【面試必備】我跟面試官聊了一個小時執行緒池!
大家好,這篇文章主要跟大家聊下 Java 執行緒池面試中可能會問到的一些問題。
全程乾貨,耐心看完,你能輕鬆應對各種執行緒池面試。
相信各位 Javaer 在面試中或多或少肯定被問到過執行緒池相關問題吧,執行緒池是一個相對比較複雜的體系,基於此可以問出各種各樣、五花八門的問題。
若你很熟悉執行緒池,如果可以,完全可以滔滔不絕跟面試官扯一個小時執行緒池,一般面試也就一個小時左右,那麼這樣留給面試官問其他問題的時間就很少了,或者其他問題可能問的也就不深入了,那你通過面試的機率是不就更大點了呢。

下面我們開始列下執行緒池面試可能會被問到的問題以及該怎麼回答,以下只是參考答案,你也可以加入自己的理解。
1. 面試官:日常工作中有用到執行緒池嗎?什麼是執行緒池?為什麼要使用執行緒池?
一般面試官考察你執行緒池相關知識前,大概率會先問這個問題,如果你說沒用過,不瞭解,ok,那就沒以下問題啥事了,估計你的面試結果肯定也凶多吉少了。
作為 JUC 包下的門面擔當,執行緒池是名副其實的 JUC 一哥,不瞭解執行緒池,那說明你對 JUC 包其他工具也瞭解的不咋樣吧,對 JUC 沒深入研究過,那就是沒掌握到 Java 的精髓,給面試官這樣一個印象,那結果可想而知了。
所以說,這一分一定要吃下,那我們應該怎麼回答好這問題呢?
可以這樣說:
計算機發展到現在,摩爾定律在現有工藝水平下已經遇到難易突破的物理瓶頸,通過多核 CPU 平行計算來提升伺服器的效能已經成為主流,隨之出現了多執行緒技術。
執行緒作為作業系統寶貴的資源,對它的使用需要進行控制管理,執行緒池就是採用池化思想(類似連線池、常數池、物件池等)管理執行緒的工具。
JUC 給我們提供了 ThreadPoolExecutor 體系類來幫助我們更方便的管理執行緒、並行執行任務。
下圖是 Java 執行緒池繼承體系:
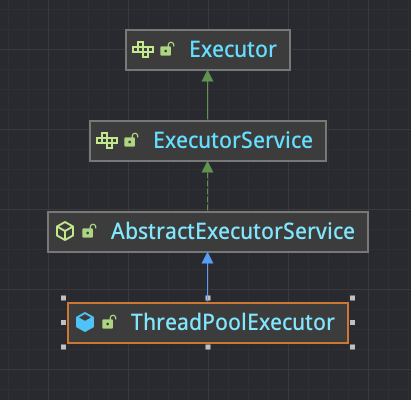
使用執行緒池可以帶來以下好處:
降低資源消耗。降低頻繁建立、銷燬執行緒帶來的額外開銷,複用已建立執行緒
降低使用複雜度。將任務的提交和執行進行解耦,我們只需要建立一個執行緒池,然後往裡面提交任務就行,具體執行流程由執行緒池自己管理,降低使用複雜度
提高執行緒可管理性。能安全有效的管理執行緒資源,避免不加限制無限申請造成資源耗盡風險
提高響應速度。任務到達後,直接複用已建立好的執行緒執行
執行緒池的使用場景簡單來說可以有:
快速響應使用者請求,響應速度優先。比如一個使用者請求,需要通過 RPC 呼叫好幾個服務去獲取資料然後聚合返回,此場景就可以用執行緒池並行呼叫,響應時間取決於響應最慢的那個 RPC 介面的耗時;又或者一個註冊請求,註冊完之後要傳送簡訊、郵件通知,為了快速返回給使用者,可以將該通知操作丟到執行緒池裡非同步去執行,然後直接返回使用者端成功,提高使用者體驗。
單位時間處理更多請求,吞吐量優先。比如接受 MQ 訊息,然後去呼叫第三方介面查詢資料,此場景並不追求快速響應,主要利用有限的資源在單位時間內儘可能多的處理任務,可以利用佇列進行任務的緩衝

2. 面試官:ThreadPoolExecutor 都有哪些核心引數?
