R資料分析:用R建立預測模型
預測模型在各個領域都越來越火,今天的分享和之前的臨床預測模型背景上有些不同,但方法思路上都是一樣的,多瞭解各個領域的方法應用,視野才不會被侷限。
今天試圖再用一個範例給到大家一個統一的預測模型的做法框架(R中同樣的操作可以有多種多樣的實現方法,框架統一尤其重要,不是簡單的我做出來就行)。而是要:
eliminate syntactical differences between many of the functions for building and predicting models
資料劃分
通常我們的資料是有限的,所以首先第一步就是決定如何使用我們的資料,就這一步來講都有很多流派。
資料比較少的情況下,一般還是將全部資料都拿來做訓練,儘可能使得模型的代表性強一點,但是隨之而來的問題就是沒有樣本外驗證。上文寫機器學習的時候提到,樣本外驗證是模型評估的重要一步,所以一般還是會劃分資料。個人意見:好多同學就200多個資料,就別去劃分資料集了,全用吧,保證下模型效度。
我現在手上有資料如下:
這是一個有4335個觀測1579個變數的資料集,我現在要對其切分為訓練集和測試集,程式碼如下:
inTrain <- createDataPartition(mutagen, p = 3/4, list = FALSE)
trainDescr <- descr[inTrain,]
testDescr <- descr[-inTrain,]
trainClass <- mutagen[inTrain]
testClass <- mutagen[-inTrain]程式碼的重點在createDataPartition,這個函數的p引數指的是訓練集的比例,此處意味著75%的資料用來訓練模型,剩下的25%的資料用來驗證。使用這個函數的時候要注意一定是用結局作為劃分的依據,比如說我現在做一個死亡預測模型,一定要在生存狀態這個變數上進行劃分,比如原來資料中死亡與否的佔比是7:3,這樣我們能保證劃分出的訓練集死亡與否的佔比依然是7:3。
資料劃分中會有兩個常見的問題:一是zero-variance predictor的問題,二是multicollinearity的問題。
第一個問題指的是很多的變數只有一個取值,不提供資訊,比如變數A可以取y和n,y佔90%n佔10%,劃分資料後訓練集中有可能全是y,此時這個變數就沒法用了。為了避免這個問題我們首先應該排除資料集中本身就是單一取值的變數,還有哪些本身比例失衡的變數,可以用到nearZeroVar函數找後進行刪除。
第二個問題是共線性,解決方法一個是取主成分降維後重新跑,另一個是做相關,相關係數大於某個界值後刪掉,可以用到findCorrelation函數。
下面的程式碼就實現了去除zero-variance predictor和相關係數大於0.9的變數:
isZV <- apply(trainDescr, 2, function(u) length(unique(u)) == 1)
trainDescr <- trainDescr[, !isZV]
testDescr <- testDescr[, !isZV]
descrCorr <- cor(trainDescr)
highCorr <- findCorrelation(descrCorr, 0.90)
trainDescr <- trainDescr[, -highCorr]
testDescr <- testDescr[, -highCorr]
ncol(trainDescr)執行上面的程式碼之後我們的預測因子就從1575個降低到了640個。
接下來對於模型特定的預測演演算法,比如partial least squares, neural networks and support vector machines,都是需要我們將數值型變數中心化或標準化的,這個時候我們需要對資料進行預處理,需要用到preProcess函數,具體程式碼如下:
xTrans <- preProcess(trainDescr)
trainDescr <- predict(xTrans, trainDescr)
testDescr <- predict(xTrans, testDescr)在preProcess函數中,可以通過method引數很方便地對訓練資料進行插補,中心化,標準化或者取主成分等等操作,我願稱其為最強資料預處理常式。
建模與調參
建模是用train函數進行的,caret提供的預測模型建立的統一框架的精髓也在train函數中,我們想要用各種各樣的機器學習演演算法去做預測模型,就只需要在train中改動method引數即可,並且我們能用的演演算法也非常多,列舉部分如下:

另外一個值得注意的引數就是trControl,這個引數可以用來設定交叉驗證的方法:
trControl which specifies the resampling scheme, that is, how cross-validation should be performed to find the best values of the tuning parameters

比如我現在需要訓練一個logistics模型(大家用的最多的),我就可以寫出如下程式碼:
default_glm_mod = train(
form = default ~ .,
data = default_trn,
trControl = trainControl(method = "cv", number = 5),
method = "glm",
family = "binomial"
)在上面的程式碼中,我們設定了4個重要的引數:
一是模型公式form,二是資料來源data,三是交叉驗證方法,這兒我們使用的是5折交叉驗證,四是模型演演算法method。
我現在要訓練一個支援向量機模型,程式碼如下:
bootControl <- trainControl(number = 200)
svmFit <- train(
trainDescr, trainClass,
method = "svmRadial",
trControl = bootControl,
scaled = FALSE)上面的程式碼執行需要一點時間,我們是用自助抽樣法,抽樣迭代次數200次,也就是抽200個資料集,所以比較耗時。
支援向量機是有兩個超參的sigma和C,上面的結果輸出中每一行代表一種超參組合,通過上圖我們可以看到不同的超參組合下模型的表現

其中有一致性係數Kappa,如果我們的結局是十分不平衡的,這個Kappa就會是特別重要的評估模型表現的一個指標
Kappa is an excellent performance measure when the classes are highly unbalanced
我們發現超參取0.00137和2,模型會表現得更好,這個也成為我們的finalmodel。
預測新樣本
模型目前已經訓練好了,我們可以用訓練好的最好的模型finalmodel來預測我們的測試集,進而評估模型表現。預測新樣本的程式碼如下:
predict(svmFit$finalModel, newdata = testDescr)有時候我們會訓練不同演演算法的多個模型,比如一個支援向量機模型,另外一個gbm模型,這個時候使用predict也可以方便的得到多個演演算法的預測結果,只需要將模型放在一個list中即可。
另外還有extractProb和extractPrediction兩個函數,extractPrediction可以很方便地從預測模型中提出預測值,extractProb可以提出預測概率。
評估模型表現
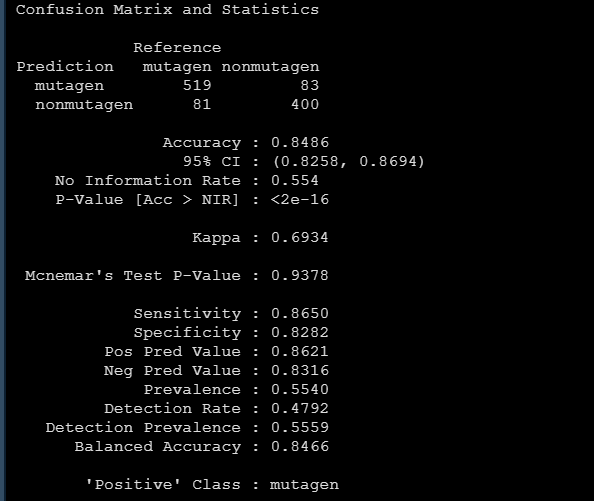
對於分類問題,我們可以用confusionMatrix很方便地得到下面的模型評估指標:
還有要報告的ROC曲線:
svmROC <- roc(svmProb$mutagen, svmProb$obs)
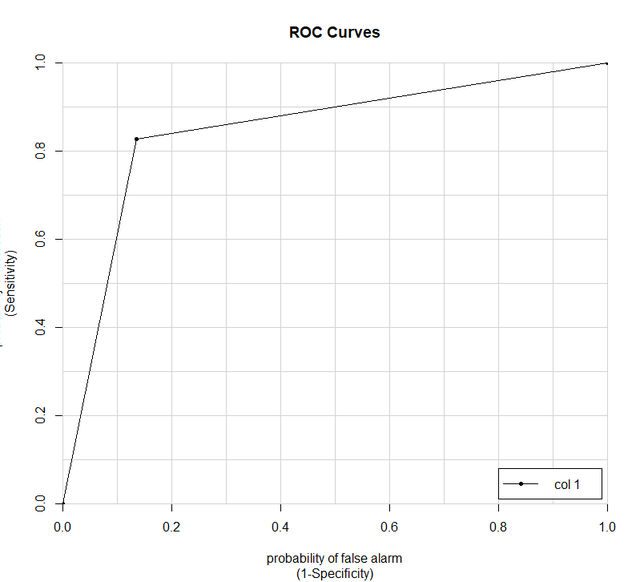
aucRoc則可以幫助我們快速地得到曲線下面積。
對於迴歸問題,評估模型表現的時候就沒有所謂的accuracy and the Kappa statistic了,我們關心R2,plotObsVsPred可以方便地畫出實際值和預測值的走勢,關心rmse和mae,calc_rmse函數可以幫助計算rmse,get_best_result函數可以輸出R方等指標。
預測因子選擇
預測因子的重要性作圖,有時候我們的資料變數很多,或者叫維度很多,從而導致維度災難,好多的預測因子其實並不能給模型提供資訊,預測因子的選擇則是要在儘量使得模型精簡的情況下不損害模型的表現。
varImp可以幫助我們檢視各個預測因子對模型的貢獻重要性,並且這個重要性是以得分的形式給出的,分怎麼計算的,我也不知道。獲得各個預測因子重要性得分的程式碼如下:
varImp(gbmFit, scale = FALSE)
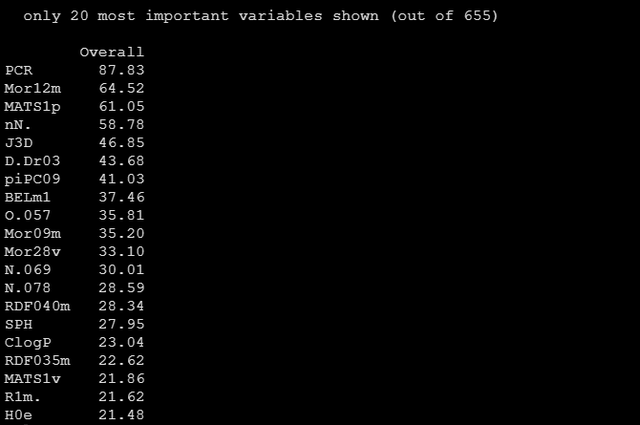
更直觀的我們將該物件plot下,就可以得到預測因子重要性的麵條圖如下:
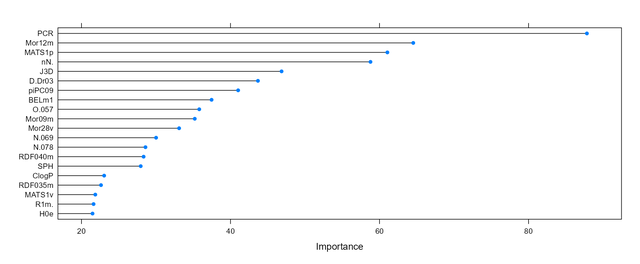
上面的圖中只列出了重要性前20的變數,我們其實是有655個變數的,但是有200多個的重要性得分均為0,所以跑模型的時候其實是可以完全不要它們的。
小結
今天給大家簡單介紹了在caret中做預測模型的一些知識,感謝大家耐心看完,自己的文章都寫的很細,重要程式碼都在原文中,希望大家都可以自己做一做,