使用Apache Flink 和 Apache Hudi 建立低延遲資料湖管道
近年來出現了從單體架構向微服務架構的轉變。微服務架構使應用程式更容易擴充套件和更快地開發,支援創新並加快新功能上線時間。但是這種方法會導致資料存在於不同的孤島中,這使得執行分析變得困難。為了獲得更深入和更豐富的見解,企業應該將來自不同孤島的所有資料集中到一個地方。
AWS 提供複製工具,例如 AWS Database Migration Service (AWS DMS),用於將資料更改從各種源資料庫複製到各種目標,包括 Amazon Simple Storage Service (Amazon S3)。但是需要將資料湖中的資料與源系統上的更新和刪除同步的客戶仍然面臨一些挑戰:
- 當記錄儲存在 Amazon S3 上的開放資料格式檔案(例如 JSON、ORC 或 Parquet)中時,很難應用記錄級更新或刪除。
- 在流式使用案例中,作業需要以低延遲寫入資料,JSON 和 Avro 等基於行的格式最適合。但是使用這些格式掃描許多小檔案會降低讀取查詢效能。
- 在源資料模式頻繁更改的用例中,通過自定義程式碼維護目標資料集的模式既困難又容易出錯。
Apache Hudi 提供瞭解決這些挑戰的好方法。 Hudi 在第一次寫入記錄時會建立索引。 Hudi 使用這些索引來定位更新(或刪除)所屬的檔案。這使 Hudi 能夠通過避免掃描整個資料集來執行快速更新插入(或刪除)操作。 Hudi 提供了兩種表型別,每種都針對特定場景進行了優化:
- Copy-On-Write (COW) – 這些表在批次處理中很常見。在這種型別中,資料以列格式(Parquet)儲存,每次更新(或刪除)都會在寫入過程中建立一個新版本的檔案。
- Merge-On-Read (MOR) – 使用列(例如 Parquet)和基於行(例如 Avro)檔案格式的組合儲存資料,旨在讓資料更加實時。
儲存在 Amazon S3 中的 Hudi 資料集提供與其他 AWS 服務的原生整合。例如可以使用 AWS Glue(請參閱使用 AWS Glue 自定義聯結器寫入 Apache Hudi 表)或 Amazon EMR(請參閱 Amazon EMR 中提供的 Apache Hudi 的新功能)寫入 Apache Hudi 表。但這些方法需要對 Hudi 的 Spark API 和程式設計技能有深入的掌握,才能構建和維護資料管道。
這篇文章中將展示一種以最少編碼處理流資料的不同方式。本文中的步驟演示瞭如何在沒有 Flink 或 Hudi 知識的情況下使用 SQL 語言構建完全可延伸的管道。可以通過編寫熟悉的 SELECT 查詢來查詢和探索多個資料流中的資料,還可以連線來自多個流的資料並將結果物化到 Amazon S3 上的 Hudi 資料集。
解決方案概述
下圖提供了本文中描述的解決方案的整體架構。接下來的部分將會詳細描述描述元件和步驟。
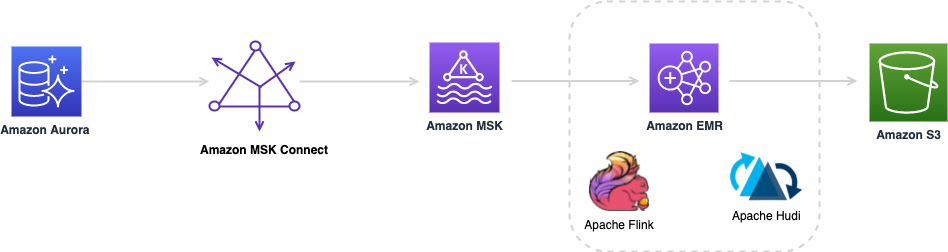
使用 Amazon Aurora MySQL 資料庫作為源,使用帶有 MSK Connect Lab 中描述的 Debezium MySQL 聯結器作為變更資料捕獲 (CDC) 複製器。本實驗將引導完成設定堆疊的步驟,以使用帶有 MySql Debezium 源 Kafka 聯結器的 Amazon MSK Connect 將 Aurora 資料庫 salesdb 複製到 Amazon Managed Streaming for Apache Kafka (Amazon MSK) 叢集。
2021 年 9 月,AWS 宣佈 MSK Connect 用於執行完全託管的 Kafka Connect 叢集。只需單擊幾下,MSK Connect 即可輕鬆部署、監控和擴充套件聯結器,將資料從資料庫、檔案系統和搜尋索引等外部系統移入和移出 Apache Kafka 和 MSK 叢集。使用者現在可以使用 MSK Connect 構建從許多資料庫源到 MSK 叢集的完整 CDC 管道。
Amazon MSK 是一項完全託管的服務,可以輕鬆構建和執行使用 Apache Kafka 處理流資料的應用程式。使用 Apache Kafka 可以從資料庫更改事件或網站點選流等來源捕獲實時資料。然後構建管道(使用流處理框架,如 Apache Flink)將它們交付到目標,如持久儲存或 Amazon S3。
Apache Flink 是一個流行的框架,用於構建有狀態的流和批次處理管道。 Flink 帶有不同級別的抽象,以涵蓋廣泛的用例。
Flink 還根據選擇的資源提供者(Hadoop YARN、Kubernetes 或獨立)提供不同的部署模式。
