從原理剖析帶你理解Stream
摘要:Stream是jdk1.8給我們提供的新特性
本文分享自華為雲社群《深入理解Stream之原理剖析》,作者: 李哥技術 。
Stream是jdk1.8給我們提供的新特性,主要就是允許我們採用宣告式的方式處理資料集合,我們要知道在專案中我們集合就是我們最常用的資料儲存結構,有時後我們需要對集合內的元素做一些過濾或者其他的操作我們一般是採用for迴圈的方式。
Stream操作分類

Stream中的操作可以分為兩大類:中間操作與結束操作。
中間操作只會進行操作記錄,只有結束操作才會觸發實際的計算,可以理解為懶載入,這也是Stream在操作大物件迭代計算的時候如此高效的原因之一。
中間操作分為有狀態操作與無狀態操作,無狀態是指元素的處理不受之前元素的影響,有狀態是指該操作只有拿到所有元素之後才能繼續下去。這也比較好理解,比如有狀態的distinct()去重方法,你說他能不關心其他值嗎?當然不能,他必須拿到所有元素才知道當前迭代的元素是否被重複。
結束操作可以分為短路與非短路操作,這個應該很好理解,短路是指遇到某些符合條件的元素就可以得到最終結果;而非短路是指必須處理所有元素才能得到最終結果。
之所以要進行如此精細的劃分,是因為底層對每一種情況的處理方式不同。
Stream結構分析
讓我們先簡單看看下面一段程式碼:
List<String> list = new ArrayList<>(); // 獲取stream1 Stream<String> stream1 = list.stream(); // stream1通過filter後得到stream2 Stream<String> stream2 = stream1.filter("lige"::equals); // stream1與stream2是同一個物件嗎? System.out.println("stream1.equals(stream2) = " + stream1.equals(stream2)); System.out.println("stream1.classTypeName = " + stream1.getClass().getTypeName()); System.out.println("stream2.classTypeName = " + stream2.getClass().getTypeName()); // 結果 // stream1.equals(stream2) = false // stream1.classTypeName = java.util.stream.ReferencePipeline$Head // stream1.classTypeName = java.util.stream.ReferencePipeline$2
很明顯,stream1與stream2不是同一個物件,並且他們不是同一個實現類。stream1的實現類為ReferencePipeline$Head,而stream2的實現類為一個匿名內部類,讓我們進步一分析其原始碼,所謂原始碼之下,無所遁形。
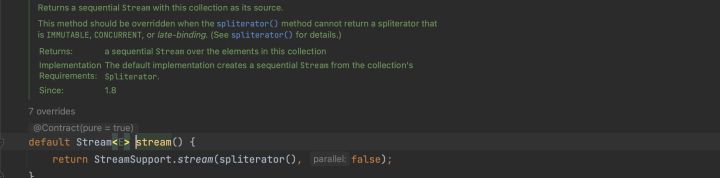
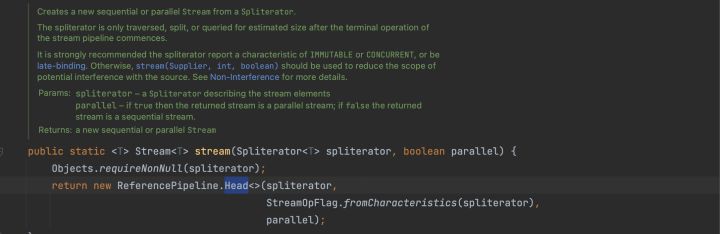

讓我們再看看stream2:

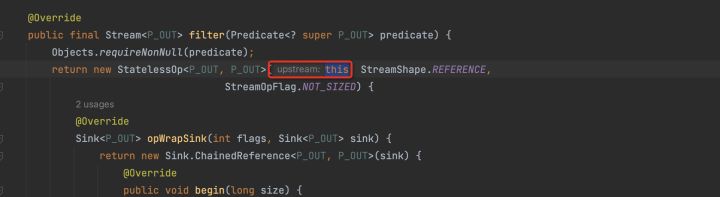
