並行程式設計二、CPU多級快取架構與MESI協定的誕生
前言:
- 文章內容:執行緒與程序、執行緒生命週期、執行緒中斷、執行緒常見問題總結
- 本文章內容來源於筆者學習筆記,內容可能與相關書籍內容重合
- 偏向於知識核心總結,非零基礎學習文章,可用於知識的體系建立,核心內容複習,如有幫助,十分榮幸
- 相關文獻:並行程式設計實戰、計算機原理
CPU多級快取架構
要學習多級快取架構,我們首先要了解一些計算機的小知識
CPU快取行(CPU Cache Line):
- CPU快取中可分配的最小儲存單元,通常64位元組,快取行是分段的,一個段對應一塊。
- CPU看到一條讀取記憶體的指令時,會把記憶體地址傳遞給一級資料快取,一級資料快取會檢查它是否有對這個記憶體地址對應的快取段,如果沒有就把整個快取段從主記憶體或更高一級的快取中載入進來。
暫存器:
- 特點:每個處理器都有自己的暫存器,CPU內部元件,擁有非常高的讀寫速度,暫存器之間資料傳輸非常快
- 能力:暫存器內的資料可以執行算術及運算邏輯、存於暫存器內的地址可用來定址,暫存器可以用來讀寫資料到電腦的周邊裝置
- 可見性問題的產生:變數有時候會被放進暫存器中暫時儲存,多個處理器各自執行一個執行緒時,可能導致某個變數放到暫存器中,會導致各個執行緒沒法看到其他處理器暫存器裡修改過的變數值,這就出現了可見性問題
寫緩衝器:
- 多個處理器互動時因為都要跟各自的主記憶體,或者快取記憶體進行讀寫操作,而這個讀寫操作可能非常耗時,為了解決這個耗時問題,引入寫緩衝器
- 一個處理器在寫資料的時候,不直接將資料寫入主內或快取記憶體,而是寫入寫緩衝器後直接返回,在特殊場景下才最終寫入主記憶體或快取記憶體。寫緩衝器加快處理器在暫存器間的計算互動
CPU多級快取架構
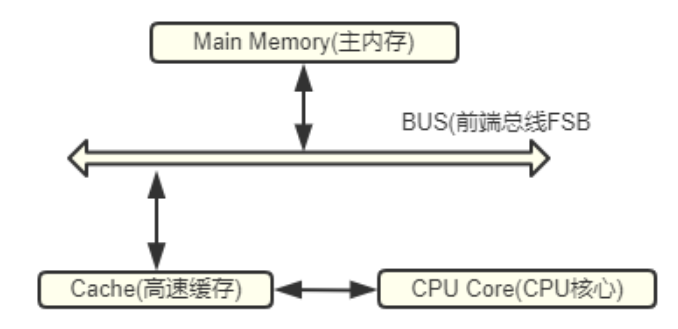 相關概念:
相關概念:
- BUS:負責將CPU連到記憶體,BUS頻率直接影響到CPU與記憶體資料交換速度。頻率越高CPU與記憶體之間資料傳輸量越大。所有的記憶體傳輸都發生在一條共用匯流排上,所有處理器都能看到這條匯流排,快取本身是獨立的,但是記憶體是共用資源,所有的記憶體存取都經過匯流排。同一個指令週期中,只有一個CPU快取可以讀寫記憶體。
- 快取記憶體:介於主記憶體和CPU之間,系統將一些CPU在近幾個時間段經常存取的資料存入快取記憶體,當CPU需要時先在快取記憶體中找。
CPU執行計算流程:
- 程式及資料被載入到主記憶體、指令和資料被載入到CPU快取記憶體
- CPU執行指令,將結果存到快取記憶體、快取記憶體把資料寫回到主記憶體
為什麼要快取記憶體呢?
