Javascript之非同步迴圈列印這道小題
這道題,我相信很多前端從業者都知道,它本質上來說並不複雜,但是卻可以有很深遠的擴充套件,最終核心的主題其實就是非同步的遍歷,其中對於題目的初級解法,還涉及到一些作用域的知識。那麼我們以最容易理解的解法入手,逐步深入,一點點的剖開這道題所涉及到的知識概念和體系。
我們先來看這道題:
for (var i = 0; i < 6; i++) { setTimeout(() => { console.log(i); }, 1000); }
這個結果想必大家都能很快的說出來,這段程式碼會在重新整理頁面一秒後一次性的列印6次6。這是為啥呢?我們來分析下這段程式碼的實際執行順序:
var i; for (i = 0; i < 6; i++) {} setTimeout(() => { console.log(i); }, 1000); setTimeout(() => { console.log(i); }, 1000); setTimeout(() => { console.log(i); }, 1000); setTimeout(() => { console.log(i); }, 1000); setTimeout(() => { console.log(i); }, 1000); setTimeout(() => { console.log(i); }, 1000);
我們看,其實這段程式碼可以這樣來理解,setTimeout並不是按照我們所想的那樣,在迴圈的內部依次執行的,原因在於setTimeout是一個非同步回撥的宏任務,他會在執行到該程式碼的時候,把傳入setTimeout的回撥函數及引數資訊存在一個延遲佇列中,並不是訊息佇列噢,是延遲佇列。當延遲佇列發現,誒?時間到了,就會把延遲佇列中的回撥函數包裝成事件插入到訊息佇列中,如果此時訊息佇列中沒有其他待執行的任務在前面,那麼就會立即執行該延遲事件。
所以由於非同步回撥的原因,導致了setTimeout中的回撥函數並不是在for迴圈體內部執行的,而是等待for迴圈執行結束之後,並且執行完迴圈體邏輯後又i++了一次,等待延遲一秒後,才一次性的執行了6次setTimeout中的回撥。