這篇文章將使用 SQL 使用者端工具作為一種互動式方式以 SQL 語法建立 Flink 作業。 sql-client.sh將作業編譯並提交到 Amazon EMR 上長時間執行的 Flink 叢集(session 模式)。根據指令碼,sql-client.sh要麼實時顯示作業的表格格式輸出,要麼返回長時間執行的作業的作業 ID。
可以通過以下步驟實施解決方案:
- 建立 EMR 叢集
- 使用 Kafka 和 Hudi 表聯結器設定 Flink
- 開發實時提取、轉換和載入 (ETL) 作業
- 將管道部署到生產環境
先決條件
本文假設環境中有一個正在執行的 MSK Connect ,其中包含以下元件:
- Aurora MySQL 託管資料庫。這篇文章中將使用範例資料庫
salesdb。 - 在 MSK Connect 上執行的 Debezium MySQL 聯結器,在 Amazon Virtual Private Cloud (Amazon VPC) 中以 Amazon MSK 結尾。
- 在 VPC 中執行的 MSK 叢集
如果沒有 MSK Connect ,請按照 MSK Connect 實驗室設定中的說明進行操作,並驗證源聯結器是否將資料更改複製到 MSK 主題。
還需要能夠直接連線到 EMR Leader節點。Session Manager 是 AWS Systems Manager 的一項功能,可提供基於瀏覽器的互動式一鍵式 shell 視窗。對談管理器還允許對受管節點進行受控存取的公司策略。
如果不使用 Session Manager ,也可以使用 Amazon Elastic Compute Cloud (Amazon EC2) 私有金鑰對,但需要在公有子網中啟動叢集並提供入站 SSH 存取。
建立 EMR 叢集
在撰寫本文時最新發布的 Apache Hudi 版本是 0.10.0。 Hudi 釋出版本 0.10.0 相容 Flink 釋出版本 1.13。 因此需要 Amazon EMR 釋出版本 emr-6.4.0 及更高版本,它與 Flink 釋出版本 1.13 一起提供。 要使用 AWS 命令列介面 (AWS CLI) 啟動安裝了 Flink 的叢集,請完成以下步驟:
- 建立一個檔案,configurations.json,包含以下內容:
[
{
"Classification": "flink-conf",
"Properties": {
"taskmanager.numberOfTaskSlots":"4"
}
}
]
- 在私有子網(推薦)或託管 MSK 叢集的同一 VPC 的公有子網中建立 EMR 叢集。 使用
--name選項輸入叢集的名稱,並使用--ec2-attributes選項指定 EC2 金鑰對的名稱以及子網 ID。 請參閱以下程式碼:
aws emr create-cluster --release-label emr-6.4.0 \
--applications Name=Flink \
--name FlinkHudiCluster \
--configurations file://./configurations.json \
--region us-east-1 \
--log-uri s3://yourLogUri \
--instance-type m5.xlarge \
--instance-count 2 \
--service-role EMR_DefaultRole \
--ec2-attributes KeyName=YourKeyName,InstanceProfile=EMR_EC2_DefaultRole, SubnetId=A SubnetID of Amazon MSK VPC
- 等到叢集狀態變更為 Running。
- 使用 Amazon EMR 控制檯或 AWS CLI 檢索Leader節點的 DNS 名稱。
- 通過 Session Manager 或在 Linux、Unix 和 Mac OS X 上使用 SSH 和 EC2 私鑰連線到Leader節點。
- 使用 SSH 連線時,領導節點的安全組必須允許埠 22。
- 確保 MSK 叢集的安全組具有接收來自 EMR 叢集安全組的流量的入站規則。
使用 Kafka 和 Hudi 表聯結器設定 Flink
Flink 表聯結器允許使用 Table API 程式設計流操作時連線到外部系統。源聯結器提供對流服務的存取,包括作為資料來源的 Kinesis 或 Apache Kafka。Sink 聯結器允許 Flink 將流處理結果傳送到外部系統或 Amazon S3 等儲存服務。