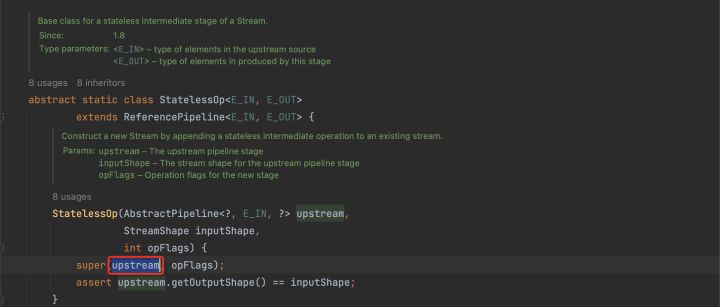
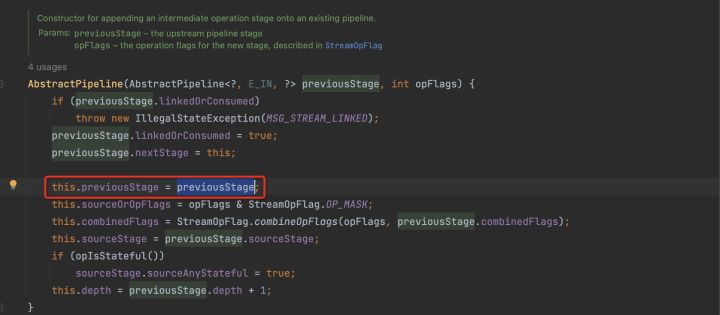
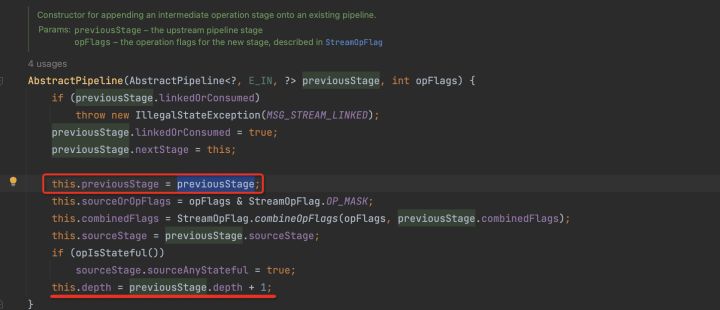
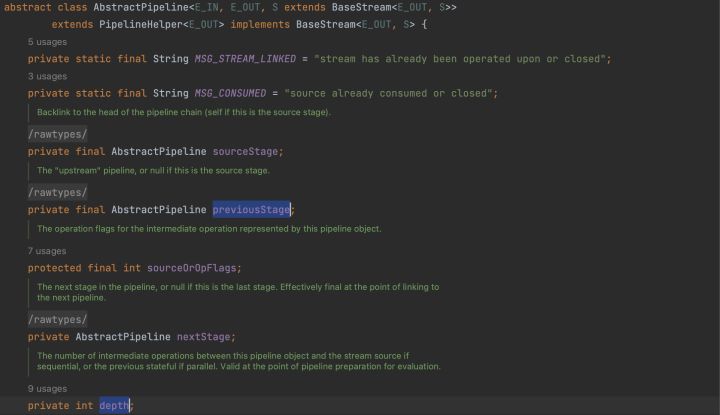
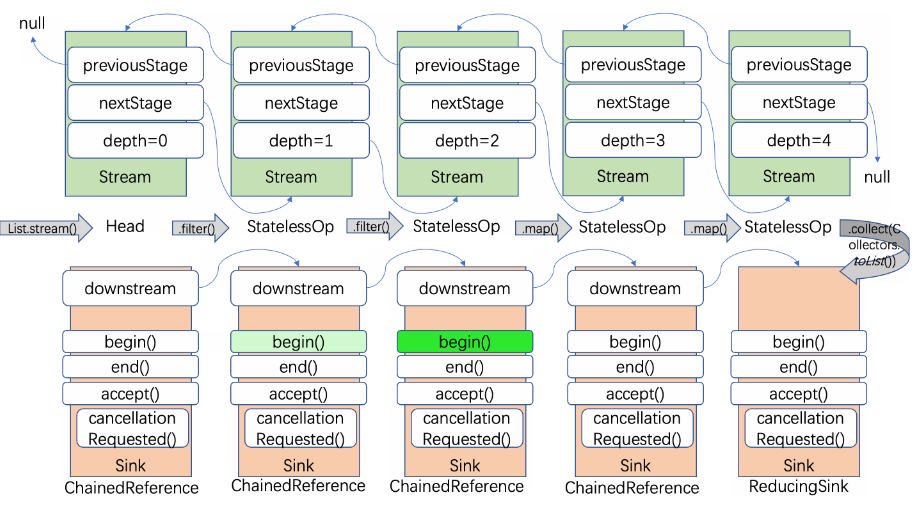
通過分析我們可以發現,stream2的實現類是StatelessOp,所以就形成了這樣一個結構。

每一次中間操作都會生成一個新的Stream,如果是無狀態操作則實現類是StatelessOp,如果是有狀態操作則實現類是StatefulOp。
讓我們再來看一下他們之間的繼承關係。
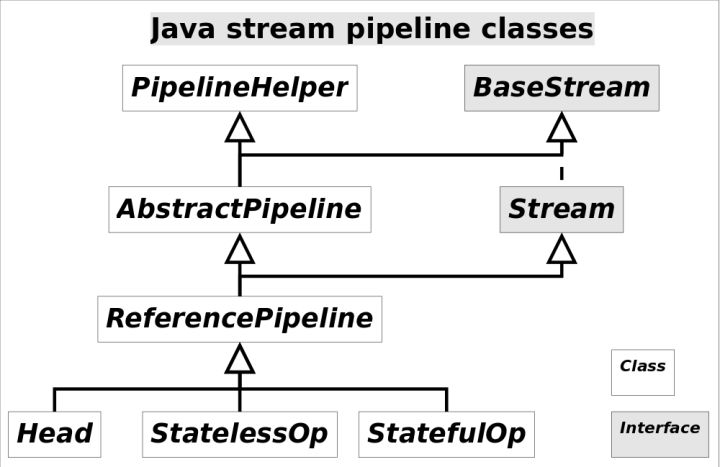

再聊核心Sink
實際上Stream API內部實現的的本質,就是如何過載Sink的這四個介面方法。
我還是從一個範例開始:
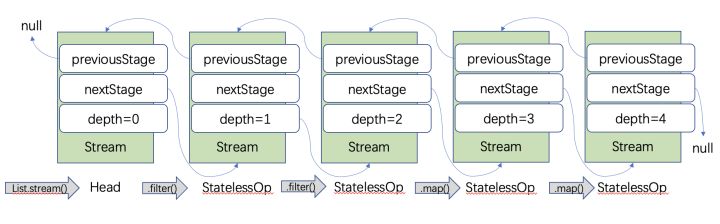
List<String> list = new ArrayList<>(); list.add("zhangsan"); list.add("ligeligeligeligeligeligeligeligeligelige"); list.add("lisilisilisilisilisilisilisilisi"); list.add("wangwu"); list.add("ligejishuligejishuligejishuligejishuligejishuligejishuligejishu"); List<String> resultList = list.stream() .filter(it -> it.contains("li"))// 1. 