技術基建如何降本增效——雲遷移
原創不易,求分享、求一鍵三連
網際網路寒冬大背景下,降本增效尤其是降本成了大部分公司的選擇,我們公司也不例外,但顯然困難很大!因為剛發生了團隊合併行為...具體困難有以下幾點:
- 兩個團隊初期規模300多人,當前兩個APP同時維護,而後優化到不足100人;
- A團隊使用騰訊雲;B團隊使用阿里雲;
- A團隊後端技術棧為Java;B團隊後端技術棧是golang,還有部分php;
- A團隊APP體系之前可能放棄治療了,居然使用的是原生+Flutter+Hybrid;B團隊使用的原生+RN;
- 前端體系Vue、React都在用...
- ...
這條船真的不好開!!!技術人員減少了,而服務規模未減少,在人員急劇減少的情況下需要研發側從工程建設、團隊管理、服務資源、需求控制等四方面進行降本增效的規劃且同時還要穩固團隊來保障業務穩定增長,所以在資源有限的情況下需要做什麼,先做什麼,後做什麼?
這真的很難,不做是死,做也很難受,這裡選擇的答案是什麼呢?
答案是:向錢看!因為騰訊對我們有技術投資,所以騰訊雲非常非常便宜,為節約每年400萬的阿里雲研發費用,我們決定先將業務從阿里雲遷移到騰訊雲,也就有了雲遷移這個專案。
整個雲遷移專案耗時5個月,共53人蔘與(包含2位外包),涉及產品、開發、測試、工程、IT、客服、財務等多個團隊和部門,涉及的雲資源包含
- ECS 185臺(共1511核);
- MySQL範例(含自建) 16個;
- Redis範例(含自建) 11個;
- MongoDB範例(含自建) 3個;
- ES(含自建)範例 4個;
- kafka叢集2個;
