Databend 原始碼閱讀系列(二):Query server 啟動,Session 管理及請求處理
query 啟動入口
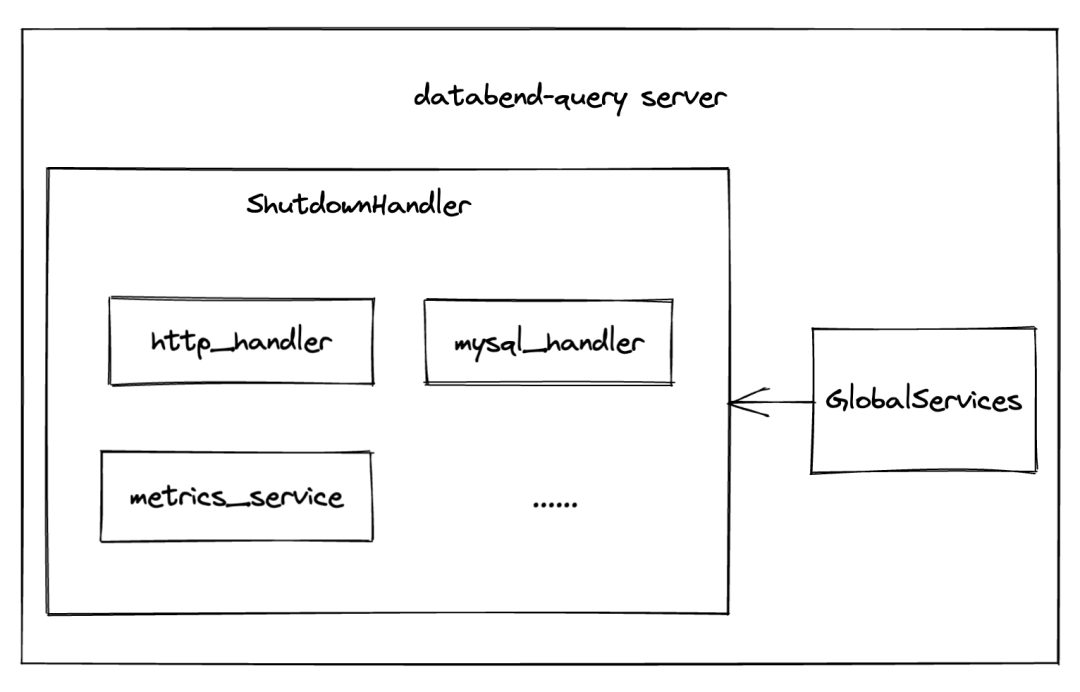
Databend-query server 的啟動入口在 databend/src/binaries/query/main.rs 下,在初始化設定之後,它會建立一個 GlobalServices 和 server 關閉時負責處理 shutdown 邏輯的 shutdown_handle
GlobalServices::init(conf.clone()).await?;
let mut shutdown_handle = ShutdownHandle::create()?;
GlobalServices
GlobalServices 負責啟動 databend-query 的所有全域性服務,這些服務都遵循單一責任原則。
pub struct GlobalServices {
global_runtime: UnsafeCell<Option<Arc<Runtime>>>,
// 負責處理 query log
query_logger: UnsafeCell<Option<Arc<QueryLogger>>>,
// 負責 databend query 叢集發現
cluster_discovery: UnsafeCell<Option<Arc<ClusterDiscovery>>>,
// 負責與 storage 層互動來讀寫資料
storage_operator: UnsafeCell<Option<Operator>>,
async_insert_manager: UnsafeCell<Option<Arc<AsyncInsertManager>>>,
cache_manager: UnsafeCell<Option<Arc<CacheManager>>>,
catalog_manager: UnsafeCell<Option<Arc<CatalogManager>>>,
http_query_manager: UnsafeCell<Option<Arc<HttpQueryManager>>>,
data_exchange_manager: UnsafeCell<Option<Arc<DataExchangeManager>>>,
session_manager: UnsafeCell<Option<Arc<SessionManager>>>,
users_manager: UnsafeCell<Option<Arc<UserApiProvider>>>,
users_role_manager: UnsafeCell<Option<Arc<RoleCacheManager>>>,
}
GlobalServices 中的全域性服務都實現了單例 trait,這些全域性管理器後續會有對應的原始碼分析文章介紹,本文介紹與 Session 處理相關的邏輯。
pub trait SingletonImpl<T>: Send + Sync {
fn get(&self) -> T;
fn init(&self, value: T) -> Result<()>;
}
pub type Singleton<T> = Arc<dyn SingletonImpl<T>>;
ShutdownHandle
接下來會根據網路協定初始化 handlers,並把它們註冊到 shutdown_handler 的 services 中,任何實現 Server trait 的型別都可以被新增到 services 中。
#[async_trait::async_trait]
pub trait Server: Send {
async fn shutdown(&mut self, graceful: bool);
async fn start(&mut self, listening: SocketAddr) -> Result<SocketAddr>;
}
目前 Databend 支援三種協定提交查詢請求(mysql, clickhouse http, raw http)。
// MySQL handler.
