虛擬機器器記憶體管理之記憶體分配器
2022-09-01 18:02:15
小編:本文由 WebInfra 團隊姚忠孝、楊文明、張地編寫。意在通過深入剖析常用的記憶體分配器的關鍵實現,以理解虛擬機器器動態記憶體管理的設計哲學,併為實現虛擬機器器高效的記憶體管理提供指引。
在現代電腦架構中,記憶體是系統核心資源之一。虛擬機器器( VM )作為執行程式的抽象"計算機",記憶體管理是其不可或缺的能力,其中主要包括如記憶體分配、垃圾回收等,而其中記憶體分配器又是決定"計算機"記憶體模型,以及高效記憶體分配和回收的關鍵元件。
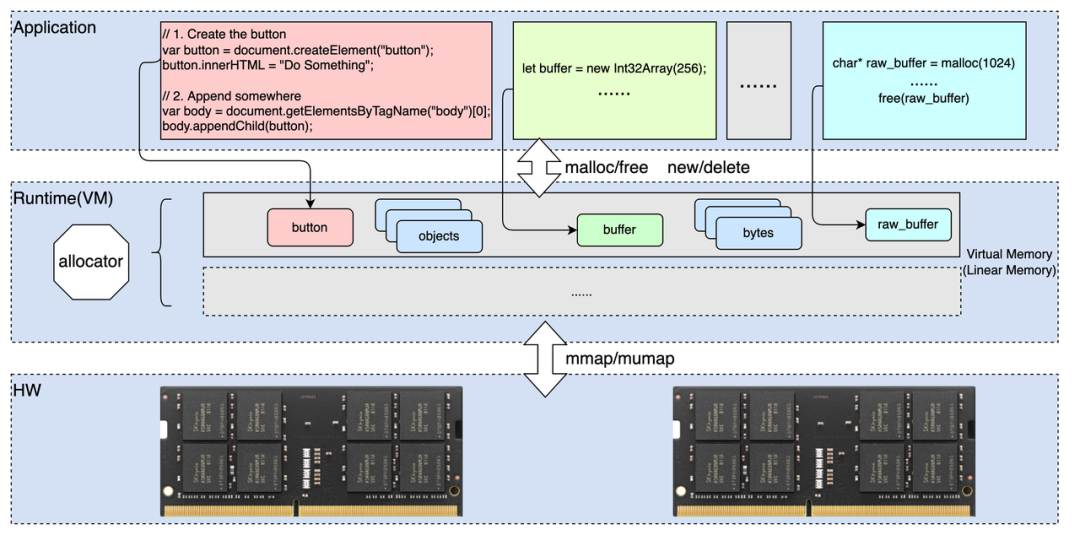
如上圖所示,各種程式設計都提供了動態分配記憶體物件的能力,例如建立瀏覽器 Dom 物件,建立 Javascript 的記憶體陣列物件( Array Buffer 等),以及面向系統程式設計的 C / C++ 中的動態分配的記憶體等。在應用開發者角度看,通過語言或者庫提供的動態記憶體管理(分配,釋放)的介面就是實現物件記憶體的分配和回收,而不需要關心底層的具體實現,例如,所分配物件的實際記憶體大小,物件在記憶體中的位置排布(物件地址),可以用於分配的記憶體區域,物件何時被回收,如何處理多執行緒情況下的記憶體分配等等;而對於虛擬機器器或者 Runtime 的開發者來說,高效的記憶體分配和回收管理是其核心任務之一,並且記憶體分配器的主要目標包括如下幾方面:
1. 減少記憶體碎片,包括內部碎片和外部碎片
-
內部碎片:分配出去的但沒有使用到的記憶體,比如需要 32 位元組,分配了 40 位元組,多餘的 8 位元組就是內部碎片。
-
外部碎片:大小不合適導致無法分配出去的記憶體,比如一直申請 16 位元組的記憶體,但是記憶體分配器中儲存著部分 8 位元組的記憶體,一直分配不出去。
2. 提高效能
記憶體分配需要通過核心分配虛擬地址空間和實體記憶體,頻繁的系統呼叫和多執行緒競爭顯著的降低了記憶體分配的效能。記憶體分配器通過接管記憶體的分配和回收,無論在單執行緒還是多執行緒場景下都可以很好的起到提升效能的作用。
3. 提高安全性
隨著系統和應用對安全性的關注度提升,預設的記憶體分配機制無論在記憶體資料佈局,還是對硬體安全機制的使用上都無法最大化的滿足應用訴求,因此自定義記憶體分配器可以針對特定的系統和應用充分的利用硬體安全機制( MTE )等,同時也能夠在實際系統中引入記憶體安全性檢測機制來進一步提升安全性。
-
檢測線性溢位, UAF 等多種記憶體非法存取異常
-
記憶體加固(地址隨機化, MTE , etc .)
因此,本文通過深入分析常用的記憶體分配器的關鍵實現( dlmalloc , jemalloc , scudo , partition-alloc ),來更好的理解背後的設計考量和設計哲學,以為我們實現高效,輕量的執行時和虛擬機器器記憶體分配器,記憶體管理模型提供指引。
1. dlmalloc [1]
* Key Points ( salient points )
-
從作業系統分配( sbrk , mmap )一大塊記憶體 " Segment " ( N * page_size ),多個 Segment 通過連結串列相互連線," Segment "可以為不同大小。
-
每次申請記憶體,從 Segment 中分配一塊記憶體" chunk "的記憶體地址(如果當前 Segment 不滿足分配需求,進入步驟 a. 從作業系統分配 Segment )," chunk "可以為不同大小。
-
dlmalloc 中切分出的各中大小的 chunk 需要通過" bin "來統一管理," Bin "用於記錄最近釋放的可重複使用的塊(快取)。有兩種型別的 Bin :" small bin "和「 tee bin 」。Small bins 用於小於 0x100 位元組的塊。每個 small bin 都包含相同大小的塊。" tree bin "用於較大的塊,幷包含給定大小範圍的塊。" small bin "被實現為簡單的雙向連結串列," tree bin "被實現 chunk 大小為 key 的 tries 樹。
實際的記憶體分配需要按照所申請的記憶體大小分別處理,如下所述:
-
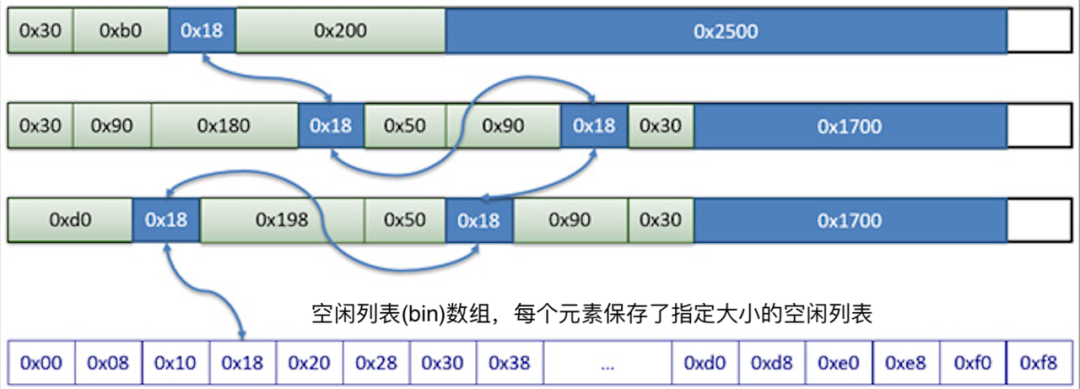
小記憶體( Small < 0x100 bytes )
小記憶體通過空閒連結串列管理空閒記憶體的使用狀態;下圖是某一時刻可能的記憶體快照情況,每個記憶體大小( size )都可作為空閒連結串列陣列的下標存取對應大小的空閒連結串列。
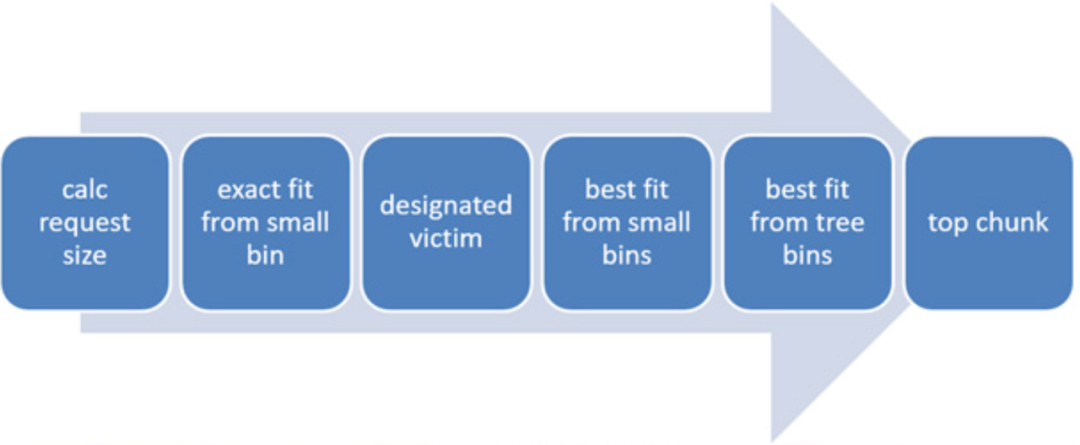
基於空閒連結串列維護的空閒記憶體狀態,採用如下的分配順序和分配策略進行實際記憶體分配。
-
大記憶體( Large )
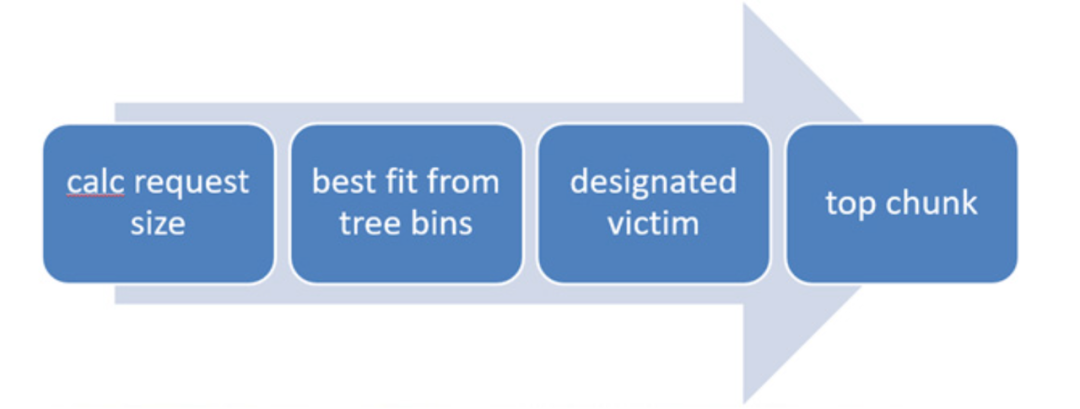
大記憶體不採用空閒連結串列陣列進行管理(虛擬機器器地址空間方範圍大,時間和空間效率均低),採用 trie-tree 作為大記憶體的狀態維護結構,每次記憶體分配和釋放在 trie-tree 上進行高效的搜尋和插入。
大記憶體採用如下的分配順序和分配策略進行實際記憶體分配。
-
超大記憶體( Huge ) > 64 kb
對於超大記憶體,直接通過 mmap 從作業系統分配記憶體。
* Weakness
-
dlmalloc 不是執行緒安全的,因此 bionic 已經切換到更現代的堆實現方案
-
典型的 Buddy memory allocation 演演算法,這種演演算法能夠有效減少外部碎片,但內部碎片嚴重。
2. jemalloc ( Android 5.0.0 ~ )
該記憶體管理器的主要目標是提升多執行緒記憶體使用的效能( efficiency 、 locality )和較少記憶體碎片(最大優勢是強大的多執行緒分配能力)
* Key Points ( salient points )
-
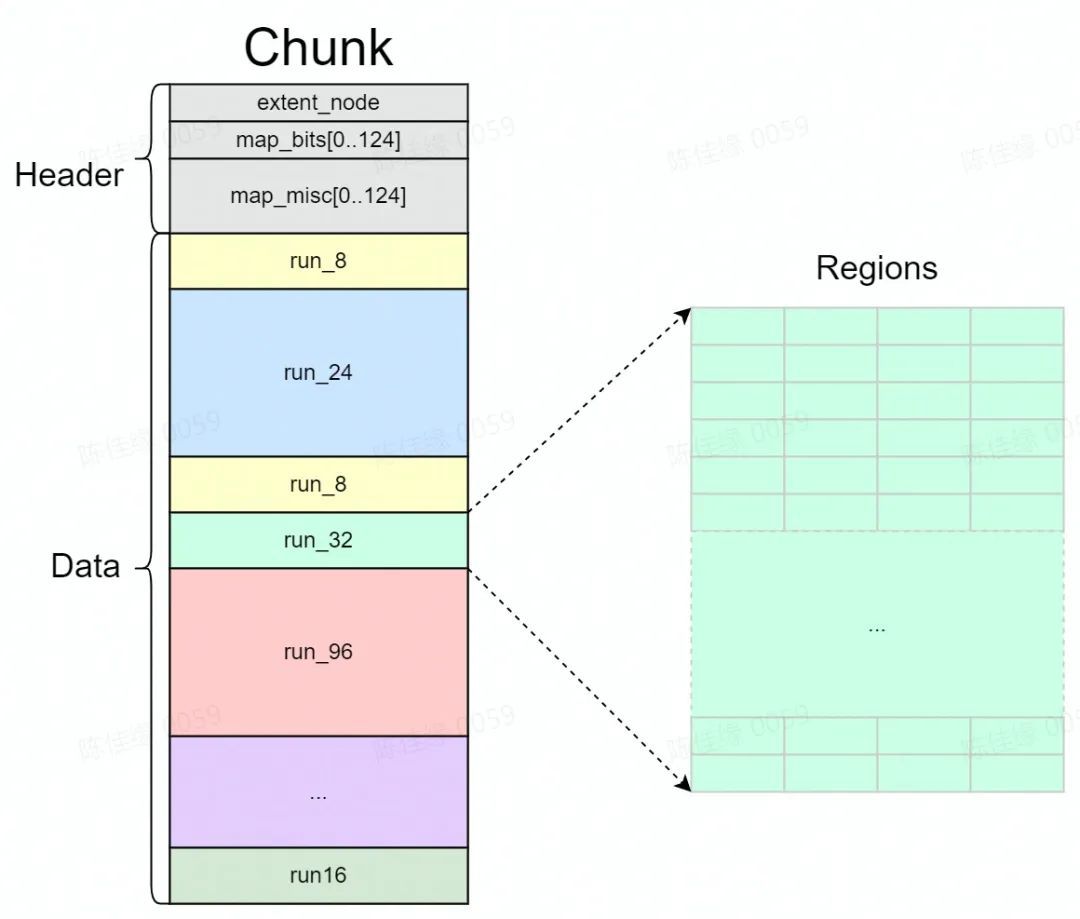
呼叫 mmap 從作業系統分配一整塊大記憶體 " Chunk ", Chunk 為固定大小( 512k ),可以被分割成兩部分:頭資訊區域和資料區域。資料區域被分割成若干個 Run 。
-
在 Chunk 的資料區中一個或者多個頁會被分成一個組,用於提供特定大小的記憶體分配,被稱為" Run "(相同大小記憶體所在的頁組),相同大小 Region 對應的 Run 屬於同一個 Bin ( bucket )進行管理(如下圖所示)。
-
" Run "中的記憶體會被切分為固定小的記憶體塊" Region ",作為最小的記憶體分配單元,作為實際記憶體地址返回給記憶體分配申請。
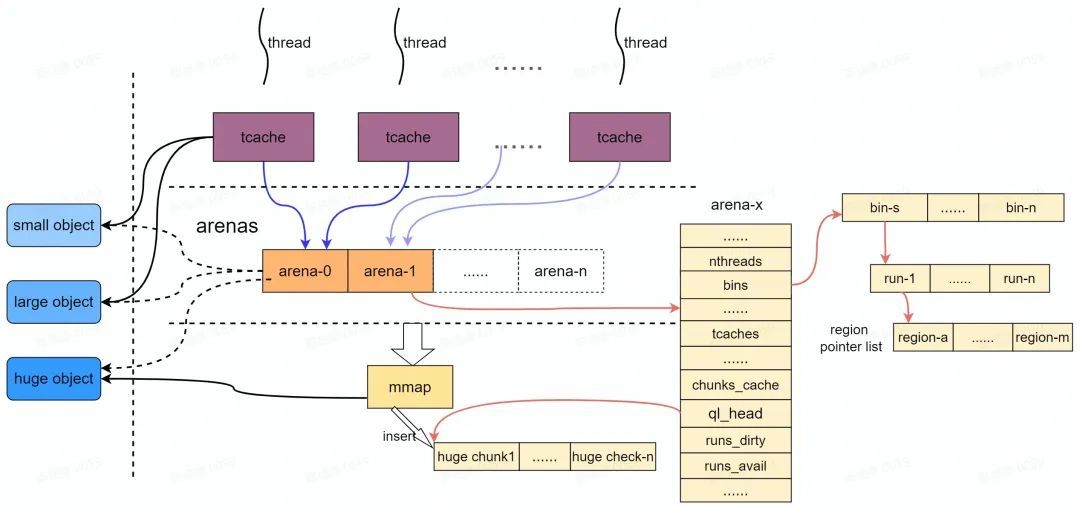
上圖展示了記憶體分配的主要流程及資料結構。 jemalloc 通過 areans 進行記憶體統一記憶體分配和回收, 由於兩個arena在地址空間上幾乎不存在任何聯絡, 就可以在無鎖的狀態下完成分配。同樣由於空間不連續, 落到同一個 cache-line 中的機率也很小, 保證了各自獨立。理想情況下每個執行緒由一個 arena 負責其記憶體的分配和回收,由於 arena 的數量有限, 因此不能保證所有執行緒都能獨佔 arena , Android 系統中預設採用兩個 arena ,因此會採用負載均衡演演算法( round-robin )實現執行緒到 arena 的均衡分配並通過內部的 lock 保持同步。
多個執行緒可能共用同一個 arena , jemalloc 為了進一步避免分配記憶體時出現多執行緒競爭鎖,因此為每個執行緒建立一個 " tcache ",專門用於當前執行緒的記憶體申請。每次申請釋放記憶體時, jemalloc 會使用對應的執行緒從 tcache 中進行記憶體分配(其實就是 Thread Local 空閒連結串列)。
每個執行緒內部的記憶體分配按如下3種不同大小的記憶體請求分別處理:
-
小物件( Small Object ) 根據 Small Object 物件大小,從 Run 中的指定 " region " 返回。
-
大物件( Large Object ) Large Object 大小比 chunk 小,比 page 大,會單獨返回一個 " Run "(1或多個 page 組成)。
-
超大物件( Huge Object ) > 4 MB huge object 的記憶體直接採用 mmap 從 system memory 中申請(獨立" Chunk "),並由一棵與 arena 獨立的紅黑樹進行管理。
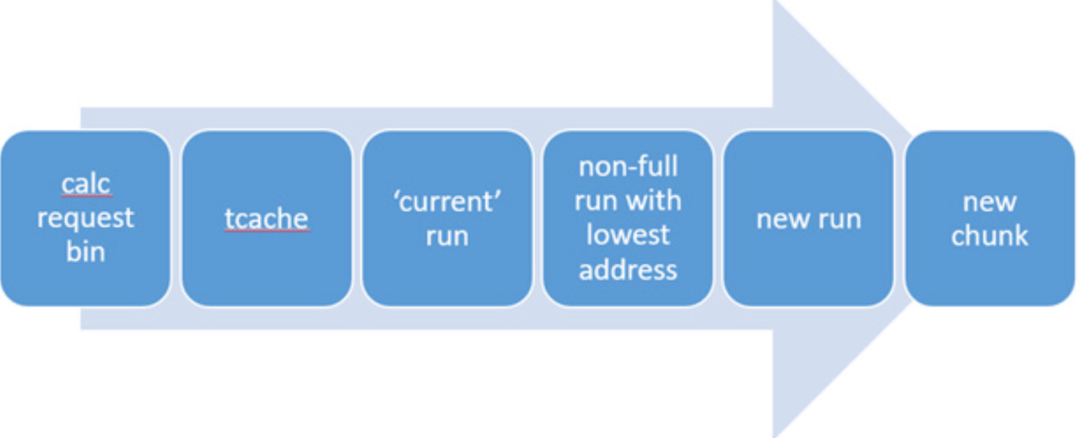
基於以上的核心資料結構,記憶體分配流程大致流程如下圖所示:
* Summary
-
jemalloc 的核心是一個基於桶分配器( bin )。每個 arena 都有一組邏輯 bin ,每個 bin 都服務於特定的尺寸等級。分配是從具有足夠大以適應分配請求的最小尺寸的 bin 進行的,它們之間的步長很小,可以減少碎片。
-
每個 arena 都有自己的鎖,所以不同 arena 上的操作不會爭搶鎖。
-
臨界區很短,僅當從 arena 中分配記憶體(共用 arena 執行緒間內部鎖),或者分配 runs 的時候才需要保持鎖定。
-
執行緒特定的記憶體快取進一步減小資料競爭。
3. scudo ( Android 11 ~)
Scudo 這個名字源自 Escudo ,在西班牙語和葡萄牙語中表示「盾牌」。為了安全性考慮,從 Android 11 版本開始,Scudo 會用於所有原生程式碼(低記憶體裝置除外,其仍使用 jemalloc )。在執行時,所有可執行檔案及其庫依賴項的所有原生堆分配和取消分配操作均由 Scudo 完成;如果在堆中檢測到損壞情況或可疑行為,該程序會中止。(以下內容以 Android-11 64位元系統實現為分析目標)
* Key Points ( salient points )
Scudo 定義了 Primary 和 Secondary 兩種型別分配器[4],當需求小於 max_class_size ( 64 k )時使用 Primary Allocator ,大於 max_class_size 時使用 Secondary Allocator 。
struct AndroidConfig {
using SizeClassMap = AndroidSizeClassMap;
#if SCUDO_CAN_USE_PRIMARY64
// 256MB regions
typedef SizeClassAllocator64<SizeClassMap, 28U, 1000, 1000,
/*MaySupportMemoryTagging=*/true>
Primary;
#else
// 256KB regions
typedef SizeClassAllocator32<SizeClassMap, 18U, 1000, 1000> Primary;
#endif
// Cache blocks up to 2MB
typedef MapAllocator<MapAllocatorCache<32U, 2UL << 20, 0, 1000>> Secondary;
template <class A>
using TSDRegistryT = TSDRegistrySharedT<A, 2U>; // Shared, max 2 TSDs.
};* Primary Allocator
Primary Allocator [5]首先會根據 AndroidSizeClassConfig [6]中的設定申請一個完整的虛擬記憶體空間,並將虛擬記憶體空間分成不同的區域( sizeClass ),每塊區域只能分配出固定空間,區域1只能分配32 bytes (包含 header ),區域2只能分配48 bytes 。
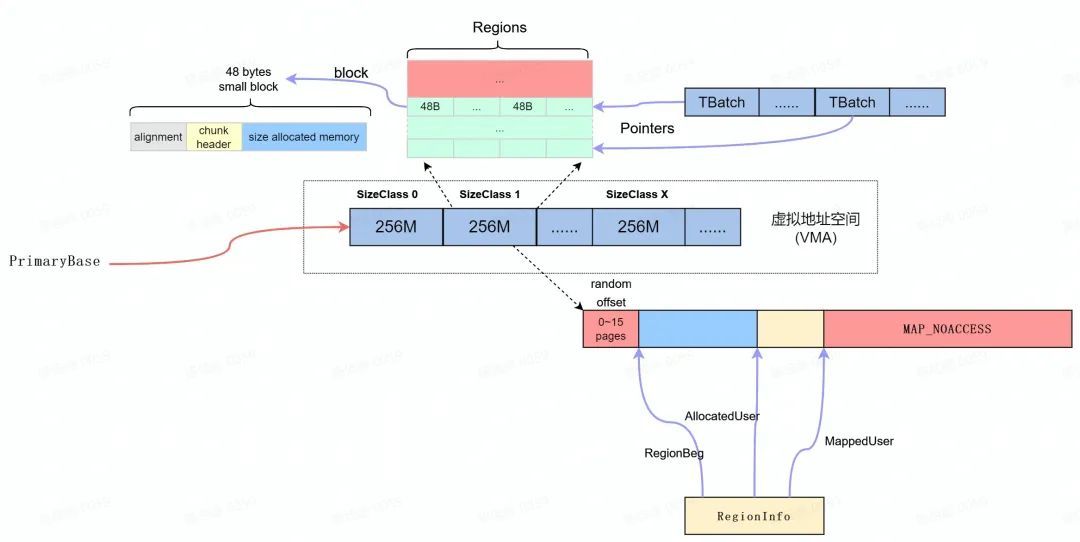
Primary Allocator 從作業系統申請" PrimaryBase "指向的虛擬記憶體區域後,按照如下的設定為虛擬記憶體區域劃分為 32 個 256 M 的記憶體區域( SizeClass )。
每個 SizeClass 提供特定大小的記憶體分配,其記憶體區域按照 RegionInfo 結構佈局,其中" randon offset "是0~16頁的隨機值,以使隨機化 ReginBeg 地址降低定向攻擊的風險。
每個 SizeClass 區域初始分配記憶體為 MAP_NOACCESS ,當收到記憶體分配請求時, ClassSize 會分配出一塊可用的記憶體區域( MappedUser ),並以 SizeClass 指定的 block 大小切分成可用使用的 Regions 。當進行 Regions 的分配的同時,每個可用的 Region 均通過 TranferBatch 進行管理( TBatch ), 這樣 TBatch 的連結串列就可以作為 FreeList 供記憶體分配使用。
為了安全性的考慮,最終返回的記憶體按照上圖" block "所示的記憶體佈局組織。其中" chunk-header "[7]是為了保證每一個 chunk 區域的完整性, Checksum 用的是較為簡單的CRC演演算法,此外,記憶體釋放過程中 Scudo 增加了 header 檢測機制,一方面可以檢測記憶體踩踏和多次釋放,另一方面也阻止了野指標的存取。
struct UnpackedHeader {
uptr ClassId : 8;
u8 State : 2;
u8 Origin : 2;
uptr SizeOrUnusedBytes : 20;
uptr Offset : 16;
uptr Checksum : 16;
};struct AndroidSizeClassConfig {
static const uptr NumBits = 7;
static const uptr MinSizeLog = 4;
static const uptr MidSizeLog = 6;
static const uptr MaxSizeLog = 16;
static const u32 MaxNumCachedHint = 14;
static const uptr MaxBytesCachedLog = 13;
static constexpr u32 Classes[] = {
0x00020, 0x00030, 0x00040, 0x00050, 0x00060, 0x00070, 0x00090, 0x000b0,
0x000c0, 0x000e0, 0x00120, 0x00160, 0x001c0, 0x00250, 0x00320, 0x00450,
0x00670, 0x00830, 0x00a10, 0x00c30, 0x01010, 0x01210, 0x01bd0, 0x02210,
0x02d90, 0x03790, 0x04010, 0x04810, 0x05a10, 0x07310, 0x08210, 0x10010,
};
static const uptr SizeDelta = 16;
};* Thread Local Cache
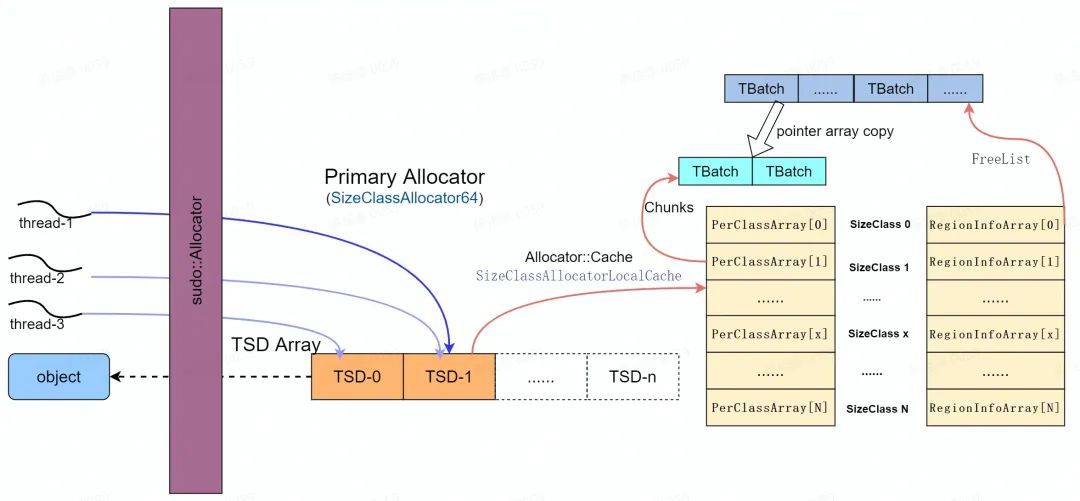
Scudo Primary Allocator 使用了 Thread Local Cache 機制來加速多執行緒下記憶體的分配,如下圖所示。當一個執行緒需要分配記憶體時,它會通過各自對應的 TSD ( Thead Specific Data )來發起物件的申請,每個 TSD 物件通過各自的 Allocator::Cache 及其 TransferBatch 來尋找合適的空閒記憶體。但 TransferBatch 的大小是有限的,如果沒有可用的記憶體會進一步利用 Primary Allocator 進行分配。
理想情況下每個執行緒由一個 TSD 負責其記憶體的分配和回收,由於 TSD 的數量有限, 因此不能保證所有執行緒都能獨佔 TSD , Android 系統中預設採用兩個 TSD ,因此會採用負載均衡演演算法( round-robin )實現執行緒到 arean 的均衡分配並通過內部的 lock 保持同步。
* Secondary Allocator
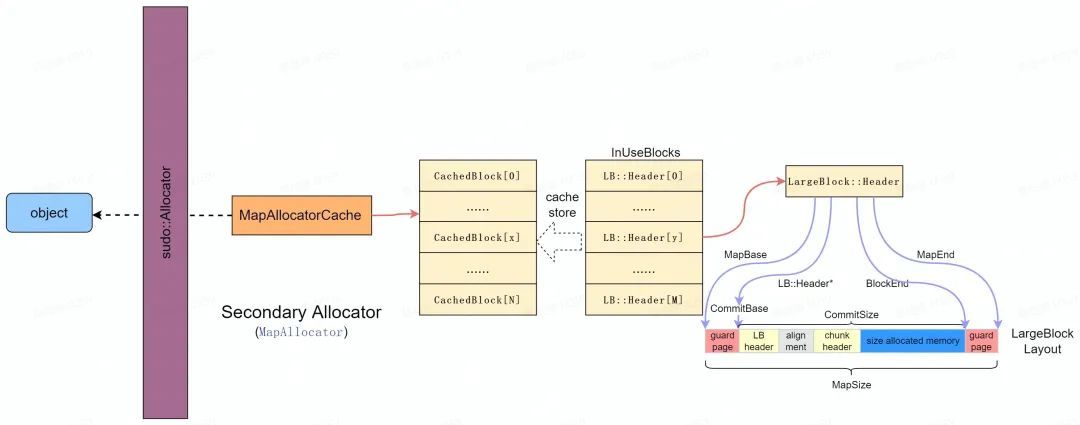
Secondary Allocator [8]主要用於大記憶體的分配(> max_size_class ),直接採用 mmap 分配出一塊滿足要求的記憶體並按照 LargeBlock::Header 進行組織, 並統一在 InUseBlocks 連結串列中統一管理,如下圖所示。
為了安全性考慮, LargeBlock 採用如下圖 LargeBlock Layout 進行組織,其中:
-
在 LargeBlock 的前後都增加了保護頁以檢測 heap-overflow 錯誤;
-
LargeBlock Header 域主要記錄了 LargeBlock 的記憶體佈局資訊以便於資料存取和管理;
-
剩餘記憶體結構和 small block 佈局一致,安全性考量和設計也一致(統一性)。
此外,為了提高效率效率, LargeBlock 在釋放的時候會通過 MapAllocatorCache 將可被複用的空閒記憶體進行快取,在大記憶體分配中優先從 Cache 中進行分配。其中 CachedBlock 和 LargeBlock::Header 基本一致,都是對 LargeBlock 記憶體佈局資訊的記錄和管理。
* Scudo記憶體分配和回收
Scudo Android R 記憶體分配核心流程如下所示。
NOINLINE void *allocate(uptr Size, Chunk::Origin Origin,
uptr Alignment = MinAlignment,
bool ZeroContents = false) {
initThreadMaybe(); // 初始化TSD Array 和 Primary SizeClass地址空間
// skip trivials.......
// If the requested size happens to be 0 (more common than you might think),
// allocate MinAlignment bytes on top of the header. Then add the extra
// bytes required to fulfill the alignment requirements: we allocate enough
// to be sure that there will be an address in the block that will satisfy
// the alignment.
const uptr NeededSize =
roundUpTo(Size, MinAlignment) +
((Alignment > MinAlignment) ? Alignment : Chunk::getHeaderSize());
// skip trivials.......
void *Block = nullptr;
uptr ClassId = 0;
uptr SecondaryBlockEnd;
if (LIKELY(PrimaryT::canAllocate(NeededSize))) {
// 從 Primary Allocator分配small object
ClassId = SizeClassMap::getClassIdBySize(NeededSize);
DCHECK_NE(ClassId, 0U);
bool UnlockRequired;
auto *TSD = TSDRegistry.getTSDAndLock(&UnlockRequired);
Block = TSD->Cache.allocate(ClassId);
// If the allocation failed, the most likely reason with a 32-bit primary
// is the region being full. In that event, retry in each successively
// larger class until it fits. If it fails to fit in the largest class,
// fallback to the Secondary.
if (UNLIKELY(!Block)) {
while (ClassId < SizeClassMap::LargestClassId) {
Block = TSD->Cache.allocate(++ClassId);
if (LIKELY(Block)) {
break;
}
}
if (UNLIKELY(!Block)) {
ClassId = 0;
}
}
if (UnlockRequired)
TSD->unlock();
}
// 如果分配的是大記憶體,或者Primary 無法分配小記憶體,
// 則直接在Secondary Allocator進行分配
if (UNLIKELY(ClassId == 0))
Block = Secondary.allocate(NeededSize, Alignment, &SecondaryBlockEnd,
ZeroContents);
// skip trivials.......
const uptr BlockUptr = reinterpret_cast<uptr>(Block);
const uptr UnalignedUserPtr = BlockUptr + Chunk::getHeaderSize();
const uptr UserPtr = roundUpTo(UnalignedUserPtr, Alignment);
void *Ptr = reinterpret_cast<void *>(UserPtr);
void *TaggedPtr = Ptr;
// skip trivials.......
// 根據返回記憶體地址,設定chunk-header物件資料
Chunk::UnpackedHeader Header = {};
if (UNLIKELY(UnalignedUserPtr != UserPtr)) {
const uptr Offset = UserPtr - UnalignedUserPtr;
DCHECK_GE(Offset, 2 * sizeof(u32));
// The BlockMarker has no security purpose, but is specifically meant for
// the chunk iteration function that can be used in debugging situations.
// It is the only situation where we have to locate the start of a chunk
// based on its block address.
reinterpret_cast<u32 *>(Block)[0] = BlockMarker;
reinterpret_cast<u32 *>(Block)[1] = static_cast<u32>(Offset);
Header.Offset = (Offset >> MinAlignmentLog) & Chunk::OffsetMask;
}
Header.ClassId = ClassId & Chunk::ClassIdMask;
Header.State = Chunk::State::Allocated;
Header.Origin = Origin & Chunk::OriginMask;
Header.SizeOrUnusedBytes =
(ClassId ? Size : SecondaryBlockEnd - (UserPtr + Size)) &
Chunk::SizeOrUnusedBytesMask;
// 設定chunk-header,CheckSum用於完整性校驗
Chunk::storeHeader(Cookie, Ptr, &Header);
// skip trivials.......
return TaggedPtr;
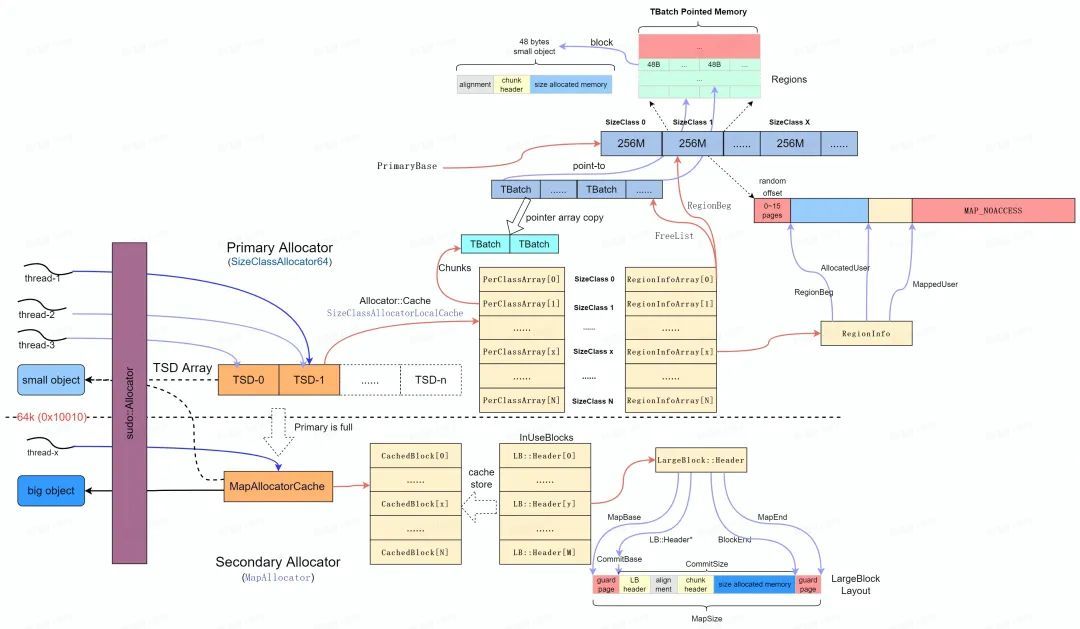
}以上程式碼包括的核心流程如下圖所示:
-
當有執行緒通過 malloc 請求記憶體分配時,會通過符號重定向呼叫 scudo::allocator 的 allocate 函數。
-
進入 allocate 函數後,首先呼叫初始化函數,以完成 TSD 和 Primary 虛擬地址空間初始化。
-
根據 malloc 記憶體 size 判定是否可以通過 Primary Allocator 進行分配。
-
如果 Primary Allocator 分配的記憶體符合要求,計算 malloc size 對應的 SizeClass ,當前執行緒採用 TSD 的 Allocator::Cache 分配記憶體, Allocator::Cache 為每個 SizeClass 維護了一個 TransferBatch 連結串列,其中 TransferBatch 中是指向實際 Block 區域的指標。
-
如果 Allocator::Cache 無法分配記憶體,那麼請求 Allocator 從對應 SizeClass 的 FreeList 中獲取記憶體並 refill 到 Allocator::Cache 中。
-
如果 FreeList 中沒有可用的記憶體, Allocator 需要從對應 SizeClass 的 class region 擴充空閒區域(調整MappedUser),並將記憶體區域切分為固定的 Block 大小,將可用的 Block 記憶體組織成 TransferBatch 新增到 FreeList ,並進一步 refill 到 Allocator::Cache 中供分配使用。
-
當我們分配小記憶體時,首先會檢查最合適區域中是否有空閒位置,如果沒有,則會去高一級區域中分配。例如在32 Bytes SizeClass Region 無法記憶體出記憶體,那麼會逐步嘗試從48 Bytes ,64 Bytes SizeClass Region 中進行分配(小記憶體區域耗盡)。
-
如果記憶體尚未分配成功,則採用 Secondary Allocator 繼續嘗試分配記憶體。
-
如果獲取了有效的記憶體地址,則根據返回記憶體地址,計算 CheckSum 並設定 chunk-header 物件資料。
-
將返回記憶體地址通過 malloc 返回。
以上介紹了記憶體分配的大致流程,記憶體釋放可以按照上述流程做反向資料流推演,不再詳細展開(對Quarantine的延遲釋放機制可以自行分析)。
* Summary
Scudo 雖然它的分配策略更加簡化,安全性上得到了很大的改進,但為了安全性引入 chunk header 等後設資料管理,記憶體隨機化和對齊引入記憶體碎片一定程度上降低了記憶體的使用效率;此外,基於 chunk header 的記憶體校驗以及記憶體安全性保障也一定程度上降低了效率(效能)。
-
記憶體
-
Primary Allocator 會在獨立劃分的一塊虛擬地址空間( RegionSize* ClassNums ~ 2G )中採用隨機化策略分配,為了安全性的同時引入了記憶體碎片。
-
Primary 分配的記憶體中, chunk header 記錄用於記憶體檢查的資訊,有效資料比例較低(特別是小記憶體物件,32 bytes 有效資料為 50% )。
-
Secondary 分配的記憶體區前後都有保護頁,記憶體空間使用率較低。
-
-
效能
-
執行期需要進行安全性檢測( heap-overflow etc .),完整性檢測( CheckSum )等安全策略,存在效能損失。
-
以上的分析主要參照了 Android R 中的實現,最初來源於 LLVM 中 scudo 的實現, LLVM 中有 scudo_allocator [9] 和 standalone [10] 2份實現,具體內容可以從[9][10]作為入口進行原始碼的分析。
4. PartitionAlloc
PartitionAlloc 是 Chromium 的跨平臺分配器,優化使用者端而不是伺服器工作負載的記憶體使用,並專注於有意義的終端使用者活動,而不是在實際使用中並不重要的微基準[16]。
-
統一跨平臺的記憶體分配,增強安全性。
-
在不影響安全性和效能的前提下,降低碎片,減少記憶體佔用。
-
客製化分配器以優化 Chrome 的效能。
* Key Points ( salient points )
* Central Partition Allocator [16]
PartitionAlloc 通過分割區( Partition )來隔離各記憶體區域。其中每個分割區都使用基於 slab 的分配器來分配記憶體, PartitionAlloc 預先保留" Super Page "作為分割區虛擬地址空間( Slab )。每個"Super Page"( Slab )按照實際可分配的最小記憶體單元大小( Slot )分成各自獨立的" Slot Span ",每個 Slot Span 包含多個 Partition Page 並歸屬於特定的桶( Partiton Bucket )用於提供中小記憶體的分配。
PartitionAlloc 針對大記憶體分配(> kMaxBucketed )是通過直接記憶體對映( direct map )實現的(特殊的 bucket 管理),為了保證和小記憶體分配結構上的統一性,直接記憶體對映記憶體結構採用(偽裝)和小記憶體分配類似的 Super Page 進行管理,並且保留了類似的記憶體佈局佈局(如下圖所示)。
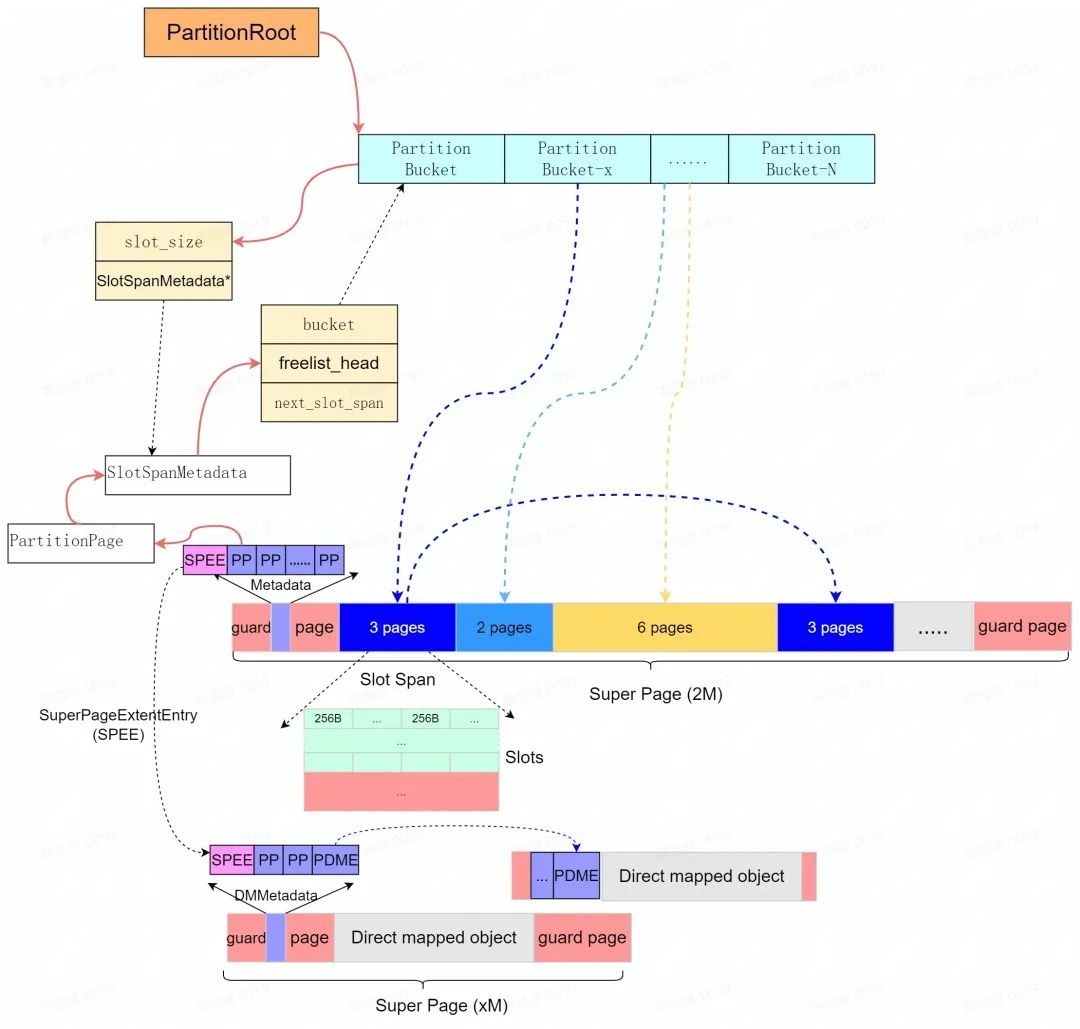
如上圖所示, PartitionAlloc 中每個分割區的記憶體通過一個 PartitionRoot 進行管理," PartitionRoot "中維護了一個 Bucket 陣列;每個 Bucket 維護了" slot span "的集合;隨著分配請求的到來, slot span 逐漸得到實體記憶體( Commit ),並按照所關聯桶的可分配記憶體的大小,將實體記憶體切分為 slot 的連續記憶體區域。PartitionAlloc 除了支援多個獨立的分割區來提升安全性外;每個" Super Page "被分割成多個" Partition Page ",其中第一個和最後一個" Partition-Page "主要作為保護頁使用( PROT_NONE )。( Super Page 選擇 2 MB 是因為 PTE 在 ARM 、 ia 32 和 x 64上對應的虛擬地址是2 M )。
* Partition Layer
PartitionAlloc 雖然通過分割區來隔離各區域,但在同一分割區內多執行緒存取受單個分割區鎖的保護。為了緩解多執行緒的資料競爭和擴充套件性問題,採用如下三層架構來提高效能:
-
Per-thread cache
為了緩解多執行緒記憶體分配的資料競爭問題,每個執行緒的資料快取區( TLS )儲存了少量用於常用中小記憶體分配的 Slots 。因為這些 Slots 是按執行緒儲存的,所以可以在沒有鎖的情況下分配它們,並且只需要更快的執行緒本地儲存查詢,從而提高程序中的快取區域性性。每個執行緒的快取已經過客製化以滿足大多數請求,通過批次分配和釋放第二層的記憶體,分期鎖獲取,並在不捕獲過多記憶體的情況下進一步改善區域性性。
-
Slot span free-list
Slot span free-lists 在每執行緒快取未命中時呼叫。對於每個對應的 bucket size,PartitionAlloc 維護與該大小相關聯的 Slot Span ,並從 Slot Span 的空閒列表中獲取一個空閒 Slot 。這仍然是一條快速路徑( fast path ),但比每執行緒快取慢,因為它需要鎖定。但是,此部分僅適用於每個執行緒快取不支援的較大分配,或者作為填充每個執行緒快取的批次處理。
-
Slot span management
最後,如果桶中沒有空閒的 slot ,那麼 Slot span management 要麼從 Super Page ( slab )中挖出空間用於新的slot span,要麼從作業系統分配一個全新的Super Page ( slab )。這是一條慢速路徑( slow path ),很慢但非常不經常操作。
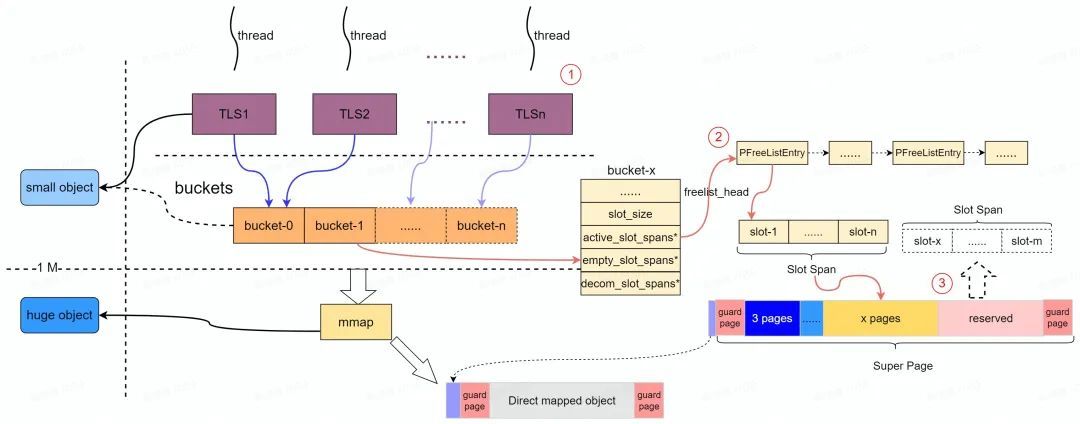
以上簡單介紹了 PartitionAlloc 中分割區的關鍵結構, PartitionAlloc 在 Chromium 中主要維護了四個分割區,針對每種分配器的用途採取不同的優化方案,並根據實際物件的型別在四個分割區中任意一個上分配物件。
-
Buffer 分割區:主要分配變長物件或者是內容可能會被使用者指令碼篡改的物件,如 Vector 、 HashTable 、 ArrayBufferContent 、 String 等容器類物件;
-
Node分割區(之前版本叫 model object 分割區):主要分配 dom 節點物件,通過重寫 Noded 的 new / delete 運運算元實現;
-
LayoutObject 分割區:主要分配 layou 相關物件,如 LayoutObject 、 PaintLayer 、雙向字型 BidiCharacterRun 等物件;
-
FastMalloc 分割區:主要分配除其他三種型別之外的物件(通用物件分配器),大量功能邏輯的內部物件都歸於此分割區;
PartitionAlloc 在 Node 分割區和 LayoutObject 分割區上分配時不會獲取鎖,因為它保證 Node 和 LayoutObject 僅由主執行緒分配。PartitionAlloc 在 Buffer 分割區和 FastMalloc 分割區上分配時獲取鎖。PartitionAlloc 使用自旋鎖以提高效能。
* 安全性
安全因素的考慮也是PartitionAlloc最重要的目標之一,這裡利用虛擬地址空間來達到安全加固的目的:不同的分割區存在於隔離的地址空間;當某個分割區記憶體頁上所有物件都被釋放掉之後,其實體記憶體歸還於系統後,但其地址空間仍被此分割區保留,這樣就保證了此地址空間只能被此分割區重用,從而避免了資訊洩露;PartitionAlloc的記憶體佈局,提供了以下安全屬性:
-
線性溢位不會破壞分割區 - guard page。
-
後設資料記錄在專用區域(不是每個物件旁邊)。線性上溢或下溢不會破壞後設資料。
-
大記憶體分配在開始和結束時被保護分頁 - guard page。
-
桶有助於在不同地址上分配不同大小的物件。一頁只能包含類似大小的物件。
* Summary
傳統記憶體分配器( jemalloc , etc.)呼叫 malloc 為物件分配記憶體時,無法指定分配器將在哪裡儲存什麼樣的資料,並且無法指定要儲存它的位置。C++ 類物件可能緊挨著包含金鑰的字串,該金鑰可能與函數指標的結構相鄰。在所有這些資料之間是分配器用來管理堆的後設資料(通常為雙向連結串列和標誌儲存的指標),這為漏洞尋找要覆蓋的資料目標時為他提供了更多選擇。例如,當利用釋放後使用漏洞時,我們希望將型別 B 的物件放置在先前分配型別 A 的物件的位置。然後我們可以觸發型別 A 的過時指標的取消參照,該指標反過來使用型別 B 物件中的位。這通常是可能的,因為兩個物件都分配在同一個堆中[43],而 PartitionAlloc 具有如下特性可以滿足分配需求。
-
呼叫者可以根據需要建立任意數量的分割區。分割區的直接記憶體成本是最小的,但碎片導致的隱含成本不可低估。
-
PartitionAlloc 保證不同的分割區存在於程序地址空間的不同區域。當呼叫者釋放了一個分割區中一個頁面中包含的所有物件時, PartitionAlloc 將實體記憶體返回給作業系統,但繼續保留地址空間區域。PartitionAlloc 只會為同一個分割區重用一個地址空間區域。但在一定程度上,它會浪費虛擬空間( virtual address space )。
由於 PartitionAlloc 是面向 Chromium 特定應用場景的高效記憶體分配器,為特定記憶體使用場景的客製化化能力能夠提供高效的記憶體分配和回收(例如, layout 分割區, node 分割區),但面向通用的記憶體分配場景及高安全場景如果能夠和 jemalloc, secudo 能力進行有效的融合( porting ),可能會是一個可行的路徑和方向( MTE 等)。
5. Overview
