字首樹的設計與實現
字首樹的設計與實現
作者:Grey
原文地址:
字首樹即字典樹,可以利用字串的公共字首來減少查詢時間,最大限度地減少無謂的字串比較。
我們使用搜尋引擎的時候,輸入 test,後面會自動顯示一堆字首是 test 的東西。這就利用了字首樹結構來實現。
比如我們有一堆字串
["Trie","apple", "insert","apple", "search", "app","search", "startsWith", "insert", "search"]
問題1.查詢字串列表裡面是否有以app,apx為字首的字串。
問題2.查詢字串列表裡面有沒有insert和serac這兩個字串。
我們可以把字串列表構造成一棵字首樹,如下圖
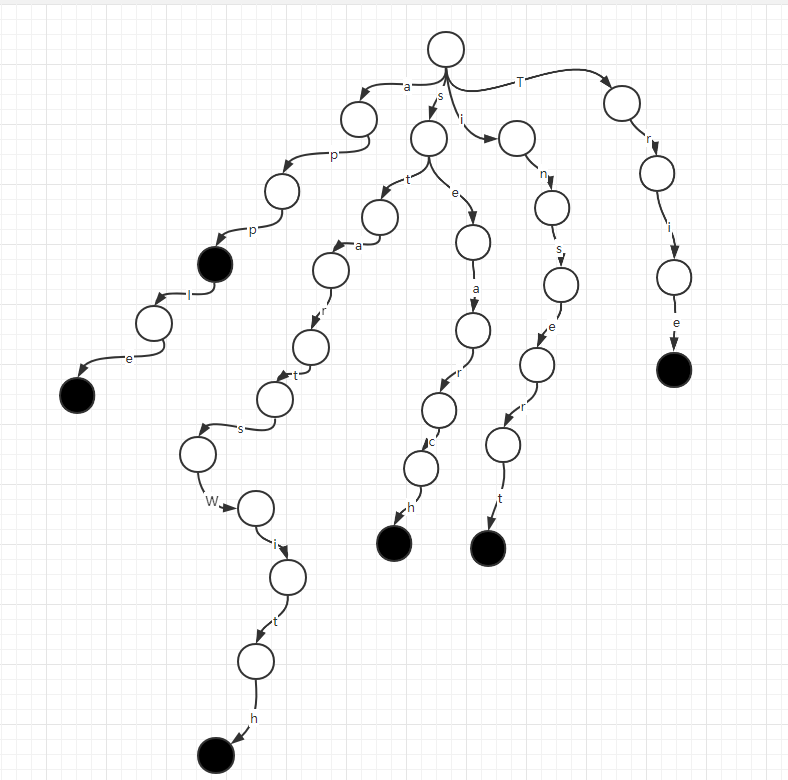
頭節點是空串,路徑表示字元,節點表示一個字串的字首(簡稱 p 節點),黑色節點表示一個字串的結尾位置(簡稱 e 節點)。
有了如上結構,針對問題1,判斷是否存在app字首的字串,流程如下
頭節點開始,先看有沒有走向a的路徑,有,則移動指標往a的路徑走,
然後判斷是否有走向p的路徑,有,則移動指標往p的路徑走,
然後判斷是否有走向p的路徑,有,則移動指標往p的路徑走,
則存在以app為字首的字串。
同理,回到頭節點,繼續判斷apx,發現到沒有到x的路徑,則直接返回不存在以apx為字首的字串。
針對問題2,判斷是否有insert這個字串,流程和判斷字首的流程一樣,只不過到了末尾位置,判斷是否是黑色節點,如果是黑色節點,說明存在這樣的字串,否則不存在。
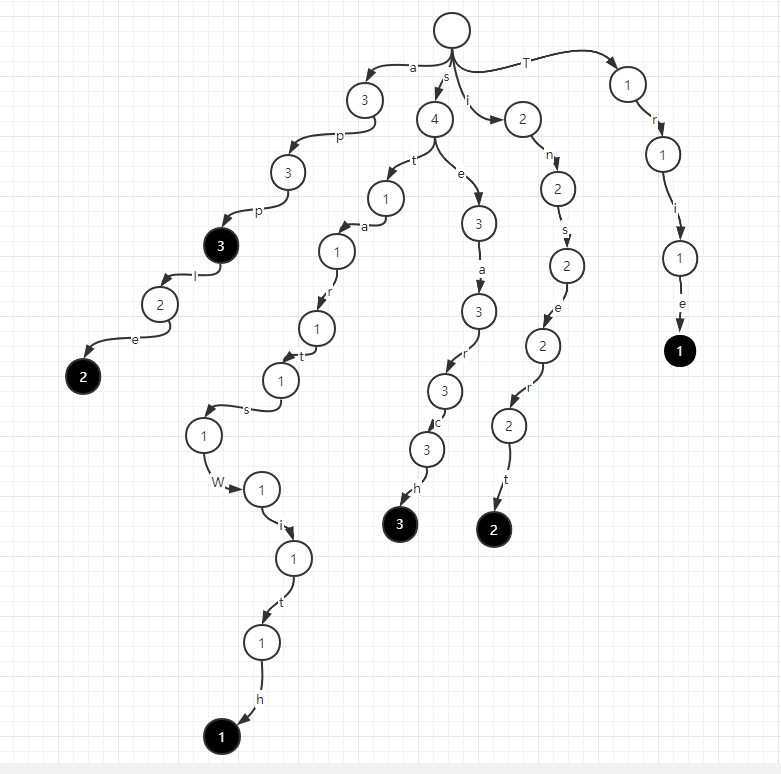
更進一步,字首樹也可以支援加入元素和刪除元素,此時,我們需要在 p 節點和 e 節點記錄一個出現次數的資訊,如上例,記錄次數後,字首樹如下圖
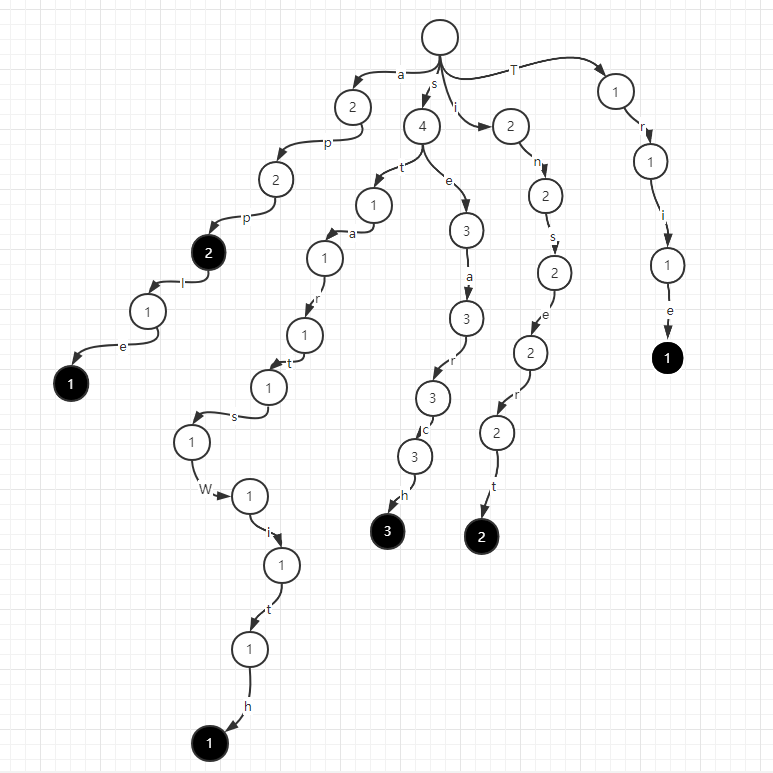
如果要刪除一個apple字串,字首樹在apple的路徑上依次減一即可
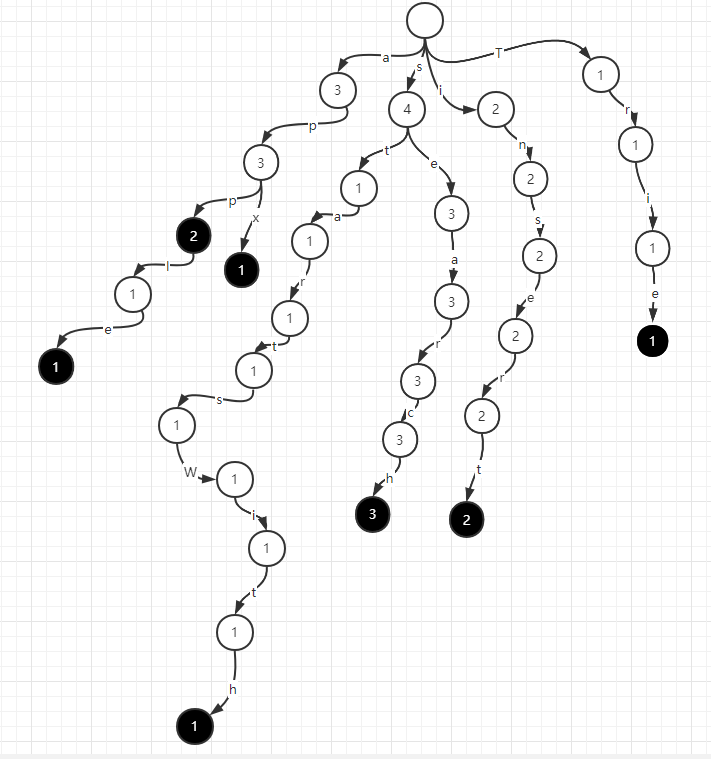
如果要繼續增加一個apx字串,字首樹繼續建出apx的路徑即可。
依據上述流程,我們可以用 Hash 表實現字首樹,程式碼如下
import java.util.HashMap;
public class Code_0030_TrieTree {
public static class Node2 {
// 某個節點經歷了幾次
public int pass;
// 某個節點是否是結尾位置
public int end;
// 是否有走向某個節點的路
public HashMap<Integer, Node2> nexts;
public Node2() {
pass = 0;
end = 0;
