效能調優讀書筆記(下篇)
一、並行程式開發優化
1、Future 設計模式

public class Client {
public Data request(final String queryStr){
final FutureData future=new FutureData();
new Thread(){
public void run(){
RealData realData=new RealData(queryStr);
future.setRealData(realData);
}
}.start();
return future;
}
}
public interface Data {
String getResult();
}
public class FutureData implements Data {
//FutureData是RealData的包裝
protected RealData realData=null;
protected boolean isReady=false;
public synchronized void setRealData(RealData realData){
if(isReady)
return;
this.realData=realData;
isReady=true;
notifyAll();
}
@Override
public synchronized String getResult() {
while (!isReady){
try {
wait();
} catch (InterruptedException e) {
e.printStackTrace();
}
}
return realData.result;
}
}
public class RealData implements Data {
protected final String result;
public RealData(String para){
//RealData的構造很慢
StringBuffer sb=new StringBuffer();
for (int i=0;i<10;i++){
sb.append(para);
try {
Thread.sleep(300);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
result=sb.toString();
}
@Override
public String getResult() {
return result;
}
}
2、Master-Worker 模式
Master-Worker 的好處是可以將大任務分為若干個小任務,並行執行。
public class Master {
//任務佇列
protected Queue<Object> workQueue=new ConcurrentLinkedQueue<>();
//Woker執行緒佇列
protected Map<String,Thread> threadMap=new HashMap<>();
//子任務的結果集
protected Map<String,Object> resultMap=new ConcurrentHashMap<>();
//是否所有子任務都結束了
public boolean isComplete(){
for (Map.Entry<String,Thread> entry:threadMap.entrySet()){
if(entry.getValue().getState()!=Thread.State.TERMINATED){
return false;
}
}
return true;
}
public Master(Worker worker,int countWorker){
worker.setWorkQueue(workQueue);
worker.setResultMap(resultMap);
for (int i = 0; i <countWorker ; i++) {