在 Amazon EMR Leader節點上下載以下聯結器並將它們儲存在 /lib/flink/lib 目錄中:
- 源聯結器——從 Apache 倉庫下載
flink-connector-kafka_2.11-1.13.1.jar。 Apache Kafka SQL 聯結器允許 Flink 從 Kafka 主題中讀取資料。 - 接收器聯結器 – Amazon EMR 釋出版本 emr-6.4.0 隨附 Hudi 釋出版本 0.8.0。但是在這篇文章中需要 Hudi Flink 捆綁聯結器釋出版本 0.10.0,它與 Flink 釋出版本 1.13 相容。從 Apache 倉庫下載
hudi-flink-bundle_2.11-0.10.0.jar。它還包含多個檔案系統使用者端,包括用於與 Amazon S3 整合的 S3A。
開發實時 ETL 作業
這篇文章使用 Debezium 源 Kafka 聯結器將範例資料庫 salesdb的資料更改流式傳輸到 MSK 叢集。聯結器以 JSON 格式生成資料更改。 Flink Kafka 聯結器可以通過在表選項中使用 debezium-json設定 value.format來反序列化 JSON 格式的事件。除了插入之外,此設定還完全支援資料更新和刪除。
使用 Flink SQL API 構建一個新作業。這些 API 允許使用流資料,類似於關聯式資料庫中的表。此方法中指定的 SQL 查詢在源流中的資料事件上連續執行。因為 Flink 應用程式從流中消費無限資料,所以輸出不斷變化。為了將輸出傳送到另一個系統,Flink 向下遊 sink 操作員發出更新或刪除事件。因此當使用 CDC 資料或編寫需要更新或刪除輸出行的 SQL 查詢時,必須提供支援這些操作的接收器聯結器。否則Flink 作業將出現如下錯誤資訊
Target Table doesn't support consuming update or delete changes which is produced by {your query statement} …
啟動 Flink SQL 使用者端
使用之前在組態檔中指定的設定在 EMR 叢集上啟動 Flink YARN 應用程式:
cd /lib/flink && ./bin/yarn-session.sh --detached
命令成功執行後就可以建立第一個作業了。執行以下命令以啟動 sql-client:
./bin/sql-client.sh
終端視窗類似於以下螢幕截圖。

設定作業引數
執行以下命令來設定此對談的檢查點間隔:
SET execution.checkpointing.interval = 1min;
定義源表
從概念上講使用 SQL 查詢處理流需要將事件解釋為表中的邏輯記錄。 因此使用 SQL API 讀取或寫入資料之前的第一步是建立源表和目標表。 表定義包括連線設定和設定以及定義流中物件的結構和序列化格式的模式。
這篇文章中將建立三個源表,每個對應於 Amazon MSK 中的一個主題。還可以建立一個目標表,將輸出資料記錄寫入儲存在 Amazon S3 上的 Hudi 資料集。
在"properties.bootstrap.servers"選項中將 BOOTSTRAP SERVERS ADDRESSES替換為自己的 Amazon MSK 叢集資訊,並在 sql-client終端中執行以下命令:
CREATE TABLE CustomerKafka (
`event_time` TIMESTAMP(3) METADATA FROM 'value.source.timestamp' VIRTUAL, -- from Debezium format
`origin_table` STRING METADATA FROM 'value.source.table' VIRTUAL, -- from Debezium format
`record_time` TIMESTAMP(3) METADATA FROM 'value.ingestion-timestamp' VIRTUAL,
`CUST_ID` BIGINT,
`NAME` STRING,
`MKTSEGMENT` STRING,
WATERMARK FOR event_time AS event_time
) WITH (
'connector' = 'kafka',
'topic' = 'salesdb.salesdb.CUSTOMER', -- created by debezium connector, corresponds to CUSTOMER table in Amazon Aurora database.