整個專案耗時5個月(4月1日 - 8月31日),專案里程碑:
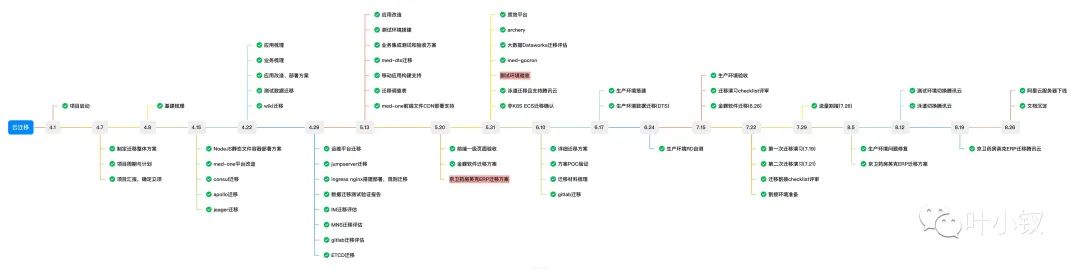
整個專案經歷了:
- 專案調研立項->
- 基建平臺遷移->
- 業務改造->
- 測試環境搭建->
- 生產環境搭建->
- 生產環境正式割接->
- 測試環境切換->
- 三方ERP系統遷移->
- 阿里雲資源下線
共9個關鍵節點,期間組織了16次大型週會,整個專案進度和質量均符合預期,以下是一些實操經驗,分享給大家。
遷移取捨
- 是否需要外包
根據團隊現狀,沒有任何一位研發過往有過雲遷移的經歷,同時團隊在資料遷移這塊缺乏經驗,加上研發人力吃緊,最終決定與騰訊云云遷移外包團隊合作,通過借鑑專業團隊的經驗來增加專案的成功率。
- 是否需要搭建測試環境
既然已經與外包團隊合作了,為什麼還需要搭建測試環境?目的是為了認知對齊,保證公司內部團隊對雲遷移整個事情有相對完整的認識和預期,提前識別專案中的一些關鍵風險點,畢竟外包團隊只是有成熟的雲遷移方法論,但不熟悉業務,遷移方案還是需要根據業務具體情況來制定實施。
- 目標是什麼
出現問題在所難免,需要集中力量辦大事。整個專案目標從一開始就很明確:保證遷移過程中,核心業務核心鏈路核心功能不出問題;並沒有設定一個大而全的目標:保證遷移過程中,業務不出問題。
- 歷史債務如何處理
在不影響專案交付的前提下,對一些技術債務、架構不合理的點,要及時優化,降低整套業務系統的熵;對於一些耗時耗力的債務,應果斷放棄,不能過於增加雲遷移專案本身的複雜度。
- 業務改造方案怎麼定