其實一般面試官問你這個問題並不是簡單聽你說那幾個引數,而是想要你描述下執行緒池執行流程。
青銅回答:
包含核心執行緒數(corePoolSize)、最大執行緒數(maximumPoolSize),空閒執行緒超時時間(keepAliveTime)、時間單位(unit)、阻塞佇列(workQueue)、拒絕策略(handler)、執行緒工廠(ThreadFactory)這7個引數。
鑽石回答:
回答完包含這幾個引數之後,會再主動描述下執行緒池的執行流程,也就是 execute() 方法執行流程。
execute()方法執行邏輯如下:
public void execute(Runnable command) {
if (command == null)
throw new NullPointerException();
int c = ctl.get();
if (workerCountOf(c) < corePoolSize) {
if (addWorker(command, true))
return;
c = ctl.get();
}
if (isRunning(c) && workQueue.offer(command)) {
int recheck = ctl.get();
if (! isRunning(recheck) && remove(command))
reject(command);
else if (workerCountOf(recheck) == 0)
addWorker(null, false);
}
else if (!addWorker(command, false))
reject(command);
}
可以總結出如下主要執行流程,當然看上述程式碼會有一些異常分支判斷,可以自己順理加到下述執行主流程裡
判斷執行緒池的狀態,如果不是RUNNING狀態,直接執行拒絕策略
如果當前執行緒數 < 核心執行緒池,則新建一個執行緒來處理提交的任務
如果當前執行緒數 > 核心執行緒數且任務佇列沒滿,則將任務放入阻塞佇列等待執行
如果 核心執行緒池 < 當前執行緒池數 < 最大執行緒數,且任務佇列已滿,則建立新的執行緒執行提交的任務
如果當前執行緒數 > 最大執行緒數,且佇列已滿,則執行拒絕策略拒絕該任務
王者回答:
在回答完包含哪些引數及 execute 方法的執行流程後。然後可以說下這個執行流程是 JUC 標準執行緒池提供的執行流程,主要用在 CPU 密集型場景下。
像 Tomcat、Dubbo 這類框架,他們內部的執行緒池主要用來處理網路 IO 任務的,所以他們都對 JUC 執行緒池的執行流程進行了調整來支援 IO 密集型場景使用。
他們提供了阻塞佇列 TaskQueue,該佇列繼承 LinkedBlockingQueue,重寫了 offer() 方法來實現執行流程的調整。
@Override
public boolean offer(Runnable o) {
//we can't do any checks
if (parent==null) return super.offer(o);
//we are maxed out on threads, simply queue the object
if (parent.getPoolSize() == parent.getMaximumPoolSize()) return super.offer(o);
//we have idle threads, just add it to the queue
if (parent.getSubmittedCount()<=(parent.getPoolSize())) return super.offer(o);
//if we have less threads than maximum force creation of a new thread
if (parent.getPoolSize()<parent.getMaximumPoolSize()) return false;
//if we reached here, we need to add it to the queue
return super.offer(o);
}
可以看到他在入隊之前做了幾個判斷,這裡的 parent 就是所屬的執行緒池物件
1.如果 parent 為 null,直接呼叫父類別 offer 方法入隊
2.如果當前執行緒數等於最大執行緒數,則直接呼叫父類別 offer()方法入隊
3.如果當前未執行的任務數量小於等於當前執行緒數,仔細思考下,是不是說明有空閒的執行緒呢,那麼直接呼叫父類別 offer() 入隊後就馬上有執行緒去執行它
4.如果當前執行緒數小於最大執行緒數量,則直接返回 false,然後回到 JUC 執行緒池的執行流程回想下,是不是就去新增新執行緒去執行任務了呢
5.其他情況都直接入隊
具體可以看之前寫過的這篇文章
動態執行緒池(DynamicTp),動態調整Tomcat、Jetty、Undertow執行緒池引數篇
可以看出噹噹前執行緒數大於核心執行緒數時,JUC 原生執行緒池首先是把任務放到佇列裡等待執行,而不是先建立執行緒執行。
如果 Tomcat 接收的請求數量大於核心執行緒數,請求就會被放到佇列中,等待核心執行緒處理,這樣會降低請求的總體響應速度。
所以 Tomcat並沒有使用 JUC 原生執行緒池,利用 TaskQueue 的 offer() 方法巧妙的修改了 JUC 執行緒池的執行流程,改寫後 Tomcat 執行緒池執行流程如下:
判斷如果當前執行緒數小於核心執行緒池,則新建一個執行緒來處理提交的任務
如果當前當前執行緒池數大於核心執行緒池,小於最大執行緒數,則建立新的執行緒執行提交的任務
如果當前執行緒數等於最大執行緒數,則將任務放入任務佇列等待執行
如果佇列已滿,則執行拒絕策略
然後還可以再說下執行緒池的 Worker 執行緒模型,繼承 AQS 實現了鎖機制。執行緒啟動後執行 runWorker() 方法,runWorker() 方法中呼叫 getTask() 方法從阻塞佇列中獲取任務,獲取到任務後先執行 beforeExecute() 勾點函數,再執行任務,然後再執行 afterExecute() 勾點函數。若超時獲取不到任務會呼叫 processWorkerExit() 方法執行 Worker 執行緒的清理工作。
詳細原始碼解讀可以看之前寫的文章:

3. 面試官:什麼是阻塞佇列?說說常用的阻塞佇列有哪些?
