HBase概念入門
HBase簡介
HBase基於Google的BigTable論文而來,是一個分散式海量列式非關係型資料庫系統,可以提供大規模資料集的實時隨機讀寫。
下面通過一個小場景認識HBase儲存。同樣的一個資料
用Mysql儲存是這樣的:
| id | name | age | salary | job |
|---|---|---|---|---|
| 1 | 小明 | 23 | 學生 | |
| 2 | 小紅 | 1000 | 律師 |
如果是HBase的話,儲存是類似這樣列式儲存的:
| field1 | filed2 |
|---|---|
| rowkey:1 | name:小明 |
| rowkey:1 | age:23 |
| rowkey:1 | job:學生 |
| rowkey:2 | name:小紅 |
| rowkey:2 | salary:1000 |
| rowkey:2 | job:律師 |
HBase這樣儲存的優點是:
- 有空值欄位的情況下,能減少儲存空間佔用
- 支援好多列
HBase的特點
- 海量儲存:底層基於HDFS儲存海量資料
- 列式儲存:HBase表的資料是基於列族進行儲存的,一個列族包含若干列
- 極易擴充套件:底層依賴HDFS,當磁碟空間不足的時候,只需要動態新增DataNode服務節點就行了
- 高並行:支援高並行的讀寫請求
- 稀疏性:稀疏主要是針對HBase列的靈活性,在列族中,你可以指定任意多的列,在列資料為空的情況下,是不會佔用儲存空間的。
- 資料的多版本:HBase表中的資料可以有多個版本值,預設情況下是根據版本號取區分,版本號就是插入資料的時間戳
- 資料型別單一:所有的資料在HBase中是以位元組陣列進行儲存
HBase的應用
- 交通方面:船隻GPS資訊,每天都有成千上萬的資料儲存
- 金融方面:消費資訊、貸款資訊、信用卡還款資訊
- 電商方面:電商網站的交易資訊、物流資訊、遊覽資訊等
- 電信、移動等:通話資訊
HBase的缺點
- HBase的有效性存在一定的問題,叢集中一個節點宕機,這個節點的資料暫時就不能存取了,需要等待一定的時間進行同步處理。
- HBase的監控粒度太粗
- 查詢簡單,只能根據key掃描一條資訊或者全部掃描
- 不支援交叉表、事務、連線查詢
總結:HBase適合海量明細資料的儲存,並且後期能有很好的查詢效能(單表超千萬、上億,且並行要求高)
HBase資料模型
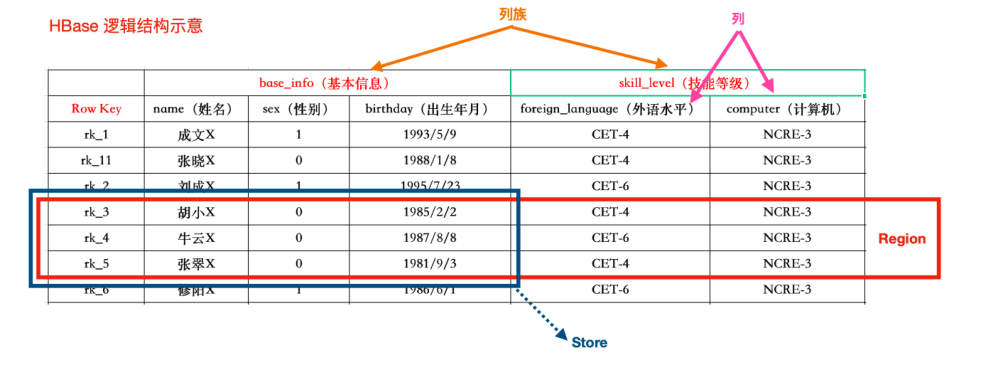
HBase邏輯結構
HBase物理儲存

HBase儲存的時候是以列族為單位進行儲存的。
HBase模型描述
- NameSpace
名稱空間,類似於關係型資料庫的database概念。每個namespace下有多個表。HBase兩個自帶的namespace,分別是hbase和default,hbase中存放的是HBase內建的表,default表是使用者預設使用的namespace。一個表可以自由選擇是否有namespace,如果建立表的時候加了namespace,這個表名字以:作為區分
