Go語言知識查漏補缺|基本資料型別
前言
學習Go半年之後,我決定重新開始閱讀《The Go Programing Language》,對書中涉及重點進行全面講解,這是Go語言知識查漏補缺系列的文章第二篇,前一篇文章則對應書中一二兩章。
我也開源了一個Go語言的學習倉庫,有需要的同學可以關注,其中將整理往期精彩文章、以及Go相關電子書等資料。
倉庫地址:https://github.com/BaiZe1998/go-learning
第三章、基本資料型別
3.1 整數
負數的%運算
&^(位運運算元:and not),x &^ y = z,y中1的位,則z中對應為0,否則z中對應為x中的位
00100010 &^ 00000110 = 00100000
無符號整數通常不會用於只為了存放非負整數變數,只有當涉及到位運算、特殊的算數運算、hash等需要利用無符號特性的場景下才會去選擇使用
比如陣列下標i用int存放,而不是uint,因為i--使得i == -1時作為判斷遍歷結束的標誌,如果是uint,則0減1則等於2^64-1,而不是-1,無法結束遍歷
注意:int的範圍隨著當前機器決定是32位元還是64位元
var x int32 = 1
var y int16 = 2
var z int = x + y // complie error
var z int = int(x) + int(y) // ok
// 大多數數值型的型別轉換不會改變值的內容,只會改變其型別(編譯器解釋這個變數的方式),但是當整數和浮點數以及大範圍型別與小範圍型別轉換時,可能會丟失精度,或者出現意外的結果
3.2 浮點數
math.MaxFloat32
math.MinFloat32
const x = 6.2222334e30 // 科學計數法
// math包中有很多的使用浮點數的函數,並且fmt包有很多適用於浮點數的格式化輸出,包括保留小數點的具體精度等
float32精度大概6位
float64精度大概15位(更常用,因為單精度計算損失太快)
// 直接用浮點數為返回值結果,再二次用於其他的比較判斷返回結果是否有效,有時會有誤差導致錯誤,推薦額外增加一個bool引數
func compute() (value float64, ok bool) {
if failed {
return 0, false
}
return result, true
}
3.3 複數
var x complex128 = complex(1, 2) // 1+2i
var y complex128 = complex(3, 4) // 3+4i
fmt.Println(x*y) // -5+10i
fmt.Println(real(x*y)) // -5
fmt.Println(imag(x*y)) // 10
// 兩個複數相等當且僅當實部和虛部相當
fmt.Println(cmplx.Sqrt(-1)) // 0+1i
3.4 布林量
bool是if或者for的判斷條件
s != "" && s[0] == 'x' // 當邏輯運運算元左側表示式可以決定操作結果則將放棄執行右側表示式
// &&的優先順序高於||
3.5 字串
string在GO語言中是不可變的量
len獲取的是字串的位元組數目,而不是碼點(UTF-8 Unicode code point)
字串第i個位元組,並不一定是字串的第i個字元,因為UTF-8編碼對於非ASCII的code point需要2個或更多位元組
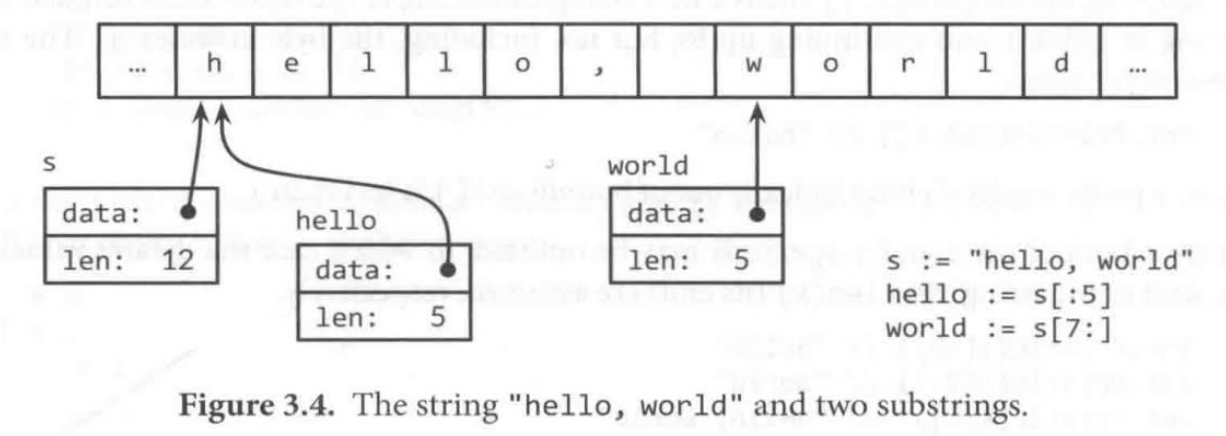
str := "hello, world"
fmt.Println(s[:5]) // hello
fmt.Println(s[7:]) // world
fmt.Println(s[:]) // hello world
s := "left"
t := s
s += " right" // 此時s指向新建立的string 」left right「,而t指向之前的s表示的「left」
a := "x"
b := "x"
a == b // true,且string可以按照字典序比較大小
string是不可變的,意味著同一個string的拷貝可以共用底層的記憶體,使得拷貝變得很輕量,比如s和s[:7]可以安全的共用相同的資料,因此substring操作也很輕量。沒有新的記憶體被分配。