- CPU頻率太快,主記憶體跟不上,CPU常常需要等待主記憶體浪費了資源,利用快取記憶體,緩解主記憶體和CPU之間的速度不匹配問題。
- 快取記憶體容量遠小於主記憶體,快取記憶體無法包含CPU所需要的所有資料,它存在的意義是區域性性原理:
- 時間區域性性:如果某個資料被存取,在不久的將來可能被再次存取
- 空間區域性性:如果某個資料被存取,與它相鄰的資料很快也可能被存取
快取記憶體的結構:
CPU的快取記憶體分為L1、L2、L3三級快取
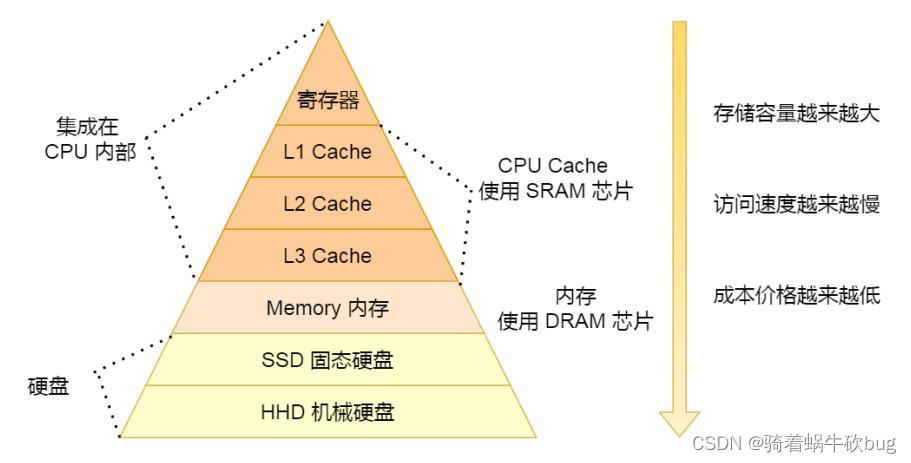
快取記憶體的底層結構是拉鍊雜湊表結構,很多個bucket,每個bucket掛了很多的cache entry。每個cache entry由tag、cache line和flag組成。cache line是快取的資料,可以包含多個變數的值,tag指向快取資料在主記憶體中的資料地址,flag標識快取行的狀態。
那麼CPU操作變數時,如何在快取記憶體中進行定位呢?
處理器在讀寫快取記憶體的時候,實際上會根據變數名執行一個記憶體地址解碼操作,解析出來index,tag和offset
- index用於定位到拉鍊雜湊表中某個bucket
- tag用於定位cache entry,指向這個快取資料在主記憶體中的資料的地址
- offset是定位一個變數在cache line中的位置。如果成功定位且flag還標誌有效,則快取命中。不滿足就是未命中。如果連續未命中,會從主記憶體重新載入資料到快取記憶體中。
瞭解了這些知識後,我們再來詳細聊一下MESI的工作過程:
- 處理器讀取某個變數資料時,首先根據index、tag、offset從快取記憶體的拉鍊雜湊表讀取資料。如果發現狀態是無效,會傳送read訊息到匯流排
- 接著主記憶體會返回對應資料給匯流排,通過read返回值返回給處理器。處理器把資料放到快取記憶體,同時cache entry的flag狀態設定為共用
- 在處理器對一個資料更新時,如果資料狀態是共用,就需要傳送一個invalidate訊息到匯流排,嘗試讓其他處理器的快取記憶體的cache entry全部變無效,已獲得資料的獨佔鎖
- 其他處理器會從匯流排嗅探到invalidate訊息,此時把自己的cache entry設定為無效,即過期掉自己的本地快取,然後返回ack訊息給匯流排,傳遞迴更新資料的處理器,必須收到所有處理器返回的ack
- 然後處理器就會將自己的cache entry設定為獨佔,在獨佔期間其他處理器不能修改資料,因為處理器此時發出invalidate訊息,這個處理器是不會返回ack的,除非他先修改完了。
- 接著處理器修改這個資料,將資料設定為修改過,也可能是把資料強制寫回主記憶體。
- 然後其他處理器看到這個資料狀態都是無效了,如果要讀,全部需要重新發read訊息,從主記憶體或其他處理器來載入,看具體底層硬體實現。
- 這套機制就是快取一致性在硬體快取模型下的完整執行原理,解決存在的可見性和有序性問題,但是存在序列的效能問題
序列化問題:每次寫資料都要傳送invalidate訊息並等待所有處理器ack,獲取到獨佔鎖才能寫資料。會導致效能很差,對於共用變數的寫操作,在硬體級別變成序列。因此在硬體層面引入寫緩衝器和無效佇列。
寫緩衝器和無效佇列:
- 寫緩衝器
- 作用是處理器寫資料,直接把資料寫入緩衝器,同時傳送invalidate訊息,就認為寫完成了。