一秒後,6次6。一秒的延遲是因為我們每次迴圈,新增的到延遲佇列中的事件所包含的資訊就是延遲一秒,因為沒有順序執行,所以並不會出現每次迴圈執行一次,就導致了這樣的情況。而6次,則是因為迴圈體迴圈了6次,從0到5,一共6次。而列印出6則是因為在i = 5的最後一次迴圈執行完迴圈體後,還執行了i++,然後setTimeout中非同步回撥所存取的i是全域性作用域下的i,於是i在執行非同步回撥的時候就是6了。
好啦,我相信大家已經知道為什麼這樣寫程式碼與我們的預期不符。那,要怎麼樣才能符合我們的預期呢?那麼在這裡確定一下,我們的預期是:每隔一秒,列印一次對應的數位。也就是第一秒列印0,第二秒列印1,這樣子。
一、部分解決方案之IIFE
第一種不完全的解決方案就是利用IIFE的特性,形成了一個閉包,我們來看程式碼:
for (var i = 0; i < 6; i++) { (function (j) { setTimeout(() => { console.log(j); }, 1000); })(i); }
我們用一個匿名立即執行函數來包裹整個非同步的setTimeout部分,然後把迴圈中的i作為匿名函數的引數傳入,列印的就是這個傳入的引數即可。這樣,我們就可以在控制檯看到順序列印的0~5,但是還有個問題沒有解決,我們看到0到5是在一秒之後,一下子列印出來的,每隔一秒的需求還是沒有做到。
每秒的事情我們稍後再說,我們先分析下為什麼用立即執行函數就能解決順序列印的問題,為什麼用立即執行函數就不再是6個6了呢?其實問題得到解決的根本原因在於區域性作用域與全域性作用域。函數會產生一個區域性的作用域,當我們使用立即執行函數包裹非同步時,非同步回撥所取的j其實是立即執行函數所傳入的引數i,當立即執行函數執行的時候,會產生一個執行上下文棧幀加入到執行上下文棧的棧頂,而每一個棧幀中會儲存一些上下文資訊。這些上下文資訊中包含了很多東西,比如arguments、比如變數環境、詞法環境、this,作用域指標等等,這裡不再展開,有興趣可以去學習下執行上下文棧。