{
let hostname = conf.query.mysql_handler_host.clone();
let listening = format!("{}:{}", hostname, conf.query.mysql_handler_port);
let mut handler = MySQLHandler::create(session_manager.clone());
let listening = handler.start(listening.parse()?).await?;
// 註冊服務到 shutdown_handle 來處理 server shutdown 時候的關閉邏輯,下同
shutdown_handle.add_service(handler);
}
// ClickHouse HTTP handler.
{
let hostname = conf.query.clickhouse_http_handler_host.clone();
let listening = format!("{}:{}", hostname, conf.query.clickhouse_http_handler_port);
let mut srv = HttpHandler::create(session_manager.clone(), HttpHandlerKind::Clickhouse);
let listening = srv.start(listening.parse()?).await?;
shutdown_handle.add_service(srv);
}
// Databend HTTP handler.
{
let hostname = conf.query.http_handler_host.clone();
let listening = format!("{}:{}", hostname, conf.query.http_handler_port);
let mut srv = HttpHandler::create(session_manager.clone(), HttpHandlerKind::Query);
let listening = srv.start(listening.parse()?).await?;
shutdown_handle.add_service(srv);
}
之後會建立一些其它服務
-
Metric service: 指標服務
-
Admin service: 負責處理管理資訊
-
RPC service: query 節點的 rpc 服務,負責 query 節點之間的通訊,使用 arrow flight 協定
// Metric API service.
{
let address = conf.query.metric_api_address.clone();
let mut srv = MetricService::create(session_manager.clone());
let listening = srv.start(address.parse()?).await?;
shutdown_handle.add_service(srv);
info!("Listening for Metric API: {}/metrics", listening);
}
// Admin HTTP API service.
{
let address = conf.query.admin_api_address.clone();
let mut srv = HttpService::create(session_manager.clone());
let listening = srv.start(address.parse()?).await?;
shutdown_handle.add_service(srv);
info!("Listening for Admin HTTP API: {}", listening);
}
// RPC API service.
{
let address = conf.query.flight_api_address.clone();
let mut srv = RpcService::create(session_manager.clone());
let listening = srv.start(address.parse()?).await?;
shutdown_handle.add_service(srv);
info!("Listening for RPC API (interserver): {}", listening);
}
最後會將這個 query 節點註冊到 meta server 中。
// Cluster register.