threadMap.put(Integer.toString(i),new Thread(worker,Integer.toString(i)));
}
}
//提交一個任務
public void submit(Object object){
workQueue.add(object);
}
//返回子任務結果集
public Map<String,Object> getResultMap(){
return resultMap;
}
//開始執行所有的Worker程序
public void execute(){
for (Map.Entry<String,Thread> entry:threadMap.entrySet()){
entry.getValue().start();
}
}
}
public class Worker implements Runnable {
//任務佇列,用於取得子任務
protected Queue<Object> workQueue;
//子任務處理結果集
protected Map<String,Object> resultMap;
public void setWorkQueue(Queue<Object> workQueue) {
this.workQueue = workQueue;
}
//子任務的處理邏輯,在子類中具體實現
public Object handle(Object input){
return input;
}
public void setResultMap(Map<String, Object> resultMap) {
this.resultMap = resultMap;
}
@Override
public void run() {
while (true){
Object input=workQueue.poll();
if(input==null)break;
Object result=handle(input);
resultMap.put(Integer.toString(input.hashCode()),result);
}
}
}
public class PlusWorker extends Worker {
@Override
public Object handle(Object input) {
if(input instanceof Integer){
Integer i=(Integer)input;
return i*i*i;
}
return 0;
}
}
測試程式碼:
@Test
public void test26(){
long start=System.currentTimeMillis();
Master master=new Master(new PlusWorker(),5);
for (int i = 0; i <100 ; i++) {
master.submit(i);
}
master.execute();
long re=0;
Map<String,Object> resultMap=master.getResultMap();
while (resultMap.size()>0||!master.isComplete()){
Set<String> keys = resultMap.keySet();
String key=null;
for (String k:keys){
key=k;
break;
}
Integer i=null;
if(key!=null)
i=(Integer)resultMap.get(key);
if(i!=null)
re+=i;
if(key!=null)
resultMap.remove(key);
}
System.out.println(re);
System.out.println(System.currentTimeMillis()-start);
}
3、優化執行緒池大小
Ncpu:CPU 的數量
Ucpu:目標 Cpu 的使用率 0<=Ucpu<=1
W/C:等待時間和計算時間的比率