- Table
類似於關係型資料庫的表的概念。不同的是,HBase定義表時只需要宣告列族即可,資料屬性:如超時時間、壓縮演演算法等,都在列族的定義中定義,不需要宣告具體的列
- Row
HBase表中的每行資料都由一個RowKey和多個Column列組成。一個行包含了多個列,這些列通過列族來分類,行中的資料所屬列族只能從表所定義的列族中選取
- RowKey
Rowkey由使用者指定的一串不重複的字串定義,是一行的唯一標識。資料是按照Rowkey的字典順序儲存的,並且查詢資料時只能根據Rowkey進行檢索,所以Rowkey的設計十分重要。如果使用了之前已經定義的RowKey,那麼會將之前的資料更新掉
- Column Family(列族)
列族是多個列的集合,一個列族可以動態靈活的定義多個列。表的相關屬性大部分都定義在列族上,同一個表裡的不同列族可以有完全不同的屬性設定,但是同一個列族內的所有列都會有相同的屬性。列族存在的意義是HBase會把相同列族的列儘量放在同一臺機器上。
- Column Wualifier(列)
HBase中的列是可以隨意定義的,一個行中的列不限名字、不限數量、只限定列族。因此列必須依賴於列族存在。列的名稱前必須帶著所屬的列族
- TimeStamp(版本)
用於標識資料的不同版本,時間戳預設由系統指定,也可以使用者顯式指定。在讀取資料的單元格時,版本號可以忽略,如果不指定,HBase預設會獲取最後一個版本的資料返回
- Cell
一個列中可以儲存多個版本的資料。而每個版本就稱為一個單元格
- Region
HBase 將表中的資料基於RowKey的不同範圍劃分到不同Region上,每個Region都負責一定範圍的資料儲存和存取。每個表一開始只有一個Region,隨著資料不斷插入表,Region不斷增大,當增大到一個閥值的時候,Region就會等分成兩個新的Region。當table中的行不斷增多,就會有越來越多的Region。
HBase整體架構
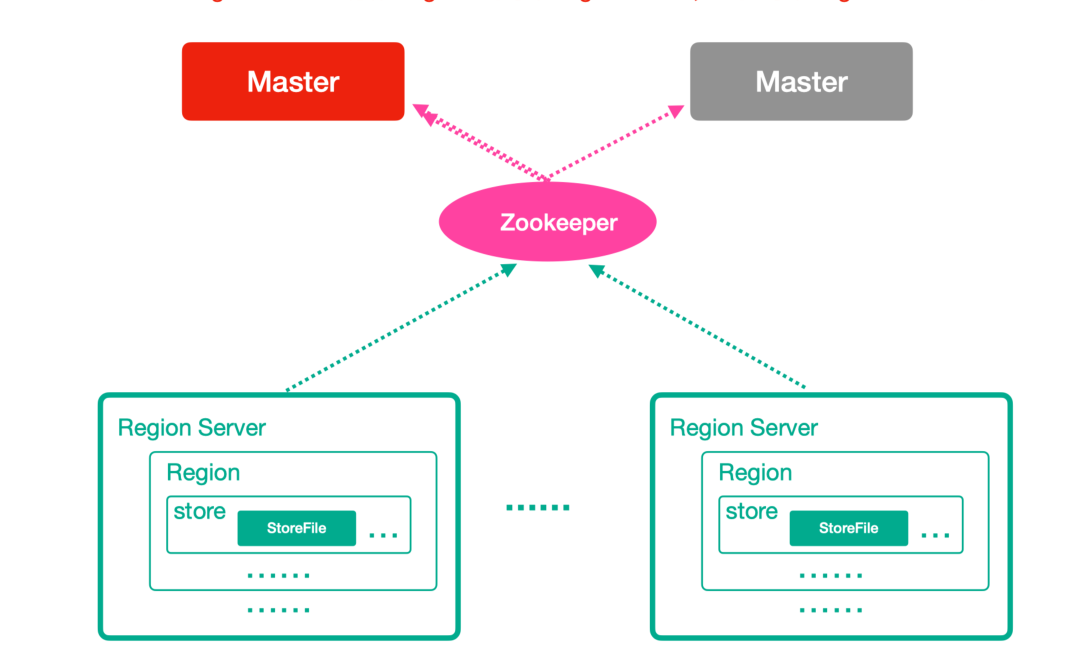
-
Zookeeper
- 實現了HMaster的高可用,儲存了HBase的後設資料資訊,是所有HBase表的定址入口
- 對HMaster和HRegionServer實現了監控
-
HMaster(Master)
- 為HRegionServer分配Region
- 維護整個叢集的負載均衡
- 發現失效的Region,並將失效的Region分配到正常的HRegionServer上
-
HRegionServer(RegionServer)
- 負責管理Region
- 接受使用者端的讀寫資料請求
- 切分在執行過程中變大的Region
-
Region
- 每個HRegion由多個Store構成
- 每個Store儲存一個列族,表有幾個列族,則有幾個Store
- 每個Store由一個MemStore和多個StoreFile組成,MemStore是Store在記憶體中的內容,寫到檔案後就是StoreFile。StoreFile底層就是以HFile的格式儲存。