{
let cluster_discovery = session_manager.get_cluster_discovery();
let register_to_metastore = cluster_discovery.register_to_metastore(&conf);
register_to_metastore.await?;
}
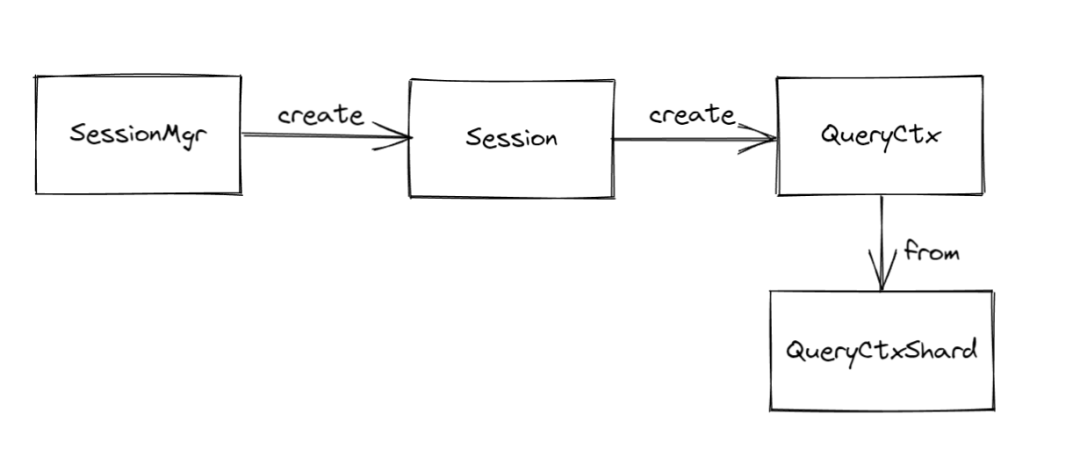
Session 相關
session 主要分為 4 個部分
-
session_manager: 全域性唯一,負責管理 client session
-
session: 每當有新的 client 連線到 server 之後會建立一個新的 session 並且註冊到 session_manager
-
query_ctx: 每一條查詢語句會有一個 query_ctx,用來儲存當前查詢的一些上下文資訊
-
query_ctx_shared: 查詢語句中的子查詢共用的上下文資訊
下面逐一來分析
SessionManager (query/src/sessions/session_mgr.rs)
pub struct SessionManager {
pub(in crate::sessions) conf: Config,
pub(in crate::sessions) max_sessions: usize,
pub(in crate::sessions) active_sessions: Arc<RwLock<HashMap<String, Arc<Session>>>>,
pub status: Arc<RwLock<SessionManagerStatus>>,
// When session type is MySQL, insert into this map, key is id, val is MySQL connection id.
pub(crate) mysql_conn_map: Arc<RwLock<HashMap<Option<u32>, String>>>,
pub(in crate::sessions) mysql_basic_conn_id: AtomicU32,
}
SessionManager 主要用來建立和銷燬 session,對應方法如下
// 根據 client 協定型別來建立 session
pub async fn create_session(self: &Arc<Self>, typ: SessionType) -> Result<SessionRef>
// 根據 session id 來銷燬 session
pub fn destroy_session(self: &Arc<Self>, session_id: &String)
Session (query/src/sessions/session.rs)
session 主要儲存 client-server 的上下文資訊,程式碼命名已經很清晰了,這裡就不再過多贅述。
pub struct Session {
pub(in crate::sessions) id: String,
pub(in crate::sessions) typ: RwLock<SessionType>,
pub(in crate::sessions) session_ctx: Arc<SessionContext>,
status: Arc<RwLock<SessionStatus>>,
pub(in crate::sessions) mysql_connection_id: Option<u32>,
}
pub struct SessionContext {
conf: Config,
abort: AtomicBool,
current_catalog: RwLock<String>,
current_database: RwLock<String>,
current_tenant: RwLock<String>,
current_user: RwLock<Option<UserInfo>>,
auth_role: RwLock<Option<String>>,
client_host: RwLock<Option<SocketAddr>>,
io_shutdown_tx: RwLock<Option<Sender<Sender<()>>>>,
query_context_shared: RwLock<Option<Arc<QueryContextShared>>>,
}
pub struct SessionStatus {
pub session_started_at: Instant,
pub last_query_finished_at: Option<Instant>,
}
Session 的另一個大的功能是負責建立和獲取 QueryContext,每次接收到新的 query 請求都會建立一個 QueryContext 並繫結在對應的 query 語句上。
QueryContext (query/src/sessions/query_ctx.rs)
QueryContext 主要是維護查詢的上下文資訊,它通過 QueryContext::create_from_shared(query_ctx_shared)建立。
#[derive(Clone)]
pub struct QueryContext {
version: String,
statistics: Arc<RwLock<Statistics>>,
partition_queue: Arc<RwLock<VecDeque<PartInfoPtr>>>,
shared: Arc<QueryContextShared>,
precommit_blocks: Arc<RwLock<Vec<DataBlock>>>,