涉及業務改動的點應足夠少,影響範圍足夠小,這樣能更好地控制專案進度,同時應準備好業務遷移改造指引檔案,提高業務開發改造效率,同時保證業務穩定性。
方案詳述
雲遷移專案整體複雜度高,需要層層拆解,化整為零,個個擊破:

叢集規劃
由於歷史原因,阿里雲叢集規劃不合理:經典網路與VPC並存,容器部署與ECS部署並存,生產叢集安全組由於網段原因無法完全禁止外網存取資料庫,安全性差,維護成本高。為保證安全性和架構統一,遷移騰訊雲時,對叢集和網路做了重新規劃:
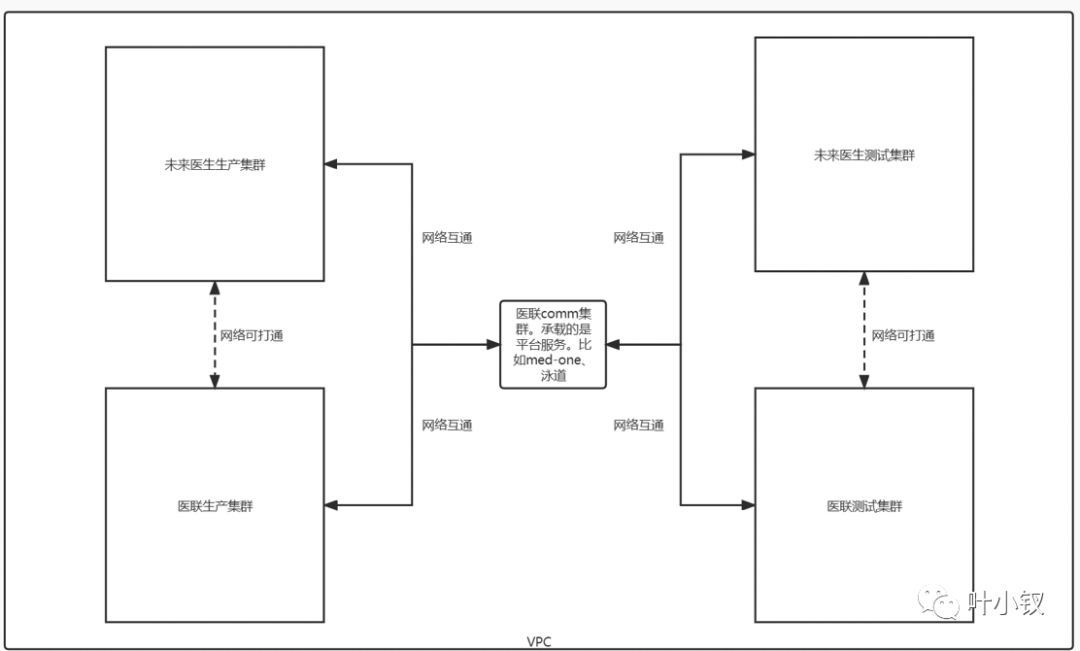
新叢集統一使用Kubernetes作為基礎設施,統一走容器化部署;叢集也按基建、業務分別建了叢集,清晰明瞭,互不影響。
基建先行
從Nginx到Kubernetes ingress
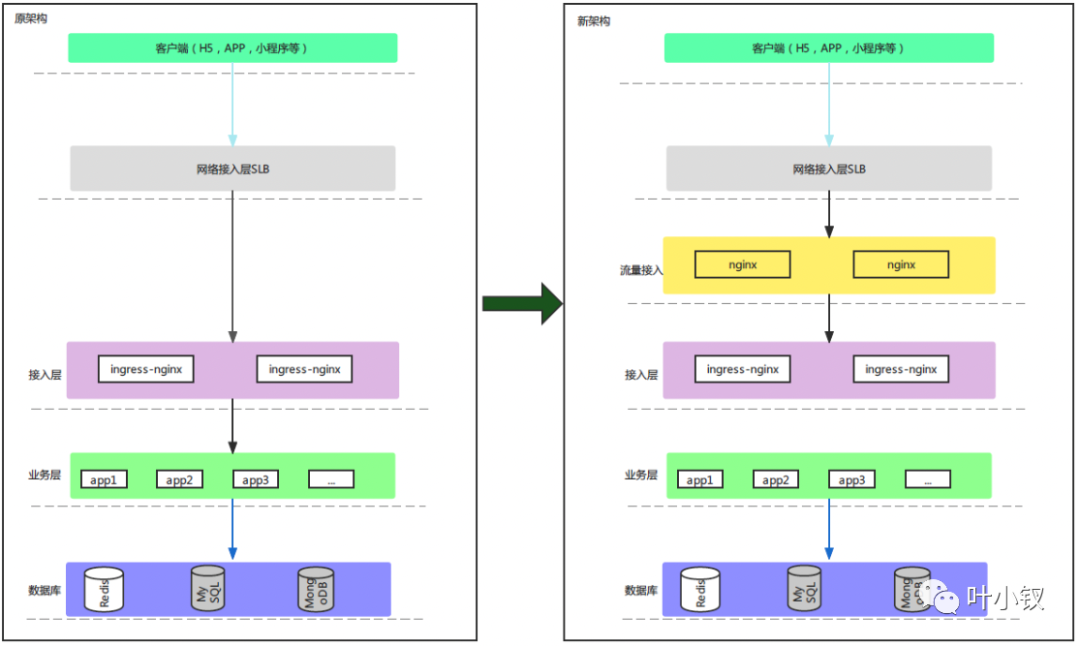
當前Nginx存在牽一髮而動全身的問題,任何一項設定變更均為全域性變更,有引發全站故障的風險。為保障業務的穩定性,使用Kubernetes ingress替代Nginx,路由設定變更從全域性變更變為區域性變更,從而降低風險。當然,ingress與Nginx存在相容性問題,需要業務來配合調整部署方案。
前端靜態檔案容器化部署
當前前端靜態檔案是通過NAS掛載的方式與Nginx聯動,使得Nginx變成有狀態應用。當前架構:
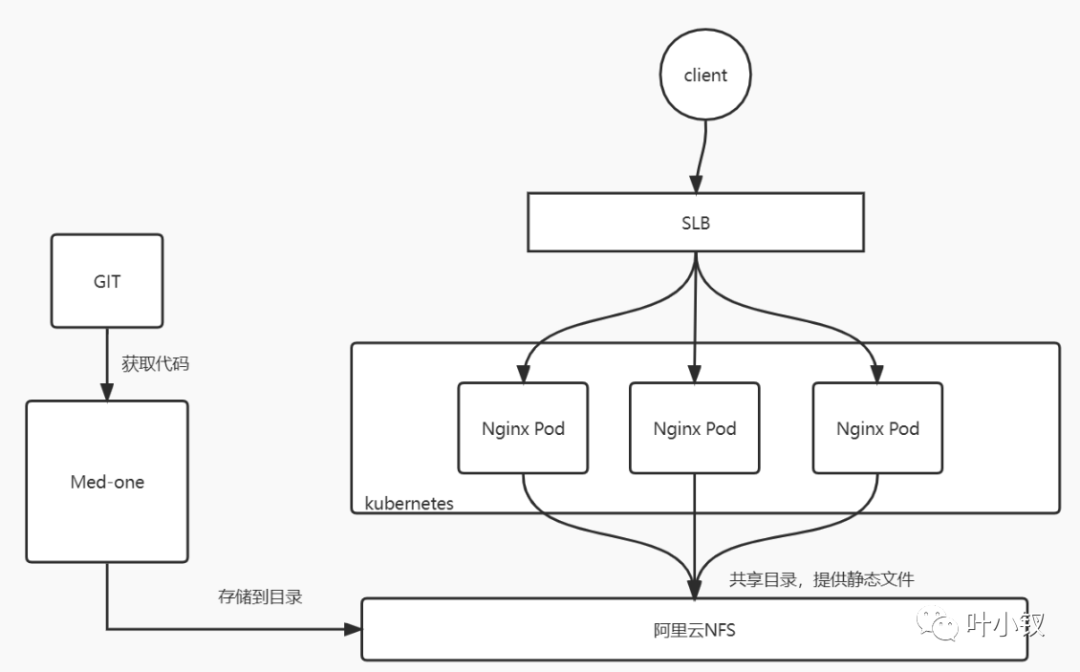
由於ingress是無狀態的,且不支援掛載目錄的方式,同時為了保證架構統一,將前端靜態檔案部署改為容器化部署,新架構:
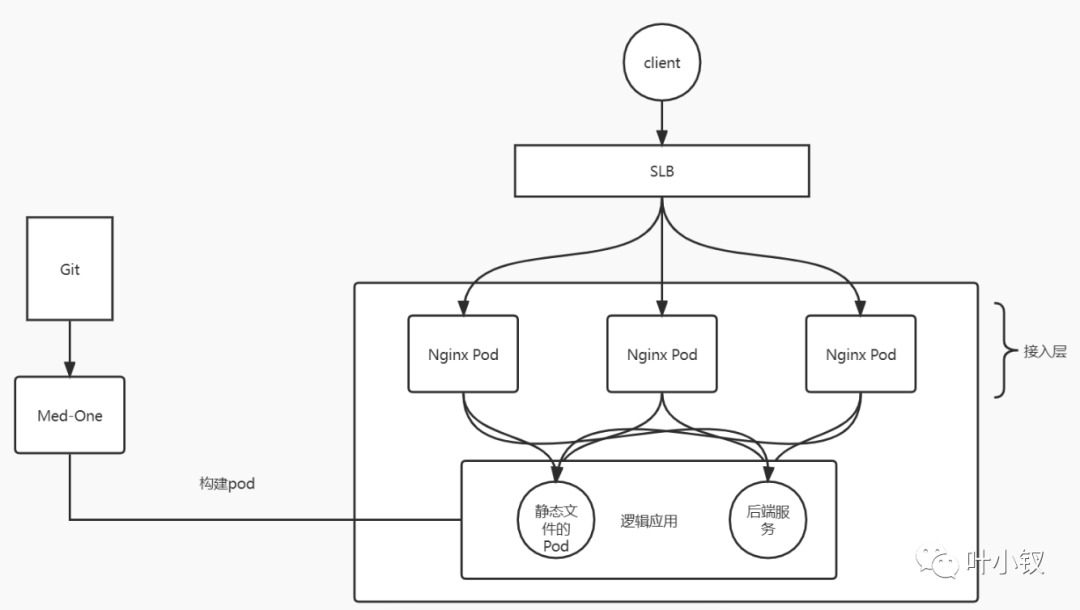
新架構統一了前後端應用部署方式,架構變得更加簡潔統一,維護成本降低。
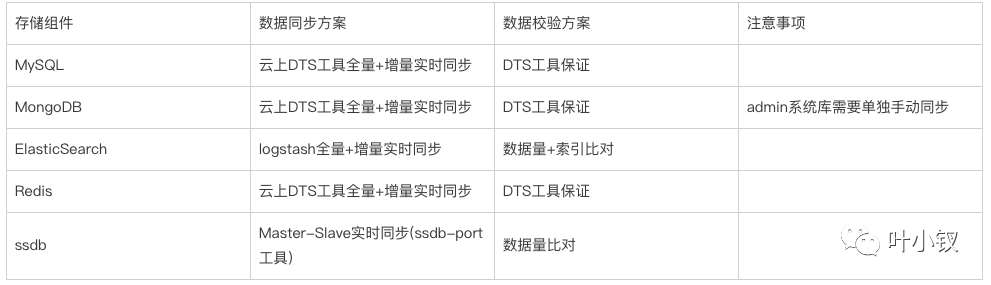
資料遷移
資料遷移最關鍵的是保證資料的完整性與一致性,這裡均採用業界成熟的資料實時同步方案來完成資料遷移:
自動化工具
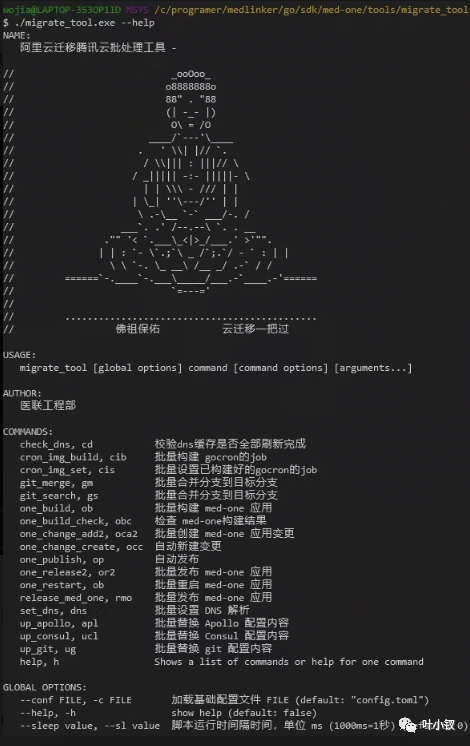
雲遷移涉及很多批次操作,包括批次構建、批次釋出、批次修改設定、批次重啟、批次切換DNS等,為保證遷移的效率和操作的穩定性,所有批次操作都工具化,下圖是小夥伴批跑的工具集:
部署標準化
程式碼、CI設定、CD設定分離,Dockerfile、啟動指令碼(start.sh)交由DevOps平臺管理,標準化、易維護。
業務改造
MNS更換為CMQMNS是阿里雲專有的訊息中介軟體,支付中心有使用,為了保證業務改動量最小,採用了騰訊雲對標的訊息中介軟體CMQ,僅支付中心改造,業務呼叫服務修改設定即可
med-dts應用遷移業務側有直接使用DTS資料訂閱進行消費的鏈路,由於阿里雲與騰訊雲DTS訂閱服務資料協定的差異,對應的消費者應用med-dts需要做協定適配改造
業務設定遷移由於歷史原因,設定中心有兩套:consul + git倉庫;apollo設定中心。業務設定遷移之後涉及資料庫等設定的修改,而且需要考慮批次更新設定。對於consul + git倉庫的設定中心,採用git patch的方式保證設定的準確性;對於apollo設定中心,採用批次替換工具全量替換的方式保證準確性
