謠言檢測——《社會網路謠言檢測綜述》
論文資訊
論文標題:社會網路謠言檢測綜述
論文作者:高玉君,樑 剛,蔣方婷,許 春,楊 進,陳俊任,王 浩
論文來源:2020,電子學報
論文地址:download
論文程式碼:download
1 介紹
- 首先,對謠言定義進行闡述,並描述當前謠言檢測的問題及檢測過程;
- 其次,介紹不同資料獲取方式並分析其利弊,同時對比謠言檢測中不同的資料標註方法;
- 第三,根據謠言檢測技術的發展對現有的人工、機器學習和深度學習的謠言檢測方法進行分析對比;
- 第四,通過實驗在相同公開資料集下對當前主流演演算法進行實證評估;
- 最後,對社會網路謠言檢測技術面臨的挑戰進行歸納並總結。
- 人工檢測方法;[8-11]
- 基於機器學習的檢測方法;[12-13]
- 基於深度學習的檢測方法;[14、6]
- 人工檢測方法準確率高,但具有明顯的滯後性,無法適應社會網路中海量資料;
- 機器學習方法將社會網路謠言問題看作有監督學習中的二分類問題,自動化程度高,有效地彌補了人工檢測方法的不足,但基於機器學習的謠言檢測方法依賴於人工提取與選擇特徵,耗費大量的人力、物力與時間,且得到的特徵向量魯棒性也不夠健壯;
- 深度學習方法則比機器學習方法中通過特徵工程得到的特徵資料對原資料具有更好、更本質的表徵性,從而能實現更好的分類效果;
社會網路謠言檢測分類:
- 謠言檢測;
- 謠言跟蹤;
- 謠言立場分類;
- 謠言準確性分類;
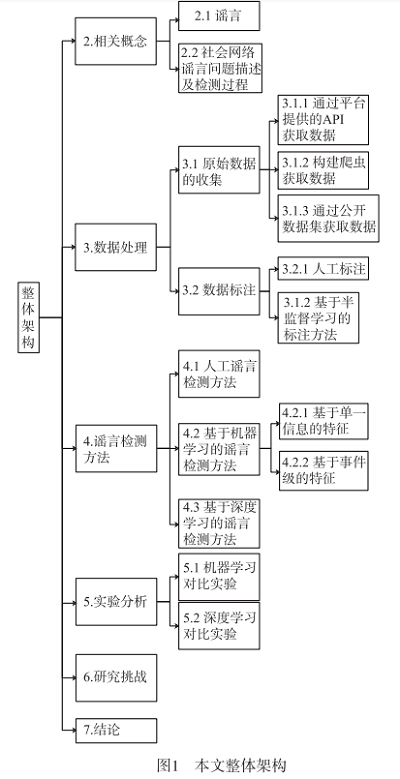
2 相關概念
2.1 謠言
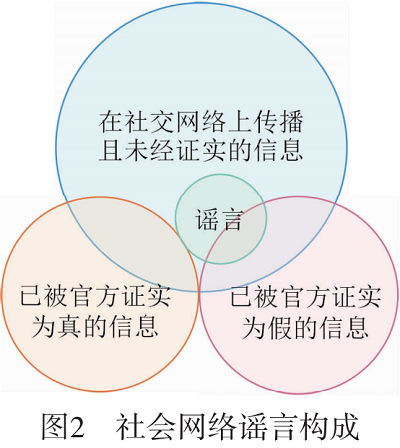
本文將社會網路謠言定義為一種在社會網路上傳播且未經驗證,或已被官方證實為假,並在社會網路中流傳的資訊。社會網路謠言的構成如圖 2 所示,其特點是:釋出門檻低、互動性強、散播速度快、散播方式和散播途徑多樣等。
2.2 社會網路謠言問題描述及檢測過程
當前主流方法將社會網路謠言檢測問題看作是有監督學習中的二分類問題,該問題的形式化定義如 下: 給定社會網路中每條推文的集合 $P=\left\{p_{1}, p_{2}, p_{3}, \cdots\right. , \left.p_{i}\right\}$ 和一個類別標籤集合 $L=\left\{l_{1}, l_{2}\right\}$ ,其中, $p_{i}$ 代表一條 推文, $l_{1}$, $l_{2}$ 分別代表謠言和非謠言這兩個類別標籤。社會媒體謠言檢測的任務是要學習一個分類模型 $M$ , 將推文 $p_{i}$ 對映成一個類別標籤 $l_{j}$ , 即 $M: p_{i} \rightarrow l_{j}$ ,模型的輸人是 一個包含有若干條微博的事件, 輸出是該事件對應的謠言或非謠言標籤。
社會網路謠言檢測過程通常包含:資料處理、特徵選擇與提取、模型訓練與謠言檢測四個階段。
- 資料處理包括原始資料的收集與資料標註,資料收集的作用主要有兩項:第一,用於構建模型訓練的資料集;第二,對社會網路進行監控,獲取待檢測的社會網路資訊。資料標註則是根據問題及需求的不同對資料進行不同的標註。
- 特徵選擇與特徵提取是從收集的原始資料中選擇與構造出最能代表資料的特徵向量集合。對於機器學習方法而言,特徵選擇與提取的重要程度甚至超過了模型選擇的重要性。因此現有基於機器學習方法的重要工作是以找到更有效的特徵作為提升謠言檢測準確率為主要思路。基於深度學習的謠言檢測具有很強的特徵學習能力,其無需對特徵進行人工提取即可得到比傳統機器學習更高維、複雜、抽象的特徵資料.