那麼我們來分析下上面的程式碼是怎麼執行的,每一次迴圈的時候,都會執行立即執行函數,立即執行函數會形成一個棧幀插入到棧頂,那麼在執行到立即執行函數中的非同步回撥setTimeout的時候,會在延遲佇列中新增一個回撥函數,這個回撥函數要去取j,而執行上下文棧中對應的棧幀有這個arguments引數j,所以回撥函數取到的j就是對應迴圈的i。當函數執行完畢,棧幀出棧,下一次迴圈再執行類似的步驟,入棧,執行程式碼讀取棧中的arguments的j,出棧。
那麼,核心的點來了,作用域是真的,執行上下文也是真的,但是在立即函數執行完畢,把setTimeout的回撥加入到延遲佇列中後,執行上文對應的棧幀已經出棧了,我從哪取到的j呢?答案就是閉包,不信你看:
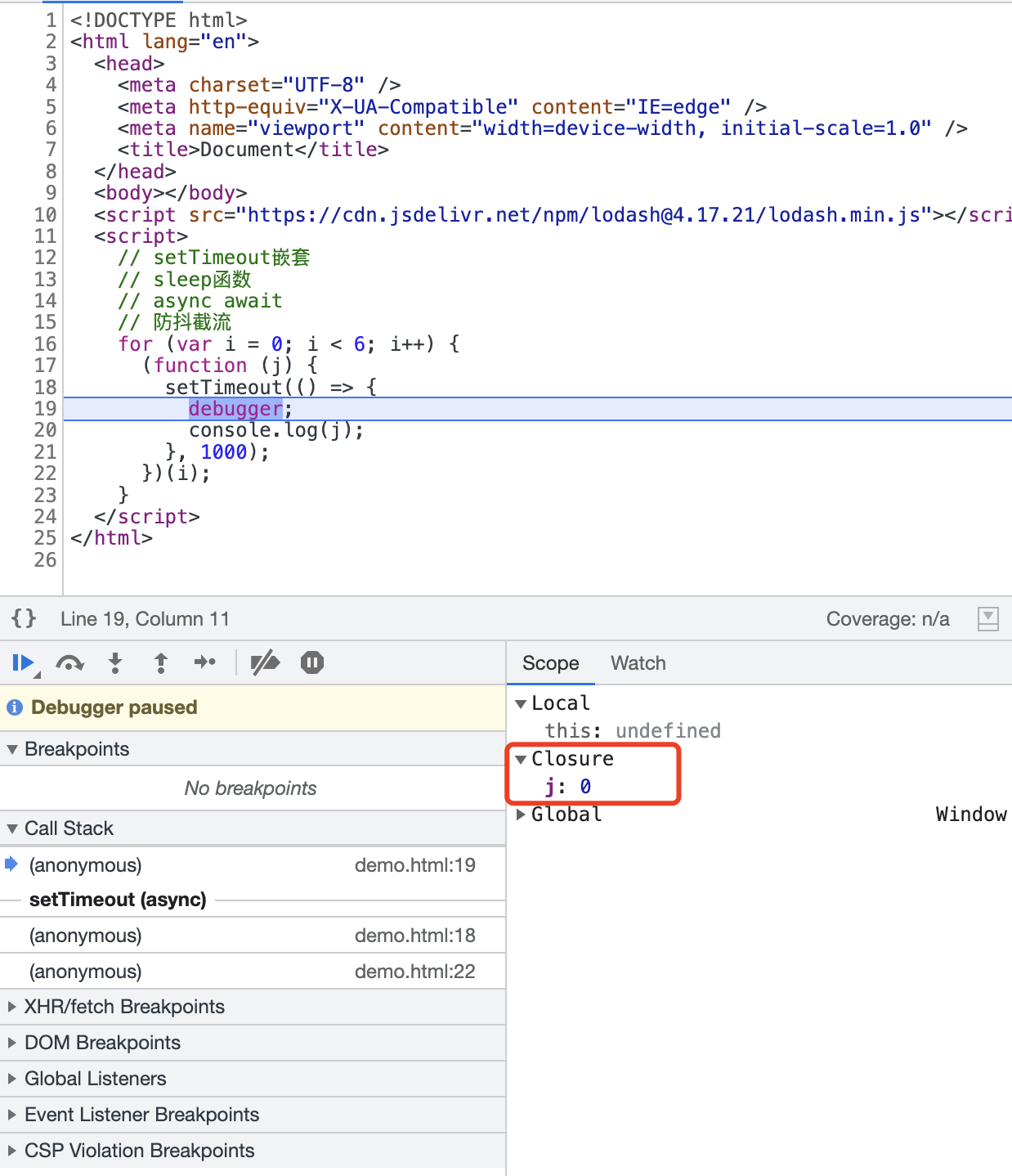
大家看到這裡有個Closure,就是延遲佇列中儲存的事件觸發執行時所取到的j。在上面的程式碼中,每一個延遲佇列中的回撥函數的作用域都會繫結一個閉包,從而取到了j。
Ok,我們現在解決了順序列印的問題,但是每秒列印的問題還沒解決。在這樣的程式碼情況下,有一種解決辦法:
for (var i = 0; i < 6; i++) { (function (j) { setTimeout(() => { console.log(j); }, 1000 * (i + 1)); })(i); }
我們在每次迴圈的時候,讓每次加入延遲佇列中的回撥事件的時間按照迴圈次數來遞增,但是實際上,這樣看起來解決了問題,但是卻並不是我們想要解決的方式,其實我們希望的執行方式是:每次迴圈都會在一秒後執行列印。換句話說,希望非同步可以像同步那樣的執行。誒?你是不是想到了什麼?嗯~~我們先看別的解決方案。
二、部分解決方案之塊級作用域
通過IIFE來解決列印順序的問題,其實是利用了函數作用域棧中儲存的資訊搞定的。那麼我們還有另外一種生成一個作用域的方式,就是塊級作用域:
for (let i = 0; i < 6; i++) { setTimeout(() => { console.log(i); }, 1000); }
那麼我們直接看解決每秒列印的問題,其實方法跟IIFE的時候一樣,加秒唄:
for (let i = 0; i < 6; i++) { setTimeout(() => { console.log(i); }, 1000 * (i + 1)); }
其實塊級作用域也好,函數作用域也罷,其核心原理幾乎都是一致的,就是通過作用域來儲存對應的變數,當非同步回撥加入到延遲佇列的時候,取的是對應作用域的值,而不是全域性作用域。
而塊級作用域,實際上是把變數資訊儲存在了執行上下文棧幀中的詞法環境中的,但是這裡,注意這裡,在執行上下文棧中僅僅只有一個全域性的根棧幀,每一次迴圈都會繫結詞法環境中的變數i,就有點像閉包一樣。所以,在非同步回撥加入到延遲佇列的時候,就會去詞法環境中取到對應的i變數。
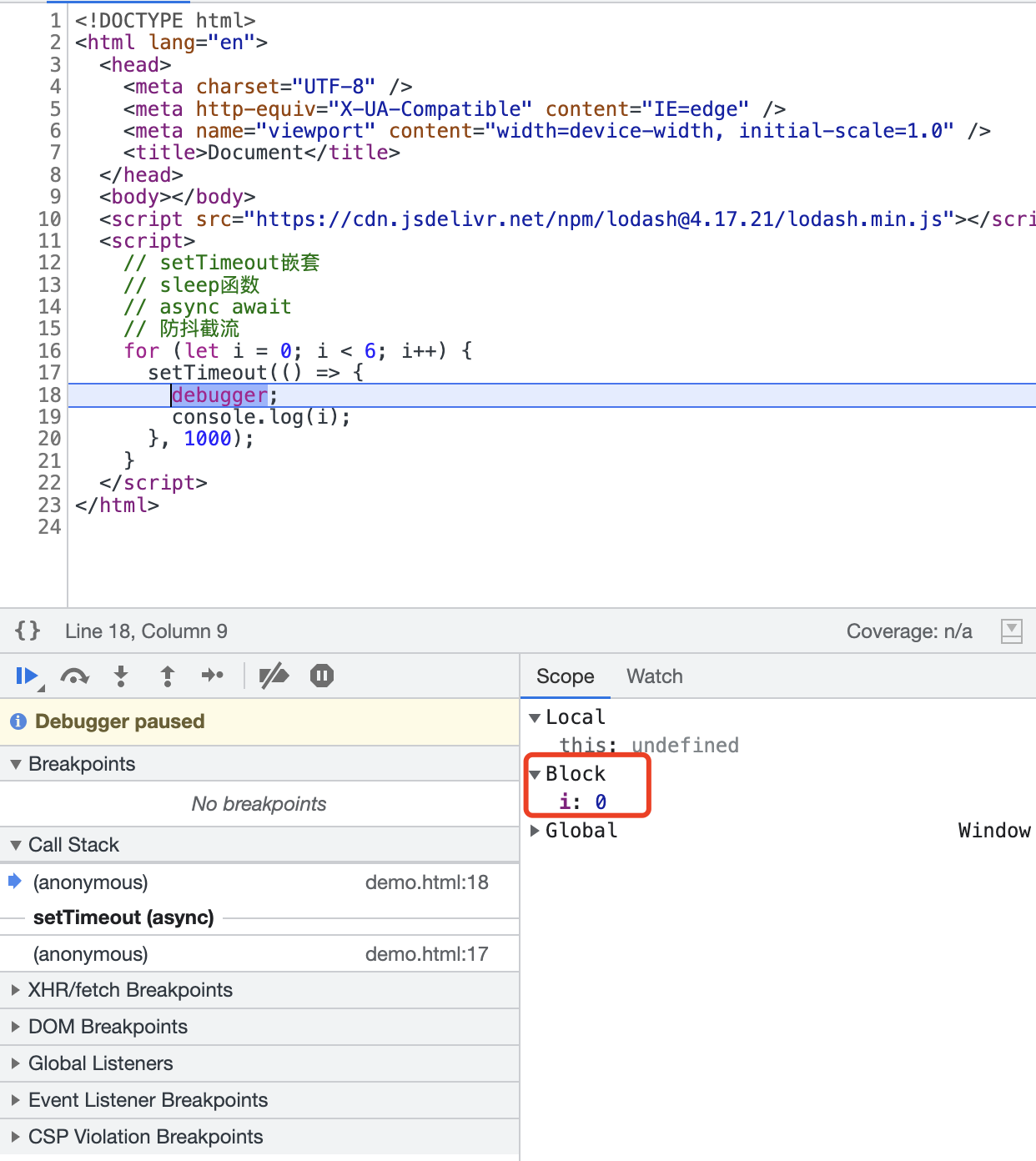
我們可以通過debugger看到,這裡不再是Closure,而是Block,也就是塊級作用域。
那麼我們來簡單分析下上面的程式碼是如何執行的:每次迴圈都會生成一個新的塊級作用域,當setTimeout把非同步回撥函數加入到延遲佇列中時,會在其所依賴的上下文中儲存非同步回撥中使用到的變數i。這裡核心的點就是,加入延遲佇列中的非同步回撥,已經有了所需要的對應的資料資訊。
三、部分解決方案之setTimeout的第三個引數
還有一種解決方案,就是利用setTimeout的第三個引數,既然如此,我們就得先來了解下setTimeout的引數都有哪些:
var timeoutID = scope.setTimeout(function[, delay, arg1, arg2, ...]); var timeoutID = scope.setTimeout(function[, delay]); var timeoutID = scope.setTimeout(code[, delay]);
我們可以看到,setTimeout的第一個引數可以是一個函數,或者一段可執行的程式碼:
for (var i = 0; i < 6; i++) { setTimeout(console.log(i), 1000); }