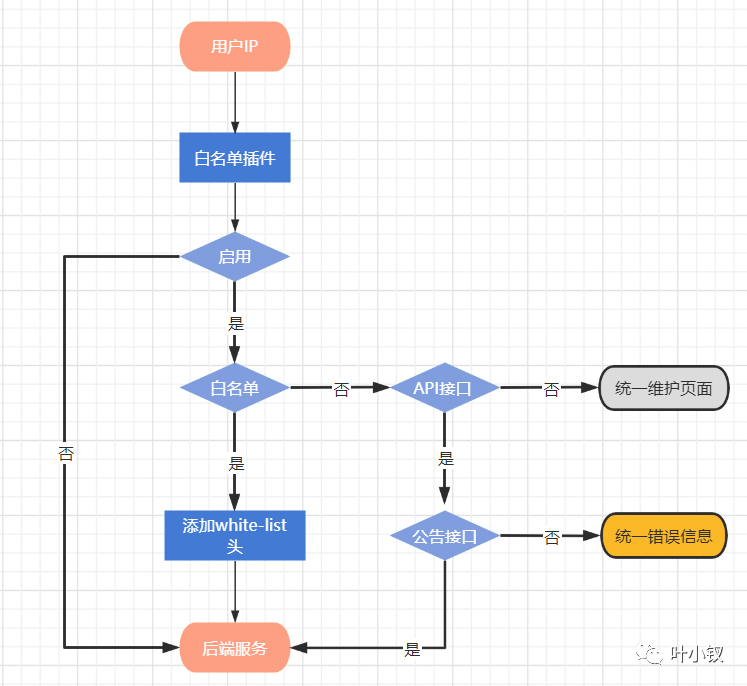
業務停服公告
遷移割接採用停服的方式進行遷移,需要提前公告通知;同時,停服進行業務驗證期間,只允許辦公網流量和供應商回撥的流量進入系統,需要提供IP白名單功能。這裡在架構上增加一層代理層,做白名單控制:
第三方供應商測試方案
做生產環境無自然流量業務驗收時,整套生產環境的架構變成兩套生產環境(騰訊雲、阿里雲)對接一套供應商生產環境,醫聯和供應商的資料一致性、介面回撥均有問題:騰訊雲發起的測試訂單在阿里雲側沒有、供應商的訂單回撥也只會回撥到阿里雲生產。該場景主要涉及訂單中心、支付中心,解決方案:
- 訂單庫訂單表自增id跳id 1000萬,用於區分不同雲環境訂單,有業務邏輯依賴自增id。若需要多次測試,則每次訂單資料都需要備份,且訂單庫訂單表自增id每次都需要跳id 1000萬
- 支付中心直接從騰訊雲匯入測試的支付單資料即可,不依賴自增id。若需要多次測試,則每次支付資料都需要備份
- 正式流量割接前,備份業務驗收的測試訂單、支付資料,割接成功後再匯入資料庫
生產快速驗收方案
生產環境流量割接需要在天窗時間進行,並向業務方承諾8小時內(23:00 - 7:00)完成割接,需要制定割接後的業務快速驗收方案,由QA團隊負責制定與執行:
箇中波折
雲上Redis Cluster版本特性差異導致自研延時佇列無法回撥業務
阿里雲與騰訊雲的Redis Cluster多分片(8分片)版本存在命令不相容的情況,延時佇列有使用MULTI; SET a b; SET b c;EXEC命令,在騰訊雲上命令無法執行,阿里雲可正常執行。詳見官方檔案:Redis不同版本相容命令列表。定位到問題原因後,將Redis Cluster更換為標準架構版本,問題解決
部署方式差異,導致延時佇列重啟後無法處理重啟前的資料
將延時佇列從StatefulSets部署變為Deployments部署(方便平臺維護),重啟後發現延時佇列無法load存量的延時任務,經過排查,發現延時佇列的Redis SortedSet名依賴了Pod Name,當作為Deployment部署時,每次重啟Pod Name就會發生變化,進而無法從Redis load存量的延時任務。解決方案:
- 合併所有SortedSet的資料到SortedSet 0和1(兩個範例)
- 將延時佇列改為StatefulSets部署,保證Pod Name不會因重啟發生變化
不太穩定的騰訊雲DTS,導致割接延期
騰訊雲MongoDB DTS資料同步過程中發生過MongoDB主從切換導致DTS同步失敗、CPU負載過高導致DTS程序僵死的問題,不夠穩定,導致正式割接延期一天。出現問題後,緊急拉騰訊雲開發來支援解決問題,通過升配 + 增大DTS同步並行數,快速將資料同步完成。
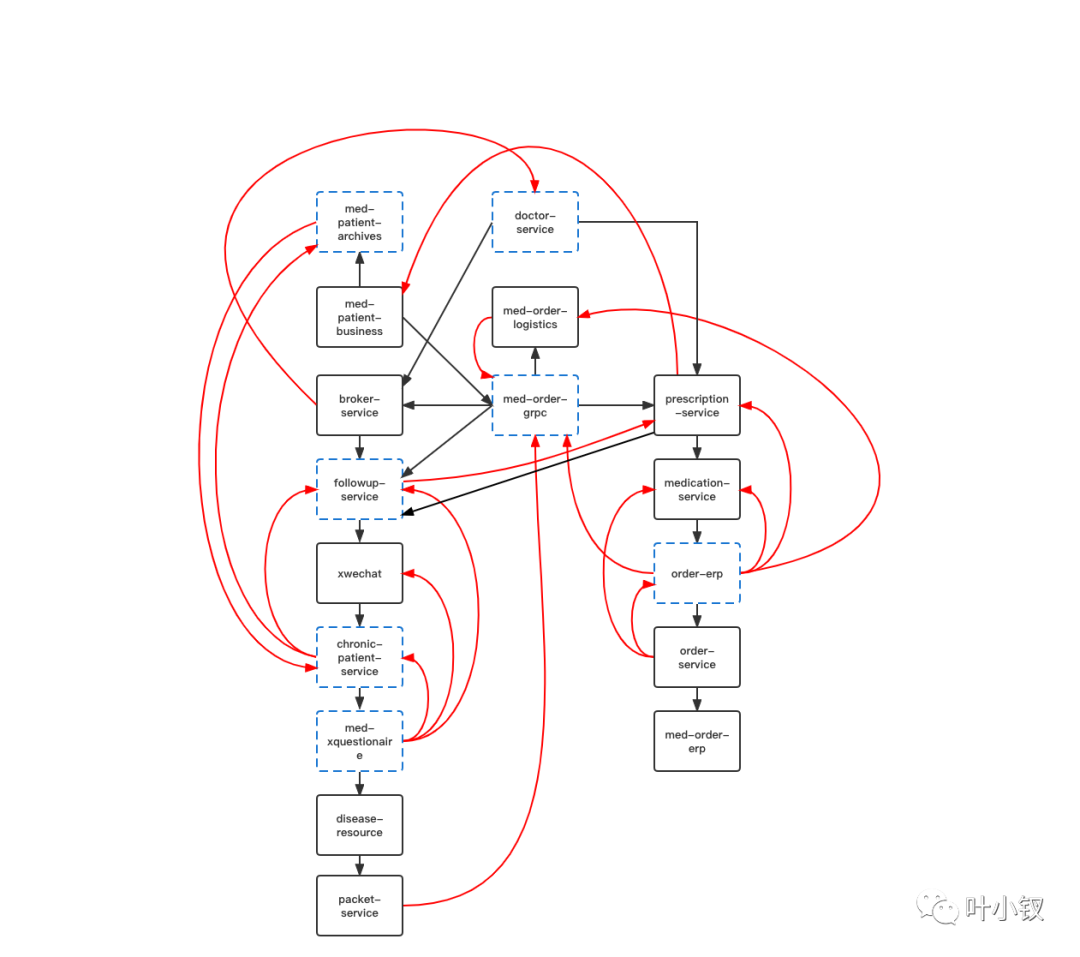
令人無奈的迴圈依賴
批次部署應用時,發現很多應用存在迴圈依賴導致應用無法啟動成功,需要修改程式碼,無奈,只能一個個解決,解環。圖中藍色虛框即表示修改過的服務:
生產割接
雖然割接方案也來來回回評審了3次,割接演習了兩次,演習過程也挺順利,但正式割接時,還是出了一些突發狀況,包括DTS資料訂閱建立失敗(kafka topic資源割接時達到上限)、DNS域名解析切換全網生效時長超過演習時、代理白名單機制遺漏CMQ公網IP等問題。這些問題在割接過程中引起了一些小波瀾,但都非阻塞性問題,快速解決後,最終生產割接在承諾時間內順利完成:

專案感悟
- 高效決策環境
專案參與人員過多時,很難保證資訊同步和透明。為保證專案快速推進和決策,需要組建一個核心決策團隊,包含各合作團隊負責人、專案核心成員,專案所有關鍵資訊都需要在團隊及時同步,有問題共同快速協商、決策、解決。
- 去中心化決策
目標一致的前提下,尋找合作者,而非執行者,實行"我們一起幹,共同把專案做成"的王道,而非"你來配合我做這做那"的霸道;
不影響目標和進度的前提下,儘可能滿足合作方訴求,調動積極性;尊重人性,尊重不同的聲音,站在同一目標下理性討論方案;決策權下放,每個人熟悉掌握的領域有限,要把具體的任務項給最合適的人去決策執行,專案負責人控制好進度和風險即可。
- 高效執行團隊
除了高效決策,高效執行也是必需的。組建一支短小精悍的執行團隊,可以保證方案的試驗、問題的解決都能快速落地。同時,快速的階段性成功反饋可大大增加核心成員對於專案推進的信心,減少專案推進的阻力,保證專案更平穩地推進下去。
- 專案決策者、贊助者、執行者保持充分溝通
專案推行過程中,出現了專案人力與業務需求人力衝突和封板通知未及時同步到產品負責人的情況,導致業務推進過程中出現了被動的局面。
作為專案負責人(執行者),應該定時與部門領導(決策者、贊助者)保持溝通,同步風險;也能提前爭取到部門領導對外的支援與協調,獲取業務部門反饋,及時調整策略,避免出現被動局面,保證專案穩定有序推進。
- 拆解目標,化整為零