從如上的分析可以看出,分配器的整體效能和空間效率取決於各種因素之間的權衡,例如快取多少、記憶體分配/回收策略等,實際的時間和空間效率需要根據具體場景衡量並針對性的優化。如下從效能,空間效率,以及 benchmark 方面提供一些總結和參考。
|
記憶體分配器
|
說明
|
|---|---|
|
dlmalloc
|
https://github.com/ARMmbed/dlmalloc· 非執行緒安全,多執行緒分配效率低· 記憶體使用率較低(記憶體碎片多)· 分配效率低· 安全性低
|
|
jemlloc
|
https://github.com/jemalloc/jemalloc/blob/dev/INSTALL.md· 程式碼體積較大,後設資料佔據記憶體大· 記憶體分配效率高(基於run(桶) + region)· 記憶體使用率高· 安全性中
|
|
scudo
|
https://android.googlesource.com/platform/external/scudo/· 更注重安全性,記憶體使用效率和效能上存在一定的損失· 記憶體分配效率偏高(sizeclass + region, 安全性+checksum校驗)· 記憶體使用率低(後設資料,安全區,地址隨機化記憶體佔用多)· 安全性高( 安全性+checksum校驗,地址隨機化,保護區)
|
|
partition-alloc
|
https://source.chromium.org/chromium/chromium/src/+/main:base/allocator/partition_allocator/PartitionAlloc.md· 程式碼體積小· 記憶體使用率偏高(相比於jemalloc多保護區,基於range的分配)· 安全性偏高(相比sudo少安全性,完整性校驗,地址隨機化)· 記憶體分配效率高(基於bucket + slot,分割區特定優化)· 支援"全"平臺 PartitionAlloc Everywhere (BlinkOn 14) :https://www.youtube.com/watch?v=QfY-WMFjjKA
|
NOTE:Benchmark alternate malloc implementations:
|
Allocator
|
QPS (higher is better)
|
Max RSS (lower is better)
|
|---|---|---|
|
tcmalloc (internal)
|
410K
|
357MB
|
|
jemalloc
|
356K
|
1359MB
|
|
dlmalloc (glibc)
|
295K
|
333MB
|
|
mesh
|
142K
|
710MB
|
|
portableumem
|
24K
|
393MB
|
|
hardened_malloc*
|
18K
|
458MB
|
|
guarder
|
FATALERROR**
|
|
|
freeguard
|
SIGSEGV***
|
|
|
scudo (standalone)
|
400K
|
318MB
|
6. Rererence
[1] A Tale of Two Mallocs: On Android libc Allocators – Part 1–dlmalloc
[2] jemalloc: https://github.com/jemalloc/jemalloc/blob/dev/INSTALL.md
[3] A Tale of Two Mallocs: On Android libc Allocators – Part 2–jemalloc: https://blog.nsogroup.com/a-tale-of-two-mallocs-on-android-libc-allocators-part-2-jemalloc/
[4] AndroidConfig:
[5] SizeClassAllocator64 <Config>:
[6] AndroidSizeClassConfig:
[7] Chunk:
[8] MapAllocator :
[9] scudo_allocator : https://github.com/llvm/llvm-project/blob/main/compiler-rt/lib/scudo/scudo_allocator.h
[11] Scudo : https://source.android.com/devices/tech/debug/scudo
[12] Scudo Hardened Allocator: https://llvm.org/docs/ScudoHardenedAllocator.html
[13] System hardening in Android 11: https://android-developers.googleblog.com/2020/06/system-hardening-in-android-11.html
[14] Android Native | Scudo記憶體分配器: https://juejin.cn/post/6914550038140026887
[15] Scudo Allocator : https://zhuanlan.zhihu.com/p/235620563
[16] Efficient And Safe Allocations Everywhere! : https://blog.chromium.org/2021/04/efficient-and-safe-allocations-everywhere.html
[17] PartitionAlloc Design: https://chromium.googlesource.com/chromium/src/+/master/base/allocator/partition_allocator/PartitionAlloc.md
[18] partition_alloc_constants:
[19] Unified allocator shim:
[20] Porting PartitionAlloc To PDFium: https://struct.github.io/pdfium_partitionalloc.html