阻塞佇列 BlockingQueue 繼承 Queue,是我們熟悉的基本資料結構佇列的一種特殊型別。
當從阻塞佇列中獲取資料時,如果佇列為空,則等待直到佇列有元素存入。當向阻塞佇列中存入元素時,如果佇列已滿,則等待直到佇列中有元素被移除。提供 offer()、put()、take()、poll() 等常用方法。
JDK 提供的阻塞佇列的實現有以下幾種:
1)ArrayBlockingQueue:由陣列實現的有界阻塞佇列,該佇列按照 FIFO 對元素進行排序。維護兩個整形變數,標識佇列頭尾在陣列中的位置,在生產者放入和消費者獲取資料共用一個鎖物件,意味著兩者無法真正的並行執行,效能較低。
2)LinkedBlockingQueue:由連結串列組成的有界阻塞佇列,如果不指定大小,預設使用 Integer.MAX_VALUE 作為佇列大小,該佇列按照 FIFO 對元素進行排序,對生產者和消費者分別維護了獨立的鎖來控制資料同步,意味著該佇列有著更高的並行效能。
3)SynchronousQueue:不儲存元素的阻塞佇列,無容量,可以設定公平或非公平模式,插入操作必須等待獲取操作移除元素,反之亦然。
4)PriorityBlockingQueue:支援優先順序排序的無界阻塞佇列,預設情況下根據自然序排序,也可以指定 Comparator。
5)DelayQueue:支援延時獲取元素的無界阻塞佇列,建立元素時可以指定多久之後才能從佇列中獲取元素,常用於快取系統或定時任務排程系統。
6)LinkedTransferQueue:一個由連結串列結構組成的無界阻塞佇列,與LinkedBlockingQueue相比多了transfer和tryTranfer方法,該方法在有消費者等待接收元素時會立即將元素傳遞給消費者。
7)LinkedBlockingDeque:一個由連結串列結構組成的雙端阻塞佇列,可以從佇列的兩端插入和刪除元素。

4. 面試官:你剛說到了 Worker 繼承 AQS 實現了鎖機制,那 ThreadPoolExecutor 都用到了哪些鎖?為什麼要用鎖?
1)mainLock 鎖
ThreadPoolExecutor 內部維護了 ReentrantLock 型別鎖 mainLock,在存取 workers 成員變數以及進行相關資料統計記賬(比如存取 largestPoolSize、completedTaskCount)時需要獲取該重入鎖。
面試官:為什麼要有 mainLock?
private final ReentrantLock mainLock = new ReentrantLock();
/**
* Set containing all worker threads in pool. Accessed only when
* holding mainLock.
*/
private final HashSet<Worker> workers = new HashSet<Worker>();
/**
* Tracks largest attained pool size. Accessed only under
* mainLock.
*/
private int largestPoolSize;
/**
* Counter for completed tasks. Updated only on termination of
* worker threads. Accessed only under mainLock.
*/
private long completedTaskCount;
可以看到 workers 變數用的 HashSet 是執行緒不安全的,是不能用於多執行緒環境的。largestPoolSize、completedTaskCount 也是沒用 volatile 修飾,所以需要在鎖的保護下進行存取。
面試官:為什麼不直接用個執行緒安全容器呢?
其實 Doug 老爺子在 mainLock 變數的註釋上解釋了,意思就是說事實證明,相比於執行緒安全容器,此處更適合用 lock,主要原因之一就是序列化 interruptIdleWorkers() 方法,避免了不必要的中斷風暴
面試官:怎麼理解這個中斷風暴呢?
其實簡單理解就是如果不加鎖,interruptIdleWorkers() 方法在多執行緒存取下就會發生這種情況。一個執行緒呼叫interruptIdleWorkers() 方法對 Worker 進行中斷,此時該 Worker 出於中斷中狀態,此時又來一個執行緒去中斷正在中斷中的 Worker 執行緒,這就是所謂的中斷風暴。
面試官:那 largestPoolSize、completedTaskCount 變數加個 volatile 關鍵字修飾是不是就可以不用 mainLock 了?