這樣寫也沒啥問題。但是並不推薦這樣寫,因為瀏覽器會像執行eval包裹的可執行字串那樣來執行這段程式碼,所以我們其實很少這麼使用,第二個引數不用說,就是我們需要延遲執行的時間,誒?setTimeout不僅有第三個引數,還有第四五六七八九十個引數,換句話說,setTimeout的從第三個引數開始,後面可以加任意個引數,這些引數是可選的附加引數,一旦定時器到期,它們會作為引數傳遞給第一個引數的function。
注意!一旦定時器到期,就會把它們作為引數傳遞給function。那我們先試一下:
for (var i = 0; i < 6; i++) { setTimeout( (j) => { console.log(j); }, 1000, i ); }
這樣也行,一點問題沒有,也是隔了一秒,一下子都按順序列印出來了。但是它的原理是咋回事呢?看起來好像跟前兩種解決方案類似,都是每一個非同步回撥在加入到延遲佇列中,觸發執行的時候去某個地方取到了對應的資料。我們還是debugger一下來看看:
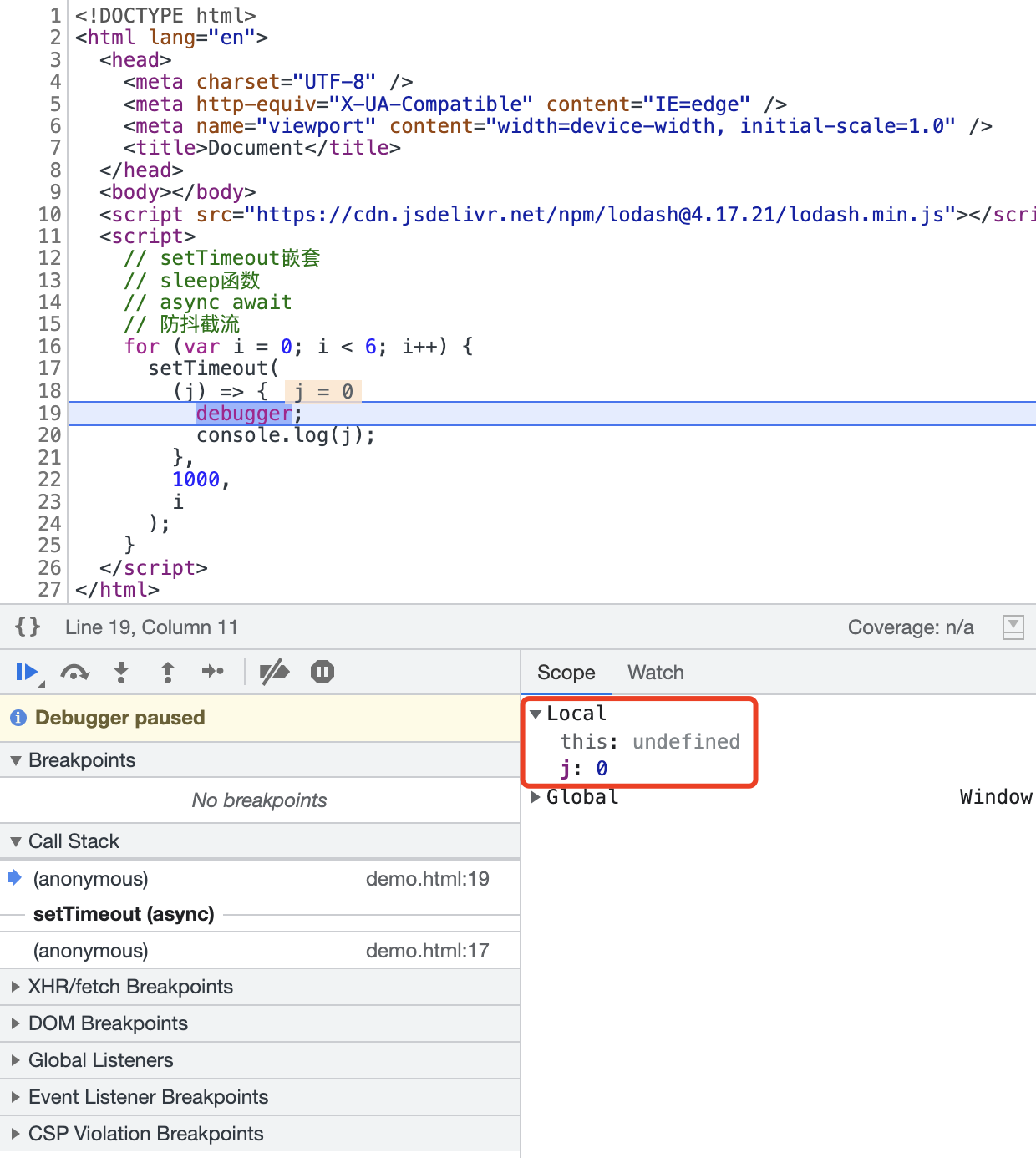
我們看setTimeout的第三個引數,所儲存的位置跟前面兩種解決方案完全不同,它存在了Local裡,也就是自己的區域性作用域。至於這種情況的秒數問題我就不寫了吧。好吧~
四、部分解決方案總結
OK,那我們先來總結下這三種場景的解決方案,這三種解決方案都是利用了語言的特性在不同的記憶體位置儲存對應的資料,但是本質上來說並沒有解決核心的需求,也就是我們之前說過的,希望非同步像同步那樣來執行。僅僅只是解決了順序列印的問題,既然我想要順序列印,不考慮每隔一秒的話,那我這樣不就行了:
for (var i = 0; i < 6; i++) { console.log(i); }
那非要非同步隔一秒的話就這樣:
setTimeout(function () { for (var i = 0; i < 6; i++) { console.log(i); } }, 1000);
這不是更好?你扯那些臭氧層有啥用。所以從根本上講,以上三種方法,都算不上是解決方案,只是不得已可以實現的手段罷了。
