web 服務軟體一般都會提供 keepalive_timeout 引數,用來指定 HTTP 長連線的超時時間。如果設定了 HTTP 長連線的超時時間是 60 秒,web 服務軟體就會啟動一個定時器,如果使用者端在完後一個 HTTP 請求後,在 60 秒內都沒有再發起新的請求,定時器的時間一到,就會觸發回撥函數來釋放該連線。
總結
如果「伺服器端掛掉」指的是「伺服器端程序崩潰」,伺服器端的程序在發生崩潰的時候,核心會傳送 FIN 報文,與使用者端進行四次揮手。
但是,如果「伺服器端掛掉」指的是「伺服器端主機宕機」,那麼是不會發生四次揮手的,具體後續會發生什麼?還要看使用者端會不會傳送資料?
- 如果使用者端會傳送資料,由於伺服器端已經不存在,使用者端的資料包文會超時重傳,當重傳總間隔時長達到一定閾值(核心會根據 tcp_retries2 設定的值計算出一個閾值)後,會斷開 TCP 連線;
- 如果使用者端一直不會傳送資料,再看使用者端有沒有開啟 TCP keepalive 機制?
- 如果有開啟,使用者端在一段時間沒有進行資料互動時,會觸發 TCP keepalive 機制,探測對方是否存在,如果探測到對方已經消亡,則會斷開自身的 TCP 連線;
- 如果沒有開啟,使用者端的 TCP 連線會一直存在,並且一直保持在 ESTABLISHED 狀態。
還有另外一個很有意思的問題:「拔掉網線幾秒,再插回去,原本的 TCP 連線還存在嗎?」,之前我也寫過,可以參考這篇:拔掉網線幾秒,原本的 TCP 連線還存在嗎?
完!
更多網路文章
 網站:xiaolincoding.com
網站:xiaolincoding.com
網路基礎篇:
HTTP 篇:
TCP 篇:
- TCP 三次握手與四次揮手面試題
- TCP 重傳、滑動視窗、流量控制、擁塞控制
- TCP 實戰抓包分析
- TCP 半連線佇列和全連線佇列
- 如何優化 TCP?
- 如何理解是 TCP 面向位元組流協定?
- 為什麼 TCP 每次建立連線時,初始化序列號都要不一樣呢?
- SYN 報文什麼時候情況下會被丟棄?
- 四次揮手中收到亂序的 FIN 包會如何處理?
- 在 TIME_WAIT 狀態的 TCP 連線,收到 SYN 後會發生什麼?
- TCP 連線,一端斷電和程序崩潰有什麼區別?
- 拔掉網線後, 原本的 TCP 連線還存在嗎?
- tcp_tw_reuse 為什麼預設是關閉的?
- HTTPS 中 TLS 和 TCP 能同時握手嗎?
- TCP Keepalive 和 HTTP Keep-Alive 是一個東西嗎?
- TCP 有什麼缺陷?
- 如何基於 UDP 協定實現可靠傳輸?
- TCP 和 UDP 可以使用同一個埠嗎?
- 伺服器端沒有 listen,使用者端發起連線建立,會發生什麼?
- 沒有 accpet,可以建立 TCP 連線嗎?
- 用了 TCP 協定,資料一定不會丟嗎?
IP 篇:
學習心得: