WebGPU實現Ray Packet
大家好~本文在如何用WebGPU流暢渲染百萬級2D物體?基礎上進行優化,使用WebGPU實現了Ray Packet,也就是將8*8=64條射線作為一個Packet一起去存取BVH的節點。這樣做的好處是整個Packet只需要一個維護BVH節點的Stack,節省了GPU Shared Memory;壞處是一個Packet的64條射線是平行計算的,需要實現同步邏輯,並且針對GPU的架構進行並行優化
相關文章如下:
如何用WebGPU流暢渲染百萬級2D物體?
成果
我們渲染1百萬個圓環,對比優化前的Demo:
效能指標:
- FPS基本上沒有變化
- GPU Shared Memory的佔用減少為1/5
在FPS不變的情況下,Stack的大小可以從之前的最大值20提升到最大值100
硬體:
- Mac OS Big Sur 11.4作業系統
- Canary瀏覽器
- Intel Iris Pro 1536 MB整合顯示卡
演演算法實現
每條射線使用一個區域性單位,所以一個Packet共使用8*8=64個區域性單位
這裡將射線與相機近平面的交點變換到了螢幕座標系下,變數名為pointInScreen(之前的Demo中的交點是在世界座標系下)
整個演演算法的相關實現程式碼如下所示:
var<workgroup>stackContainer: array<TopLevel, 20>;
var<workgroup>rayPacketAABBData: array<f32, 4>;
var<workgroup>isRayPacketAABBIntersectWithTopLevelNode: bool;
var<workgroup>rayPacketRingIntersectLayer: array<u32, 64>;
var<workgroup>stackSize: u32;
var<workgroup>isAddChild1: bool;
var<workgroup>isAddChild2: bool;
...
fn _intersectScene(ray: Ray, LocalInvocationIndex : u32) -> RingIntersect {
var intersectResult: RingIntersect;
intersectResult.isClosestHit = false;
intersectResult.layer = 0;
var rootNode = topLevel.topLevels[0];
var pointInScreen = ray.rayTarget;
// 用兩個區域性單位並行建立Packet的AABB
if (LocalInvocationIndex == 0) {
rayPacketAABBData[0] = pointInScreen.x;
rayPacketAABBData[1] = pointInScreen.y;
}
if (LocalInvocationIndex == 63) {
rayPacketAABBData[2] = pointInScreen.x;
rayPacketAABBData[3] = pointInScreen.y;
}
//用一個區域性單位並行初始化共用變數
if (LocalInvocationIndex == 1) {
stackSize = 1;
stackContainer[0] = rootNode;
}
workgroupBarrier();
//遍歷BVH節點
while (stackSize > 0) {
//在迴圈開始的時候要同步下(暫時不清楚原因,反正是因為stackSize是共用變數造成的)
workgroupBarrier();
if (LocalInvocationIndex == 0) {
stackSize -= 1;
}
workgroupBarrier();
var currentNode = stackContainer[stackSize];
var leafInstanceCountAndMaxLayer = u32(currentNode.leafInstanceCountAndMaxLayer);
var leafInstanceCount = _getLeafInstanceCount(leafInstanceCountAndMaxLayer);
//如果是葉節點,則Packet中所有射線都與該節點進行相交檢測
if (_isLeafNode(leafInstanceCount)) {
//判斷射線是否與節點的AABB相交
if (_isPointIntersectWithTopLevelNode(pointInScreen, currentNode)) {
var leafInstanceOffset = u32(currentNode.leafInstanceOffset);
var maxLayer = _getMaxLayer(u32(currentNode.leafInstanceCountAndMaxLayer));
//判斷射線是否與節點包含的所有圓環相交
while (leafInstanceCount > 0) {
var bottomLevel = bottomLevel.bottomLevels[leafInstanceOffset];
//判斷射線是否與圓環的AABB相交
if (_isPointIntersectWithAABB(pointInScreen, bottomLevel.screenMin, bottomLevel.screenMax)) {
var instance: Instance = sceneInstanceData.instances[u32(bottomLevel.instanceIndex)];
var geometry: Geometry = sceneGeometryData.geometrys[u32(instance.geometryIndex)];
//判斷射線是否與圓環相交
if (_isIntersectWithRing(pointInScreen, instance, geometry)) {
var layer = u32(bottomLevel.layer);
if (!intersectResult.isClosestHit || layer > intersectResult.layer) {
intersectResult.isClosestHit = true;
intersectResult.layer = layer;
intersectResult.instanceIndex = bottomLevel.instanceIndex;
}
}
}
leafInstanceCount = leafInstanceCount - 1;
leafInstanceOffset = leafInstanceOffset + 1;
}
}
}
//如果不是葉節點,則通過剔除檢測後加入兩個子節點
else {
// 一個非葉節點必有兩個子節點
var child1Node = topLevel.topLevels[u32(currentNode.child1Index)];
var child2Node = topLevel.topLevels[u32(currentNode.child2Index)];
var child1NodeMaxLayer = _getMaxLayer(u32(child1Node.leafInstanceCountAndMaxLayer));
var child2NodeMaxLayer = _getMaxLayer(u32(child2Node.leafInstanceCountAndMaxLayer));
//平行計算Packet中所有射線的最小layer
rayPacketRingIntersectLayer[LocalInvocationIndex] = intersectResult.layer;
workgroupBarrier();
if (LocalInvocationIndex < 32) {
_minForRayPacketRingIntersectLayer(LocalInvocationIndex, LocalInvocationIndex + 32);
}
workgroupBarrier();
if (LocalInvocationIndex < 16) {
_minForRayPacketRingIntersectLayer(LocalInvocationIndex, LocalInvocationIndex + 16);
}
workgroupBarrier();
if (LocalInvocationIndex < 8) {
_minForRayPacketRingIntersectLayer(LocalInvocationIndex, LocalInvocationIndex + 8);
}
workgroupBarrier();
if (LocalInvocationIndex < 4) {
_minForRayPacketRingIntersectLayer(LocalInvocationIndex, LocalInvocationIndex + 4);
}
workgroupBarrier();
if (LocalInvocationIndex < 2) {
_minForRayPacketRingIntersectLayer(LocalInvocationIndex, LocalInvocationIndex + 2);
}
workgroupBarrier();
//用兩個區域性單位並行判斷子節點是否在Packet的前面以及Packet的AABB是否與子節點相交
if (LocalInvocationIndex == 0) {
isAddChild1 = child1NodeMaxLayer > rayPacketRingIntersectLayer[0] && _isRayPacketAABBIntersectWithTopLevelNode(rayPacketAABBData, child1Node);
}
if (LocalInvocationIndex == 1) {
isAddChild2 = child2NodeMaxLayer > rayPacketRingIntersectLayer[0] && _isRayPacketAABBIntersectWithTopLevelNode(rayPacketAABBData, child2Node);
}
workgroupBarrier();
// 加入兩個子節點到stack中
if (LocalInvocationIndex == 0) {
if (isAddChild1) {
stackContainer[stackSize] = child1Node;
stackSize += 1;
}
if (isAddChild2) {
stackContainer[stackSize] = child2Node;
stackSize += 1;
}
}
}
workgroupBarrier();
}
return intersectResult;
}
「建立Packet的AABB」程式碼說明

如上圖所示,紅色方塊為Packet的2D AABB,由64個射線的pointInScreen組成
圖中藍色方塊為一個pointInScreen,從中心點開始
pointInScreen對應的區域性單位序號是從紅色方塊左下角開始,朝著右上方增加。
部分區域性單位序號在圖中用數位標註了出來
所以Packet的2D AABB的min即為0號區域性單位對應的pointInScreen,而max則為63號區域性單位對應的pointInScreen
建立Packet的AABB的相關程式碼如下:
var pointInScreen = ray.rayTarget;
// 用兩個區域性單位並行建立Packet的AABB
if (LocalInvocationIndex == 0) {
rayPacketAABBData[0] = pointInScreen.x;
rayPacketAABBData[1] = pointInScreen.y;
}
if (LocalInvocationIndex == 63) {
rayPacketAABBData[2] = pointInScreen.x;
rayPacketAABBData[3] = pointInScreen.y;
}
平行計算的優化點
因為現在需要對一個Packet中64條射線平行計算,所以需要了解GPU的架構和特點,從而進行相應的優化
GPU是以warp為單位,每個wrap包含32個執行緒。所以我們這裡的一個Packet應該使用了兩個wrap,其中一個wrap中的一個執行緒對應一個區域性單位
平行計算的優化點為:
-
只有當整個wrap中所有執行緒都不執行某個操作時,這個wrap才不會被執行,從而FPS會提高。只要wrap中至少有一個執行緒要執行某個操作,那麼即使其它所有執行緒不執行該操作,它們也會在執行"workgroupBarrier()"時等待)
-
GPU中Memory IO是個瓶頸,所以應該減少記憶體讀寫操作
GPU記憶體型別分為暫存器、共用、區域性、常數、紋理、全域性,讀寫速度依次遞減
記憶體模型如下圖所示:
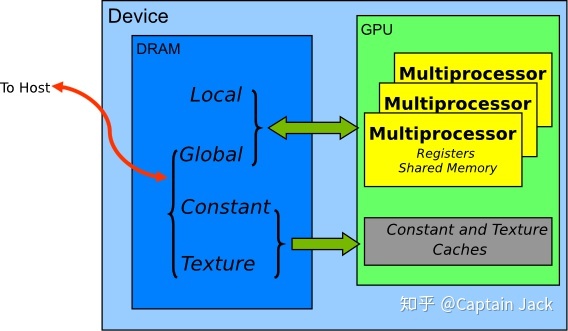
記憶體特性如下圖所示:

應該減少速度慢的區域性、常數、紋理、全域性記憶體的讀寫
-
減少bank conflict
共用記憶體是由多個bank組成,對於同一個bank的不同地址的讀寫會造成bank conflict
因此儘量讀寫共用記憶體的連續地址 -
減少wrap diverse
應該減少一個Packet中不同的區域性單位進入不同的if分支的情況(這會造成區域性單位阻塞)
為什麼沒有提升FPS?
之前的Demo使用序列演演算法,而現在的Demo使用並行演演算法
如果都不使用traverse order優化(即判斷節點如果在射線的後面,則不遍歷它),則FPS提升了50%;
如果都使用traverse order優化,則FPS沒有變化;
這說明traverse order優化對於序列演演算法的提升更大。這是因為對於並行演演算法而言,只有當節點在一個Packet的所有射線的後面時,才不會遍歷節點(可以參考之前的提到的優化點1);
而對於序列演演算法而言,只要當節點在一條射線的後面,就不會遍歷節點
為什麼不使用改進的Ranged traversal演演算法?
通過Large Ray Packets for Real-time Whitted Ray Tracing論文,得知現在的並行演演算法屬於文中提到的「Masked traversal」演演算法
文中還介紹了改進版的Ranged traversal演演算法,具體就是指一個Packet增加first active和last active標誌,從而使一個Packet中只有first到last之間的射線進行相交檢測,減少了相交檢測的射線數量
但是這個演演算法應用到本文的並行演演算法中並不會提高FPS!因為本文的並行演演算法中的一個Packet至少會有一條射線會與葉節點進行相交檢測,所以根據之前提到的優化點1可知FPS不會提高
具體案例分析
現在我們對程式碼進行一些具體的分析:
暫存器、共用、區域性、全域性記憶體分析
參考程式碼與儲存的對映關係:

以及參考gpu cpu 共用記憶體 提高傳輸速度_GPU程式設計3--GPU記憶體深入瞭解,我們來分析下本文部分程式碼中的記憶體使用情況:
fn _intersectScene(ray: Ray, LocalInvocationIndex : u32) -> RingIntersect {
//intersectResult是較大結構體,應該位於區域性記憶體
var intersectResult: RingIntersect;
intersectResult.isClosestHit = false;
intersectResult.layer = 0;
//topLevel.topLevels是storage buffer資料,位於全域性記憶體
//rootNode是較大結構體,應該位於區域性記憶體
var rootNode = topLevel.topLevels[0];
//pointInScreen位於暫存器
var pointInScreen = ray.rayTarget;
if (LocalInvocationIndex == 0) {
//rayPacketAABBData位於共用記憶體
rayPacketAABBData[0] = pointInScreen.x;
rayPacketAABBData[1] = pointInScreen.y;
}
if (LocalInvocationIndex == 63) {
rayPacketAABBData[2] = pointInScreen.x;
rayPacketAABBData[3] = pointInScreen.y;
}
...
}
GPU Memory IO優化
根據之前提到的優化點2,我們知道應該減少GPU記憶體的讀寫,特別是全域性記憶體的讀寫
我們來對照程式碼分析一下全域性記憶體讀寫的優化,看下面的程式碼:
var rootNode = topLevel.topLevels[0];
...
if (LocalInvocationIndex == 1) {
stackSize = 1;
stackContainer[0] = rootNode;
}
這裡一個Packet中所有區域性單位都從全域性記憶體中讀取第一個元素為rootNode,寫到本地記憶體中(這裡進行了64次全域性記憶體讀操作);
然後在1號區域性單位中,從本地記憶體中讀取rootNode,寫到共用記憶體中
如果將程式碼改為:
if (LocalInvocationIndex == 1) {
stackSize = 1;
stackContainer[0] = topLevel.topLevels[0];
}
那麼就應該只進行1次全域性記憶體讀操作,從而提高FPS
但是實際上卻降低了10%左右FPS,這是為什麼呢?
這是因為GPU會將對全域性記憶體同一地址或者相鄰地址的讀操作合併為一次操作(寫操作也是一樣),所以修改前後的程式碼對全域性記憶體的讀操作都是1次。
那麼FPS應該不變,但為什麼下降了呢?
這是因為在進行記憶體操作時,需要加上事務(進行鎖之類的同步操作)。如果一個wrap中的所有執行緒同時對全域性記憶體的一個地址進行讀,則合併後的該次操作只需要一個事務;而如果是一個wrap中的部分執行緒進行讀,則合併後的該次操作需要更多的事務(如4個),從而需要更多時間開銷,降低了FPS
參考資料:
Nvidia GPU simultaneous access to a single location in global memory
初識事務記憶體(Transactional Memory)
我們再看下面的程式碼:
else {
var child1Node = topLevel.topLevels[u32(currentNode.child1Index)];
var child2Node = topLevel.topLevels[u32(currentNode.child2Index)];
var child1NodeMaxLayer = _getMaxLayer(u32(child1Node.leafInstanceCountAndMaxLayer));
var child2NodeMaxLayer = _getMaxLayer(u32(child2Node.leafInstanceCountAndMaxLayer));
這裡只需要一次合併後的讀操作,從全域性記憶體中讀出child1Node、child2Node
如果程式碼改為:
else {
var child1Node = topLevel.topLevels[u32(currentNode.child1Index)];
var child1NodeMaxLayer = _getMaxLayer(u32(child1Node.leafInstanceCountAndMaxLayer));
var child2Node = topLevel.topLevels[u32(currentNode.child2Index)];
var child2NodeMaxLayer = _getMaxLayer(u32(child2Node.leafInstanceCountAndMaxLayer));
因為要切換記憶體(全域性和區域性記憶體之間切換),所以就不能合併了,而需要二次全域性記憶體的讀操作,分別讀出child1Node和child2Node,所以FPS會下降10%左右
parallel reduction優化並沒有提高FPS
下面的程式碼使用了parallel reduction的優化版本來平行計算Packet中所有射線的最小layer:
if (LocalInvocationIndex < 32) {
_minForRayPacketRingIntersectLayer(LocalInvocationIndex, LocalInvocationIndex + 32);
}
workgroupBarrier();
if (LocalInvocationIndex < 16) {
_minForRayPacketRingIntersectLayer(LocalInvocationIndex, LocalInvocationIndex + 16);
}
workgroupBarrier();
if (LocalInvocationIndex < 8) {
_minForRayPacketRingIntersectLayer(LocalInvocationIndex, LocalInvocationIndex + 8);
}
workgroupBarrier();
if (LocalInvocationIndex < 4) {
_minForRayPacketRingIntersectLayer(LocalInvocationIndex, LocalInvocationIndex + 4);
}
workgroupBarrier();
if (LocalInvocationIndex < 2) {
_minForRayPacketRingIntersectLayer(LocalInvocationIndex, LocalInvocationIndex + 2);
}
workgroupBarrier();
關於parallel reduction優化可以參考啥是Parallel Reduction
優化後的程式碼並不比下面的原始版本的程式碼快:
for (var s: u32 = 1; s < 64; s = s * 2) {
if (LocalInvocationIndex % (2 * s) == 0) {
_minForRayPacketRingIntersectLayer(LocalInvocationIndex, LocalInvocationIndex + s);
}
workgroupBarrier();
}
估計是GPU幫我們優化了
wrap diverse優化
在之前使用序列演演算法的Demo程式碼中,我們在遍歷葉節點包含的所有圓環時,加入了「如果找到了最前面的相交圓環,則退出葉節點的遍歷」的優化,相關程式碼為:
if (_isLeafNode(leafInstanceCount)) {
...
while (leafInstanceCount > 0) {
...
if (_isPointIntersectWithAABB(point, bottomLevel.worldMin, bottomLevel.worldMax)) {
...
if (_isIntersectWithRing(point, instance, geometry)) {
if (!intersectResult.isClosestHit || layer > intersectResult.layer) {
...
if(layer == maxLayer){
break;
}
}
}
}
...
}
而在本文的使用並行演演算法的程式碼,卻刪除了這個優化,FPS反而提升了10%。這是因為Packet中只有部分的區域性單位會退出遍歷,造成其它區域性單位阻塞等待
注:如果並行演演算法的程式碼要加入這個優化,那也不能直接break,而是改為設定isBreak=true,在if中判斷isBreak,這樣才不會有同步的問題
bank conflict優化
現代顯示卡實現了broadcast機制,從而對同一個bank的相同地址的讀寫不會造成bank conflict。但由於我的測試顯示卡是老顯示卡,還沒有該機制,所以在這種情況下會造成bank conflict
如下面程式碼所示:
if (LocalInvocationIndex == 0) {
isAddChild1 = _isRayPacketAABBIntersectWithTopLevelNode(rayPacketAABBData, child1Node);
}
if (LocalInvocationIndex == 1) {
isAddChild2 = _isRayPacketAABBIntersectWithTopLevelNode(rayPacketAABBData, child2Node);
}
兩個區域性單位同時讀共用變數rayPacketAABBData,從而造成bank conflict,FPS下降5%左右
參考資料
Large Ray Packets for Real-time Whitted Ray Tracing
Realtime Ray Tracing on GPU with BVH-based Packet Traversal
is early exit of loops on GPU worth doing?
issue while using break statement in cuda kernel
What's the mechanism of the warps and the banks in CUDA?
歡迎來到Wonder~
掃碼加入我的QQ群:

掃碼加入免費知識星球-YYC的Web3D旅程:

掃碼關注微信公眾號:
