位元組跳動端智慧工程鏈路 Pitaya 的架構設計
Client AI 是位元組跳動產研架構下屬的端智慧團隊,負責端智慧 AI 框架和平臺的建設,也負責模型和演演算法的研發,為位元組跳動開拓端上智慧新場景。本文介紹的 Pitaya 是由位元組跳動的 Client AI 團隊與 MLX 團隊共同構建的一套端智慧工程鏈路。
作者|覃量
1、Client AI-Pitaya 定位
這些年,隨著演演算法設計和裝置算力的發展,AI 的端側應用逐步從零星的探索走向規模化應用。行業裡,FAANG、BAT 都有眾多落地場景,或是開創了新的互動體驗,或是提升了商業智慧的效率。
Client AI是位元組跳動產研架構下屬的端智慧團隊,負責端智慧AI框架和平臺的建設,也負責模型和演演算法的研發,為位元組跳動開拓商業智慧新場景。
Pitaya則是由位元組跳動的Client AI 團隊與 MLX 團隊共同構建的一套端智慧工程鏈路,為端智慧應用提供從開發到部署的全鏈路支援。
Pitaya的願景是打造行業領先的端智慧技術,助力位元組智慧商業化應用。我們通過 AI 工程鏈路為端智慧業務提供全鏈路支援;通過 AI 技術方案,幫助業務提升指標、降低成本、改善使用者體驗。
迄今為止,Pitaya端智慧已經為抖音、頭條、西瓜、小說等應用的 30+場景提供了端智慧支援,讓端智慧演演算法包在手機端每天萬億生效次數的同時,錯誤率控制在不到十萬分之一。

2、Pitaya 架構
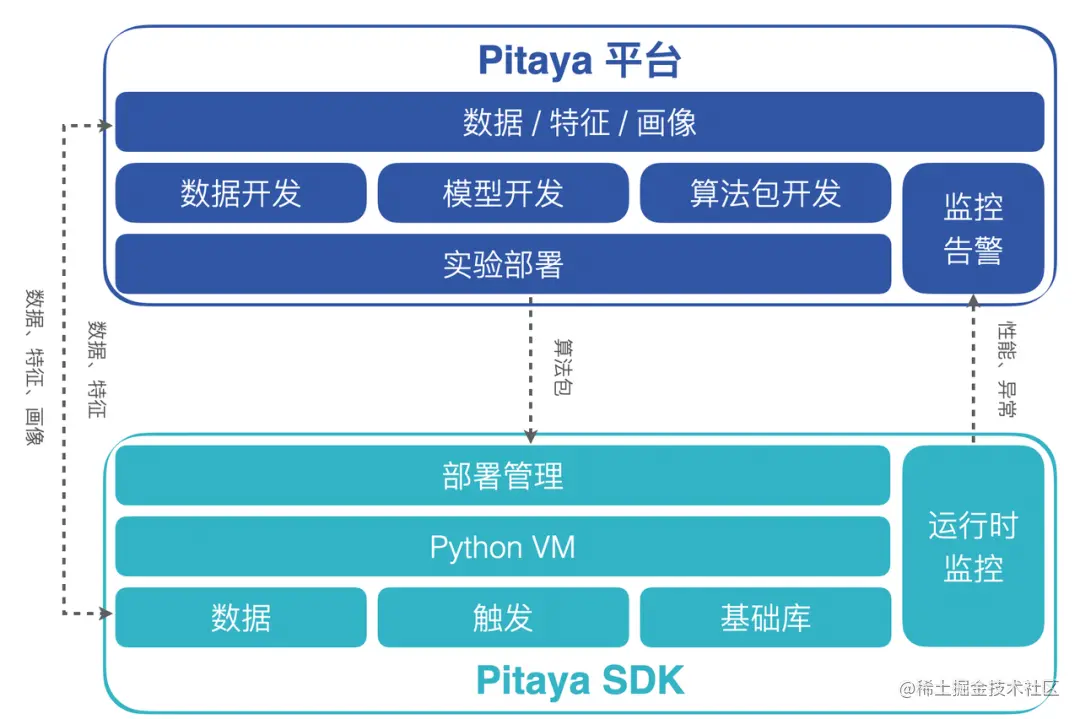
在這一節我們來詳細介紹一下Pitaya架構的兩個最核心的部分:Pitaya平臺和Pitaya SDK。
-
Pitaya 平臺為端上AI提供了工程管理、資料接入、模型開發、演演算法開發和演演算法包部署管理等一系列的框架能力。在端上演演算法策略開發過程中,Pitaya 平臺支援在AB平臺對端智慧演演算法策略進行實驗,驗證演演算法策略的效果。除此之外,Pitaya 平臺還支援對端上AI的效果進行實時的監控和告警設定,並在看板上進行多維度的分析與展示。
-
Pitaya SDK為端智慧演演算法包提供了在端上的執行環境,支援端上AI在不同裝置上高效地運轉起來。Pitaya SDK同時還支援在端上進行資料處理和特徵工程,提供了為演演算法包和AI模型提供版本和任務管理、為端上AI執行的穩定和效果進行實時監控的能力。
3、Pitaya 平臺
3.1 Pitaya Workbench
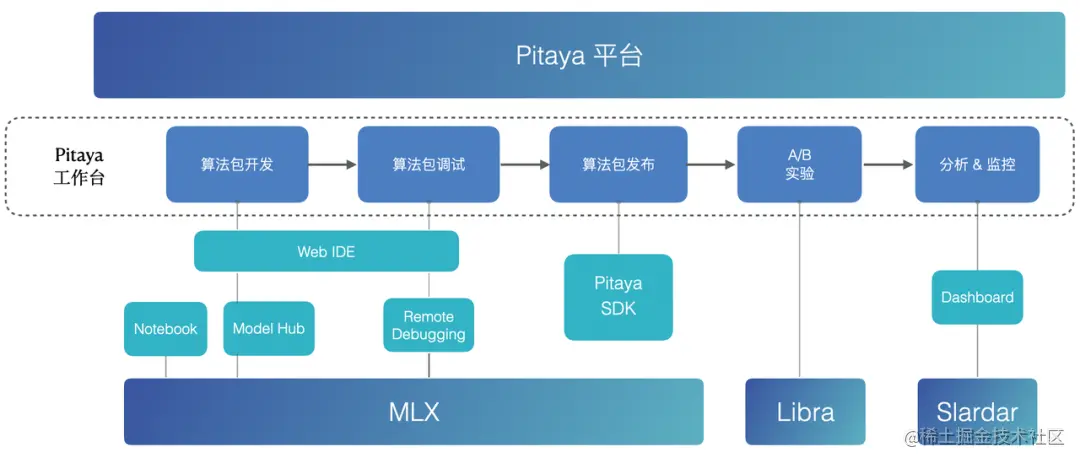
*MLX: 位元組通用機器學習平臺
*Libra: 位元組大規模線上AB實驗評估平臺
*Slardar: 位元組效能和體驗保障的端監控APM平臺
Pitaya平臺為演演算法包的開發、管理、偵錯、釋出、部署、實驗、監控提供了一套完善易用的Pitaya Workbench。
-
為了提高演演算法開發效率,Pitaya Workbench為演演算法工程師提供了一套可以方便設定資料、模型、演演算法的開發環境。
-
為了簡化偵錯,Pitaya Workbench在 WebIDE 上實現了真機聯調,支援斷點、SQL 執行等能力。
-
為了驗證AI策略效果,Pitaya平臺打通了位元組的 A/B 實驗平臺 Libra ,從而實現更靈活的實驗環境設定。
-
為了保證端上AI的效果和穩定性,Pitaya平臺提供監控告警能力來監控演演算法包的效能、成功率等執行指標,以及端上模型的準確率、AUC等模型效果指標,並在Dashboard中進行視覺化展示。
3.2 機器學習平臺
為了應對巨量資料處理、深度學習模型訓練需求,Pitaya平臺連通位元組MLX平臺,為通用機器學習場景提供一套自研的雲端共同作業式Notebook解決方案。
MLX Notebook內建Spark 3.0以及Flink等巨量資料計算引擎,和local、yarn、K8S等多種資源佇列,可以將多種資料來源(HDFS / Hive / Kafka / MySQL)和多種機器學習引擎(TensorFlow, PyTorch, XGBoost, LightGBM, SparkML, Scikit-Learn)連線起來。同時MLX Notebook還在標準SQL的基礎上拓展了MLSQL運算元,可以在底層將SQL查詢編譯成可以分散式執行的工作流,完成從資料抽取,加工處理,模型訓練,評估,預測,模型解釋的Pipeline構建。
4、Pitaya SDK
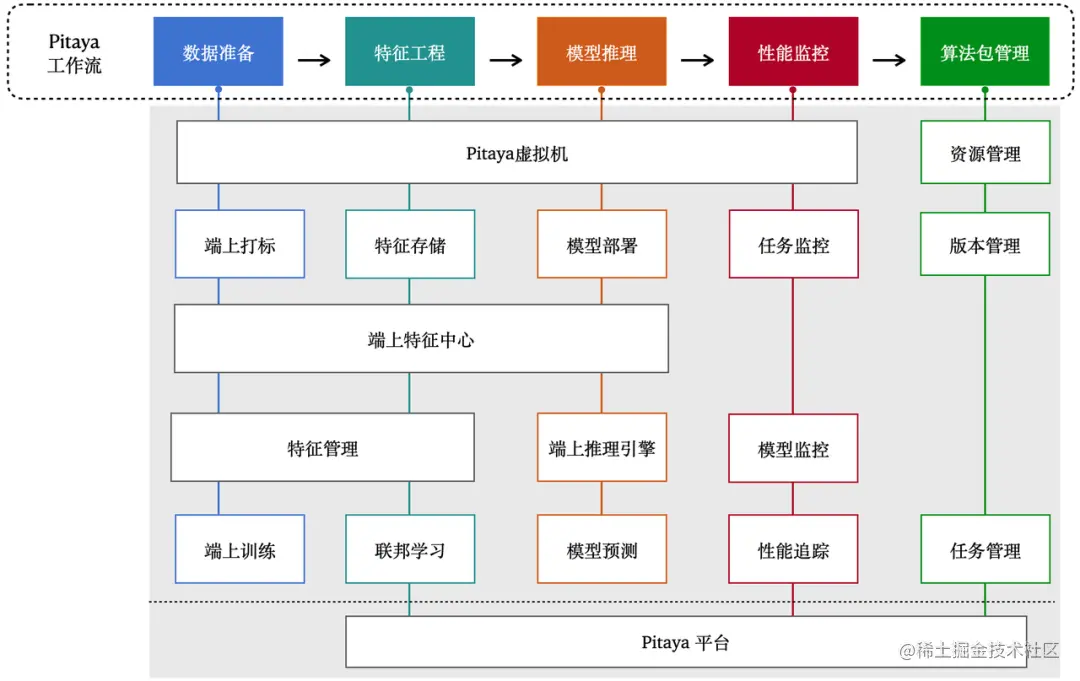
4.1 端上AI環境
4.1.1 端上虛擬機器器
Pitaya SDK 的核心是自研實現的端上虛擬機器器 - PitayaVM,為演演算法包和端上模型在手機端上執行提供了必要的環境。為了能夠讓虛擬機器器在端上執行,解決端上虛擬機器器存在的效能差、體積大的問題,Pitaya在保留了大部分的核心功能的同時,對虛擬機器器做了許多優化:
-
輕量:包體積影響使用者更新升級率。通過對核心、標準庫進行功能裁剪,優化程式碼實現,並開發自研工具對包體積進行詳細解析,PitayaVM的包體積在保證核心功能的同時,包體積縮減到了原來的10%以下,控制在了1MB以內。
-
高效:PitayaVM在保持輕量的同時,效能上也進行了對應的優化。在容器操作、數值統計場景處理的效能甚至超越了Android和iOS上的原生效能。同時虛擬機器器也支援並行執行演演算法程式碼,大幅度提升執行效率。除此之外,PitayaVM還支援通過JIT的方式優化在Android上的執行效能,開啟JIT後可以提升將近30%的表現。
-
安全:PitayaVM使用自研的位元組碼和檔案格式,確保檔案和虛擬機器器的安全性。
對於嚴格要求體積的產品線(比如ToB業務),還可以選用Pitaya SDK的MinVM方案,通過自研輕量級直譯器,在PitayaVM的基礎上進行極致輕量優化,將包體積壓縮到100KB以內。
4.2 端智慧核心流程
4.2.1 資料準備
Pitaya SDK提供了對資料準備流程的一系列支援。提供從裝置、應用、業務、端上特徵中心,雲端裝置畫像平臺、搜推廣模組獲取特徵資料的能力。同時Pitaya SDK也支援在端上進行動態labeling來對資料進行標註,提升訓練資料質量,進而提高階上模型效果。
4.2.2 端上特徵工程
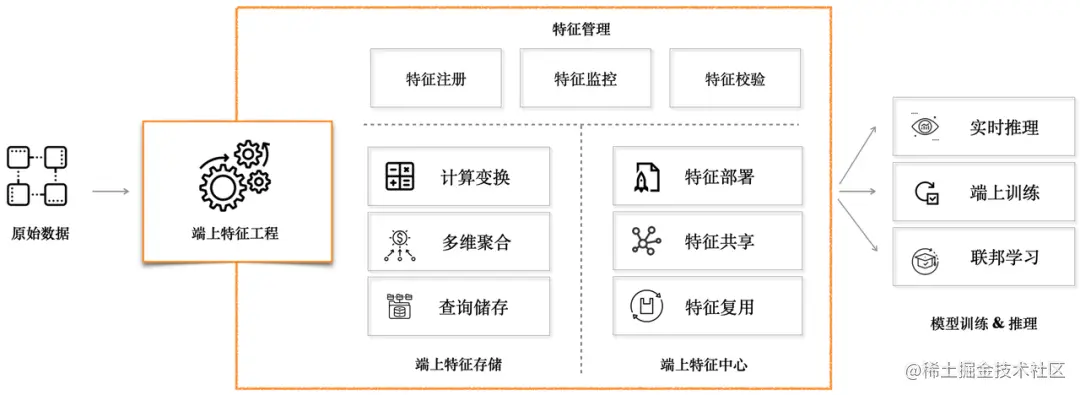
端上特徵工程分成三個主要部分:「特徵管理」、「端上特徵儲存」、「端上特徵中心」。
特徵儲存
Pitaya SDK提供了KV和SQL lite等多種方式的特徵儲存,在端上實現了類似於Redis和Hive的資料儲存模組。同時Pitaya SDK也提供針對端上進行裁剪優化的numpy、MobileCV、MLOps等基礎庫,以相容更多格式的資料、提供更復雜的端上資料處理能力。
Pitaya SDK提供的高時效、多維度、長序列特徵和合規允許下的隱私資料,除了可以支援相當比例的端內決策,還可以進一步加工特徵、樣本,為雲端模型推理、訓練提供支援,進而支援CV、NLP、資訊流等不同的端上智慧場景。