- 然後處理器之後收到其他處理器的ack,會把寫緩衝器中的寫結果拿出來,通過對cache entry設定為獨佔,同時修改資料,設定為修改過,獨佔這條資料的讀寫操作
- 寫緩衝器通過不同步阻塞等待ack,提升硬體層面執行效率。查詢資料時,會先從緩衝器查,因為有可能剛修改的值在這裡,然後才會走快取記憶體。通過儲存轉發,同樣提升了效率
- 無效佇列:其他處理器收到invalidate訊息,不需要立馬過期本地快取,直接把訊息放入無效佇列,然後返回ack給寫處理器,加速效能。然後從無效佇列中取出訊息,過期本地快取
- 通過這兩個方式解決序列化效率問題。但是寫緩衝器和無效佇列的資料不能立馬回刷快取記憶體的話,會導致可見性問題。
寫緩衝器和無效佇列導致的可見性問題:
由於寫緩衝器和無效佇列,可能導致寫資料時不一定立馬寫入快取記憶體或主記憶體,因為可能寫入了寫緩衝器。讀資料不一定立馬從別人的快取記憶體或主記憶體重新整理最新值,invalidate訊息在無效佇列裡,有可能獲取到的值還是快取記憶體或主記憶體的舊值
寫緩衝器和無效佇列導致的有序性問題:
- Store Load重排序
- a=1是store,b=c是load。可能處理器對store操作先寫入寫緩衝器,此時這個寫操作就相當於沒有執行。然後就load操作了。這就導致第二行程式碼的load先執行了,第一行程式碼的store後執行。
- 第一個store操作寫到寫緩衝器,導致其他執行緒讀不到看不到。代表第二個load操作成功的執行StoreLoad重排,常見的有store先執行,load後執行,load先執行,store後執行。
- Store Store重排序
resoure = loadResource(); loaded = true;
兩個寫操作,如果第一個寫到寫緩衝器,第二個直接修改的快取記憶體,就會導致兩個寫操作的重排序。
有序性問題就是如此,會因為MESI的機制而發生。可見性也是如此,寫入寫緩衝器後,沒有刷入快取記憶體,就導致別人讀不到;讀資料時候,可能invalidate訊息在無效佇列裡,導致沒發立馬感知到過期的快取,立馬載入到最新資料。
引入記憶體屏障,解決硬體級別的可見性和有序性問題:
- Store+Load解決可見性問題:
- Store屏障:該屏障強制性要求對一個寫操作必須阻塞等待其他處理器返回invalidate ack後,對資料加鎖,然後修改資料到快取記憶體中,必須在寫資料後強制執行flush操作。
- flush處理器快取:把自己更像的值重新整理到快取記憶體或主記憶體。因為必須要重新整理後才有可能通過一些特殊機制讓其他處理器從自己的快取記憶體或主記憶體讀取到最新的值。
- Load屏障:在從快取記憶體中讀取資料時,如果發現無效佇列裡有一個invalidate訊息,會立馬強制根據那個invalidate訊息把自己本地快取記憶體的資料,設定為無效,然後強制從其他處理器的快取記憶體中載入最新值。這就是refresh操作。解決本地讀操作對自己處理器資料過期的可見性問題
- refresh處理器快取:除了flush外,還會傳送一個訊息到匯流排,通知其他處理器,某個變數值被他修改。refresh表示處理器中的執行緒在讀取一個變數值時,如果發現其他處理器的執行緒更新了變數的值,必須從其他處理器的快取記憶體或主記憶體,讀取這個最新的值,更新到自己的快取記憶體。
- 可見性保障底層是通過MESI協定、flush處理器快取、refresh處理器快取實現。