最優執行緒池大小為:
Nthreads=NcpuUcpu(1+W/C);
4、擴充套件 ThreadPoolExecutor
ThreadPoolExecutor 是一個可以擴充套件的執行緒池,它提供了 beforeExecutor()和 afterExecutor()和 terminated()3 個方法進行擴充套件。
5、並行資料結構
- 並行 List
CopyOnWriteArrayList:適用於讀多寫少的場景 - 並行 Set
CopyOnWriteArraySet:適用於讀多寫少的場景,如果有並行寫的情況,也可使用 Collections.synchronizedSet(Sets)方法得到一個執行緒安全的 Set - 並行 Map
ConcurrentHashMap - 並行 Queue
JDK 提供了兩套實現,一套是 ConcurrentLinkedQueue 為代表的高效能佇列,一個是以 BlockingQueue 介面為代表的阻塞佇列 - 並行 Deque(雙端佇列)
LinkedBlockingDeque
6、鎖的效能優化
- 避免死鎖
- 減小鎖的作用範圍
- 減小鎖的粒度
- 讀寫分離鎖代替獨佔鎖
- 鎖分離
- 重入鎖(ReentrantLock)和內部鎖(Synchronized)
- 鎖粗化:不斷地獲取和釋放鎖也很耗資源,比如在 for 迴圈裡使用 synchronized
- 自旋鎖:執行緒沒有取得鎖時不被掛起,轉而去執行一個空迴圈。
- 鎖消除:JVM 在即時編譯時通過多執行上下文的掃描,去除不可能有共用資源競爭的鎖。如方法內部的 StringBuffer。
逃逸分析和鎖消除分別可以使用-XX:+DoEscapeAnalysis 和-XX:+EliminateLocks 開啟(鎖消除必須工作在-server 模式下)
範例如下:
分別在-server -XX:-DoEscapeAnalysis -XX:-EliminateLocks 和-server -XX:+DoEscapeAnalysis -XX:+EliminateLocks 下執行程式
public class LockTest {
private static final int CIRCLE=20000000;
public static void main(String[] args) {
long start=System.currentTimeMillis();
for (int i = 0; i <CIRCLE ; i++) {
createStringBuffer("java","Performance");
}
long bufferCost=System.currentTimeMillis()-start;
System.out.println("CreateStringBuffer:"+bufferCost+"ms");
}
public static String createStringBuffer(String s1,String s2){
StringBuffer sb=new StringBuffer();
sb.append(s1);
sb.append(s2);
return sb.toString();
}
}
- 鎖偏向:如果程式沒有競爭,則取消之前獲得鎖的執行緒的同步操作。通過設定-XX:+UseBiasedLocking 可以設定啟用偏向鎖
- Amino 集合:無鎖的執行緒安全集合框架。包下載地址:https://sourceforge.net/projects/amino-cbbs/files/cbbs/
相關集合類有 LockFreeList 和 LockFreeVector,LockFreeSet,LockFreeBSTree。另外該框架還實現了兩個 Master-Worker 模式。一個靜態的和動態的。分別需要實現 Doable 和 DynamicWorker 介面。
/**
* Amino框架實現了Master-woker模式
*/
public class Pow3 implements Doable<Integer,Integer> {