端上特徵中心
Pitaya SDK提供一個端上特徵中心模組,通過對端上的豐富多樣的特徵資料進行多維度的整合和管理,來讓不同的端上業務場景方便高效地消費、共用、客製化、複用各自的特徵資料。端上特徵中心可以通過中心化部署的形式,自動化地通過時間、應用生命週期、甚至自定義的session來對特徵資料進行整合和生產,然後提供給不同的模組進行使用,顯著提高特徵開發效率。同時由於資料的生產、消費都在本地,整個過程可以實現毫秒級的資料時效。
特徵管理
端上資料來源豐富,特徵生產靈活,可以經過端上特徵工程處理後得到較複雜高階的端上特徵,還可以進行二次特徵交叉後再提供給業務場景進行消費。針對端上特徵的這種特性,Pitaya SDK在端上維護了一套特徵管理機制,做到特徵上下游生產可靠、可維護、可溯源。同時提供以下能力:
-
端上特徵監控:特徵管理模組對端上特徵建立了一系列校準和監控,實時監控端上特徵缺失、特徵值異常、特徵值偏移等情況,確保端上特徵的正常生產。
-
端上特徵地圖:為了實現跨團隊的特徵共用與共同作業,特徵管理模組提供端上特徵地圖的能力,讓不同業務團隊都可以通過特徵地圖對裝置上的特徵進行發現、檢索、貢獻和管理。端上特徵地圖提供一套新增和使用特徵的標準規範,並可以通過建立特徵組,為特徵新增metadata資訊來最大化降低對特徵含義的理解成本,提高特徵建設和複用的效率。
4.2.3 端上模型推理
Pitaya SDK對AI模型在端上的部署和實際應用進行了深度優化,連通位元組自研的高效能異構推理引擎框架,Client AI團隊開發的機器學習決策樹推理引擎ByteDT,以及AML團隊談發的位元組TVM引擎,讓AI模型可以在端上進行快速部署和高效能推理。目前Pitaya SDK支援的端上推理引擎可以覆蓋大部分端上AI場景,並提供完善的工具鏈支援,包括:
-
高相容:支援將業務主流框架訓練的模型(Caffe、Pytorch(ONNX)、TensorFlow(tflite)、XGBoost、CatBoost、LightGBM、...)轉換成端上支援的模型格式並進行壓縮量化。覆蓋CV、Audio、NLP等多個業務領域的常用OP,在端上相容全部安卓機型和iOS機型。
-