反引號中的字串表示其原生的意思,內容可以多行定義,不支援跳脫字元
func main() {
a := `hello
world
lalala`
fmt.Println(a)
}
Unicode
UTF-8使用碼點描述字元(Unicode code point),在Go中對應術語:rune(GO中使用int32儲存)
可以使用一個int32的序列,來代表rune序列,固定長度帶來了額外的開銷(因為大多數常用字元可以使用16bits描述)
UTF-8
可變長編碼,使用1-4 bytes來代表一個rune,1byte儲存 ASCII ,2 or 3 bytes 儲存大多數常用字元 rune,並且採用高位固定的方式來區分範圍(字首編碼,無二義性,編碼更緊湊)

s := "Hello, 世界"
fmt.Println(len(s)) // 13
fmt.Println(utf8.RuneCountInString(s)) // 9

字串和陣列切片
字串包含了一連串的位元組(byte),建立後不可變。而[]byte內容是可變的
s := "abc"
b := []byte(s) // 分配新的位元組陣列記憶體
s2 : string(b) // 發生記憶體拷貝
為了避免沒有必要的轉換和記憶體分配,bytes包中提供了很多與string包中相同功能的方法,更推薦使用(共用記憶體)
bytes.Buffer用於字元(字串)的累加構造字串操作很方便,高效
// 一些操作Buffer的api
var buf bytes.Buffer
fmt.Fprintf(&buf, "%d", x)
buf.WriteString("abc")
buf.WriteByte('x')
buf.WriteRune(碼點值)
字串和數值型別的轉換
// 整數轉string
x := 123
y := fmt.Sprintf("%d", x)
fmt.Println(y, strconv,Itoa(x)) // "123" "123"
// %b %d %u %x 用於進位制轉換
s := fmt.Sprintf("x=%b", x) // "x=1111011"
// string轉整數
x, err := strconv.Atoi("123")
y, err := strconv.ParseInt("123", 10, 64)// base 10, up to 64 bits,第三個參數列示轉換的整型的範圍為int64
// fmt.Scanf()可以用於讀取混合資料(整型、字元等)
3.6 常數
所有常數的底層都是由:boolean、string、number組成(在編譯時確定,不可變,常數的運算結果依舊是常數)
const a = 2
const b = 2*a // b 在編譯時完成
大多數常數的宣告沒有指定型別,但是也可以指定,沒有型別的常數Go中稱為無型別常數(untyped constant),具體的型別到使用到的時候確定
untyped constant
const a = 10
fmt.Printf("%T\n", a) // int(隱式型別)
var b float64 = 4*a // 在需要的時候,a轉變成了float64
fmt.Printf("%T\n", b) // float64
在預設情況下,untyped constant 不是沒有具體型別,而是隱式轉換成了如下型別,因此上述a的型別可以列印為int
並且untyped constant擁有更高的精度,可以認為至少有 256bit 的運算精度
- untyped boolean
- untyped integer (隱式轉換成 int)
- untyped rune (隱式轉換成 int32)
- untyped floaing-point (隱式轉換成 float64)
- untyped complex (隱匿轉換成 complex128)
- untyped string
常數生成器
可以參與計算且擁有增長屬性
type Flags uint
const (
a = 1 << iota // 1
b // 2
c // 4
d // 8
)
const (
_ = 1 << (10 * iota)
KiB // 2^10
MiB // 2^20
GiB // 2^30
TiB //
PiB //
EiB //
ZiB // 2^70
...
)