//業務邏輯
@Override
public Integer run(Integer integer) {
return integer*integer*integer;
}
public static void main(String[] args) {
MasterWorker<Integer,Integer> mw=MasterWorkerFactory.newStatic(new Pow3());
List<MasterWorker.ResultKey> keyList=new Vector<>();
for (int i = 0; i <100 ; i++) {
keyList.add(mw.submit(i));
}
mw.execute();
int re=0;
while (keyList.size()>0){
MasterWorker.ResultKey k=keyList.get(0);
Integer i=mw.result(k);
if(i!=null){
re+=i;
keyList.remove(0);
}
}
System.out.println(re);
}
}
7、協程
為了增加系統的並行性,人們提出了執行緒,隨著應用程式日趨複雜,並行量要求越來越高,執行緒也變得沉重了起來。為了使系統有更高的並行度,便有了協程的概念。如果說執行緒是輕量級程序,那麼協程就是輕量級的執行緒。
相關框架:kilim。
介紹:略。
二、JVM 調優
1、虛擬機器器記憶體模型

1、程式計數器
每一個執行緒都有一個獨立的程式計數器,用於記錄下一條要執行的指令,各個執行緒互不影響。
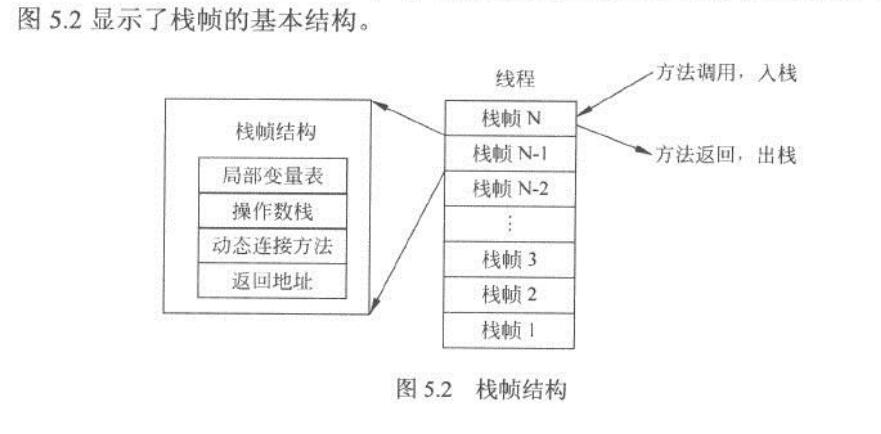
2、Java 虛擬機器器棧
它和 Java 執行緒在同一時間建立,儲存方法的區域性變數,部分結果,並參與方法的呼叫和返回。
- 當執行緒在計算過程中請求的棧深度大於最大可用的棧深度,丟擲 StackOverflowError 異常。
- 如果 Java 棧可以可以動態擴充套件,在擴充套件的過程中沒有足夠的空間支援,則丟擲 OutOfMemoryError
- -Xss1M 該命令可以調整棧的深度。
public void test28(){ //gc無法回收,因為b還在區域性變數表中
{
byte[] b=new byte[6*1024*1024];
}
System.gc();
System.out.println("first explict gc over");
}
public void test29(){ //gc可以回收,因為變數a複用了b的字
{
byte[] b=new byte[6*1024*1024];
}
int a=0;
System.gc();
System.out.println("first explict gc over");
}
3、本地方法棧
本地方法棧和 java 虛擬機器器棧的功能很像,本地方法棧用於管理本地方法的呼叫。
4、Java 堆
幾乎所有的物件和陣列都是在堆中分配空間的。
5、方法區
主要儲存類的後設資料,所有執行緒共用的。其中最為重要的是類的型別資訊,常數池,靜態變數,域資訊,方法資訊。在 Hot Spot 虛擬機器器中,方法區也被稱為永久區。
2、JVM 記憶體分配引數
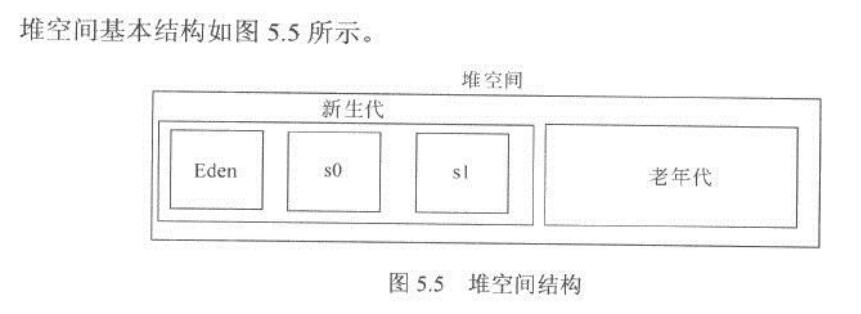
- 最大堆記憶體:可以用-Xmx 引數指定。是指新生代和老年代的大小之和。
- 最小堆記憶體:JVM 啟動時,所佔據的作業系統記憶體大小,可以用-Xms 指定。
- 設定新生代:新生代一般設定未 1/4 到 1/3 之間。用引數-Xmn 指定
- 持久代(方法區):-XX:PermSize 可以設定初始大小,-XX:MaxPermSize 可以設定最大值
- 執行緒棧:可以使用-Xss 設定大小。-Xss1M 表示每個執行緒擁有 1M 的空間。
- 堆的比例分配:-XX:SurvivorRatio:eden/s0=eden/s1。 -XX:NewRatio=老年代/新生代
