分散式協同AI基準測試專案Ianvs:工業場景提升5倍研發效率
摘要:全場景可延伸的分散式協同AI基準測試專案 Ianvs(雅努斯),能為演演算法及服務開發者提供全面開發套件支援,以研發、衡量和優化分散式協同AI系統。
本文分享自華為雲社群《KubeEdge|分散式協同AI基準測試專案Ianvs:工業場景提升5倍研發效率》,作者 華為雲|鄭子木。
在邊緣計算的浪潮中,AI是邊緣雲乃至分散式雲中最重要的應用。隨著邊緣裝置的廣泛使用和效能提升,將人工智慧相關的部分任務部署到邊緣裝置已經成為必然趨勢。
KubeEdge-Sedna子專案,作為業界首個分散式協同AI框架,基於KubeEdge提供的邊雲協同能力,支援現有AI類應用無縫下沉到邊緣,降低分散式協同機器學習服務構建與部署成本、提升模型效能、保護資料隱私等。
本篇文章為大家闡釋分散式協同AI技術背景,研發落地三大生態挑戰和社群調研報告,並對全新社群SIG AI子專案(於KubeEdge Summit 2022 重磅釋出):全場景可延伸的分散式協同AI基準測試專案 Ianvs(雅努斯),進行介紹。該專案能為演演算法及服務開發者提供全面開發套件支援,以研發、衡量和優化分散式協同AI系統。歡迎關注Ianvs專案,持續獲得第一手獨家公開資料集與完善基準測試配套。開源專案GitHub地址:https://github.com/kubeedge/ianvs
01 分散式協同AI技術背景
隨著邊側算力逐步強化,時代也正在見證邊緣AI往分散式協同AI的持續演變。分散式協同AI技術是指基於邊緣裝置、邊緣伺服器、雲伺服器利用多節點分散式乃至多節點協同方式實現人工智慧系統的技術。雖然還在發展初期,分散式協同AI成為必然趨勢的驅動力主要有二。第一,由於資料首先在邊緣產生,有大量資料處理需要在邊側執行。第二,由於邊側逐步具備AI能力,高階資料處理需要在邊側執行。在實際應用場景中,以往常見的是雲上訓練、邊側推理模式,現在在各個場合已經頻繁聽到邊雲協同推理、邊雲協同增量學習、邊雲協同終身學習、聯邦學習等協同模式,可以看到邊緣AI向邊雲協同乃至分散式協同的演進正在發生。上述這些都使得我們有理由相信,分散式協同AI是大勢所趨。
關於分散式協同AI的產業發展形態,根據Research Dive Analysis預測,全球邊緣AI乃至分散式協同AI軟體(演演算法、平臺等)市場規模將從2019年的4.36億美元增長到2023年的30.93億美元。分散式協同AI解決方案市場規模比例顯著大於服務。也就是說,與直接提供通用服務相比,結合行業解決方案可能是分散式協同AI商業變現的主要途徑。至於與行業解決方案結合的話,據麥肯錫預測,邊緣AI乃至分散式協同AI至少覆蓋12個行業。可以看到,相關行業解決方案的市場領域多樣化,通過產業鏈聚攏乃至壟斷方式來收割商業價值無疑存在規模複製挑戰。因此,從產業發展形態出發考慮,一家企業獨大並不可取,與生態夥伴同行才有可能走得更遠。
鑑於上述分散式協同AI技術趨勢和產業發展形態,KubeEdge社群基於CNCF成熟治理模式,成立了KubeEdge SIG AI。其工作目標是基於 KubeEdge 的邊雲協同能力,提供具有低成本、高效能、易用性、隱私保護等優勢的邊緣智慧平臺。SIG AI工作範圍包括:
1、 構建分散式協同AI框架,高效合理利用端、邊、雲的各類資源,並能根據負載和應用型別實時地進行模型排程,實現高效能和低成本兼備的邊緣AI系統。
2、 構建分散式協同AI基準測試,識別AI系統中重要指標,幫助使用者評估邊緣AI系統的功能和效能,以衡量和優化分散式協同AI系統,揭露各應用場景的最佳實踐。
3、積極與周邊AI平臺、邊緣智慧硬體廠商等夥伴開展合作,實現自動化的異構資源匹配,減少使用者管理異構資源的工作量,提升AI 應用的部署管理維護效率。
02 分散式協同AI應用落地挑戰調研報告
KubeEdge SIG AI及整個行業各個技術方案落地與成果轉化到產業的程序正在緊鑼密鼓地進行,大家也經常提到sedna進入質檢、衛星和園區的案例。但僅憑技術是不足夠完成落地和產業轉化的。當前學界業界很多團隊已經遇到各式各樣的困難。社群從演演算法開發者、服務開發者和技術佈道者三種邊緣AI研發角色的需求出發,啟動了邊緣AI研發落地生態挑戰問卷調研,希望進一步瞭解邊緣AI方案落地與產業轉化過程中遇到的,諸如研發資源難獲取、工具鏈不完備等主要依賴社群分工與共用的生態挑戰。
截止2021年9月20日已回收有效答卷180份。調研結果發現了20+生態挑戰,問卷開放選項採集到49條補充意見和8條補充建議。
• 調研物件職業主要是工業界從業者(53.45%),其次是在校學生(31.03%)和學術界研究者(25.86%)。
• 調研物件的技術方向主要是邊緣AI及其應用(55.75%)、AI及其應用(49.43%)、邊緣計算及其應用(42.53%)。也有約四分之一的方向為雲端計算及其應用(25.86%),以及少量的其它方向(13.22%)。
基於調研結果已釋出業界首份邊緣AI落地生態挑戰調研報告,可通過下方二維條碼掃描獲取。我們也繪製了三種不同角色所反饋的生態挑戰詞雲。

報告的重點內容簡要介紹如下:
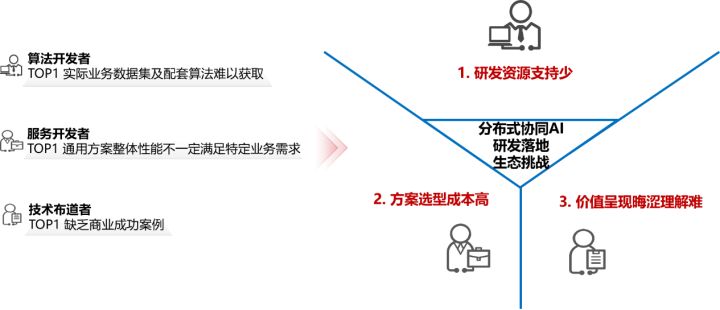
• 對於演演算法開發者排名第一的挑戰是實際業務資料集及配套演演算法難以獲取,排名第二的挑戰是重複部署整套端邊雲系統過於沉重。從中我們可以對於演演算法開發總結出研發資源支援少的生態挑戰。
• 對於服務開發者排名第一的挑戰是通用方案整體效能不一定滿足特定業務需求,排名第二的挑戰是自研業務演演算法和系統方案週期長成本高。從中我們可以針對服務開發總結出方案選型成本高的生態挑戰。
• 對於技術佈道者排名第一的挑戰是缺乏商業成功案例,排名第二的挑戰是缺乏與現有方案系統對比,包括成本、部署要求。從各挑戰中可以針對技術佈道者總結出價值呈現晦澀理解難的生態挑戰。
基於本次調研,我們從剛剛提到的幾個挑戰出發,進一步瞭解這個領域各位開發者的心聲和行業痛點,探索可能的解決方案。
核心痛點I:業務資料集及其配套演演算法難以獲取
在調研過程,演演算法開發者跟社群反饋得最多的還是業務資料集機器配套演演算法難以獲取
• 正在打造邊緣AI演演算法利器,有什麼實際業務可以練兵嗎,在哪找?
• 我認識一家邊緣計算公司在做工業質檢,質檢靠譜資料有嗎?可以先試一試。
• 公開資料集太多,大海撈針翻到頭都禿了。
• 資料集要麼質量不太高,或者要麼跟具體業務不太匹配……
• 真實、好用的資料集說起來輕巧,但新業務資料集找起來太累了吧。
• 也不知道找哪家公司合適;自己去買裝置採集?
