雲資料庫架構思維升級,看這篇就夠了
近期,ArchSummit 全球架構師峰會(以下簡稱:AS峰會)北京站圓滿落幕。AS峰會是極客邦科技旗下 InfoQ 中國團隊推出的重點面向高階技術管理者、架構師的技術會議。AS峰會北京站以「升級架構思維,支撐業務發展」為目標,邀請各廠商展示先進技術在行業中的典型實踐,以及技術在企業轉型、發展中的推動作用。在此次AS峰會上,騰訊雲資料庫專家團亮相「雲資料庫的架構設計與技術演進」專場,由騰訊雲資料庫專家工程師伍鑫擔任專場出品人。
資料庫作為基礎軟體的三駕馬車之一,是IT行業的必爭之地。雲時代下,雲原生技術和資料庫技術的結合,已經成為資料庫行業重要發展方向。在專場中,四位講師圍繞雲資料庫的架構設計和技術演進,以騰訊雲的資料庫產品為例,針對性地解讀資料庫產品容器化難點、資料庫統一管理、超大規模叢集線上數倉架構設計等話題。

一、雲原生資料庫管控探索和實踐
孫勇福,騰訊雲資料庫專家工程師

技術變革日新月異,迭代迅速。孫勇福認為,多元技術融合、多元架構形態會成為未來的常態。隨著業務的不斷擴大,沿用分散的管控架構模式勢必會帶來重複建設的問題,導致資源使用效率低下,弊端也逐漸凸顯,具體如下:
- 無法利用雲上 IaaS 層的資源池和彈性擴縮容的能力,以及 IaaS 層成本和效能優化的紅利;
- 缺少統一的資料庫 PaaS 平臺,對多個產品、多個環境進行統一管控和排程;
- 業務功能複用程度低,造成人力資源浪費;
- 無法利用雲原生紅利,平臺無法標準化,運維和交付成本比較高;
上述問題,可以歸納為資源排程和統一的流程管控問題。
得益於騰訊雲上IaaS基礎設施的優勢,孫勇福提出了PaaS on IaaS的思考,提高資料庫系統的彈效能力,實現降本增效,同時解決資料庫產品發展過程中遺留的歷史架構問題, 提升孵化新資料庫產品的效率。
如何統一管理IaaS層的資源,是 PaaS on IaaS 面臨的主要挑戰。孫勇福所在的研發團隊進行了各種不同的嘗試,從最初的框架模式逐漸演化到平臺模式,一個叫雲巢(Khaos)的產品誕生了。現如今,雲巢(Khaos)有狀態服務PaaS平臺已經可以支援各種資料庫產品快速上雲。
什麼是有狀態服務?孫勇福解釋說,有狀態服務是指需要將資料、對談或服務狀態做持久儲存,服務啟動、執行和恢復時均嚴格依賴所儲存資料的正確性和一致性的服務。資料庫就是典型的有狀態服務。有狀態服務區別於無狀態服務主要是狀態兩個字,有狀態服務往往伴隨著資料持久化,服務節點狀態化( MySQL 主從節點)。
如何在複雜的狀態服務中,更好的解耦業務邏輯,提供通用的平臺能力是PaaS 平臺設計的難點之一。在雲巢的構建中,首先要明確平臺的邊界和業務邊界,平臺不僅要關心業務的具體邏輯,也必須要提供業務靈活的接入功能。
在架構設計上,雲巢平臺包含 Khaos Platform 和 Khaos Eros 兩個子系統。Khaos Platform藉助Kubernetes的標準化能力統一了不同的底座, 向上提供資料庫服務範例的設定管理、生命週期管理、跨故障域排程等基礎能力。除了底層資源管理之外,資料庫管控系統往往還有較複雜的業務流程, 例如,對於某個資料庫範例的發貨流程,管控系統收到請求後,先申請底層計算、儲存資源以及VIP等, 等待資源就緒之後,管控系統繼續執行新增路由、設定計費策略等操作。為了降低業務流程與雲巢的互動複雜度,雲巢在資源管理的基礎上提供了 Khaos Eros服務, 用來將底層資源平臺的操作細節封裝成更粗粒度的業務流程,簡化使用雲巢的難度。
此外,孫勇福還分享了雲巢架構設計實現的具體細節,有想了解的小夥伴可入群與講師討論哦!
二、騰訊雲資料庫雲上SaaS生態演進
潘怡飛,騰訊雲資料庫高階工程師

在實際工作中,潘怡飛通過與使用者的交流發現,使用者在用PaaS產品的時候經常需要客製化開發,比如說資料庫運維工具、資料傳輸工具等等。客製化化工作會分散運維同學的精力,增加研發同學在業務上的研發時間。因此,SaaS產品應運而生。
騰訊雲資料庫提供完整的SaaS生態矩陣,潘怡飛重點分享了以下三大產品:
1. 資料傳輸服務DTS
DTS提供資料遷移與資料流打通服務,特點是支援線上遷移同步,滿足低時延和高可靠的要求,在功能上主要包含遷移、同步和訂閱三大模組。具體來看:
- DTS資料遷移是面向單次的資料庫遷移上雲、下雲,支援常見的鏈路,可以實現歷史全量和動態增量的遷移,同時它還支援一致性校驗,可以在遷移前隨時發起一致性校驗,幫助客戶預知遷移效果。在遷移中,DTS能夠保證資料的正確性以及做到對源庫無感知,潘怡飛表示這也是客戶最關注的點。
- DTS資料同步是指兩個資料來源之間的資料長期實時同步,具有多種高階特性,例如庫表重對映、DML/DDL過濾,Where條件過濾;主要適用於雲上雲下多活、異地多活,跨境資料同步、實時資料倉儲等場景。
- DTS資料訂閱是指實時按需獲取資料庫中關鍵業務的資料變化資訊,將這些資訊包裝為訊息物件推播到內建Kafka中,方便下游實時消費應用;適用於異構資料更新等。
整體來看,DTS通過遷移、同步和訂閱這三個功能模組,充分打通資料鏈路之間的流轉管理,構建雙向、環形、異構、多合一等場景。這樣不用客戶自己去開發一些工具或定時任務來解決問題,使得客戶可以更專注於自身業務,發揮優勢創造價值,剩下的就交給PaaS平臺或SaaS平臺來做。
2. 資料智慧管家DBbrain
資料庫統一管理過程中有許多的難點和痛點,DBbrain正是應用於解決這些問題的一款SaaS工具。DBbrain是自動化、智慧化運維統一管理平臺,從前期的資料庫巡檢、故障發現、故障定位到後期的故障解決與系統優化,形成一套資料庫全生命週期管理運維的工具。
潘怡飛列舉了兩個典型場景,為大家詳細展示了DBbrain的功能。
第一個是慢SQL分析。DBbrain會基於多維度的統計來進行統一彙總,並實現自動排序。在效能優化這方面,利用編譯器、優化器的改寫來計算代價和成本,以此判斷SQL是不是優質,是不是需要新增索引。另外DBbrain支援通過API的拉取分析介面,藉助雲上計算的優勢,直接使用 SaaS 去構建自有運維平臺。
第二個是異常診斷。日常診斷是根據秒級的監控,日常的巡檢會有一些告警項提示,同時收集十幾個維度的資訊之後做彙總展示,進一步進行預警診斷。
3. 資料庫安全審計
資料庫安全審計是一個基於核心級別的安全審計平臺,區別於一些需要旁路管控部署的方式,這種對效能和收集完整度都支援的比較好;同時可以DBbrain進行聯動,針對審計紀錄檔進行彙總、分析,真正能夠做到收集並使用。
SaaS的產品價值在於可以降低客戶在工具或者不必要的研發上的投入,把資源聚焦於自己的業務。直接使用SaaS 工具可以幫助業務更好的創造價值。
未來,潘怡飛表示騰訊雲資料庫SaaS生態產品還將繼續發力。DTS後續會在場景化和複雜拓撲場景深耕,支援一鍵建立複雜拓撲鏈路,比如說星型、環形、雙向等一系列場景,並且實現不需要逐條設定衝突策略。DBbrain會更加智慧化、AI化,可以直接基於慢SQL自動,將之前的推薦模式升級到自動建立索引,甚至實現資料庫負載自動擴容、縮容;同時可以利用目前雲原生資料庫的快速縮擴容能力,充分結合更多產品之間的場景聯動,幫助客戶創造更多業務價值。
此外,潘怡飛還分享了騰訊雲資料庫SaaS生態的發展思路,有想了解的小夥伴可入群與講師討論哦!
三、大規模線上數倉技術構架分享
張倩,騰訊雲資料庫專家工程師

大規模線上數倉的分析效能提升,可以在自研列式儲存、向量化引擎、並行執行邏輯、計算層快取等核心技術模組做突破,張倩分享道。
資料庫技術發展半個世紀,從早期對關係模型的研究到SQL語句的出現,都是不斷面向業務需求和使用者體驗的最佳設計實踐。而列儲存的出現甚至可以追溯到上世紀70年代的資料庫開創時代,當時人們就在討論具體用何種儲存模型來支援上層計算。
張倩提到,其實在實際使用場景中,使用者業務模型並不會完全適配某一種儲存型別,更多的是混合業務模型中帶有OLTP或者OLAP場景的傾向性。所以資料庫系統在早期針對專一場景的探索比較成熟後,近年來開始進一步探索,逐步提出混合HTAP(Hybrid Transactional/Analytical Processing)模式,希望通過一套引擎來處理混合業務型別。
大規模線上數倉整體以OLAP極致查詢效能讀優化RO(Read Optimize)為基礎前提,保證資料庫事務ACID特性,同時針對OLTP場景進行寫優化WO(Write Optimize)。並且對RO/WO能力進行透明整合,為使用者提供透明易用的表結構設計。
張倩基於列式儲存的自研過程,為大家重點分析了其中的技術細節。列儲存模組中資料塊採用DSM模型每列以Silo格式獨立儲存保證高壓縮比和最大化I/O裁剪能力支援。而每張列儲存表會建立兩張輔助heap表,Registry表用來儲存Silo的後設資料資訊,Stash表用來承接Write Optimize的短事務DML資料並後臺進行資料「沉降」Merge。
通過基於heap表的後設資料實現,將列存的MVCC設計與行存表統一,使得列存表能夠完美支援DML、分散式事務一致性、並行更新等能力。同時列存表也支援B-Tree/Hash索引,range/hash/list等多級分割區表能力。使用者使用起來更加方便,在選擇儲存型別建表後,使用者基本可以無感知的進行行列混合多表關聯、基於索引的點查詢加速、多工並行入庫/查詢。
此外,張倩還分享了騰訊雲資料庫在向量化引擎、並行執行邏輯、計算層快取等技術上的優化思路,有想了解的小夥伴可入群與講師討論哦!