- 引數總結:

3、垃圾回收
1、參照計數法
如果有參照,計數器就加 1,當參照失效時,計數器就減 1.這種方法無法處理迴圈參照,不適用與 JVM 的回收。
2、標記-清除演演算法
第一階段,標記所有從根節點開始可達的物件。第二階段,清理所有未標記的物件。缺點是回收後的空間是不連續的。
3、複製演演算法
將原有的空間分為兩塊,將正在使用的那個空間的活物件複製到未使用的那個空間,在垃圾回收時,只需要清理正在使用的記憶體空間的所有物件,然後交換兩個記憶體空間的角色。缺點是要將系統記憶體折半。
4、標記壓縮演演算法
標記完成之後,將所有的存活物件壓縮到記憶體的一端,然後清除邊界外所有的空間。避免了碎片的產生。
5、增量演演算法
一次性的垃圾清理會造成系統長時間停頓,那麼就可以讓垃圾收集執行緒和應用程式執行緒交替執行。在垃圾回收的過程中間斷性的執行應用程式程式碼。
6、分代
對新生代使用複製演演算法,老年代使用標記-壓縮演演算法。
7、序列收集器
- -XX:+UseSerialGC 新生代,老年代都使用序列回收器
- -XX:+UseParNewGC 新生代使用並行,老年代使用序列
- -XX:+UseParallelGC 新生代使用並行,老年代使用序列
- -XX:+UseConcMarkSweepGC 新生代使用並行,老年代使用 CMS(-XX:ParallelGCThreads 可以指定執行緒數量,Cpu 小於 8 時,就設定 cput 的數量,大於 8 時設定為(3+5*cpucount/8))
8、CMS 收集器
使用的是標記清除演演算法,並行的垃圾收集器
9、G1 收集器
基於標記-壓縮演演算法,目標是一款伺服器的收集器,在吞吐量和停頓控制上,要優於 CMS 收集器。
觀察 GC 情況:
package com.mmc.concurrentcystudy.test;
import java.util.HashMap;
public class StopWorldTest {
public static class MyThread extends Thread{
HashMap map=new HashMap();
@Override
public void run() {
try{
while (true){
if(map.size()*512/1024/1024>=400){ //防止記憶體溢位
map.clear();
System.out.println("clean map");
}
byte[] b1;
for (int i = 0; i <100 ; i++) {
b1=new byte[512]; //模擬記憶體佔用
map.put(System.nanoTime(),b1);
}
Thread.sleep(1);
}
}catch (Exception e){}
}
}
public static class PrintThread extends Thread{ //每毫秒列印時間資訊
public static final long starttime=System.currentTimeMillis();
@Override
public void run() {
try{
while (true){
long t=System.currentTimeMillis()-starttime;
System.out.println(t/1000+"."+t%1000);
Thread.sleep(100);
}
}catch (Exception e){}
}
}
public static void main(String[] args) {
MyThread t=new MyThread();
PrintThread p=new PrintThread();
t.start();
p.start();
}
}
4、常用調優案例
1、將新物件預留在新生代
避免新物件因空間不夠進入了年老代,可以適當增加新生代的 from 大小。
- 可以通過-XX:TargetSurvivorRatio 提高 from 區的利用率