從中可總結出核心痛點:業務資料集及其配套演演算法難以獲取,同時封閉測試環境難以跟上各類新業務孵化。同時看到第一個需求:分散式協同AI標準資料集和配套演演算法管理與下載,快速上手真實業務。
核心痛點 II:通用方案不滿足特定需求
在調研過程,服務開發者跟社群反饋得最多的則是通用方案不一定滿足特定業務需求。
• 業務問題多得很……一宿一宿睡不著,天天挨客戶罵,現場各種安撫疲於奔命。頂會論文?真的沒有時間看。
• 現有測試資料和指標要求與實際業務差距過大。聽說演演算法進展很快,但調研大半年,嘗試很多演演算法,要真正能做進客戶心窩裡還是很困難的。
• 新業務不斷產生,現有測試需要對應改進。但現有測試都是那幾個玩具資料集和指標,基準固化後還不能改。亟需針對特定場景個性化設定。
• 場景很多,問題更多。針對不同場景甚至相同場景的不同演演算法正規化要針對不同架構、介面和引數使用不同測試工具。這導致在不同邊側場景,進行各種測試實驗非常繁瑣。要規模化被迫採用簡單技術。
• 自研人力物力成本高,比如裝置貴、人才高薪。挑戰複雜難題?中小企業試試就逝世,不如交給大企業或者高校(躺)。
從中可總結出核心痛點:全場景多正規化測試成本高、個性化場景的測試用例準備繁瑣。同時看到第二個需求:個性化、全場景測試乃至自動化測試,對症下藥並降低研發成本。
03 分散式協同AI基準測試Ianvs專案開源釋出
針對上述痛點和挑戰,KubeEdge SIG AI也為大家帶來了一個全新的社群子專案 全場景可延伸的分散式協同AI基準測試工具 Ianvs來解決以上問題。藉助單機就可以完成分散式協同AI前期研發工作。專案地址:https://github.com/kubeedge/ianvs
全場景可延伸的分散式協同AI基準測試工具 Ianvs
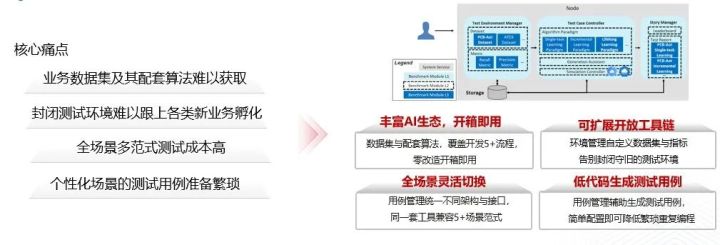
1、 針對業務資料集難以獲取,資料採集與處理成本高的痛點,ianvs提供豐富AI生態,做到開箱即用。ianvs開源資料集與5+配套演演算法,覆蓋預處理、預訓練、訓練、推理、後處理全流程,零改造開箱即用。
2、 針對封閉測試環境難跟上各類新業務孵化的痛點,ianvs提供可延伸開放工具鏈。測試環境管理實現自定義動態設定測試資料集、指標,告別封閉守舊的測試環境。
3、 針對全場景多正規化測試成本高的痛點,ianvs提供全場景靈活切換。ianvs測試用例管理統一不同場景及其AI演演算法架構與介面,能用一套工具同時相容多種AI正規化。
4、 針對個性化場景的測試用例準備繁瑣的痛點,ianvs提供低程式碼生成測試用例。ianvs測試用例管理基於網格搜尋等輔助生成測試用例,比如一個組態檔即可實現多個超參測試,降低超參搜尋時的繁瑣重複程式設計。
Ianvs同步釋出一個新的工業質檢資料集PCB-AoI。PCB-AoI 資料集是開源分散式協同 AI 基準測試專案 KubeEdge-Ianvs 的一部分。 Ianvs 很榮幸成為第一個釋出此資料集的站點,Ianvs 專案相關社群成員將PCB-AoI 公共資料集同時也放在 Kaggle和雲服務上方便各位下載。PCB-AoI工業質檢公開資料集下載連結請參見:https://ianvs.readthedocs.io/en/latest/proposals/scenarios/industrial-defect-detection/pcb-aoi.html

