HDFS 偽分散式環境搭建
HDFS 偽分散式環境搭建
作者:Grey
原文地址:
相關軟體版本
-
Hadoop 2.6.5
-
CentOS 7
-
Oracle JDK 1.8
安裝步驟
在CentOS 下安裝 Oracle JDK 1.8
將下載好的 JDK 的安裝包 jdk-8u202-linux-x64.tar.gz 上傳到應用伺服器的/tmp目錄下
執行以下命令
cd /usr/local && mkdir jdk && tar -zxvf /tmp/jdk-8u202-linux-x64.tar.gz -C ./jdk --strip-components 1
執行下面兩個命令設定環境變數
echo "export JAVA_HOME=/usr/local/jdk" >> /etc/profile
echo "export PATH=\$PATH:\$JAVA_HOME/bin" >> /etc/profile
然後執行
source /etc/profile
驗證 JDK 是否安裝好,輸入
java -version
顯示如下內容
'java version "1.8.0_202"
Java(TM) SE Runtime Environment (build 1.8.0_202-b08)
Java HotSpot(TM) 64-Bit Server VM (build 25.202-b08, mixed mode)
JDK 安裝成功。
建立如下目錄:
mkdir /opt/bigdata
將 Hadoop 安裝包下載至/opt/bigdata目錄下
下載方式一
執行:yum install -y wget
然後執行如下命令:cd /opt/bigdata/ && wget https://archive.apache.org/dist/hadoop/common/hadoop-2.6.5/hadoop-2.6.5.tar.gz
下載方式二
如果報錯或者網路不順暢,可以直接把下載好的安裝包上傳到/opt/bigdata/目錄下
設定靜態ip
vi /etc/sysconfig/network-scripts/ifcfg-ens33
內容參考如下內容修改
修改BOOTPROTO="static"
新增:
IPADDR="192.168.150.137"
NETMASK="255.255.255.0"
GATEWAY="192.168.150.2"
DNS1="223.5.5.5"
DNS2="114.114.114.114"
然後執行service network restart
設定主機名vi /etc/sysconfig/network
設定為
NETWORKING=yes
HOSTNAME=node01
注:HOSTNAME 自己定義即可,主要要和後面的 hosts 設定中的一樣。
設定本機的ip到主機名的對映關係:vi /etc/hosts
192.168.150.137 node01
注:IP 根據你的實際情況來定
重啟網路service network restart
執行如個命令,關閉防火牆
systemctl stop firewalld.service
systemctl disable firewalld.service
firewall-cmd --reload
service iptables stop
chkconfig iptables off
關閉 selinux:執行vi /etc/selinux/config
設定
SELINUX=disabled
做時間同步yum install ntp -y
修改組態檔vi /etc/ntp.conf
加入如下設定:
server ntp1.aliyun.com
啟動時間同步服務
service ntpd start
加入開機啟動
chkconfig ntpd on
SSH 免密設定,在需要遠端到這個伺服器的使用者端中
執行ssh localhost
依次輸入:yes
然後輸入:本機的密碼
生成本機的金鑰和公鑰:
ssh-keygen -t dsa -P '' -f ~/.ssh/id_dsa
在伺服器上設定免密:
cat ~/.ssh/id_dsa.pub >> ~/.ssh/authorized_keys
在使用者端再次執行ssh localhost
發現可以免密登入,不需要輸入密碼了
接下來安裝 hadoop 安裝包,執行
cd /opt/bigdata && tar xf hadoop-2.6.5.tar.gz
然後執行:
mv hadoop-2.6.5 hadoop
新增環境變數vi /etc/profile
加入如下內容:
export JAVA_HOME=/usr/local/jdk
export HADOOP_HOME=/opt/bigdata/hadoop
export PATH=$PATH:$JAVA_HOME/bin:$HADOOP_HOME/bin:$HADOOP_HOME/sbin
然後執行source /etc/profile
Hadoop 設定
執行vi $HADOOP_HOME/etc/hadoop/hadoop-env.sh
設定 JAVA_HOME
export JAVA_HOME=/usr/local/jdk
執行vi $HADOOP_HOME/etc/hadoop/core-site.xml
在<configuration></configuration>節點內設定:
<property>
<name>fs.defaultFS</name>
<value>hdfs://node01:9000</value>
</property>
執行vi $HADOOP_HOME/etc/hadoop/hdfs-site.xml
在<configuration></configuration>節點內設定
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
<property>
<name>dfs.namenode.name.dir</name> <value>/var/bigdata/hadoop/local/dfs/name</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>/var/bigdata/hadoop/local/dfs/data</value>
</property>
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>node01:50090</value>
</property>
<property>
<name>dfs.namenode.checkpoint.dir</name> <value>/var/bigdata/hadoop/local/dfs/secondary</value>
</property>
執行vi $HADOOP_HOME/etc/hadoop/slaves
設定為node01
初始化和啟動 HDFS,執行
hdfs namenode -format
建立目錄,並初始化一個空的fsimage
如果你使用windows作為使用者端,那麼需要設定 hosts 條目
進入C:\Windows\System32\drivers\etc
在 host 檔案中增加如下條目:
192.168.241.137 node01
注:ip 地址要和你的伺服器地址一樣
啟動 hdfs
執行start-dfs.sh
輸入: yes
第一次啟動,datanode 和 secondary 角色會初始化建立自己的資料目錄
並在命令列執行:
hdfs dfs -mkdir /bigdata
hdfs dfs -mkdir -p /user/root
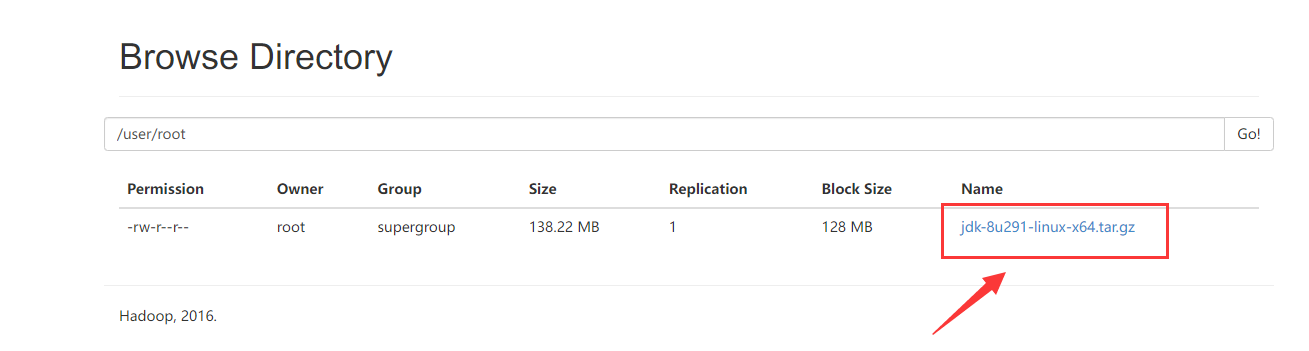
通過 hdfs 上傳檔案:
hdfs dfs -put jdk-8u291-linux-x64.tar.gz /user/root
通過:http://node01:50070/explorer.html#/user/root
可以看到上傳的檔案
參考資料
Hadoop MapReduce Next Generation - Setting up a Single Node Cluster.
本文來自部落格園,作者:Grey Zeng,轉載請註明原文連結:https://www.cnblogs.com/greyzeng/p/16659749.html