'properties.bootstrap.servers' = '<PLAINTEXT BOOTSTRAP SERVERS ADDRESSES>',
'properties.group.id' = 'ConsumerGroup1',
'scan.startup.mode' = 'earliest-offset',
'value.format' = 'debezium-json'
);
CREATE TABLE CustomerSiteKafka (
`event_time` TIMESTAMP(3) METADATA FROM 'value.source.timestamp' VIRTUAL, -- from Debezium format
`origin_table` STRING METADATA FROM 'value.source.table' VIRTUAL, -- from Debezium format
`record_time` TIMESTAMP(3) METADATA FROM 'value.ingestion-timestamp' VIRTUAL,
`CUST_ID` BIGINT,
`SITE_ID` BIGINT,
`STATE` STRING,
`CITY` STRING,
WATERMARK FOR event_time AS event_time
) WITH (
'connector' = 'kafka',
'topic' = 'salesdb.salesdb.CUSTOMER_SITE',
'properties.bootstrap.servers' = '< PLAINTEXT BOOTSTRAP SERVERS ADDRESSES>',
'properties.group.id' = 'ConsumerGroup2',
'scan.startup.mode' = 'earliest-offset',
'value.format' = 'debezium-json'
);
CREATE TABLE SalesOrderAllKafka (
`event_time` TIMESTAMP(3) METADATA FROM 'value.source.timestamp' VIRTUAL, -- from Debezium format
`origin_table` STRING METADATA FROM 'value.source.table' VIRTUAL, -- from Debezium format
`record_time` TIMESTAMP(3) METADATA FROM 'value.ingestion-timestamp' VIRTUAL,
`ORDER_ID` BIGINT,
`SITE_ID` BIGINT,
`ORDER_DATE` BIGINT,
`SHIP_MODE` STRING,
WATERMARK FOR event_time AS event_time
) WITH (
'connector' = 'kafka',
'topic' = 'salesdb.salesdb.SALES_ORDER_ALL',
'properties.bootstrap.servers' = '< PLAINTEXT BOOTSTRAP SERVERS ADDRESSES>',
'properties.group.id' = 'ConsumerGroup3',
'scan.startup.mode' = 'earliest-offset',