- 模型訓練是指根據具體的問題場景從已有的分類模型中選擇模型,並根據模型在訓練資料集上的分類表現調整引數以找到一個最優模型的過程。對於社會網路謠言問題,如何在充滿噪音、且不均衡的海量資料資訊中訓練出準確率高的分類器是當前社會網路謠言檢測問題面臨的最大挑戰。
- 謠言檢測則是根據模型訓練中得到的謠言分類器對社會網路中傳播的資訊進行資訊真實性的鑑別。
3 資料處理
資料處理是社會網路謠言自動檢測技術的基礎,包括原始資料收集與資料標註兩個階段。本節將對資料收集與資料標註的方法及其存在的問題進行總結與分析。
3.1 原始資料的收集
原始資料的收集是謠言檢測工作的第一步。社會網路中充斥著各種各樣的資訊使得獲取龐大的資料整合為可能。如表 1所示,目前社會網路的收集方式主要有三種:通過社會網路平臺提供的 API 獲得,使用者自己構建通用爬蟲獲得以及直接獲取第三方提供的公開資料集。
3.1.1 通過平臺提供的 API 獲取資料
基於平臺提供的 API 獲取資料的方法優點是簡單快捷,但其缺點也十分突出:
(1)受限於社會網路平臺的保護策略,通過平臺 API 獲取的資料在資料爬取速度及爬取數量上都受到嚴格控制,無法滿足使用者研究的需求。
(2)收集的資料具有較強的先驗性,利用 API 收集資料存在一個先決條件:需要使用者提供搜尋鍵碼,根據搜尋鍵碼收集微博中對應使用者或是對應事件的資訊。所以基於 API 的資料收集方法在社會網路謠言問題中只適用於收集模型訓練中的資料集,而無法有效用於實時監控資料的收集。
3.1.2 構建爬蟲獲取資料
(1)受限於法律;
(2)技術複雜度高;
3.1.3 通過公開資料集獲取資料
公開資料集在一定程度將研究者從瑣碎繁重的資料收集工作中解放出來,讓研究者集中精力在謠言檢測方法的研究。但是公開資料集存在的弊端也顯而易見:
(1)公開資料集中的資料也是通過 API 或是爬蟲獲取得到的,所以 API 或是爬蟲獲取資料的問題在公開資料集中依然存在。
(2)收集的資料可能無法滿足使用者的實際需求,公開資料是資料提供者根據自己的知識背景與經驗收集的資料,在收集時無法做到面面俱到,從而滿足所有使用者的需求。
3.2 資料標註
- 資料標註分為:
- 人工標註
- 基於半監督學習標註
3.2.1 人工標註
人工標註方法是指專人對收集的初始資料的類別(謠言或正常資訊)進行標記。為了避免認知的偏差,現有的人工標註方法通常會聘請兩人及以上標註者對資料內容同時進行標註,並從初始資料集中選擇標註結果相同的項作為最終訓練資料集的候選項。人工標註方法簡單直接,但該方法耗費了大量的人力、物力與時間,而且標註的質量依賴於標註者的知識背景與經驗。
3.2.2 基於半監督學習的標註方法
針對人工標註方法的問題,Wu等人首次在社會網路謠言檢測問題中引入基於半監督學習的自動標註方法,在人工標註少量資料的條件下,引入了一種叫做CERT( Crosstopic Emerging Rumor deTection)的框架,該框架聯合聚類資料、選擇特徵和訓練分類器實現資料的分類。基於半監督學習的自動標註方法簡單且易實現,在一定程度上緩解了人工標註方法存在的問題,但該方法的先決條件太強,需要研究者能準確地估計資料分佈資訊。但在實際工作中,研究者很難事先對資料做出準確的模型估計。因此社會網路謠言檢測問題中,人工標註方法依然占主導地位。
4 謠言檢測方法
- 謠言檢測方法分為:
- 人工謠言檢測方法;