但是我還有個問題,就是閉包也好、塊級作用域也罷,它們是如何查詢到對應的要列印的那個j的呢?首先,作用域是在函數宣告時就已經確定好的,儲存在執行函數的執行上下文棧幀中的。其次,閉包則像是某一個函數的揹包,在它自己的執行上下文棧幀中找不到的時候,就會去閉包中找。最後,setTimeout的第三個引數會作為function的引數,則是儲存在了執行上下文的aguments中,aguments也是在執行上下文的棧幀裡。你知道我說的這幾種情況對應的以上哪種解決方案的吧?
五、破壞性解決方案之遞迴巢狀
破壞性解決方案,什麼意思呢?就是與本篇開頭的那段程式碼無論在形式上還是程式碼的編寫上,都可能會脫離原貌甚至是完全不同,但是卻可以實現我們真正的目的:每隔一秒順序列印。換句話說,我們完全拋棄迴圈內非同步的形式,只要能實現每隔一秒順序列印即可。那麼我們的目的也就變成了如何實現每隔一秒順序列印的問題。
那麼我們先看第一種解決方案,通過回撥的方式,來試試。
setTimeout(() => { console.log(0); setTimeout(() => { console.log(1); setTimeout(() => { console.log(2); setTimeout(() => { console.log(3); setTimeout(() => { console.log(4); setTimeout(() => { console.log(5); }, 1000); }, 1000); }, 1000); }, 1000); }, 1000); }, 1000);
這程式碼是不是很好看,從形式上如此的美妙,勻稱,從邏輯上如此的清晰、易懂。完美的實現了我們的需求。我相信你看到這肯定會笑出聲,嗯~我也一樣。哈哈哈哈哈。
雖然你笑出了聲,但是我還是要嚴肅的解釋下上面的程式碼。嗯~~就是非同步回撥裡巢狀非同步回撥,這樣子其實每一次都在延遲佇列中加入了一個事件,當時間到了執行函數的時候就又加進去了一個,如此往復。
這程式碼雖然好看,並且清晰易懂,但是著實不那麼優雅,我們想辦法怎麼讓上面的程式碼更優雅一點呢?