'value.format' = 'debezium-json'
);
預設情況下 sql-client將這些表儲存在記憶體中,它們僅在活動對談期間存在,每當 sql-client 對談到期或退出時都需要重新建立表。
定義目標Sink表
以下命令建立目標表。 指定 'hudi'作為此表中的聯結器。 其餘的 Hudi 設定在 CREATE TABLE語句的 with(...)部分中設定。將 S3URI OF HUDI DATASET LOCATION替換為在 Amazon S3 中的 Hudi 資料集位置並執行以下程式碼:
CREATE TABLE CustomerHudi (
`order_count` BIGINT,
`customer_id` BIGINT,
`name` STRING,
`mktsegment` STRING,
`ts` TIMESTAMP(3),
PRIMARY KEY (`customer_id`) NOT Enforced
)
PARTITIONED BY (`mktsegment`)
WITH (
'connector' = 'hudi',
'write.tasks' = '4',
'path' = '<S3URI OF HUDI DATASET LOCATION>',
'table.type' = 'MERGE_ON_READ' -- MERGE_ON_READ table or, by default is COPY_ON_WRITE
);
從多個主題驗證 Flink 作業的結果
對於 select查詢,sql-client將作業提交到 Flink 叢集,然後將結果實時顯示在螢幕上。 執行以下選擇查詢以檢視 Amazon MSK 資料:
SELECT Count(O.order_id) AS order_count,
C.cust_id,
C.NAME,
C.mktsegment
FROM customerkafka C
JOIN customersitekafka CS
ON C.cust_id = CS.cust_id
JOIN salesorderallkafka O
ON O.site_id = CS.site_id
GROUP BY C.cust_id,
C.NAME,
C.mktsegment;
此查詢連線三個流並聚合按每個客戶記錄分組的客戶訂單計數,幾秒鐘後會在終端中看到結果。 請注意終端輸出如何隨著 Flink 作業從源流中消耗更多事件而發生變化。
將結果寫入 Hudi 資料集
要擁有完整的管道,需要將結果寫到 Amazon S3 上的 Hudi 資料集。 為此請在查詢前面新增一個插入 CustomerHudi 語句:
INSERT INTO customerhudi
SELECT Count(O.order_id),
C.cust_id,
C.NAME,
C.mktsegment,
Proctime()
FROM customerkafka C
JOIN customersitekafka CS
ON C.cust_id = CS.cust_id
JOIN salesorderallkafka O
ON O.site_id = CS.site_id
GROUP BY C.cust_id,
C.NAME,
C.mktsegment;
這一次 sql-client提交作業後與叢集斷開連線,使用者端不必等待作業的結果,因為它會將結果寫入 Hudi 資料集。即使停止了 sql-client對談,該作業也會繼續在 Flink 叢集上執行。