只要包含li的資料 .filter(it -> it.contains("lige"))// 2. 只要包含lige的資料 .map(String::toUpperCase)// 3. 對符合的資料作進一步加工,轉換大寫 .map(String::toLowerCase)// 4. 對符合的資料作進一步加工,轉換小寫 .collect(Collectors.toList()); resultList.forEach(System.out::println);
不管是filter方法,還是map方法,還是其他的方法,我們進入到原始碼層面,返回了一個StatelessOp物件或StatefulOp物件。
所以便產生了這樣一個結構:
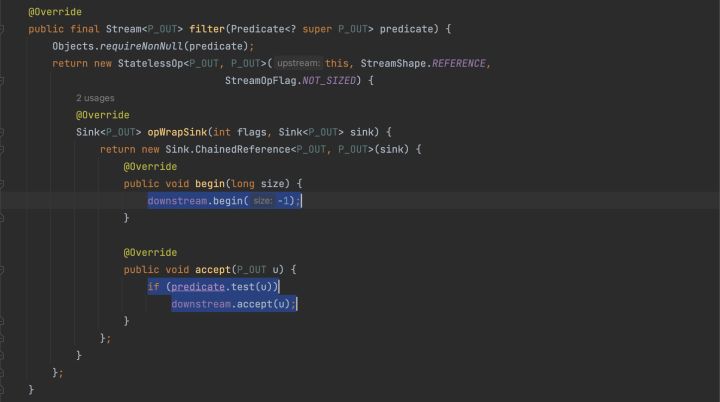
但是和Sink有什麼關係呢?我們再反過來看filter或者map原始碼:
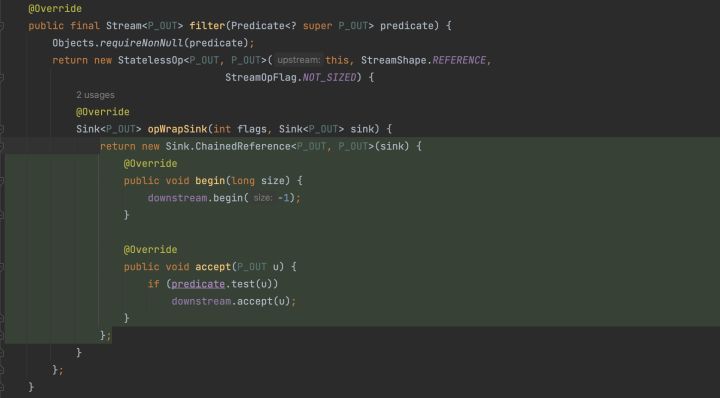
直接返回一個匿名StatelessOp物件,實現opWrapSink方法,opWrapSink方法是傳入一個sink物件,返回另一個sink物件。而新的sink物件擁有傳入sink物件的參照。
但是,這個程式碼有什麼用?什麼時候觸發的呢?
彆著急,讓我們從collect(Collectors.toList())方法開始一步一步深入研究。

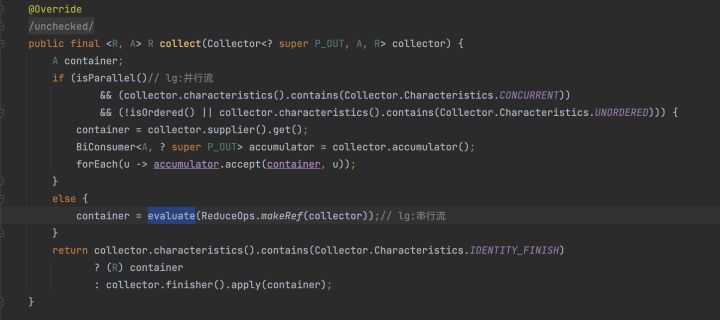