這個其實 Doug 老爺子也考慮到了,其他一些內部變數能用 volatile 的都加了 volatile 修飾了,這兩個沒加主要就是為了保證這兩個引數的準確性,在獲取這兩個值時,能保證獲取到的一定是修改方法執行完成後的值。如果不加鎖,可能在修改方法還沒執行完成時,此時來獲取該值,獲取到的就是修改前的值。
2)Worker 執行緒鎖
剛也說了 Worker 執行緒繼承 AQS,實現了 Runnable 介面,內部持有一個 Thread 變數,一個 firstTask,及 completedTasks 三個成員變數。
基於 AQS 的 acquire()、tryAcquire() 實現了 lock()、tryLock() 方法,類上也有註釋,該鎖主要是用來維護執行中執行緒的中斷狀態。在 runWorker() 方法中以及剛說的 interruptIdleWorkers() 方法中用到了。
面試官:這個維護執行中執行緒的中斷狀態怎麼理解呢?
protected boolean tryAcquire(int unused) {
if (compareAndSetState(0, 1)) {
setExclusiveOwnerThread(Thread.currentThread());
return true;
}
return false;
}
public void lock() { acquire(1); }
public boolean tryLock() { return tryAcquire(1); }
在runWorker() 方法中獲取到任務開始執行前,需要先呼叫 w.lock() 方法,lock() 方法會呼叫 tryAcquire() 方法,tryAcquire() 實現了一把非重入鎖,通過 CAS 實現加鎖。
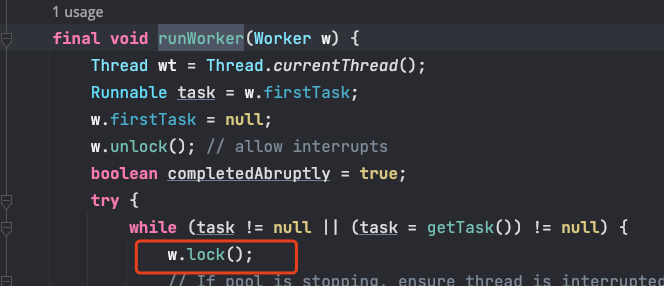
interruptIdleWorkers() 方法會中斷那些等待獲取任務的執行緒,會呼叫 w.tryLock() 方法來加鎖,如果一個執行緒已經在執行任務中,那麼 tryLock() 就獲取鎖失敗,就保證了不能中斷執行中的執行緒了。
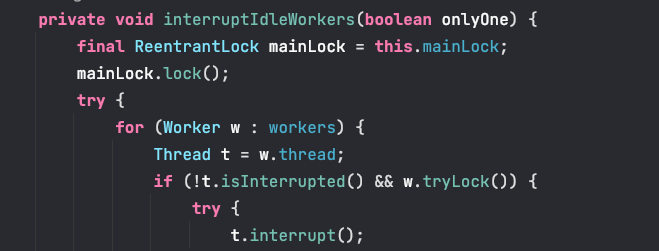
所以 Worker 繼承 AQS 主要就是為了實現了一把非重入鎖,維護執行緒的中斷狀態,保證不能中斷執行中的執行緒。

5. 面試官:你在專案中是怎樣使用執行緒池的?Executors 瞭解嗎?