整個專案複雜度高,週期長。需要拆解總體目標,不斷交付階段性目標,持續反饋和調整,形成正迴圈。
- 提前和雲廠商團隊溝通,獲取專人支援
雲遷移涉及公司所有業務,通常複雜度都會比較高,割接前提前與雲廠商溝通,爭取專人支援,可快速解決雲上的一些問題,提高遷移成功率和效率。
- 外包雖好,但不可過度依賴
雲遷移外包團隊豐富的雲遷移經驗可以幫助團隊少走很多彎路,但外包團隊不熟悉公司業務,專案的整體計劃和方案還是需要公司內部團隊來主導和把控,這樣可以減少遷移問題和風險。
- 預留演習的時間
正式割接前,一定要演習,最好演習2-3次,增加割接操作的熟練與穩定,期間暴露的問題也可以提前解決,做割接方案的最後補足。
- 專案階段性任務延期
關注延期風險,延期任務對專案目標的影響,如果影響不大或者無影響,可以先捨棄,優先保證目標按期達成。
- 專案覆盤
不管專案成功還是失敗,都應做好覆盤,從專案各個角色、各個崗位,思考總結提升大型架構活動成功率的方法論,好的經驗需要沉澱下來改進流程,甚至改進文化;不好的應及時糾正,防止下次出錯。
- 謹慎造輪子
對於業務在雲上的公司,應儘量使用雲上的基礎元件,對於造輪子保持克制與謹慎的態度,組織架構變動、人員離職都很有可能讓輪子無人維護,一旦出問題很可能就是大問題。
- 持續解決重要不緊急問題
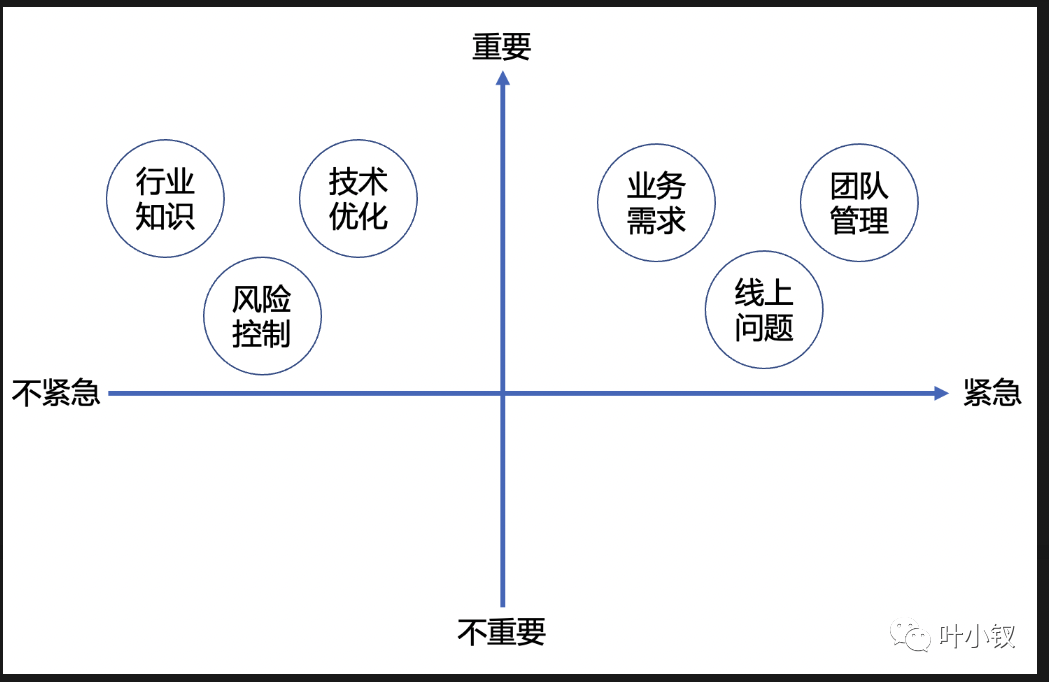
優秀的技術管理者需要時刻與系統熵增做鬥爭,將系統的熵控制在一定範圍,持續關注第二象限的事,積極修煉"內功"。做好第一象限是本職,做好第二象限方顯功力。
好了,今天的分享就到這。如果本文對你有幫助的話,歡迎點贊&評論&在看&分享,這對我非常重要,感謝