nexts = new HashMap<>();
}
}
public static class Trie2 {
private Node2 root;
public Trie2() {
root = new Node2();
}
public void insert(String word) {
if (word == null || word.length() < 1) {
return;
}
char[] str = word.toCharArray();
Node2 cur = root;
cur.pass++;
int n = 0;
for (char v : str) {
n = v;
if (!cur.nexts.containsKey(n)) {
cur.nexts.put(n, new Node2());
}
cur.nexts.get(n).pass++;
cur = cur.nexts.get(n);
}
cur.end++;
}
public void delete(String word) {
if (search(word) == 0) {
return;
}
char[] str = word.toCharArray();
Node2 cur = root;
cur.pass--;
for (char v : str) {
int n = v;
if (--cur.nexts.get(n).pass == 0) {
cur.nexts.remove(n);
return;
}
cur = cur.nexts.get(n);
}
cur.end--;
}
// word這個單詞之前加入過幾次
public int search(String word) {
if (word == null || word.length() < 1) {
return 0;
}
char[] str = word.toCharArray();
Node2 cur = root;
for (char v : str) {
int n = v;
if (!cur.nexts.containsKey(n)) {
return 0;
}
cur = cur.nexts.get(n);
}
return cur.end;
}
// 所有加入的字串中,有幾個是以pre這個字串作為字首的
public int prefixNumber(String pre) {
if (pre == null || pre.length() < 1) {
return 0;
}
char[] str = pre.toCharArray();
Node2 cur = root;
for (char v : str) {
int n = v;
if (!cur.nexts.containsKey(n)) {
return 0;
}