- 通過-XX:SurvivorRatio 設定更大的 from 區
2、大物件直接進入老年代
在大部分情況下,新物件分配在新生代是合理的,但是,對於大物件,很可能擾亂新生代,使得大量小的新生代物件因空間不足移到老年代。
- 使用-XX:PretenureSizeThreshold 設定大物件進入老年代的閾值。當物件大小超過這個值時,物件直接分配在老年代。
3、設定物件進入老年代的年齡
- 可以通過設定-XX:MaxTenuringThreshold 閾值年齡的最大值。
4、穩定與震盪的堆大小
1、一般來說穩定的堆大小是對回收有利的,獲得一個穩定的堆大小的方法就是設定-Xms 和-Xmx 的大小一致。穩定的堆空間可以減少 GC 的次數,但是會增加每次 GC 的時間。
基於這樣的考慮,JVM 提供了壓縮和擴充套件堆空間的引數。
- -XX:MinHeapFreeRatio 設定堆空間最小空閒比例,預設是 40,當堆空間記憶體小於這個數值時,JVM 會擴充套件堆空間。
- -XX:MaxHeapFreeRatio 設定堆空間的最大空閒比例,預設是 70,當堆空間記憶體大於這個數值時,JVM 會壓縮堆空間。
- 注意:當設定-xms 和-xmx 一樣時,這兩個引數會失效。
5、吞吐量優先案例
在擁有 4G 記憶體和 32 核 CPU 的計算機上,進行吞吐量的優化

6、使用大頁案例
在 Solaris 系統中,可以支援大頁的使用,大的記憶體分頁可以增強 CPU 的記憶體定址能力。
- -XX:LargePageSizeInBytes:設定大頁的大小。
7、降低停頓案例
為了降低停頓,應儘可能將物件預留在新生代,因為新生代的 GC 成本遠小於老年代。

5、實用 JVM 引數
1、JIT 編譯引數
JIT 編譯器可以將位元組程式碼編譯成原生程式碼,從而提高執行效率。
- -XX:CompileThreshold 為 JIT 編譯的閾值,當函數的呼叫次數超過他,JIT 就將位元組碼編譯成本地機器碼。
- -XX:+CITime 可以列印出編譯的耗時
- -XX:+PrintCompilation 可以列印 JIT 編譯資訊
2、堆快照
在效能優化中,分析堆快照是必不可少的環節。
- 使用-XX:+HeapDumpOnOutOfMemoryError 引數可以在程式發生 OOM 異常時匯出當前堆快照
- 使用-XX:HeapDumpPath 可以指定堆快照儲存的位置。(例:
-Xmx20M -XX:+HeapDumpOnOutOfMemoryError -XX:HeapDumpPath=d://log
)
- 使用 Visual VM 工具可以分析堆檔案。
3、錯誤處理
可以在系統發生 OOM 時,執行第三方指令碼。如重置系統
- -XX:OnOutOfMemoryError=c:\reset.bat
4、獲取 GC 資訊
- -XX:+PrintGC
- -XX:+PrintGCDetails 列印更詳細的 GC 資訊
- -XX:+PrintHeapAtGC 列印堆的使用情況
5、類和物件跟蹤
- -XX:+TraceClassLoading 用於跟蹤類載入情況
- -XX:+TraceClassUnloading 用於跟蹤類解除安裝情況
- -XX:+PrintClassHistogram 開關列印執行時範例的資訊,開關開啟後,當按下 Ctrl+Break 時,會列印系統內類的統計資訊
6、控制 GC
- -XX:+DisableExplicitGC 用於禁止顯示的 GC
- -Xnoclassgc 禁止類的回收
- -Xincgc 增量式的 GC
7、使用大頁
- -XX:+UseLargePages 啟用大頁
- -XX:+LargePageSizeInBytes 指定大頁的大小
8、壓縮指標
在 64 位虛擬機器器上,應用程式佔的記憶體要遠大於 32 位的,因為 64 位系統擁有更寬的定址空間,指標物件進行了翻倍。
- +XX:+UseCompressedOops 開啟指標壓縮,減少記憶體消耗(但是壓縮和解壓指標效能會影響)
6、實戰案例
1、tomcat 優化
