涉及區間的查詢
1.找出一系列連續的值
問題:判斷哪些行表示一系列連續的專案。即某一行專案開始時間和前一行的專案結束時間是一致的。
範例表:
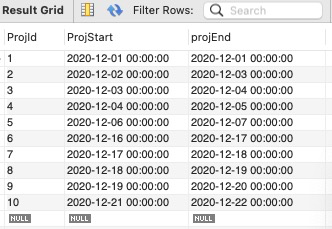
解決方案:利用窗函數 LEAD OVER 來查詢下一行的專案開始時間,從而避免使用自連結。需要按照專案ID進行排序。
select * from ( select ProjId 專案ID,ProjStart 專案開始時間,projEnd 專案結束時間,lead(ProjStart) over(order by ProjId ) 下一行專案開始時間 from projs ) V where 專案結束時間 = 下一行專案開始時間
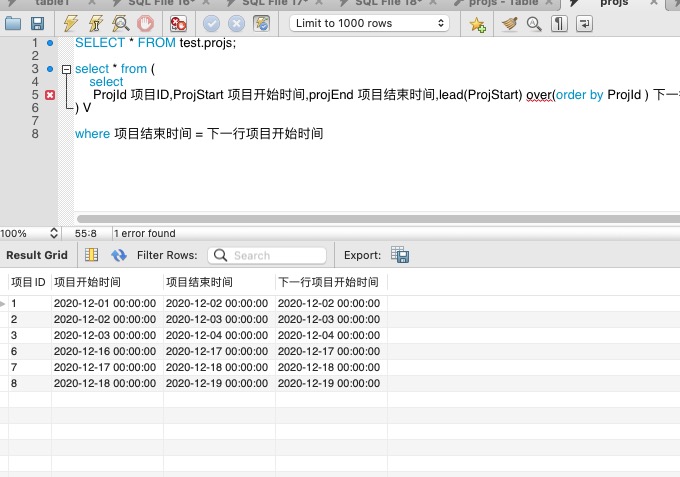
注意:使用視窗函數時,別忘了它們是在 From 和 Where 子句之後執行的。
使用自連線:
select * from ( select a.ProjId 專案ID,a.ProjStart 專案開始時間,a.projEnd 專案結束時間,b.ProjStart 下一行專案開始時間 from projs a join projs b on a.ProjId = b.ProjId-1 ) V
2.找出同一個分組或分割區中相鄰行的差
問題:返回每位員工的 部門編號,姓名,薪水以及與當前部門中(部門編號相同)下一位員工的薪水差。這裡的下一位員工是通過獲聘時間確定的。對於每個部門最後獲聘的員工,將薪水差設定為 N/A。
範例表:
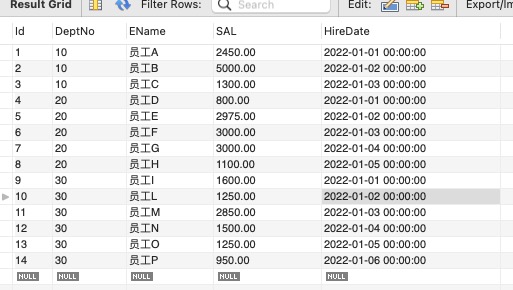
解決方案:同樣使用窗函數 LEAD OVER 存取下一行資料。因為比較的同部門的薪水,所以需要使用 PARTITION BY 部門編號 進行分割區。
with next_sal_table (DeptNo,EName,SAL,HireDate,Next_Sal) as ( select DeptNo,EName,SAL,HireDate,lead(SAL) over(partition by DeptNo order by HireDate) as Next_Sal from emps ) select DeptNo,EName,SAL,HireDate,coalesce(cast(SAL-Next_Sal as char),'N/A') from next_sal_table
為了展示解決方案的多樣性,這裡使用了 CTE (公用表表示式)。這裡為了將 NULL 設定為 ‘N/A’ 使用了 COALESCE 函數,返回NULL列表中的第一個非值。
在使用函數 LEAD OVER 時需要考慮存在重複值的情況。如果在上述表中存在相同部門相同獲聘時間的員工資料,那麼上述SQL語句就不正確了。因為需要的事當前員工與不同獲聘日期的下一個員工的薪水差。這裡我們往上數表中插入部門編號為10 獲聘日期都是 ‘2022-01-02’ 的員工資料。
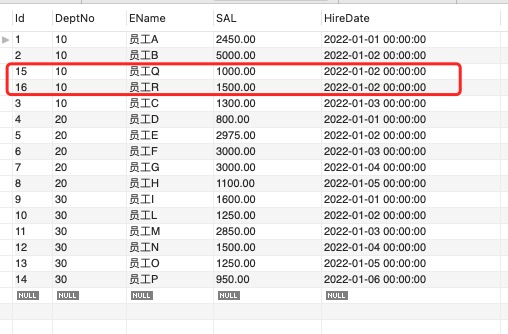
這種情況需要跳過相同獲聘日期的資料,函數 LEAD支援傳入跳過的行數。
解決方案:先計算出相同部門相同獲聘日期員工的數量以及當前資料在這個分組的序號,cnt-rn+1 便是需要跳過的行數。
select DeptNo,EName,SAL,HireDate,coalesce(cast(SAL-Next_Sal as char),'N/A') from ( select DeptNo,EName,SAL,HireDate, lead(SAL,cnt-rn+1) over(partition by DeptNo order by HireDate) as Next_Sal from ( select DeptNo,EName,SAL,HireDate,count(*) over(partition by DeptNo,HireDate) as cnt,row_number() over(partition by DeptNo,HireDate order by Sal) rn from emps ) a ) next_sal_table
