smile——Java機器學習引擎
資源
https://haifengl.github.io/
https://github.com/haifengl/smile
介紹
Smile(統計機器智慧和學習引擎)是一個基於Java和Scala的快速、全面的機器學習、NLP、線性代數、圖形、插值和視覺化系統。
憑藉先進的資料結構和演演算法,Smile提供了最先進的效能。Smile有很好的檔案記錄,請檢視專案網站以獲取程式設計指南和更多資訊。
Smile涵蓋了機器學習的各個方面,包括分類、迴歸、聚類、關聯規則挖掘、特徵選擇、流形學習、多維縮放、遺傳演演算法、缺失值插補、高效最近鄰搜尋等。
Smile實現了以下主要的機器學習演演算法:
- 分類:支援向量機、決策樹、AdaBoost、梯度提升、隨機森林、邏輯迴歸、神經網路、RBF網路、最大熵分類器、KNN、樸素貝葉斯、Fisher/線性/二次/正則判別分析。
- 迴歸:支援向量迴歸、高斯過程、迴歸樹、梯度提升、隨機森林、RBF網路、OLS、套索、彈性網路、嶺迴歸。
- 特徵選擇:基於遺傳演演算法的特徵選擇,基於整合學習的特徵選擇、樹形圖、訊雜比和平方比。
- 聚類:BIRCH、CLARANS、DBSCAN、DENCLUE、確定性退火、K-均值、X-均值、G-均值、神經氣體、生長神經氣體、層次聚類、順序資訊瓶頸、自組織對映、光譜聚類、最小熵聚類。
- 關聯規則和頻繁項集挖掘:FP增長挖掘演演算法。
- 流形學習:IsoMap、LLE、拉普拉斯特徵對映、t-SNE、UMAP、PCA、核PCA、概率PCA、GHA、隨機投影、ICA。
- 多維標度:經典MDS、等滲MDS和Sammon對映。
- 最近鄰搜尋:BK樹、覆蓋樹、KD樹、SimHash、LSH。
- 序列學習:隱馬爾可夫模型,條件隨機場。
- 自然語言處理:分句器和標記器、雙元統計測試、短語提取器、關鍵詞提取器、詞幹分析器、詞性標註、相關性排序
使用(Java等整合)
maven引入
<dependency>
<groupId>com.github.haifengl</groupId>
<artifactId>smile-core</artifactId>
<version>2.6.0</version>
</dependency>
Shell使用
模型序列化
大多數模型支援Java可序列化介面(所有分類器都支援可序列化介面),因此您可以在Spark中使用它們。
對於在非Java程式碼中讀/寫模型,我們建議使用XStream以序列化訓練的模型。XStream是一個簡單的庫,用於將物件序列化為XML並再次序列化。XStream易於使用,不需要對映(實際上不需要修改物件)。Protostuff是一個很好的替代方案,它支援向前向後相容性(模式演化)和驗證。除了XML之外,Protostuff還支援許多其他格式,如JSON、YAML、protobuf等。
視覺化
Smile提供了一個基於Swing的資料視覺化庫SmilePlot,它提供散點圖、線圖、階梯圖、條形圖、方框圖、直方圖、3D直方圖、樹狀圖、熱圖、hexmap、QQ圖、等高線圖、曲面和線框。
需要引入庫
<dependency>
<groupId>com.github.haifengl</groupId>
<artifactId>smile-plot</artifactId>
<version>2.6.0</version>
</dependency>
Smile還支援宣告方式的資料視覺化。使用mile.plot.vega軟體包,我們可以建立一個規範,將視覺化描述為從資料到圖形標記(如點或條)屬性的對映。
該規範基於Vega-Lite。Vega-Lite編譯器自動生成視覺化元件,包括軸、圖例和比例。然後,它根據一組精心設計的規則確定這些元件的屬性。
範例
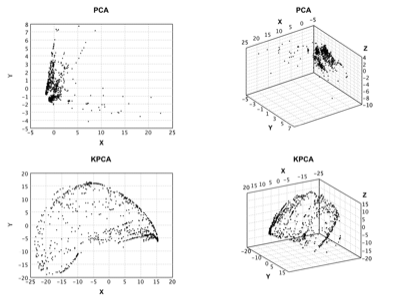
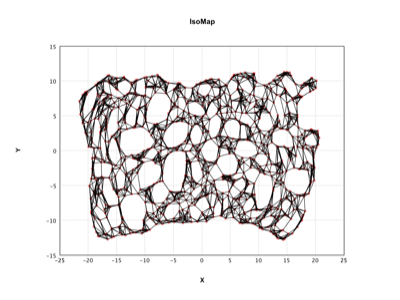
作者:馬洪彪 
出處:http://www.cnblogs.com/mahongbiao/
本文版權歸作者和部落格園共有,歡迎轉載,但未經作者同意必須保留此段宣告,且在文章頁面明顯位置給出原文連線,否則保留追究法律責任的權利。