等待幾分鐘,直到作業將 Hudi 提交紀錄檔檔案生成到 Amazon S3。然後導航到為 CustomerHudi 表指定的 Amazon S3 中的位置,其中包含按 MKTSEGMENT 列分割區的 Hudi 資料集。在每個分割區中,您還可以找到 Hudi 提交紀錄檔檔案。這是因為表型別定義為 MERGE_ON_READ。在此模式下使用預設設定,Hudi 會在出現五個 delta 提交紀錄檔後將提交紀錄檔合併到更大的 Parquet 檔案中。可以通過將表型別更改為 COPY_ON_WRITE 或指定自定義壓縮設定來更改此設定。
查詢 Hudi 資料集
可以使用 Hudi Flink 聯結器作為源聯結器來讀取儲存在 Amazon S3 上的 Hudi 資料集。為此可以針對 CustomerHudi 表執行 select 語句,或者使用為聯結器指定的 hudi 建立一個新表。該路徑必須指向 Amazon S3 上現有 Hudi 資料集的位置。將 S3URI OF HUDI DATASET LOCATION 替換並執行以下命令以建立新表:
CREATE TABLE `CustomerHudiReadonly` (
`_hoodie_commit_time` string,
`_hoodie_commit_seqno` string,
`_hoodie_record_key` string,
`order_count` BIGINT,
`customer_id` BIGINT,
`name` STRING,
`mktsegment` STRING,
`ts` TIMESTAMP(3),
PRIMARY KEY (`customer_id`) NOT Enforced
)
PARTITIONED BY (`mktsegment`)
WITH (
'connector' = 'hudi',
'hoodie.datasource.query.type' = 'snapshot',
'path' = '<S3URI OF HUDI DATASET LOCATION>',
'table.type' = 'MERGE_ON_READ' -- MERGE_ON_READ table or, by default is COPY_ON_WRITE
);
請注意以 _hoodie_為字首的附加列名,這些列是 Hudi 在寫入過程中新增的,用於維護每條記錄的後設資料。另請注意在表定義的 WITH 部分中傳遞的額外"hoodie.datasource.query.type"讀取設定,這可確保從 Hudi 資料集的實時檢視中讀取資料。執行以下命令:
select * from CustomerHudiReadonly where customer_id <= 5;
終端會在 30 秒內顯示結果。導航到 Flink Web 介面可以在其中觀察由 select 查詢啟動的新 Flink 作業(有關如何找到 Flink Web 介面,請參見下文)。它掃描 Hudi 資料集中已提交的檔案,並將結果返回給 Flink SQL 使用者端。
使用 mysql CLI或其他 IDE 連線到託管在 Aurora MySQL 上的 salesdb 資料庫。針對 SALES_ORDER_ALL表執行一些插入語句:
insert into SALES_ORDER_ALL values (29001, 2, now(), 'STANDARD');
insert into SALES_ORDER_ALL values (29002, 2, now(), 'TWO-DAY');