高通用:支援CPU/GPU/NPU/DSP/CUDA等處理器、可以結合處理器硬體情況、當前系統資源佔用情況進行擇優選擇與排程。
-
高效能:支援多核並行加速和低位元計算(int8,int16,fp16),降低功耗的同時提升效能,整體效能在業界持續保持領先。
4.3 端智慧核心配套能力
4.3.1 端監控
端監控模組提供對端上AI耗時、成功率、大盤穩定性和模型效果的主動監控。
使用者端在推理任務執行過程中,會自動監控演演算法包執行關鍵鏈路上的效能並進行埋點,然後針對不同型別的埋點,上報到不同的平臺進行相應的展示。
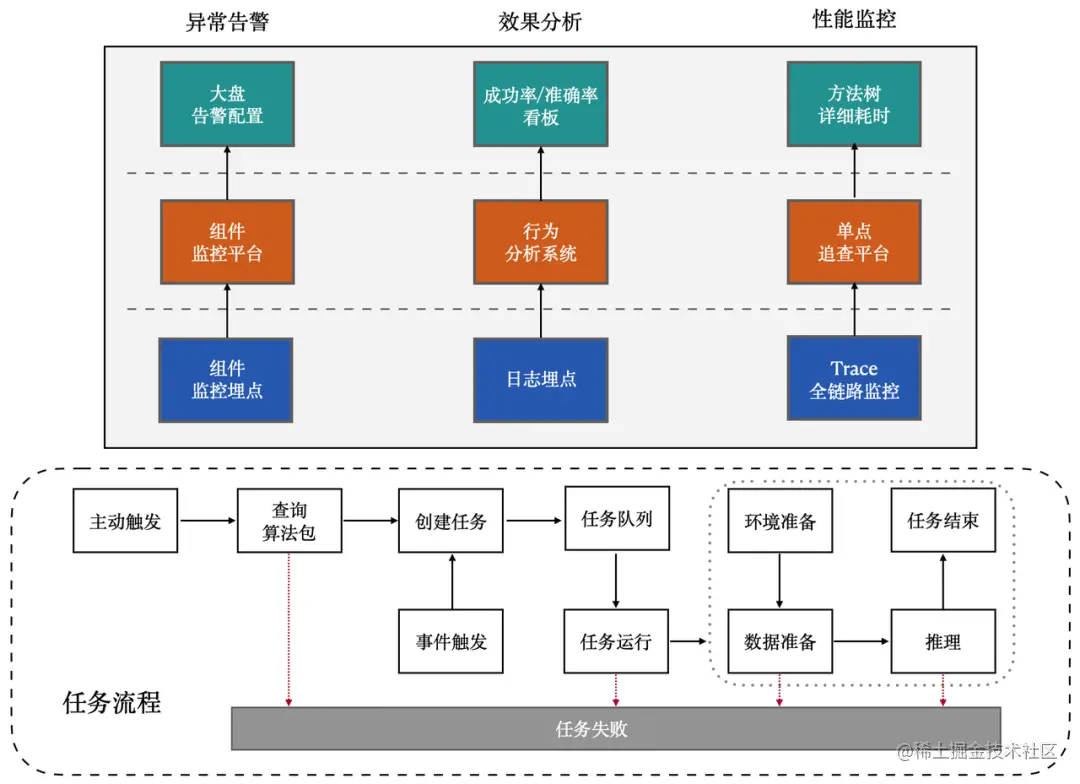
對應不同的平臺,端監控支援:
-
在元件監控平臺上,通過自定義設定的形式為大盤的穩定性,比如整體演演算法包執行耗時、人均觸發次數等指標客製化化告警設定以及告警頻率。
-
在行為分析系統上,埋點演演算法包執行結果和行為,通過 報表/看板 展示演演算法包執行成功率、模型推理準確度等資訊。
-
在單點追查平臺上,針對推理耗時太長的問題,檢視方法樹的詳細耗時。
4.3.2 演演算法包管理
資源管理資源管理具備對演演算法包的更新、下線、版本相容等能力,讓演演算法包能夠自動絲滑地部署在端上;同時還維護了一整套的使用者端AI執行環境。經過長時間的磨練,我們提供了這些功能:
-
客製化下發:支援按需下發和手動下發等不同的下發方式,兼顧可用性和使用者體驗。
-
靈活觸發:支援多種演演算法包觸發方式,可以通過定時、事件、以及自定義的方式在業務期望的時機點去執行端上AI模型或策略。
-
環境隔離:針對不同演演算法包的不同環境依賴,以及相同依賴不同版本之間的相容性,提供了模組隔離的環境;同時提供模組快取和釋放能力,避免模組頻繁切換,兼顧了執行速度和記憶體佔用。
任務管理
由於資料和模型都在端上進行計算和推理,不需要依賴網路,也沒有網路延遲。因此端上AI相比雲端AI的耗時低非常多,使得端上AI可以做到頻率更高,響應更快。任務管理專門對應端上AI的特性進行設計,支援了多種能力:
-
高並行:支援多工並行、多執行緒排程的任務管理模式來給AI任務保證一個高效的執行環境。
-
熔斷保護:為了保證業務核心場景的穩定性,Task Management模組支援熔斷保護,對於連續N次執行失敗,或者連續N次導致崩潰的演演算法包,我們會進行熔斷,暫時阻止其執行。