function run(num) { if (num > 5) return; setTimeout(() => { console.log(num); run((num += 1)); }, 1000); } run(0);
其實這程式碼也很好理解,跟我們上面的巢狀的方式沒有任何區別,無非就是遞迴罷了,在每一次run方法執行的setTimeout中再呼叫run方法,遞迴的終點就是num > 5的時候,所以如果強硬的類比一下,遞迴就是迴圈的另外一種形式罷了。這個玩意沒啥技術難度。但是確實是一種解決方案。
這裡額外提一句,死迴圈和棧溢位有啥區別?嗯~~死迴圈可能會導致棧溢位,但是棧溢位不一定是因為死迴圈。
首先死迴圈是指程式碼形式,是指你的程式碼一直的執行下去(一直執行就可能會重複的宣告某些變數,佔用記憶體,就算你就是一個空的死迴圈,也會一直佔用執行佇列導致卡死),沒有終點,於是瀏覽器或者宿主環境會根據你的程式碼,在編譯的時候解析到了死迴圈的程式碼並丟擲錯誤。而棧溢位,實際上可能是由於死迴圈導致的執行上下文棧的無限疊加,超出了宿主環境允許的最大棧幀的數量,從而導致的錯誤。
六、破壞性解決方案之促銷秒殺
額~~其實這個標題有點跑題了,但是它看起來很吸睛,讓不懂的人很好奇,懂的人不珍惜,額~~~沒事,我純粹為了押韻。繼續繼續~~
額~~沒辦法,因為標題跑題了,我不得不解釋下促銷秒殺的實現思路大概是什麼樣的。
首先,促銷秒殺意味著在某一個時間段會有遠超平峰時期的並行,會產生一個伺服器請求處理的擁堵,前面收到的資料還沒處理完,後面的馬上又來了。所以,大量資料在短時間內的並行會造成伺服器的崩潰。當然,這種場景也可以有另外一種叫法,比如Dos或者DDos攻擊,稍微擴充套件一下,大家知道即可。
其次,要解決這樣的場景造成的伺服器阻塞問題,並不僅僅是伺服器中存在,在前端範疇內也是有類似的場景的,比如VueRouter中實現的runQueue方法就是為了解決這樣的問題。那麼解決方案說起來也很簡單,就是我們把所有的請求都放到一個佇列或者也可以說是陣列中,從頭開始呼叫執行陣列中的非同步方法,當非同步結果返回,再去呼叫下一個。
那麼,我們來看下程式碼的實現:
// 一個佇列,我們模擬一下,在佇列中加入了幾個方法。 const queue = []; for (let i = 0; i < 6; i++) { queue.push(function () { return new Promise((resolve, reject) => { setTimeout(() => { console.log(i, new Date()); resolve(i); }, 1000); }); }); } // 執行佇列的方法,主要用來增加步數,也就是遍歷佇列 function runQueue(queue, fn, cb) { const step = (index) => { if (index >= queue.length) { cb(); } else { if (queue[index]) { fn(queue[index], () => { step(index + 1); }); } else { step(index + 1); } } }; step(0); } // 具體的執行邏輯 function run(hook, next) { hook().then((val) => { next(val); }); } // 啟動 runQueue(queue, run, () => { setTimeout(() => { console.log("finally", new Date()); }, 1000); });
我們來看上面完整的程式碼,其實核心的runQueue方法是從VueRouter的原始碼抄過來的,嘿嘿。
首先,們虛擬了一個queue陣列,這個陣列用來儲存所有的非同步方法,我們用Promise包裹了一下,最終會返回這個Promise。Promise內部就是一個一秒之後列印i和當前時間的setTimeout用來模擬ajax請求,或者其他非同步邏輯。
接下來重點來了,就是這個runQueue方法,它接收一個queue作為要執行佇列的資料列表,fn則是作為執行器,執行每一個queue中的事件,cb呢就是回撥,當queue清空了之後會執行這個回撥。runQueue方法的核心是一個step,step內部則其實很簡單,判斷傳入的index,如果大於queue的長度,說明整個queue都執行完畢,則執行回撥。否則,那麼則繼續執行fn執行器來執事件,其第二個引數則是開始下一次執行。
接下來就是執行器方法,也就是runQueue的第二個引數要接收的方法,很簡單,就是呼叫事件,並且在確定有了結果之後執行next,也就是step。