- 基於機器學習的謠言檢測方法;
- 基於深度學習的謠言檢;
4.1 人工謠言檢測方法
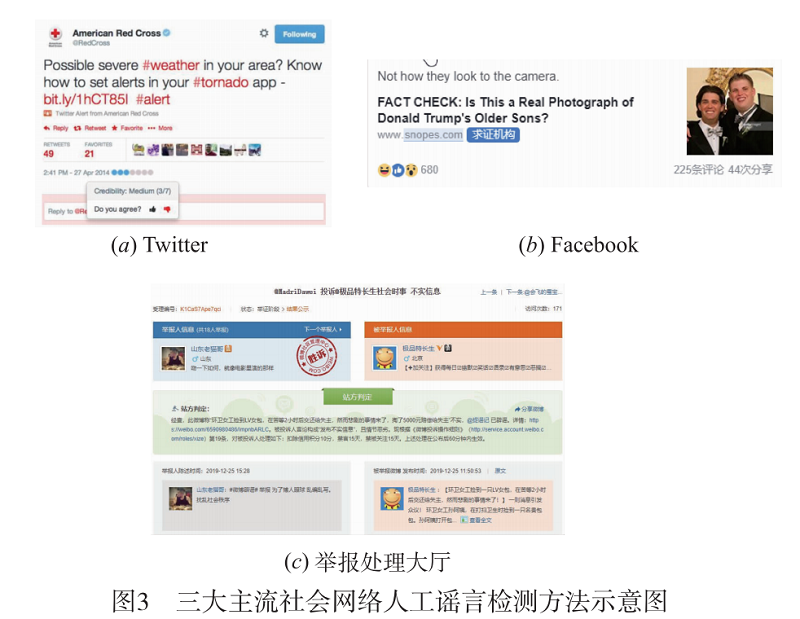
人工謠言檢測方法是當前社會網路平臺主流的謠言檢測方式,平臺將社會網路中的可疑資訊交給經驗豐富的編輯或是行業專家,利用編輯和專家的領域知識和經驗對資訊的真實性進行甄別.當前的主流社會網路平臺,如 Twitter、Facebook與新浪微博,在其平臺上都是採用人工的謠言檢測方法。
- Twitter採用眾包方法對平臺上的資訊的真實性進行鑑別。Twitter設計了一種資訊真實性判別演演算法,該演演算法能根據 Twitter上使用者對資訊的評價計算平臺上每一條資訊的真實度。
- Facebook採用人工標註與權威媒體證實相結合的方法對 Facebook上的傳播資訊的真實性進行判別。Facebook使用者一旦在 Facebook上發現可疑資訊,可通過平臺的介面提交其發現的可疑資訊,被舉報的資訊其後通過權威媒體(比如 FactCheck。或 Snopes.com)提供的 API 提交給該媒體的編輯,由權威媒體的編輯與專家對訊息的真實性進行甄別。
- 新浪微博平臺提供了兩種不實資訊檢測方法,第一種是「微博闢謠」,「微博闢謠」是微博平臺上的一個公眾號, 該公眾號定期釋出平臺上發現的不實資訊,凡是關注了該公眾號的微博使用者第一時間可以瞭解到微博平臺中不實資訊的傳播情況。第二種方法是「舉報處理大 廳」,該方法同樣採用眾包方法,微博使用者通過「舉報處理大廳」提供的介面向平臺舉報可疑的資訊,微博平臺的專家對舉報的資訊進行鑑別,並在平臺上公佈鑑別結果。
圖 3 展示三大社群網路平臺使用的謠言檢測方法;
4.2 基於機器學習的謠言檢測方法
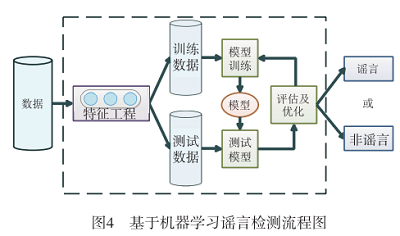
對於基於機器學習的謠言檢測方法而言, 如何選 擇與提取出顯著的特徵來表徵資料對謠言檢測的效果至關重要。早在 1999 年, Waikato 大學 Mark A Hall 就在其博士論文《Correlation-based Feature Selection for Machine Learning》中指出: 「選擇與提取有效的特徵對於分類演演算法非常重要,其重要性在某種程度上甚至超過了分類模型的選擇」。因此基於機器學習的謠言檢測方法在某種程度上可以說是一種基於特徵工 程的方法。
有的用於檢測社會網路謠言的特徵提取 方式主要包括:
(1)基於單一資訊的特徵提取方式,通過提取單條資料的特徵來處理資料;
(2)基於事件級特徵提取方式,通過挖掘資料之間層次性關係來提取資料之間的潛在聯絡。
本節將分析基於單一資訊的特徵與基於事件級特徵兩種特徵提取方式並描述其謠言檢測的過程。
4.2.1 基於單一資訊的特徵
基於單一資訊的特徵提取方式是早期謠言檢測中最常使用的方法,根據特徵提取複雜度的不同,可分為顯式特徵 ( explicit feature) 與隱式特徵 ( implicit feature)。
(1)顯式特徵
顯式特徵指的是通過直接選取即可獲得的特徵, 包括訊息文字的長度、使用者的個人資訊、粉絲數以及轉 發數等,表 2為各種顯式特徵及其特徵描述。

對於機器學習方法而言,單純地通過文字,使用者以及傳播特徵[8,21,27,41,42]等進行資訊真實性的鑑別是一件非常困難的事情。因此,研究者們引 入一種動態的、潛在的隱式特徵,用以提取資料之間的隱含關係。