四、TDSQL升級版引擎架構和關鍵技術介紹
韓碩,騰訊雲資料庫高階工程師

隨著企業業務場景的不斷增長和複雜化,業務形態、業務量會不可預知性的增大。由此,業務的敏態發展對資料庫底層技術也提出了需要具有敏感能力的要求。
韓碩老師分享道,在資料庫投產的過程中,應對業務敏態變更的時候常常會遇到以下這些問題:
- 相容性:建表需要手動指定shardkey;
- 運維:儲存層擴容,需要DBA發起,部分事務會中斷;
- 模式變更:online DDL依賴Pt等工具。
基於上述問題,騰訊雲資料庫升級了TDSQL新敏態儲存引擎架構。韓碩老師表示,考慮到敏態業務變化較大,團隊希望在TDSQL新敏態儲存引擎架構中,使用者可以像單機資料庫一樣去使用分散式資料,不需要關注儲存變化,可以隨時加欄位、建索引,做到業務完全無感知。
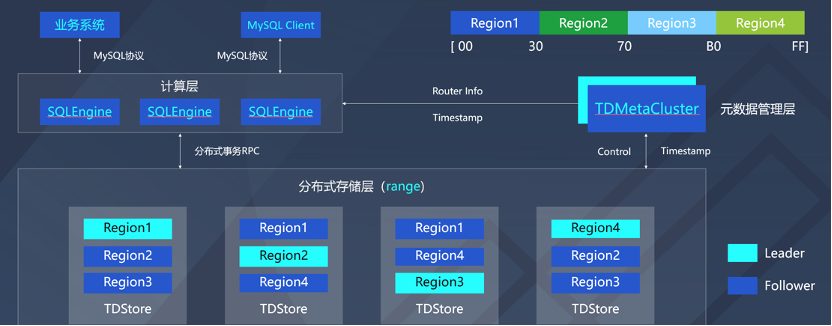
如上圖所示,升級版的架構圖分為計算層、後設資料管理層和分散式儲存層三個部分。韓碩重點分享了這三個部分的設計要點。
在計算模組SQLEngine中,核心完全相容MYSQL8.0。計算層為多主架構,每個SQLEngine節點均可讀寫,SQLEngine之間通過一定方式重新整理表結構變更等資訊。改造是無狀態化設計,移除各種有狀態化的資料,多執行緒替換為協程框架。
在儲存模組TDstore中,架構是基於LSM-tree和Multi-raft的分散式KV儲存引擎。資料是Region是基於raft同步的多副本的儲存管理單元,資料根據key範圍分佈在不同Region上;Region TDMC排程下可發生分裂、合併、遷移、切主等操作。
在管控模組TDMetacluser中,重點關注三個方面,第一是高效的生成和下發全域性唯一的事務時間戳;第二是管理模組的後設資料,比如TDstore和SQLEngine後設資料,管理Region資料路由資訊,以Region為基本單位進行負載均衡和儲存的均衡排程;第三是負載均衡的排程,這個排程要考慮負載的熱點,簡單來講,會把熱點Region打散到不同的儲存節點上,也需要兼顧效能的影響,還要對Region程序做一些合理的劃分,會有跨Region的分散式事務,是兩階段提交的模型,我們會把程序通過合理的Region排程和劃分,把兩個階段的事務變成一階段的事務,從而提升效率。
韓碩將升級版引擎技術亮點總結為以下四點:
- 相容性:具有TDSQL相容性,升級版的架構是原生分散式結構,資料以key range打散和路由,成本比較低;儲存層採用LSM-Tree結構,壓縮比有量級的提升,非常適合於大規模業務量的業務。
- 可延伸性強:首先計算層是多主模式,每個SQLengine均可讀寫,同時是無狀態化設計,可根據業務流量隨時靈活新增或減少一些計算節點。儲存層也是根據業務資料儲存量需求,去做平滑的新增或者移除TDstore節點,通過資料自動遷移,實現容量彈性伸縮,做到業務層無感知。
- 一致性:事務模型具有全域性讀一致性,圍繞管理層TDmetacluster統一分配全域性唯一遞增事務時間戳來做資料的一致性的判斷。
- 支援線上變更:計算節點支援線上模式變更,目前已經支援了線上操作、索引操作等。
最後,韓碩再次將團隊的願景傳遞給大家:希望使用者能夠像使用單機資料庫一樣使用我們的分散式資料庫,同時還能擁有無限擴充套件性。
此外,想了解韓碩分享的TDSQL新敏態儲存引擎架構實現細節的小夥伴,可入群與講師討論哦!