一次較波折的MySQL調優
春節長假某日,陽光明媚,春暖花開,恰逢冬奧會開幕,想著一定是一個黃道吉日,必能順風順水。沒想到卻遇到一個有點小波折 的客戶報障。
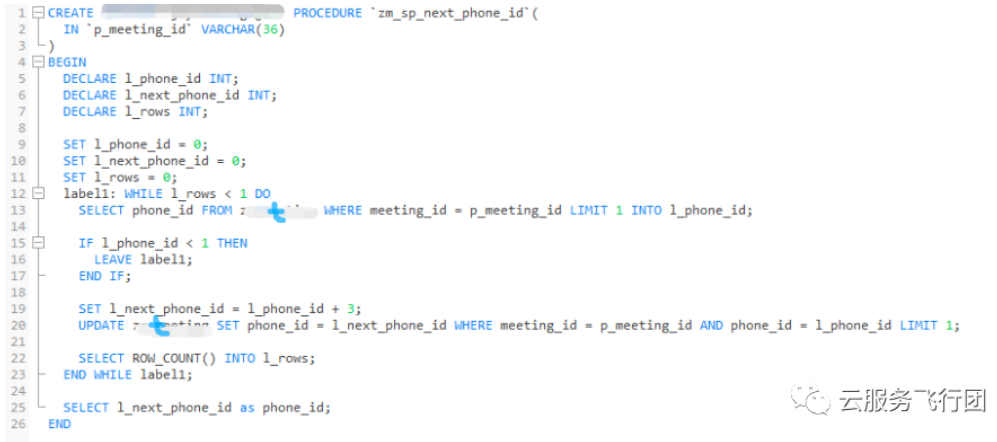
01故障起因故障起因是客戶前一天從自建MySQL遷移到雲上RDS,在執行某個並行較高的業務時出現了大量鎖等待,客戶當時升級了範例到最高規格,但故障依舊。客戶反饋升級後的範例規格比自建範例高了一倍,自建範例上從未發生過類似情況。後客戶根據當時的業務故障模擬了現場,主要是並行執行如下儲存過程的時候效能很差:
02初步診斷
從儲存過程的邏輯看,比較簡單,主要涉及兩個SQL,一個從表t(隱藏了真實表名)中meeting_id根據傳入引數值查詢,具體的入參由字元型變數p_meeting_id帶入;另外一個根據meeting_id和剛查出的phone_id去更新t中的phone_id為phone_id+3。表t資料量約40w左右。
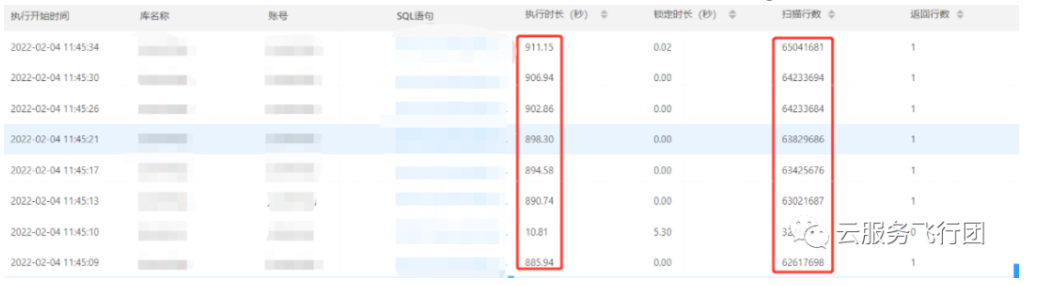
第一感覺這是個簡單問題,估計兩個SQL的meeting_id索引沒有生效,查詢表上索引後果然發現meeting_id和phone_id上沒有索引,建議客戶在兩個欄位上分別建立了索引,且meeting_id為主鍵。此時使用者執行模擬的並行指令碼反饋速度有了明顯提升,200個並行最高執行時間40s左右,但模擬500個並行的時候,超過了8分鐘還沒有執行完。使用者反饋在自建MySQL上並行500執行都是秒級完成。此時在控制檯看,這個儲存過程在慢查詢紀錄檔中批次出現,且掃描行數巨大,使用者端已經完全hang住:
03進一步優化
雖然優化有了初步的效果, 但距離客戶自建環境效能描述還差距很大,由於並行高, 從監控看測試期間CPU到了100%,懷疑引數innodb_thread_concurrency的設定可能不當。此引數的作用是控制 InnoDB 的並行執行緒上限。也就是說,一旦並行執行緒數達到這個值,InnoDB 在接收到新請求的時候,就會進入等待狀態,直到有執行緒退出。RDS預設值為0,也就是沒有限制上限,在高並行的場景下可能會產生較多的上下文切換,導致CPU升高。和客戶諮詢了一下,他們自建環境的值設定為32,建議他們將RDS的值也改為32再看看效果。客戶很快反饋,修改後的確有效果,500個並行在3分鐘內完成,沒有再發生hang住不動的情況,效能有了進一步的提升。但引數innodb_thread_concurrency進一步調整效果不明顯。
04加trace診斷客戶看到效能不斷提升也很有信心,但和自建環境差距還是很大,還有哪裡可能有問題?突然想到,建立索引後,在控制檯的慢查詢列表中看到很多儲存過程的呼叫sql,且掃描記錄數巨大,如果是走meeting_id唯一索引,應該掃描很少的記錄數才對,難道沒有走索引?或者沒有走meeting_id主鍵索引?聯絡客戶,希望提供測試環境登陸測試。
在測試環境,首先希望驗證一下兩個SQL的執行計劃到底是怎麼樣的。登陸範例後,分別對兩個儲存過程中的SQL執行explain,發現走的確實是主鍵(meeting_id):

為了進一步確認SQL在儲存過程中的實際執行計劃,修改了一下測試的儲存過程邏輯,加入了SQL執行的explain結果和實際執行的trace,過程中主要增加的程式碼如下:

執行計劃結果如下:

從結果看,兩個SQL居然真的沒有走主鍵meeting_id索引,而是都走了phone_id這個普通的二級索引,其中第一個查詢SQL走的索引全掃描,掃描記錄數rows為397399,和表的記錄數一致,顯然走了全索引掃描,雖然比全表掃描好一些,但效率仍然低下;另外一個update的SQL走了正常的索引掃描,rows只有2,效能高效。為什麼兩個SQL沒有走meeting_id這個主鍵索引呢?看trace列印的部分內容:
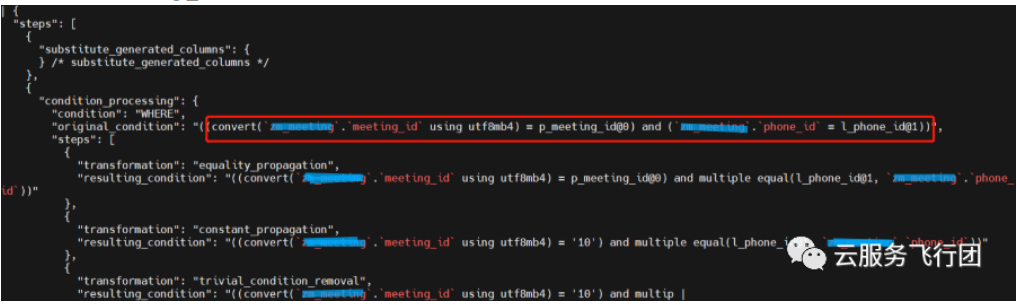
trace顯示兩個SQL在優化器分析時,將meeting_id做了隱式轉換,轉換函數為convert('meeting_id' using utf8mb4),也就是將meeting_id做了字元集的轉換,熟悉索引機制的同學都清楚,這種情況下優化器是不會走meeting_id索引的。這也可以解釋了客戶第一次建立索引的時候為啥有效能提升,但效果並不明顯,原因就是隻有update語句真正用到了索引帶來的效能提升,而且是phone_id索引帶來的提升,不是效能更高的主鍵meeting_id。
05真相大白
現在聚焦到最關鍵的問題,meeting_id為啥要做字元集的隱式轉換?檢視了一下範例相關字元集的設定:
-
表和列的字元集都為utf8;
-
表所在庫的字元集為utf8mb4;
-
server字元集((character_set_server))為utf8
-
character_set_client/character_set_connection/character_set_results為utf8mb4
果然,server、database、table的字元集不完全一致,猜想一下實際流程應該是這樣的:儲存過程中傳入的字元引數字元集為utf8mb4,和表中字元集為utf8的欄位meeting_id比較時,meeting_id做了字元集的隱式轉換,轉換為utf8mb4後再和輸入引數比較,從而導致meeting_id上的索引無法使用。
根據這個猜測,建議使用者將表的字元集更改為utf8mb4,這樣應該可以避免字元集的轉換。由於這個功能還未上線,使用者直接對 表做了字元集的修改:
alter table zm_meeting convert to character set utf8mb4;
修改後讓使用者再次測試,預期效果終於出現,並行500測試在秒級完成,trace檢視執行計劃,都走了meeting_id的主鍵索引,隱式轉換也隨之消失,效能問題得到了徹底解決。
06後續思考儲存過程的入參為啥使用了utf8mb4?這是本次案例的核心,查閱mysql檔案,儲存過程介紹裡面有一段描述:

簡單說,就是儲存過程的字元型引數,如果沒有顯式指定字元集,預設將會使用所在資料庫的字元集,而本案例中表所在的資料庫字元集為utf8mb4,所以引數預設使用了utf8mb4,導致了匹配過程的隱式轉換。儲存過程外直接寫SQL為什麼沒有這種情況發生,我猜測比較的字串應該會自動匹配‘=’左邊表欄位的字元集。
既然這樣,理論上直接修改引數的字元集應該也可以達到同樣結果,簡單測試下,將儲存過程引數加上表上的字元集屬性:
CREATE PROCEDURE `zm_sp_next_phone_id`(IN `p_meeting_id` VARCHAR(36) character set utf8)
測試結果如我們預期,不會產生隱式轉換,執行計劃正確。
問題雖然解決了,原因也找到了,但反思一下整個過程,如果使用者的server、庫、表字元集能夠保持一致,將完全可以避免這個故障。與字元集相關的類似故障也可以大概率避免,所以客戶側還是要有一定的設計規範;產品側如果有一定的檢查規則可以幫客戶發現類似的隱患,對提升客戶體驗也是一種很有價值的服務。