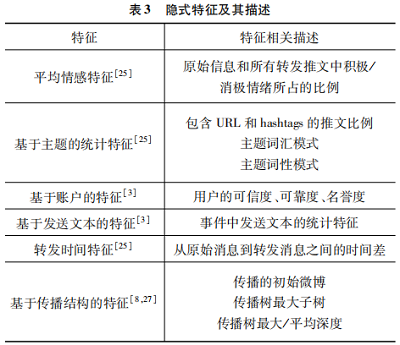
(2)隱式特徵
隱式特徵指的是無法直接獲取, 需通過關聯分析 或數值計算得到的一種潛在特徵, 如平均情感特徵、用 戶可信度以及質疑率等, 如表 3 所示。
$\mathrm{Guo}^{[3]}$ 等人提取 了基於賬戶的特徵 (Account-Based Features),包含從用 戶簡介和使用者行為中提取使用者可信度, 可靠性和名譽等隱含資訊。Wu 等人提出主題型別特徵(Topic Type Feature)、使用者型別的特徵(User Type Feature)、平均情感特徵(Avg Sentiment Feature) 以及轉發時間特徵( Repost Time Feature),通過狄利克雷分佈 (Latent Dirichlet Allocation,LDA) ${ }^{[43,44]}$ 提取訊息的主題,該主題在訊息中的概率分佈可通過式 (1)求得:
$p\left(\beta_{1: K}, \theta_{1: D}, z_{1: D}, w_{1: D}\right) =\prod_{i=1}^{K} p\left(\beta_{i}\right) \prod_{d=1}^{D} p\left(\theta_{d}\right)\left(\prod_{n=1}^{N} p\left(z_{d, n} \mid \theta_{d}\right) p\left(w_{d, n} \mid \beta_{1 ; K}, z_{d, n}\right)\right)$
其中, $\beta_{1: K}$ 表示 $1$ 到 $K$ 的所有主題,$\beta_{i}$ 表示第 $i$ 個主題詞 的分佈,$\theta_{d}$ 表示第 $d$ 個訊息中主題所佔的比例, $z_{d, n}$ 表示 第 $d$ 個訊息中第 $n$ 個詞的主題,$w_{d, n}$ 表示第 $d$ 個訊息中第 $n$個詞。
除得到推文的主題型別之外,他們還考慮發帖者 是否是已被驗證的使用者,並通過基於詞彙的平均情緒得分來判斷情緒詞與謠言之間的關聯,並考慮原始訊息和轉發訊息之間的時間間隔因素。通過基於隨機遊走圖核(Random Walk Graph Kernel)的 SVM 檢測演演算法在隨機選取的微博資料上得到 91.3% 的準確率。在社會網路傳播的資訊其實隱藏著使用者的某種行為,Mendoza等人[45]在研究智利大地震時 Twitter 中的推文變化情況發現:相較於真實資訊,謠言更容易引起受眾的質疑。由此 Liang 等人[46]提出了一種基於使用者行為特徵的謠言檢測方法,他們通過收集的微博資料發現:造謠者相較於正常資訊釋出者,為了逃避可能承擔的懲罰以 及為了快速傳播謠言資訊,其使用者行為與普通使用者存 在著較大的行為差異,使用者在閱讀正常資訊與閱讀謠言資訊時也存在著較大的行為差異。在此基礎上, Liang 等人[47]還提出了包括質疑率,單位時間發文數在內共計10條特徵用於社會網路謠言的實驗。其中,質疑率表示使用者所質疑的評論在所有評論中所佔的比例。實驗結果表明,該方法相較於傳統的基於文字、使用者與傳播結構特徵方法,查準率與查全率的提高均超過了 15%。
基於單一資訊的特徵提取方式雖簡單,但存在以下不足 :