-
優先排程:當業務場景較多時,高頻觸發推理任務可能導致任務堆積。為了保證高優任務的優先順序,我們支援通過優先順序對任務進行排程;此外,實時性較高的場景下,我們還支援合併處於待執行狀態的中間任務,保證任務響應的實時性。
-
防卡死:演演算法程式碼動態性較高,可能會引入死迴圈,端上若執行包含死迴圈程式碼的推理任務,會導致資源持續佔用。為此我們開發了卡死檢測功能,檢測到死迴圈後,會在直譯器層面退出死迴圈,並清理環境和恢復直譯器,以保證正常任務排程。
4.3.3 聯邦學習
為了保障使用者的資料隱私,Pitaya SDK提供Pitaya聯邦學習模組,支援在不上傳任何隱私資料的情況下訓練AI模型。在這個過程中,AI模型訓練只依賴於經過隱私保護和加密技術處理後的端上模型更新結果,使用者相關的資料不會被傳送到雲端儲存,也無法反推出原始資料資訊,實現了模型訓練和雲端資料儲存的解耦。除此之外,Pitaya SDK還支援直接在端上進行模型訓練、部署和迭代,來實現千人千模或者千人百模的使用者個性化模型。
為了保證使用者體驗,Pitaya FL在端上實現了一套自動排程方案,只有在裝置同時滿足空閒、充電以及有wifi連線狀態下才會進行聯邦學習訓練,整個過程不會對裝置造成任何影響。
Pitaya 未來建設
位元組Client AI團隊的端智慧架構Pitaya目前已經為端智慧提供了一套完善成熟的開發平臺,為端智慧開發workflow中的各項環節都提供了完整易用的功能模組,並在SDK裡提供了業界領先的端上虛擬機器器、特徵、監控、推理引擎支援。
在未來的幾個月,位元組Pitaya會致力於進一步建設端到端的 AI 工程鏈路,覆蓋開發、迭代、監控流程,提升業務 AI 演演算法研發能效。同時我們計劃在目前已經趨近成熟的端智慧架構上,沉澱更多可複用的 AI 應用能力,實現 AI 能力在應用間、To B 的高效遷移,將端上AI進行規模化應用。
Client AI團隊一直在招募傑出人才,包括端智慧演演算法工程師、端智慧應用工程師(iOS/Android)、端智慧資料研發工程師等崗位,來讓我們在這個領域上創造自己的影響力。如果你對端智慧有熱情,動力,經驗,歡迎加入我們團隊,一起探索端智慧的可能性~
聯絡郵箱:[email protected]