PCB-AoI資料集由KubeEdge SIG AI 來自中國電信和瑞斯康達的成員釋出。在這個資料集中,收集了 230 多個板,影象數量增加到 1200 多個。具體來說,資料集包括兩部分,即訓練集和測試集。訓練集包括 173 個板,而測試集包括 60 個板。也就是說,就 PCB 板而言,train-test 比率約為 3:1。進行了資料增強,將影象方面的訓練測試比率提高到 1211:60(約 20:1)。 train_data 和 test_data 的兩個目錄都包含索引檔案,用於關聯原始影象和註釋標籤。
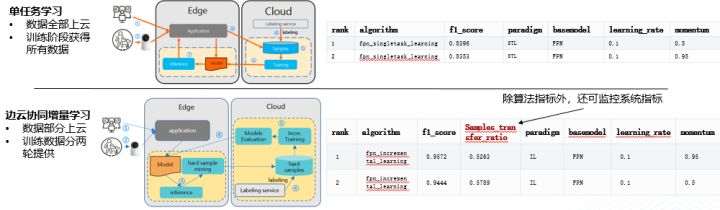
這裡同步展示一個Ianvs在工業場景的案例。本案例是基於PCB-AoI資料集的工業質檢。該案例基於工業視覺AoI裝置輸出視訊圖片,檢測PCB板是否存在貼裝異常。
案例提供了單任務學習和邊雲協同增量學習兩種正規化。在本案例的單任務學習正規化中,資料全部上雲,在訓練階段獲得所有資料。在本案例的邊雲協同增量學習正規化中,資料部分上雲,訓練資料分兩輪提供。Ianvs除演演算法指標外,還可監控系統指標,如樣本上雲比例指標。測試的基礎模型選用特徵圖金字塔網路FPN(Feature Pyramid Networks)。
基準測試結果顯示,待測FPN演演算法F1效能在0.84-0.95波動。邊雲協同增量學習可節省近50%的上雲資料量,同時獲得10%以上的精度提升。如下圖所示,增量前1處漏檢:僅檢出7處,增量後全部檢出:檢出全部8處缺陷。

Ianvs將提供開箱即用的資料集與配套演演算法,藉助支援多場景正規化切換和易擴充套件的工具鏈,以及測試用例的低程式碼自動生成能力,來降低開發者在分散式協同AI應用開發測試時的門檻,技術驗證時間半年降低到1個月,提升5倍研發效率。
Ianvs釋出之際在此也特別感謝社群10+初創單位。社群也持續募集在Ianvs專案上的合作伙伴,共同孵化開源專案、研究報告及行業標準等。

KubeEdge-Ianvs 初創單位
04 Ianvs未來工作展望
對於未來工作上,Ianvs專案希望進一步解決各位社群使用者的問題。
首先,演演算法開發者們投票第二位的挑戰是重複部署端邊雲系統費時費力的問題
• 只是想聚焦系統上的分散式排程而已,需要自己把遷移學習、增量學習、聯邦學習演演算法啥的協同機器學習演演算法學一遍很痛苦
• 想聚焦系統上的AI演演算法而已,真需要寫那麼多系統程式碼,把整一套邊雲協同系統自己搭起來非常不友善
• 費力氣搭系統,也不足以落地應用到工業界……工業界有些系統機制,包括模型管理和維護等,能為模型上線護航
• 好了,組裡花大錢搭起來,系統和演演算法終於能用了,但眼看著一年過去,馬上畢業來不及科研……AI系統的構建對於高校團隊來說費時過長成本過高,簡直大坑
• 很多公司已經有了,重複造輪子感覺憋屈。想在巨人肩膀上實現系統突破,搞大事情
因此第一項未來工作可以是實現工業級分散式協同系統模擬,提升方案研發效率。
另外一個未來工作,可以是關於技術佈道者和終端使用者的價值呈現問題
• 缺乏與先前方案的對比。受眾不明白什麼是邊緣,跟以前有什麼區別
• 客戶有資料,夥伴有研發,但因資料使用協定,資料無法出邊緣,經常需要駐場調整
• 沒有介面,缺乏demo,方案不直觀,客戶看不懂,沒有吸引力
因此第二項未來工作可以是演演算法/正規化測試排行與最佳方案展示,做好價值呈現。
Ianvs專案規劃路標如下圖。歡迎關注Ianvs專案,持續獲得第一手獨家公開資料集與完善基準測試配套。社群也持續募集在Ianvs專案上的合作伙伴,共同孵化開源專案、研究報告及行業標準等。開源專案GitHub地址:https://github.com/kubeedge/ianvs
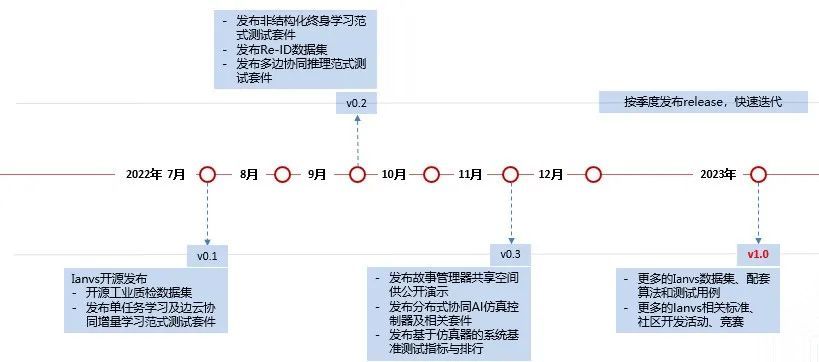
Ianvs 專案路標
新增KubeEdge小助手微信putong3333, 進群和社群成員一起交流。