- 在 catalina.bat 中增加列印 GC 紀錄檔,以便偵錯:
set CATALINA_OPTS=-Xloggc:gc.log -XX:+PrintGCDetails
2.當發現產生了 GC 時,看下是否需要增加新生代大小
set CATALINA_OPTS=%CATALINA_OPTS% -Xmx32M -Xms32M
3.如果發現有人使用了顯示的 GC 呼叫,可以禁止掉 set CATALINA_OPTS=%CATALINA_OPTS% -XX:+DesableExplicitGC
4.擴大新生代比例 set CATALINA_OPTS=%CATALINA_OPTS% -XX:NewRatio=2
5.給新生代使用並行回收 set CATALINA_OPTS=%CATALINA_OPTS% -XX:UseParallelGC
6.當確保 class 安全的時候,可以關閉 class 校驗 set CATALINA_OPTS=%CATALINA_OPTS% -Xverify:none
2、JMeter 介紹和使用
JMeter 是一款效能測試和壓力測試工具。
下載路徑:https://jmeter.apache.org/download_jmeter.cgi
-
下載解壓之後,進入 bin 目錄,點選 jmeter.bat 啟動。
-
右鍵新增執行緒組
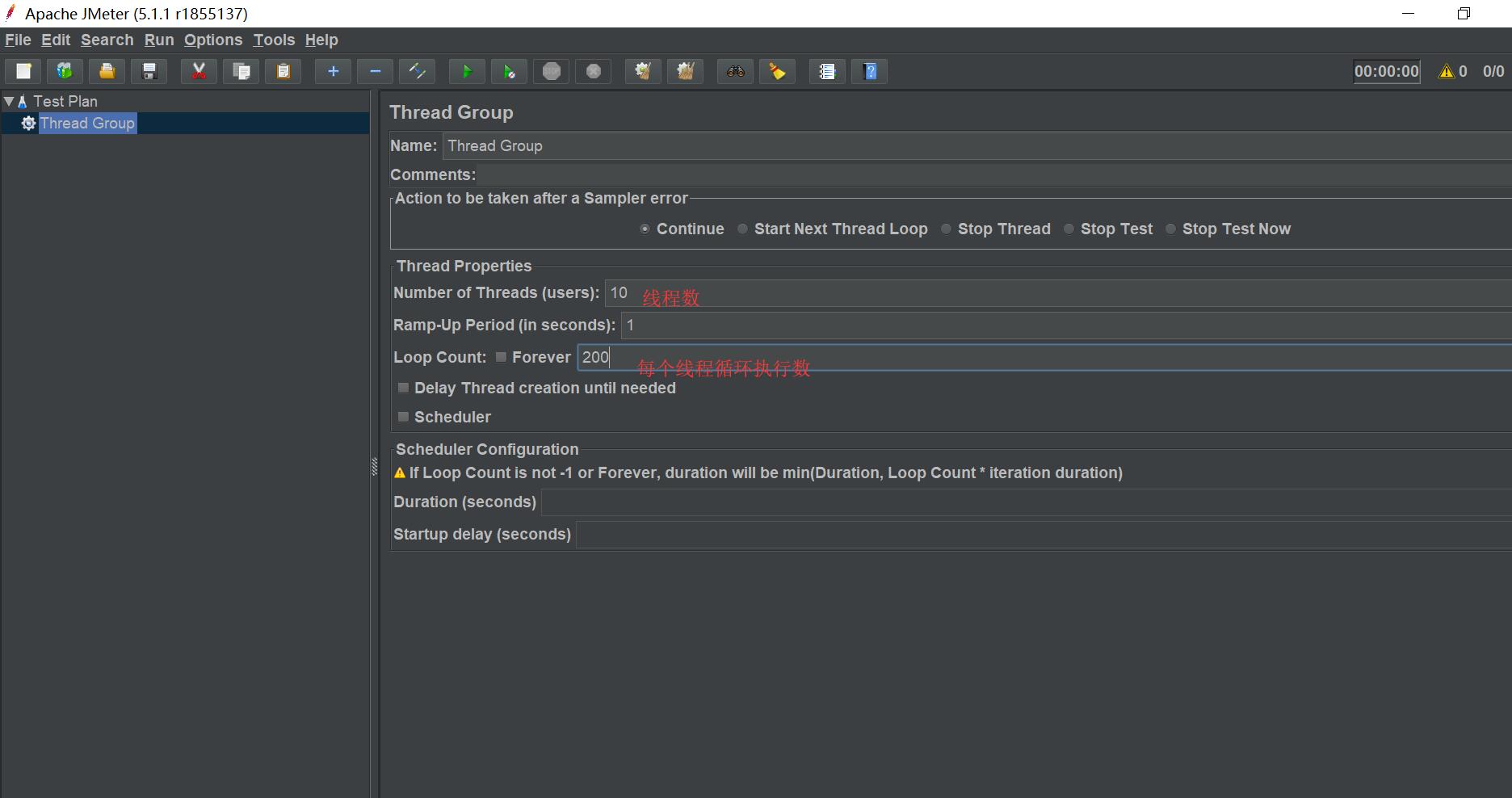
-
右鍵新增請求
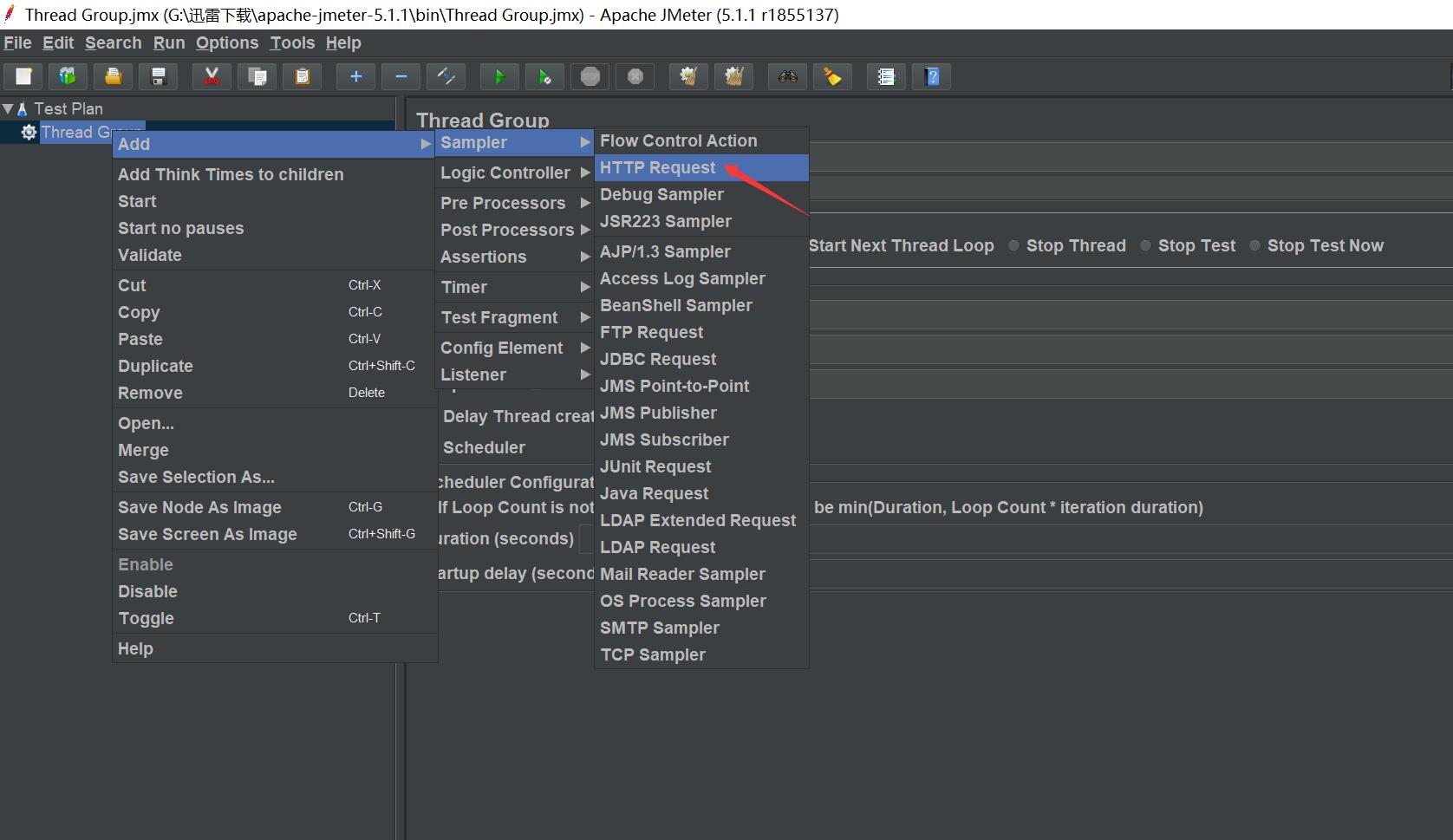
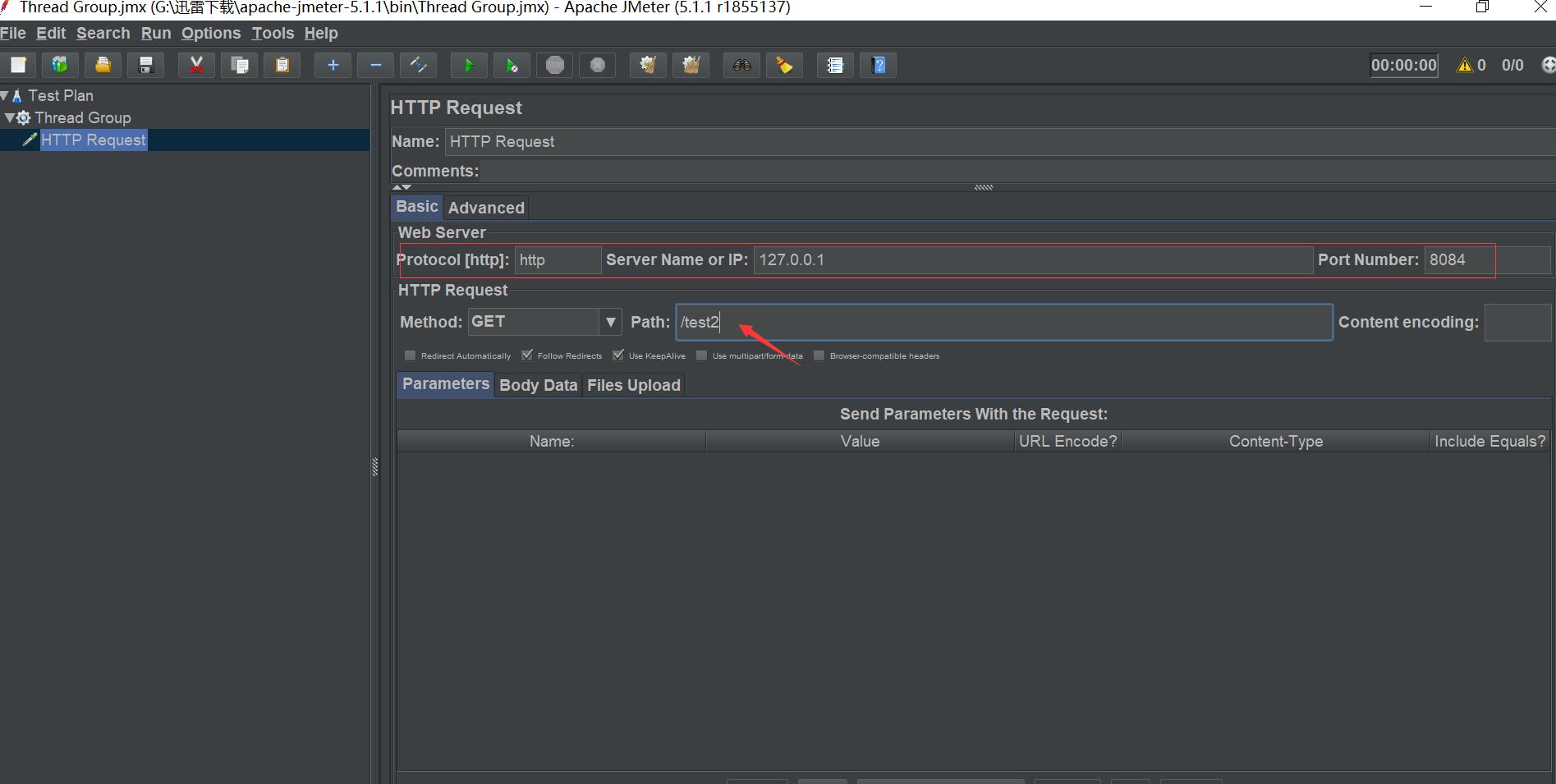
-
新增結果檢視
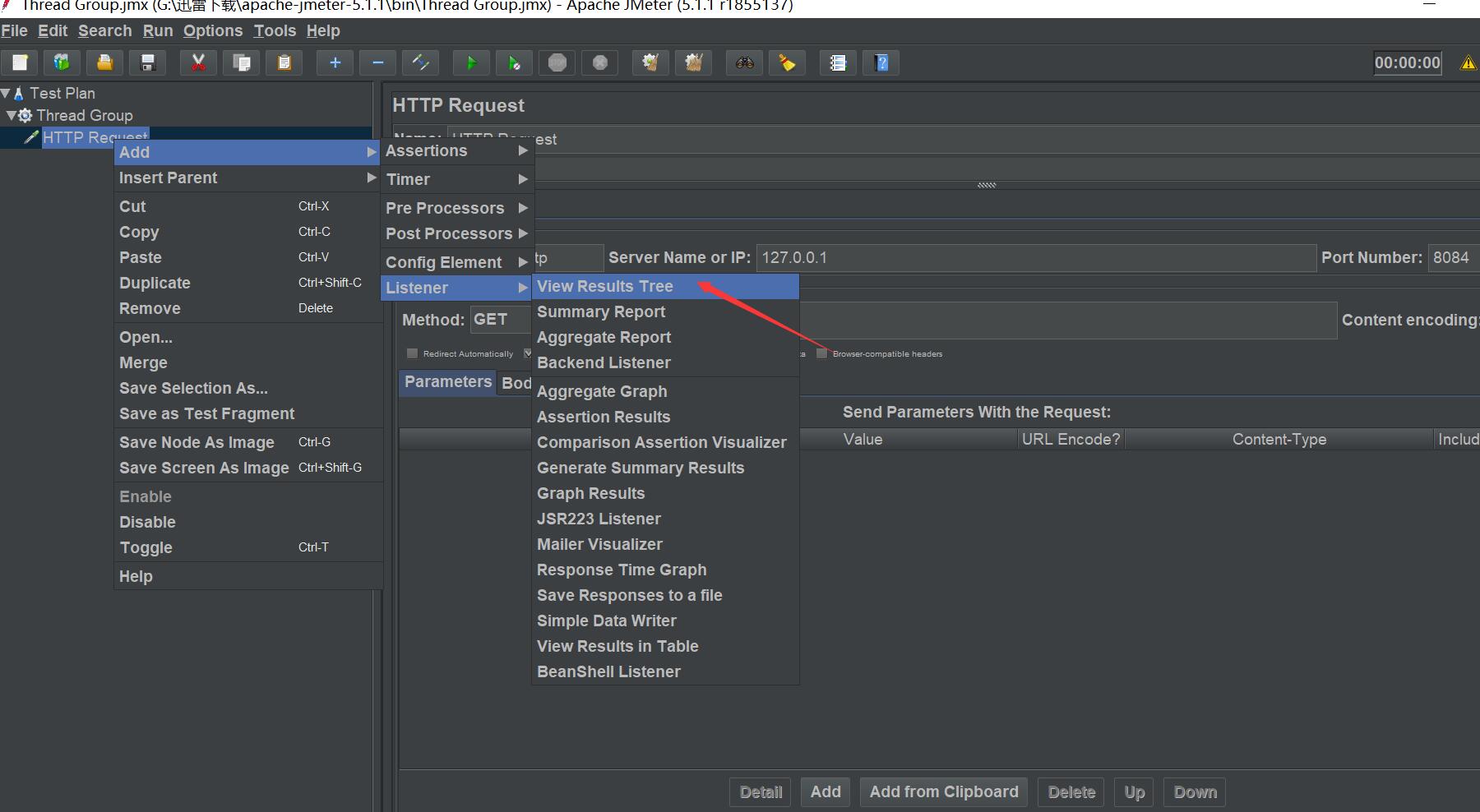
這裡有很多結果檢視,都可以選來試試。
- 點選執行
3、案例
確認堆大小(-Xmx,-Xms),合理分配新生代和老年代(-XX:NewRatio,-Xmn,-XX:SurvivorRatio),確定永久區大小(-XX:PermSize,-XX:MaxPermSize),選擇垃圾收集器,除此之外,禁用顯示的 GC,禁用類元素回收,禁用類驗證對效能也有提升。
實戰的調優:

三、Java 效能調優工具
1、Linux 命令列工具
1、top 命令
2、sar 命令
3、vmstat 命令
統計 CPU、記憶體情況
4、iostat 命令
統計 IO 資訊
5、pidstat
可以監控執行緒的
2、JDK 命令列工具
- jps
- jstat
- jinfo 檢視 jvm 引數
- jmap 生成堆快照和物件的統計資訊 jmap -histo 2972 >c:/s.txt
生成當前程式的堆快照:jmap -dump:format=b,file=c:\heap.hprof 2972 - jhat 分析堆快照檔案
- jstack 匯出 java 程式的執行緒堆疊,可以列印鎖的資訊 jstack -l 149864>d:/a.txt
- jstatd 有些工具(jps,jstat)可以支援對遠端計算機的監控,這就需要 jstatd 的配合
開啟 jstatd:
1、在 d 盤新建了個檔案 jstatd.all.policy。內容為
grant codebase "file:D:/Java/jdk1.8.0_112/lib/tools.jar" {
permission java.security.AllPermission;
};
2、執行開啟
jstatd -J-Djava.security.policy=D:/jstatd.all.policy
3、新開一個 cmd 視窗,執行 jps localhost:1099 即可遠端監聽
8.hprof 工具,程式執行時加上-agentlib:hprof=cpu=times,interval=10 可以匯出函數執行時間。還可以使用-agentlib:hprof=heap=dump,format=b,file=d:/core.hprof 匯出檔案
3、JConsole 工具
4、Visual VM 工具