3.找出連續值構成的區間的起點和終點
問題:找出連續值構成的區間,並只返回區間的起點和終點。跟上面第一個範例不同,如果某行並非一組連續值的一部分,依然要返回它。因為其自身構成區間的起點和終點。
解決方案:首先找出所有的區間。使用窗函數 LAG Over 判斷當前行的專案開始日期是否與上一行的專案結束日期是否一致,如果一致則屬於分組的一部分。如果某行的專案開始日期不與上一行一致,專案結束日期也不與下一行一直,則它自己構成一組。
找出所有分組後,給各組編號。最後找出每組的開始日期和結束日期。
select proj_group,min(ProjStart),max(projEnd) from ( select *,sum(flag) over(order by ProjId) as proj_group from ( SELECT ProjId ,ProjStart ,projEnd , case when lag(projEnd) over(order by ProjId ) = ProjStart then 0 else 1 end flag from projs ) a ) b group by proj_group
下面分步講解:
1.找出各個組,並給每個組的第一行做標記
SELECT ProjId ,ProjStart ,projEnd , case when lag(projEnd) over(order by ProjId ) = ProjStart then 0 else 1 end flag from projs
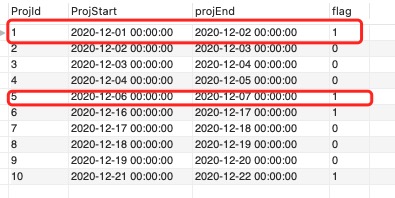
2.使用滑動小記 sum(flag) over(order by ProjId) as proj_group 將每個組內各行設定為同一個標記。
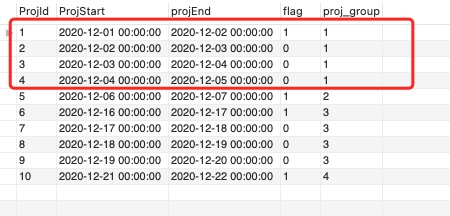
3.最後根據上面的組標記進行分組聚合,取最小開始日期為連續專案的開始日期,最大結束日期為連續專案的結束日期。
4.填補值區間空隙
問題:返回10年間每一年聘請的員工數,但其中有些年份並沒有聘請任何員工。
解決方案:建立一張包含 1到10 數位的透視表,也可以通過 CTE 的遞迴功能動態建立。根據透視表生成一個每個年份的臨時表,然後外連線根據員工表聘請年份分組統計的表。使用 coalesce 函數將沒有聘請資料的值設定為0。
WITH RECURSIVE Ta10 (id) as ( select 1 as id union all select id+1 from Ta10 where id <10 ) select * from Ta10
select y.yr,coalesce(x.cnt,0) as cnt from ( select min_year +rn as yr from ( select ( select min(extract(year from HireDate)) from emps) as min_year,id-1 as rn from t10 ) a ) y left join ( select extract(year from HireDate) as yr,count(*) as cnt from emps group by extract(year from HireDate) ) x on x.yr = y.yr
5.生成連續的數位值
上面已經實現了這個問題,使用 CTE (公用表表示式) 的遞迴功能可以解決這個問題。