cur = cur.nexts.get(n);
}
return cur.pass;
}
}
}
如果字串只由 26 個英文字母組成,那麼字首樹的資料結構可以優化成
class Node {
int p;
int e;
Node[] nodes = new Node[26];
}
nodes[0] != null:表示有走向a的路,否則則沒有走向a的路;
nodes[1] != null:表示有走向b的路,否則則沒有走向b的路;
nodes[2] != null:表示有走向c的路,否則則沒有走向c的路;
...
nodes[25] != null:表示有走向z的路,否則則沒有走向z的路;
LeetCode 有對應的題目連結:見:LeetCode 208. Implement Trie (Prefix Tree)
完整程式碼如下
class Trie {
class Node {
int p;
int e;
Node[] nodes = new Node[26];
}
Node root;
public Trie() {
root = new Node();
}
public void insert(String word) {
char[] str = word.toCharArray();
Node cur = root;
for (char c : str) {
cur.p++;
if (cur.nodes[c - 'a'] == null) {
cur.nodes[c - 'a'] = new Node();
}
cur = cur.nodes[c - 'a'];
}
cur.e++;
}
public boolean search(String word) {
char[] str = word.toCharArray();
Node cur = root;
for (char c : str) {
if (cur.nodes[c - 'a'] == null) {
return false;
}
cur = cur.nodes[c - 'a'];
}
return cur.e != 0;
}
public boolean startsWith(String prefix) {
char[] str = prefix.toCharArray();
Node cur = root;
for (char c : str) {
if (cur.nodes[c - 'a'] == null) {
return false;
}
cur = cur.nodes[c - 'a'];
}
return true;
}
}
本文的所有圖例見: processon:字首樹的設計和實現
更多
本文來自部落格園,作者:Grey Zeng,轉載請註明原文連結:https://www.cnblogs.com/greyzeng/p/16647565.html