(1) 依賴人工進行特徵的選擇,耗費人力物力的同時,得到特徵向量的魯棒性較差。
(2) 選取的特徵主要集中在從原始訊息和轉發消 息中提取大量的詞彙和語意特徵,並從標記的資料中學習模型 [8,21],難以全面系統地概括謠言的特點。
(3) 加人使用者特徵雖引人了訊息之間的關係且構造機器學習的特徵向量也相對方便,但忽略了訊息傳輸的內部圖形結構以及該結構下使用者之間的差異 [25]。同時,僅依賴於社交媒體平臺提供的使用者資訊,無法真正有效地對不同平臺使用者釋出的資訊進行檢測。
4.2.2 基於事件級的特徵
僅僅提取單一資訊的特徵往往忽略了謠言之間的 聯絡,而基於事件級特徵可通過其層次性結構反映出謠言之間的潛在關聯。本節將基於事件級的特徵定義為使用者、訊息、子事件、事件之間的層次關係特徵。如圖 5所示.
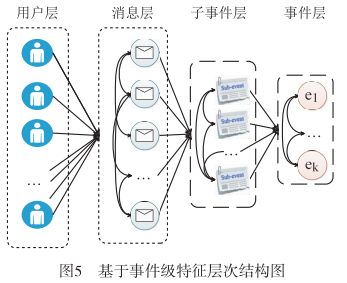
該層次結構是由使用者層、訊息層、子事件層以及事件層組成的多型別網路結構。其中,事件層為 $E=\left\{e_{1}\right. , \left.e_{2}, e_{3}, \cdots, e_{k}\right\}$ , 指在特定時間、特定地點包含一定關鍵詞 的事件集合; 子事件層為 $S=\left\{s_{k, 1}, s_{k, 2}, s_{k, 3}, \cdots, s_{k, n}\right\}$,指 每個事件中子主題的集合;訊息層為 $M=\left\{m_{n, 1}, m_{n, 2}\right. , \left.m_{n, 3}, \cdots, m_{n, i}\right\}$ , 指使用者發出的原貼以及轉發貼的集合。層內連線反映同一層級內實體之間的關係, 而層間鏈 接則反映了不同層級之間的關係。2012 年,Gupta 等 人[49] 提出了一種基於事件圖優化(Event Graph-based Optimization) 的可信度分析方法。根據事件重要程度的 不同賦予不同的分數, 同時, 通過對新事件層次化關係 之間使用正則化更新事件可信度得分來增強基本的可信度分析。在數百萬條推文的資料集上,參考 Castillo 等 人 [8] 用四種機器學習演演算法進行實驗,得到高於文獻 [8] 方法 14 % 的準確率,說明基於事件的層次化結構優於 基本的基於單條推文的可信度分析方法。此後, Sun 等 人 [24] 引人一種新的基於多媒體的特徵 (MultimediaBased Feature),加入了圖片的特徵, 並根據該項特徵來判斷微博資訊中包含的圖片是否是過去圖片。採用樸素貝葉斯、貝葉斯網路、神經網路以及決策樹對新特徵進行驗證,發現該特徵在貝葉斯網路中可獲得 85 % 的 準確率。由於不同主題事件中不同層級或層內訊息在謠言檢測中的潛在聯絡也是不同的,因此,Jin 等人 [50]
首次引人子事件層, 提出了一種分級傳播模型( Hierarchical Propagation Model), 用以對從訊息級到事件級新聞可信度進行評估。 該模型由事件、子事件和訊息組成 三層可信度網路,並利用這些實體之間的語意和社會關係建立聯絡,同時將該網路的可信度傳播過程表示為圖的優化問題,用以求出迭代演演算法的全域性最優解。 在兩個資料集該模型的準確率提高了 6%以上,F-score[51] 提高了16%以上。