fragment_id: Arc<AtomicUsize>,
}
其中 partition_queue 主要儲存查詢對應的 PartInfo,包括 part 的地址、版本資訊、涉及資料的行數,part 使用的壓縮演演算法、以及涉及到 column 的 meta 資訊。在 pipeline build 時候會去設定 partition。pipeline 後續會有專門的文章介紹。
precommit_blocks 負責暫存插入操作的時已經寫入到儲存, 但是尚未提交的後設資料,DataBlock 主要包含 Column 的元資訊參照和 arrow schema 的資訊。
QueryContextShared (query/src/sessions/query_ctx_shared.rs)
對於包含子查詢的查詢,需要共用很多上下文資訊,這就是 QueryContextShared存在的理由。
/// 資料需要在查詢上下文中被共用,這個很重要,比如:
/// USE database_1;
/// SELECT
/// (SELECT scalar FROM table_name_1) AS scalar_1,
/// (SELECT scalar FROM table_name_2) AS scalar_2,
/// (SELECT scalar FROM table_name_3) AS scalar_3
/// FROM table_name_4;
/// 對於上面子查詢, 會共用 runtime, session, progress, init_query_id
pub struct QueryContextShared {
/// scan_progress for scan metrics of datablocks (uncompressed)
pub(in crate::sessions) scan_progress: Arc<Progress>,
/// write_progress for write/commit metrics of datablocks (uncompressed)
pub(in crate::sessions) write_progress: Arc<Progress>,
/// result_progress for metrics of result datablocks (uncompressed)
pub(in crate::sessions) result_progress: Arc<Progress>,
pub(in crate::sessions) error: Arc<Mutex<Option<ErrorCode>>>,
pub(in crate::sessions) session: Arc<Session>,
pub(in crate::sessions) runtime: Arc<RwLock<Option<Arc<Runtime>>>>,
pub(in crate::sessions) init_query_id: Arc<RwLock<String>>,
...
}
它提供了 query 上下文所需要的一切基本資訊。
Handler
之前提到了 Databend 支援多種 handler,下面就以 mysql 為例,看一下 handler 的處理流程以及如何與 session 產生互動。
首先 MySQLHandler 會包含一個 SessionManager 的參照
pub struct MySQLHandler {
abort_handle: AbortHandle,
abort_registration: Option<AbortRegistration>,
join_handle: Option<JoinHandle<()>>,
}
MySQLHandler 在啟動後,會 spawn 一個 tokio task 來持續監聽 tcp stream,並且建立一個 session 再啟動一個 task 去執行之後的查詢請求。
fn accept_socket(session_mgr: Arc<SessionManager>, executor: Arc<Runtime>, socket: TcpStream) {
executor.spawn(async move {
// 建立 session
match session_mgr.create_session(SessionType::MySQL).await {
Err(error) => Self::reject_session(socket, error).await,
Ok(session) => {
info!("MySQL connection coming: {:?}", socket.peer_addr());
// 執行查詢
if let Err(error) = MySQLConnection::run_on_stream(session, socket) {
error!("Unexpected error occurred during query: {:?}", error);
};
}
}
});
}
在 MySQLConnection::run_on_stream中,session 會先 attach 到對應的 client host 並且註冊一個 shutdown 閉包來處理關閉連線關閉時需要執行的清理,關鍵程式碼如下:
// mysql_session.rs
pub fn run_on_stream(session: SessionRef, stream: TcpStream) -> Result<()> {
let blocking_stream = Self::convert_stream(stream)?;
MySQLConnection::attach_session(&session, &blocking_stream)?;
...