1、BTrace 外掛,可在不修改程式碼情況下給程式碼加紀錄檔
/* BTrace Script Template */
import com.sun.btrace.annotations.*;
import static com.sun.btrace.BTraceUtils.*;
@BTrace
public class TracingScript {
/* put your code here */
private static long startTime=0;
//方法開始時呼叫
@OnMethod(clazz="com.mmc.concurrentcystudy.test.BTraceTest",method="writeFile") //監控任意類的writeFile方法
public static void startMethod(){
startTime=timeMillis();
}
@OnMethod(clazz="com.mmc.concurrentcystudy.test.BTraceTest",method="writeFile",location=@Location(Kind.RETURN)) //方法返回時觸發
public static void endM(){
print(strcat(strcat(name(probeClass()),"."),probeMethod()));
print("[");
print(strcat("Time taken:",str(timeMillis()-startTime)));
println("]");
}
}
範例 2:
/* BTrace Script Template */
import com.sun.btrace.annotations.*;
import static com.sun.btrace.BTraceUtils.*;
@BTrace
public class TracingScript {
/* put your code here */
@OnMethod(clazz="/.*Test/",location=@Location(value=Kind.LINE,line=27)) //,監控Test結尾的類,指定程式執行到第27行觸發
public static void onLine(@ProbeClassName String pcn,@ProbeMethodName String pmn,int line){
print(Strings.strcat(pcn,"."));
print(Strings.strcat(pmn,":"));
println(line);
}
}
範例 3:每秒執行
@BTrace
public class TracingScript {
/* put your code here */
@OnTimer(1000) //每秒鐘執行
public static void getUpTime(){
println(Strings.strcat("l000 msec:",Strings.str(Sys.VM.vmUptime()))); //虛擬機器器啟動時間
}
@OnTimer(3000)
public static void getStack(){
jstackAll(); //匯出執行緒堆疊
}
}
範例 4:獲取引數
@BTrace
public class TracingScript {
/* put your code here */
@OnMethod(clazz="com.mmc.concurrentcystudy.test.BTraceTest",method="writeFile")
public static void any(String filename){
print(filename);
}
}
5、MAT 記憶體分析工具
1、下載 mat
https://www.eclipse.org/mat/
2、深堆和淺堆
淺堆:一個物件結構所佔用的記憶體大小。
深堆:一個物件被 GC 後,可以真實釋放的記憶體大小
6、JProfile
略