這裡面試官主要想知道你日常工作中使用執行緒池的姿勢,現在大多數公司都在遵循阿里巴巴 Java 開發規範,該規範裡明確說明不允許使用
Executors 建立執行緒池,而是通過 ThreadPoolExecutor 顯示指定引數去建立
你可以這樣說,知道 Executors 工具類,很久之前有用過,也踩過坑,Executors 建立的執行緒池有發生 OOM 的風險。
Executors.newFixedThreadPool 和 Executors.SingleThreadPool 建立的執行緒池內部使用的是無界(Integer.MAX_VALUE)的 LinkedBlockingQueue 佇列,可能會堆積大量請求,導致 OOM
Executors.newCachedThreadPool 和Executors.scheduledThreadPool 建立的執行緒池最大執行緒數是用的Integer.MAX_VALUE,可能會建立大量執行緒,導致 OOM
自己在日常工作中也有封裝類似的工具類,但是都是記憶體安全的,引數需要自己指定適當的值,也有基於 LinkedBlockingQueue 實現了記憶體安全阻塞佇列 MemorySafeLinkedBlockingQueue,當系統記憶體達到設定的剩餘閾值時,就不在往佇列裡新增任務了,避免發生 OOM
我們一般都是在 Spring 環境中使用執行緒池的,直接使用 JUC 原生 ThreadPoolExecutor 有個問題,Spring 容器關閉的時候可能任務佇列裡的任務還沒處理完,有丟失任務的風險。
我們知道 Spring 中的 Bean 是有生命週期的,如果 Bean 實現了 Spring 相應的生命週期介面(InitializingBean、DisposableBean介面),在 Bean 初始化、容器關閉的時候會呼叫相應的方法來做相應處理。
所以最好不要直接使用 ThreadPoolExecutor 在 Spring 環境中,可以使用 Spring 提供的 ThreadPoolTaskExecutor,或者 DynamicTp 框架提供的 DtpExecutor 執行緒池實現。
也會按業務型別進行執行緒池隔離,各任務執行互不影響,避免共用一個執行緒池,任務執行參差不齊,相互影響,高耗時任務會佔滿執行緒池資源,導致低耗時任務沒機會執行;同時如果任務之間存在父子關係,可能會導致死鎖的發生,進而引發 OOM。
更多使用姿勢參考之前發的文章:

6. 面試官:剛你說到了通過 ThreadPoolExecutor 來建立執行緒池,那核心引數設定多少合適呢?
這個問題該怎麼回答呢?
可能很多人都看到過《Java 並行程式設計事件》這本書裡介紹的一個執行緒數計算公式:
Ncpu = CPU 核數
Ucpu = 目標 CPU 利用率,0 <= Ucpu <= 1
W / C = 等待時間 / 計算時間的比例
要程式跑到 CPU 的目標利用率,需要的執行緒數為:
Nthreads = Ncpu * Ucpu * (1 + W / C)
這公式太偏理論化了,很難實際落地下來,首先很難獲取準確的等待時間和計算時間。再著一個服務中會執行著很多執行緒,比如 Tomcat 有自己的執行緒池、Dubbo 有自己的執行緒池、GC 也有自己的後臺執行緒,我們引入的各種框架、中介軟體都有可能有自己的工作執行緒,這些執行緒都會佔用 CPU 資源,所以通過此公式計算出來的誤差一定很大。
所以說怎麼確定執行緒池大小呢?
其實沒有固定答案,需要通過壓測不斷的動態調整執行緒池引數,觀察 CPU 利用率、系統負載、GC、記憶體、RT、吞吐量 等各種綜合指標資料,來找到一個相對比較合理的值。
所以不要再問設定多少執行緒合適了,這個問題沒有標準答案,需要結合業務場景,設定一系列資料指標,排除可能的干擾因素,注意鏈路依賴(比如連線池限制、三方介面限流),然後通過不斷動態調整執行緒數,測試找到一個相對合適的值。

7. 面試官:你們執行緒池是咋監控的?
因為執行緒池的執行相對而言是個黑盒,它的執行我們感知不到,該問題主要考察怎麼感知執行緒池的執行情況。
可以這樣回答:
我們自己對執行緒池 ThreadPoolExecutor 做了一些增強,做了一個執行緒池管理框架。主要功能有監控告警、動態調參。主要利用了 ThreadPoolExecutor 類提供的一些 set、get方法以及一些勾點函數。
動態調參是基於設定中心實現的,核心引數設定在設定中心,可以隨時調整、實時生效,利用了執行緒池提供的 set 方法。
監控,主要就是利用執行緒池提供的一些 get 方法來獲取一些指標資料,然後採集資料上報到監控系統進行大盤展示。也提供了 Endpoint 實時檢視執行緒池指標資料。
同時定義了5中告警規則。
執行緒池活躍度告警。活躍度 = activeCount / maximumPoolSize,當活躍度達到設定的閾值時,會進行事前告警。
佇列容量告警。容量使用率 = queueSize / queueCapacity,當佇列容量達到設定的閾值時,會進行事前告警。
拒絕策略告警。當觸發拒絕策略時,會進行告警。
任務執行超時告警。重寫 ThreadPoolExecutor 的 afterExecute() 和 beforeExecute(),根據當前時間和開始時間的差值算出任務執行時長,超過設定的閾值會觸發告警。
任務排隊超時告警。重寫 ThreadPoolExecutor 的 beforeExecute(),記錄提交任務時時間,根據當前時間和提交時間的差值算出任務排隊時長,超過設定的閾值會觸發告警
通過監控+告警可以讓我們及時感知到我們業務執行緒池的執行負載情況,第一時間做出調整,防止事故的發生。

8. 面試官:你在使用執行緒池的過程中遇到過哪些坑或者需要注意的地方?