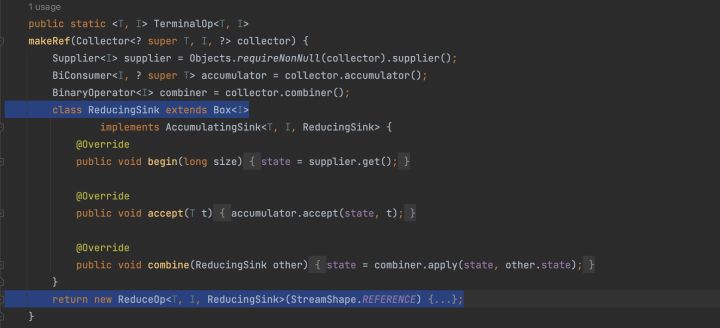
這裡我們需要知道傳入xx方法的終端物件是ReduceOp,並且這個ReduceOp物件在makeSink的時候返回了一個匿名內部類ReducingSink物件。
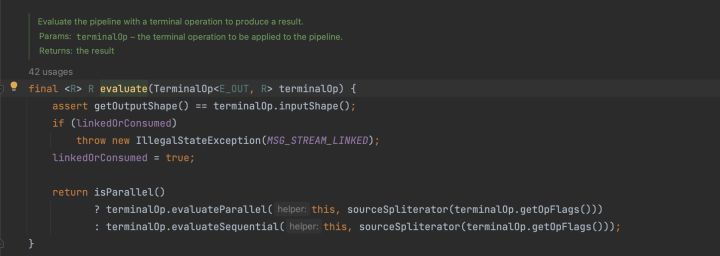
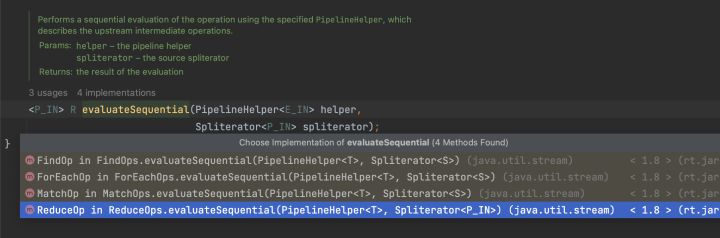

這裡的makeSink我們提到過,返回一個匿名內部類ReducingSink物件。

先執行warpSink,再執行copyInto。直白一點就是先對Sink進行包裝成鏈式Sink,再遍歷Sink鏈進行copy到結果物件裡。這裡的兩個步驟都很核心。
先看warpSink:
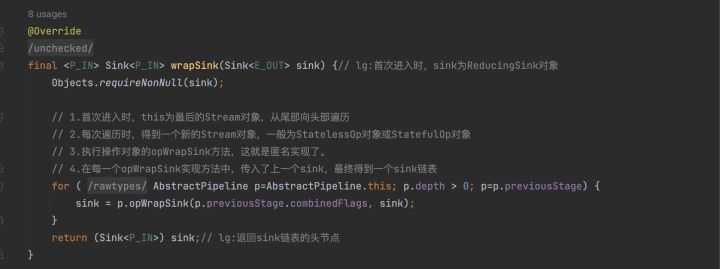
- 首次進入時,this為最後的Stream物件,從尾部向頭部遍歷
- 每次遍歷時,得到一個新的Stream物件,一般為StatelessOp物件或StatefulOp物件
- 執行操作物件的opWrapSink方法,這就是匿名實現了。
- 在每一個opWrapSink實現方法中,傳入了上一個sink,最終得到一個sink連結串列
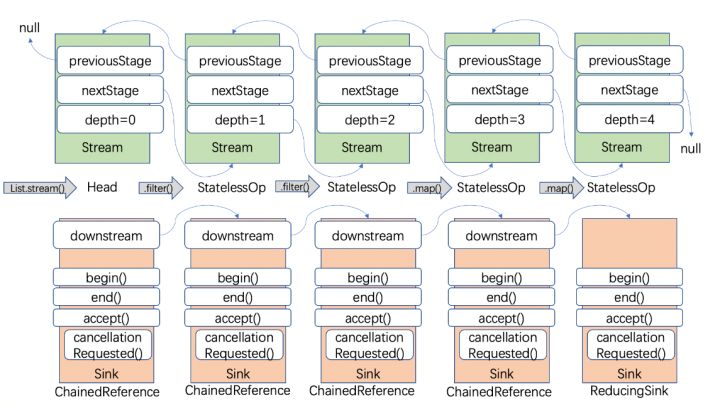
最後,返回Sink鏈的頭節點,內部稱之為包裝好的sink,命名wrapped,隨後,準備進行執行begin,forEachRemaining,end方法。
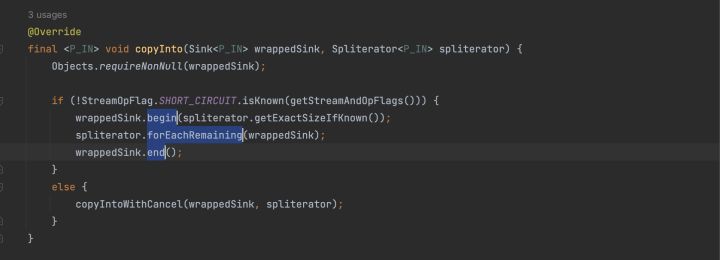
forEachRemaning最終呼叫accept方法。
動畫理解Stream執行流程