}
fn attach_session(session: &SessionRef, blocking_stream: &std::net::TcpStream) -> Result<()> {
let host = blocking_stream.peer_addr().ok();
let blocking_stream_ref = blocking_stream.try_clone()?;
session.attach(host, move || {
// 註冊 shutdown 邏輯
if let Err(error) = blocking_stream_ref.shutdown(Shutdown::Both) {
error!("Cannot shutdown MySQL session io {}", error);
}
});
Ok(())
}
// session.rs
pub fn attach<F>(self: &Arc<Self>, host: Option<SocketAddr>, io_shutdown: F)
where F: FnOnce() + Send + 'static {
let (tx, rx) = oneshot::channel();
self.session_ctx.set_client_host(host);
self.session_ctx.set_io_shutdown_tx(Some(tx));
common_base::base::tokio::spawn(async move {
// 在 session quit 時候觸發清理
if let Ok(tx) = rx.await {
(io_shutdown)();
tx.send(()).ok();
}
});
}
之後會啟動一個 MySQL InteractiveWorker 來處理後續的查詢。
let join_handle = query_executor.spawn(async move {
let client_addr = non_blocking_stream.peer_addr().unwrap().to_string();
let interactive_worker = InteractiveWorker::create(session, client_addr);
let opts = IntermediaryOptions {
process_use_statement_on_query: true,
};
let (r, w) = non_blocking_stream.into_split();
let w = BufWriter::with_capacity(DEFAULT_RESULT_SET_WRITE_BUFFER_SIZE, w);
AsyncMysqlIntermediary::run_with_options(interactive_worker, r, w, &opts).await
});
let _ = futures::executor::block_on(join_handle);
該 InteractiveWorker會實現 AsyncMysqlShim trait 的方法,比如:on_execute、on_query 等。查詢到來時會回撥這些方法來執行查詢。這裡以 on_query 為例,關鍵程式碼如下:
async fn on_query<'a>(
&'a mut self,
query: &'a str,
writer: QueryResultWriter<'a, W>,
) -> Result<()> {
...
// response writer
let mut writer = DFQueryResultWriter::create(writer);
let instant = Instant::now();
// 執行查詢
let blocks = self.base.do_query(query).await;
// 回寫結果
let format = self.base.session.get_format_settings()?;
let mut write_result = writer.write(blocks, &format);
...
// metrics 資訊
histogram!(
super::mysql_metrics::METRIC_MYSQL_PROCESSOR_REQUEST_DURATION,
instant.elapsed()
);
write_result
}
在 do_query 中會建立 QueryContext 並開始解析 sql 流程來完成後續的整個 sql 查詢。關鍵程式碼如下:
// 建立 QueryContext
let context = self.session.create_query_context().await?;
// 關聯到查詢語句
context.attach_query_str(query);
let settings = context.get_settings();
// parse sql
let stmts_hints = DfParser::parse_sql(query, context.get_current_session().get_type());
...
// 建立並生成查詢計劃
let mut planner = Planner::new(context.clone());
let interpreter = planner.plan_sql(query).await.and_then(|v| {
has_result_set = has_result_set_by_plan(&v.0);
InterpreterFactoryV2::get(context.clone(), &v.0)
})
// 執行查詢,返回結果
Self::exec_query(interpreter.clone(), &context).await?;
let schema = interpreter.schema();
Ok(QueryResult::create(
blocks,
extra_info,
has_result_set,
schema,
))
尾聲
以上就是從 Databend 啟動服務到接受 sql 請求並開始處理的流程。最近我們因為一些原因(Clickhouse tcp 協定偏向 clickhouse 的底層,協定沒有公開的檔案說明,同時裡面歷史包袱比較重,排查問題浪費大量精力)去掉了 ClickHouse native tcp client,具體請參見: https://github.com/datafuselabs/databend/pull/7012
如果你閱讀完程式碼有好的提議,歡迎來這裡討論,另外如果發現相關的問題,可以提交到 issue 來幫助我們提高 Databend 的穩定性。Databend 社群歡迎一切善意的意見和建議