- flush是強制重新整理資料到快取記憶體或主記憶體,不要僅僅停留在寫緩衝器裡面。refresh是從匯流排嗅探發現某個變數被修改,必須強制從其他必須從其他處理器的快取記憶體或主記憶體,讀取這個最新的值,更新到自己的快取記憶體。
- Acquire+Release解決有序性問題:
- Acquire屏障:即StoreStore屏障,會強制讓寫操作全部按照順序寫入寫緩衝器,不會讓兩個寫操作一個寫到寫緩衝器,另一個直接修改快取記憶體。
- Release屏障:即StoreLoad屏障,會強制先將寫緩衝器的資料寫入快取記憶體,接著讀資料時強行清空無效佇列,對裡面的validate訊息全部過期掉快取記憶體中的條目,然後強制從主記憶體重新載入資料。
記憶體模型
作用:
保障共用記憶體的正確性(三特性),其定義了共用記憶體系統中多執行緒程式讀寫操作的規範。主要採用限制處理器優化(通過優化屏障避免編譯器的重排序優化操作)和使用記憶體屏障(通過讀寫屏障強制限制記憶體存取順序)。
JAVA記憶體模型(JMM):
- 符合記憶體模型規範,遮蔽了各種硬體和作業系統存取差異,保證java程式在各種平臺下對記憶體的存取都能保證效果一致的機制及規範
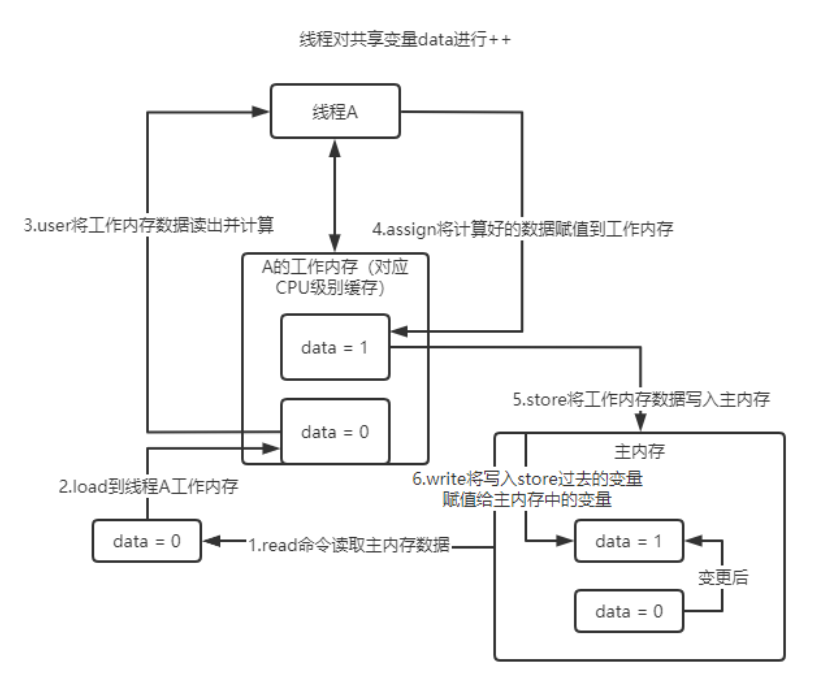
- 該模型規定所有變數都儲存在主記憶體中,每個執行緒有自己的工作記憶體,儲存了該執行緒用到的變數在主記憶體中的副本拷貝。執行緒對變數的操作都必須在自己的工作記憶體中進行不能直接讀寫主記憶體,不同執行緒之間工作記憶體不能直接存取,執行緒間變數的傳遞需要在自己工作記憶體和主記憶體直接進行資料同步。
- 在JMM中,資料用read從主記憶體讀取資料,用load將資料加入工作記憶體,user將工作記憶體資料讀出並計算,assign將計算好的資料賦值到工作記憶體,store將工作記憶體資料寫入主記憶體,write將寫入store過去的變數賦值給主記憶體中順序不能打亂,保證使用變數前一定是從主記憶體拿的新值、assign、write順序不能打斷,保證賦值後馬上寫入主記憶體。 因此在use前插入讀屏障,從主記憶體拿最新值,讓工作記憶體中資料失效。在assign之後插入寫屏障,保證寫入工作記憶體的最新資料更新到主記憶體被其他執行緒可見。
Happens-before(先行發生原則):
- 程式順序性規則:在一個執行緒中,按程式碼順序,前面的操作先行發生於後續的任意操作
- volatile變數規則:對一個volatile變數的寫操作先行發生於後面對這個變數的讀操作
- 傳遞性:如果A先行發生於B且B先行發生於C,那A先行發生於C
- 鎖的規則:一個鎖的解鎖操作先行發生於後續對這個鎖的加鎖
- 執行緒啟動規則:Thread物件的start()方法先行發生於此執行緒的每一個動作,在主執行緒執行過程中,啟動子執行緒,那麼主執行緒在啟動子執行緒之前對共用變數的修改結果對子執行緒可見。
- 執行緒join()規則:在主執行緒執行過程中,子執行緒終止,那麼子執行緒在終止之前對共用變數的修改結果在主執行緒中可見(join方法)
- 執行緒中斷規則:對執行緒interrupt()方法的呼叫先行發生於被中斷執行緒的程式碼檢測到中斷事件的發生,可以通過Thread.interrupted()方法檢測到是否有中斷髮生。
- 物件終結規則:一個物件的初始化完成(建構函式執行結束)先行發生於它的finalize()方法的開始。
本文來自部落格園,作者:難得,轉載請註明原文連結:https://www.cnblogs.com/zhangbLearn/p/16638313.html