結合謠言的層次結構雖然可彌補基於單條推文特徵的一些不足,但其本質還是通過人工選擇並提取特 徵。因此,仍存在機器學習中特徵提取的通病:
(1)難以獲得高維、複雜、抽象的特徵資料。
(2)試圖用一套通用的特徵集合表徵社會網路不同平臺不同語言中的全部資訊,訓練出來的謠言分類器容易陷入「過擬合」狀態 [52],模型準確度不高。
(3)所有的實驗都在研究者自己選擇的資料集上進行實驗,並不能有效地體現出新提出的特徵在不同平臺不同資料集下對謠言檢測的作用。
4.3 基於深度學習的謠言檢測方法
由於傳統機器學習的謠言檢測方法依賴特徵工程需要耗費大量的人力、物力與時間來選擇合適的特徵向量,因此, 研究者們嘗試在社會謠言問題檢測中引人深度學習的方法。深度學習具有很強的特徵 學習能力, 其模型學習的特徵比傳統機器學習演演算法中通過特徵工程得到的特徵資料對原資料具有更好的, 更本質的代表性,從而能實現更好的分類效果[14]。本節以基於深度學習的謠言檢測技術的發展 為線索,深人分析並總結了現有的基於深度學習的謠言檢測方法。
微博中的資訊是一種與時間密切相關的時序資料,而回圈神 經網 絡 ( Recurrent Neural Network, $\mathrm{RNN}$) [53,54] 在時間序列和句子等變長序列資訊建模方面顯示出了強大的功能。2016 年, $\mathrm{Ma}$ 等人 [55] 首次將回圈神經網路引人到謠言檢測中, 通過對文字序列數 據進行時間維度上的建模分析得到謠言上下文資訊隨時間變化的隱式特徵。加人長短期記憶 ( Long-ShortTerm Memory, LSTM ) [56,57] 以及門控迴圈單元 ( Gated Recurrent Unit, GRU) [58] 等額外的隱藏層,解決了在長序列訓練過程中, 隨著 RNN 層數的加深而造成的梯度消失與梯度爆炸問題 [59,60] , 從而提高謠言檢測的準確度。在微博資料集上,加人雙層 GRU 的迴圈神經網路準確率為88.1%,在 Twitter 資料集上,其準確率高達 91.0%,都 超過了基 礎 tanh RNN 與加 入 一 層 LSTM/GRU 的謠言檢測準確率。
圖 6為基於迴圈神經網路的謠言檢測的流程圖。
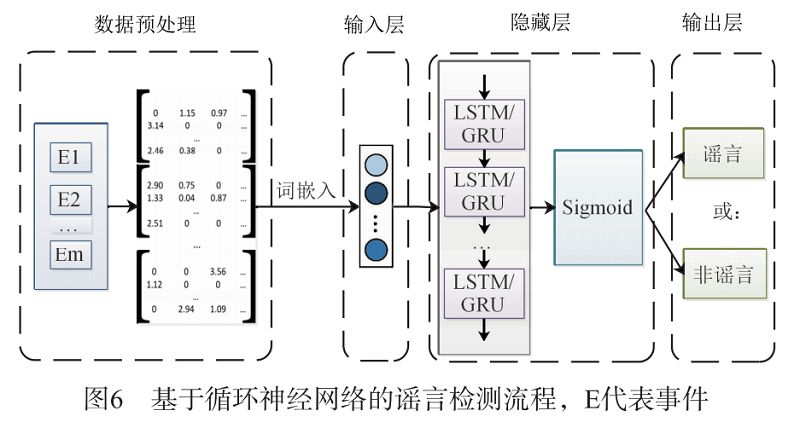
首先,針對每個事件收集相關貼文,對輸入的事件文字資料得到 tf-idf 值矩陣,再將高維的詞袋模型向量通過詞嵌入的方式轉成低維空間的向量表示,得到輸入值。然後,將該值輸入到 RNN 模型中,通過迴圈神經網路捕獲文字序列的相關語意特徵,由於基礎的隱藏層沒有門控單元,在 $t$ 時刻向前反向傳播的過程中,存在梯度消失(大部分情況 下)或者梯度爆炸的情況,使得該結構難以捕捉長距離依賴,為緩解基礎模型帶來的缺陷,在隱藏層加入門控單元 LSTM/GRU,通過門(gate)機制控制隱藏層 中的資訊流動,保留了文字間的語意資訊,以提高謠言檢測的準確度。最後,通過 Sigmoid 啟用函數輸出分類標籤,預測是否是謠言。
然而,在謠言爆發的初期,無法獲取足夠的標記 資料用來訓練模型,因此,為能夠儘早地檢測出社會網路中的謠言,Chen 等人[52]提出結合迴圈神經網路和變分自編碼器(Variational Auto Encoder)[61]的無監督學習模型來學習社會網路使用者的網路行為,由於正常資料與異常資料在降維過程中存在著顯著的差異[62],因此利用模型得到輸出值和輸入的目標值之間的誤差與指定閾值進行比較,判斷其是否是謠言。其中,RNN 與自編碼器(Auto Encoder,AE)的結合模 型如圖 7所示。