insert into SALES_ORDER_ALL values (29003, 2, now(), 'STANDARD');
insert into SALES_ORDER_ALL values (29004, 2, now(), 'TWO-DAY');
insert into SALES_ORDER_ALL values (29005, 2, now(), 'STANDARD');
幾秒鐘後一個新的提交紀錄檔檔案會出現在 Amazon S3 上的 Hudi 資料集中。 Debezium for MySQL Kafka 聯結器捕獲更改併為 MSK 主題生成事件。 Flink 應用程式使用來自主題的新事件並相應地更新 customer_count 列。然後它將更改的記錄傳送到 Hudi 聯結器以與 Hudi 資料集合並。
Hudi 支援不同的寫操作型別。預設操作是 upsert,它最初在資料集中插入記錄。當具有現有鍵的記錄到達流程時,它被視為更新。此操作在希望將資料集與源資料庫同步且不希望出現重複記錄的情況下很有用。
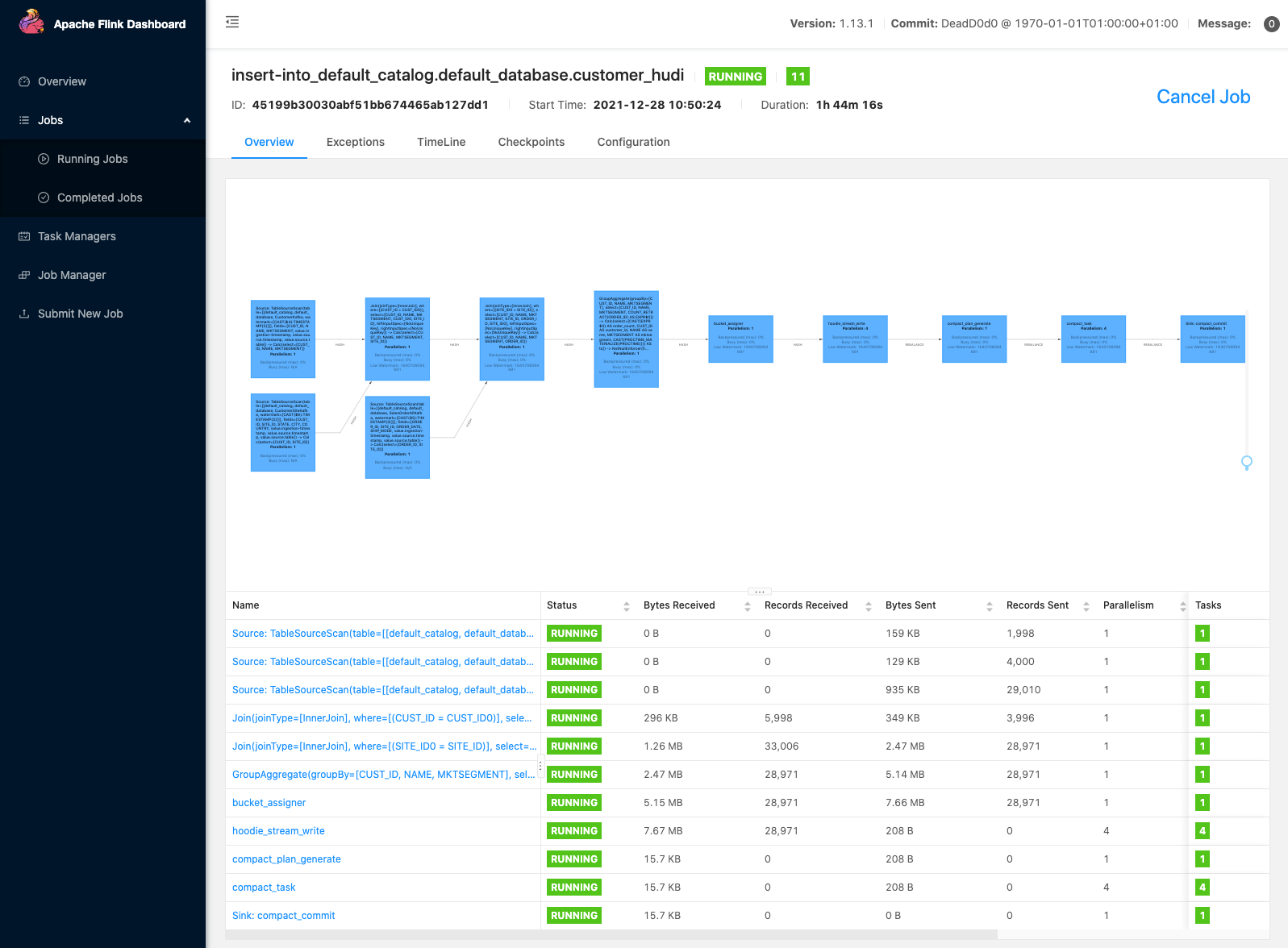
Flink web介面
Flink Web 介面可幫助您檢視 Flink 作業的設定、圖表、狀態、異常錯誤、資源利用率等。要存取它首先需要在瀏覽器中設定 SSH 隧道並啟用代理,以連線到 YARN 資源管理器。連線到資源管理器後,選擇託管 Flink 對談的 YARN 應用程式。選擇 Tracking UI 列下的連結以導航到 Flink Web 介面。
將管道部署到生產環境
對於實驗、開發或測試資料管道來說,使用 Flink sql-client以互動方式快速構建資料管道,這是一個不錯的選擇。但是對於生產環境,建議將 SQL 指令碼嵌入 Flink Java 應用程式並在 Amazon Kinesis Data Analytics 上執行。 Kinesis Data Analytics 是用於執行 Flink 應用程式的完全託管服務;它具有內建的自動擴充套件和容錯功能,可為生產應用程式提供所需的可用性和可延伸性。GitHub 上提供了一個 Flink Hudi 應用程式,其中包含這篇文章中的指令碼,使用者可以存取此儲存庫,並比較在 sql-client和 Kinesis Data Analytics中執行之間的差異。
清理
為避免產生持續費用,請完成以下清理步驟:
- 停止 EMR 叢集
- 刪除 MSK Connect Lab 設定建立的 AWS CloudFormation
結論
構建資料湖是打破資料孤島和執行分析以從所有資料中獲取洞察力的第一步。在資料湖上的事務資料庫和資料檔案之間同步資料並非易事,而且需要大量工作。在 Hudi 新增對 Flink SQL API 的支援之前,Hudi 客戶必須具備編寫 Apache Spark 程式碼並在 AWS Glue 或 Amazon EMR 上執行它的必要技能。在這篇文章中展示了一種新方法,可以使用 SQL 查詢以互動方式探索流服務中的資料,並加快資料管道的開發過程。
PS:如果您覺得閱讀本文對您有幫助,請點一下「推薦」按鈕,您的「推薦」,將會是我不竭的動力!
作者:leesf 掌控之中,才會成功;掌控之外,註定失敗。
出處:http://www.cnblogs.com/leesf456/
本文版權歸作者和部落格園共有,歡迎轉載,但未經作者同意必須保留此段宣告,且在文章頁面明顯位置給出原文連線,否則保留追究法律責任的權利。
如果覺得本文對您有幫助,您可以請我喝杯咖啡!