這個問題其實也是在考察你對一些細節的掌握程度,就全甩鍋給年輕剛畢業沒經驗的自己就行。可以適當多說些,也證明自己對執行緒池有著豐富的使用經驗。
1)OOM 問題。剛開始使用執行緒都是通過 Executors 建立的,前面說了,這種方式建立的執行緒池會有發生 OOM 的風險。
2)任務執行異常丟失問題。可以通過下述4種方式解決
在任務程式碼中增加 try、catch 例外處理
如果使用的 Future 方式,則可通過 Future 物件的 get 方法接收丟擲的異常
為工作執行緒設定 setUncaughtExceptionHandler,在 uncaughtException 方法中處理異常
可以重寫 afterExecute(Runnable r, Throwable t) 方法,拿到異常 t
3)共用執行緒池問題。整個服務共用一個全域性執行緒池,導致任務相互影響,耗時長的任務佔滿資源,短耗時任務得不到執行。同時父子執行緒間會導致死鎖的發生,今兒導致 OOM
4)跟 ThreadLocal 配合使用,導致髒資料問題。我們知道 Tomcat 利用執行緒池來處理收到的請求,會複用執行緒,如果我們程式碼中用到了 ThreadLocal,在請求處理完後沒有去 remove,那每個請求就有可能獲取到之前請求遺留的髒值。
5)ThreadLocal 線上程池場景下會失效,可以考慮用阿里開源的 Ttl 來解決
以上提到的執行緒池動態調參、通知告警在開源動態執行緒池專案 DynamicTp 中已經實現了,可以直接引入到自己專案中使用。
關於 DynamicTp
DynamicTp 是一個基於設定中心實現的輕量級動態執行緒池管理工具,主要功能可以總結為動態調參、通知報警、執行監控、三方包執行緒池管理等幾大類。

經過多個版本迭代,目前最新版本 v1.0.8 具有以下特性
特性 ✅
-
程式碼零侵入:所有設定都放在設定中心,對業務程式碼零侵入
-
輕量簡單:基於 springboot 實現,引入 starter,接入只需簡單4步就可完成,順利3分鐘搞定
-
高可延伸:框架核心功能都提供 SPI 介面供使用者自定義個性化實現(設定中心、組態檔解析、通知告警、監控資料採集、任務包裝等等)
-
線上大規模應用:參考美團執行緒池實踐,美團內部已經有該理論成熟的應用經驗
-
多平臺通知報警:提供多種報警維度(設定變更通知、活性報警、容量閾值報警、拒絕觸發報警、任務執行或等待超時報警),已支援企業微信、釘釘、飛書報警,同時提供 SPI 介面可自定義擴充套件實現
-
監控:定時採集執行緒池指標資料,支援通過 MicroMeter、JsonLog 紀錄檔輸出、Endpoint 三種方式,可通過 SPI 介面自定義擴充套件實現
-
任務增強:提供任務包裝功能,實現TaskWrapper介面即可,如 MdcTaskWrapper、TtlTaskWrapper、SwTraceTaskWrapper,可以支援執行緒池上下文資訊傳遞
-
相容性:JUC 普通執行緒池和 Spring 中的 ThreadPoolTaskExecutor 也可以被框架監控,@Bean 定義時加 @DynamicTp 註解即可
-
可靠性:框架提供的執行緒池實現 Spring 生命週期方法,可以在 Spring 容器關閉前儘可能多的處理佇列中的任務
-
多模式:參考Tomcat執行緒池提供了 IO 密集型場景使用的 EagerDtpExecutor 執行緒池
-
支援多設定中心:基於主流設定中心實現執行緒池引數動態調整,實時生效,已支援 Nacos、Apollo、Zookeeper、Consul、Etcd,同時也提供 SPI 介面可自定義擴充套件實現
-
中介軟體執行緒池管理:整合管理常用第三方元件的執行緒池,已整合Tomcat、Jetty、Undertow、Dubbo、RocketMq、Hystrix等元件的執行緒池管理(調參、監控報警)
專案地址
目前累計 1.7k star,感謝你的 star,歡迎 pr,業務之餘一起給開源貢獻一份力量
gitee地址:https://gitee.com/dromara/dynamic-tp
github地址:https://github.com/dromara/dynamic-tp