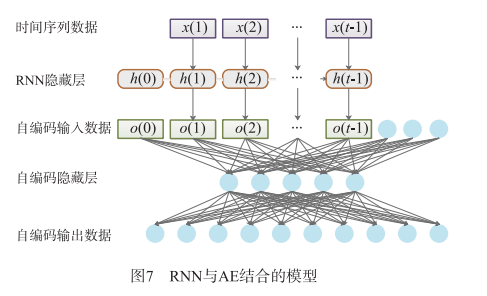
該模型主要分成兩個模組進行層次訓練,分別為 RNN 模組和 AE 模組。首先將收集到的不同時間節點的微博資料進行清洗後,建立特徵工程,通過微博內容提取是否有圖片,是否有轉發,是否是積極態度等 15 個特徵, 傳入 RNN 模組,並在時間維度上進行訓練;然後將該模 塊的輸出結合發博時間,發博來源等其餘特徵送入 AE 模組,通過 AE 實現無監督的異常檢測,通過一系列的矩 陣對映將輸出重構成與輸入形狀相同的結構;最後,使用歐幾里得正規化計算 AE 模組輸入的目標值和輸出值之間的誤差,並與設定的閾值比較,從而判斷該推文是否是謠言。該模型實現了單隱藏層和多隱藏層結構,兩層模型的準確率分別為 92.49% 和 89.16%。但該模型只在新浪微博的謠言資料下進行實驗,並不能很好地驗證出其在不同平臺資料下的適應性。因此,Wen 等人[23]設計了一個基於神經網路的模型,該模型採用了跨語言、跨平臺的有限元分析方法,利用不同平臺和語言之間的資訊相似性和一致性來驗證謠言。Ajao等人[63]利用折積神經網路(Convolutional Neural Networks, CNN)和長短期迴圈神經網路模型(Long-Short Term Recurrent Neural Network Models)來檢測並分類 Twitter 上釋出的虛假新聞。該方法無需任何人工提取外部特徵的步驟即可直觀地識別與謠言相關的特徵。
傳統的基於深度學習的謠言檢測方法擺脫了人工 構建特徵工程的方式。然而, 天然的端到端結構難以把 握謠言資訊中的關鍵成分, 模型訓練缺乏可控性,訓練時間長且模型複雜。 因而引人注意力機制 (Attention Mechanism [30,64] 進行謠言檢測。注意力機制最早提出於視覺影象 [65] 領域,該方法借鑑了人類的注意力思維方式,模仿人類對圖片不同地方的觀察側重點,用以對影象不同位置施加不同的權重,從而決定更重要的部分,並提高該部分的權重,降低噪聲部分的權重。 2014 年, Bahdanau 等人 [66] 首次將注意力機制引人自然語言處理領域,該工作首先通過對 Encoder 部分的輸人和隱 藏狀態值經過迴圈神經網路進行編碼,從而輸出中間向量,再由 Decoder 部分將中間向量藉助另一個迴圈神經網路解碼成輸出向量。
基於注意力機制在謠言檢測領域的應用,Chen 等人 [11] 提出一種基於注意力機制的迴圈神經網路 模型 CallAtRumors(Call Attention to Rumors),加人注 意力機制從重複、不斷變化的推文中提取出隱式與 顯式的謠言特徵,用於對社會網路資訊序列中選擇 關注度高的資訊進行檢測,在模型訓練中,採用交叉熵損失函數和雙重隨機正則化 [67] 相結合的方法,對輸人字矩陣的每個元素進行校正,其損失函數如式 (2) 所示 :
$L=-\sum_{t=1}^{\tau} \sum_{i=1}^{c} y_{t, i} \log y_{t, i}^{\prime}+\lambda \sum_{i=1}^{K}\left(1-\sum_{t=1}^{\tau} a_{t, i}\right)^{2}+\gamma \varphi^{2} $
其中, $y_{i}$ 表示獨熱標籤向量 (one hot label vector),$y_{i}^{\prime}$ 表示 在 $t$ 時刻的二分類概率向量, $\tau$ 表示總時間, $C$ 表示輸出類的數目,其數值為 $2$ (表示謠言或非謠言 ),$ \lambda$ 表示注意力分配係數, $\gamma$ 表示權值係數, $\varphi$ 代表所有模型引數。
該模型在 Twitter 與新浪微博上分別取得 88.63 % 和 87.10 % 準確率。Jin 等人 [1] 在此基礎上加人圖片這 一特徵,使用迴圈神經網路來學習文字和社會背景( social context)相結合的表示;使用折積神經網路訓練提取影象的視覺特徵;使用注意力機制對視覺特徵和共 同的文字/社會背景特徵分配不同權重.融合了文字、 影象和社會背景特徵對 Twitter 和新浪微博資料集進行 謠言檢 測,但 其 在 兩 個 數 據 集 上 的 準 確 率 分 別 為78.8%和68.2%,難以保證謠言檢測的效果。因此,Guo 等人[3]提出了一種結合社會資訊(social information)的 層次神經網路(HSA-BLSTM)方法用於謠言檢測。首先建立了表示學習的層次雙向長短時記憶模型(Hierarchical Bi-directional Long Short-term Memory Model),然 後通過注意力機制將社會背景整合到網路中,最後在新浪微博和 Twitter 中進行實驗,分別取得94.3%和 84.4%的準確率。與 Guo 等人[3]類似,Liao 等人[68]通過採用兩層帶有注意力機制的雙向 GRU 網路從微博內容和時間層面分別獲取微博序列的隱藏層表示和時間 段序列的隱藏層表示,從而在事件的特徵表示中融入了時間段內各微博間的時序資訊。此外,還針對各個時 間段提取了區域性使用者特徵及文字潛在特徵,並將這些 特徵融入到時間段中,進一步捕獲這些特徵隨時間變 化的隱藏層狀態值,最終得到 96.8%的謠言檢測準確率。但該方法依賴人工對事件進行時間段劃分,在花費人力及時間的基礎上還可能帶來資訊的丟失。為通過區別原貼和轉發貼來檢測謠言,Xu等人[69]考慮原帖內容、轉發帖的擴散情況以及使用者資訊三方面,提出一個融合神經謠言檢測(Merged Neural Rumor Detection, MNRD)模型,通過基於內容的注意力機制的原貼編碼 和基於擴散的注意力機制的轉發編碼分別學習從原貼 和轉發中提取高層次的特徵表示,通過使用者特徵編碼 器對使用者資訊進行編碼,以獲取使用者可靠性和社會影 響力,結合這些特徵對謠言進行檢測。在新浪微博資料 集上取得 94.4%的準確率。
基於注意力機制的迴圈神經網路模型不僅具有很強的特徵學習能力,同時能捕獲謠言中的重要語意成分,但其仍存在以下不足: (1)對資料的需求量大,當樣本資料較少時,訓練出來的分類器仍存在分類偏倚[70]問題。 (2)模型訓練週期更長,訓練出的模型可解釋性差。(3)需要 GPU 來高效優化矩陣運算,對 GPU 的要求較高。
因上求緣,果上努力~~~~ 作者:關注我更新論文解讀,轉載請註明原文連結:https://www.cnblogs.com/BlairGrowing/p/16650417.html