最後,我們執行runQueue方法,傳入queue,run,以及最後的cb,啊~~這裡的cb我為了好看,也延遲了一秒,無所謂,你在本章的場景下,不寫也行。
我們好好看看上面的程式碼,並不複雜,其實它的本質跟我們上一部分的巢狀來說沒什麼區別,只不過不是setTimeout單純的巢狀,而是通過Promise的鏈式呼叫巢狀。只不過我們在執行的過程中加入了步數和回撥,來讓我們可以更細節的操作整個佇列執行的過程,為啥要更細節的操作整個執行過程呢?因為針對複雜場景,很多地方都需要更加細膩的處理。當然,在本章的場景下,其實我們可以簡化下上面的程式碼:
const step = (index) => { if (index > queue.length) return false; if (queue[index]) { queue[index]().then(() => { step(index + 1); }); } else { step(index + 1); } }; step(0);
看到沒,其實就一個step方法……其實就是通過Promise的鏈式呼叫的能力,在then的時候執行下一個事件,當然也可以不用then,也可以用finally,讓巢狀看起來好看了些。這程式碼就很好理解了吧~~
七、破壞性解決方案之Generator
generator是什麼,有什麼,怎麼做,我不會說的很詳細,這不是本篇文章的重點。如果你不清楚generator的作用和效果,為避免不分輕重我會盡可能簡短的介紹清楚,但是如果我沒說清楚,或者你還是沒理解,請一定參考:generator函數的語法和generator的非同步應用以及Iterator。
generator可以理解為一個狀態機,它的內部會使用yield表示式產出狀態,我們可以這樣來建立一個Generator函數,通過執行Generator函數,會返回一個遍歷器物件,也就是Iterator物件:
function* gen() { yield console.log("hello"); yield console.log("zaking"); } var genItem = gen(); genItem.next(); genItem.next(); console.log(genItem.next());
我們通過funciton*來宣告一個Generator函數,內部有兩個狀態,這兩個狀態是一個console語句。然後我們通過執行gen這個Generator函數後,得到了genItem這個Iterator遍歷器物件,然後就可以通過呼叫遍歷器物件的next來獲取到Generator函數內部的狀態,當遍歷結束後,再執行genItem.next()則會得到擁有value和done欄位的物件,此時的done是true,來標識遍歷結束。當然,這只是同步執行前提下的Generator函數,比較好理解。
由於 Generator 函數返回的遍歷器物件,只有呼叫next方法才會遍歷下一個內部狀態,所以其實提供了一種可以暫停執行的函數。yield表示式就是暫停標誌。我們還可以把上面的程式碼寫的豐富一點,便於理解:
function* gen() { console.log("1"); yield "hello"; console.log("2"); yield "zaking"; console.log("3"); } var genItem = gen();
console.log(genItem.next());
這樣會列印出:

但是假設你不執行genItem.next()則不會列印任何內容也就是不會執行任何程式碼,換句話說,通過Generator生成的物件,只有呼叫該物件的next方法才會執行,直到在函數內部遇到yield則會暫停,會返回yield後面的內容到函數外部。再一次執行genItem.next():

最後一次執行genItem.next():

這樣,則整個Generator函數執行完畢,你看,我們有兩個yield,但是其實要三次next()方法的呼叫才能真正的執行完整個Generator函數,那我要想知道什麼時候結束了,只能通過判斷呼叫next()返回的物件的done來確定。
以上都是同步執行,非同步執行怎麼辦呢?其實看起來也並不複雜:
function* gen() { yield setTimeout(function () { console.log(1, new Date()); }, 1000); yield setTimeout(function () { console.log(2, new Date()); }, 1000); } var g = gen(); g.next(); g.next();
上面的程式碼列印出來是這樣的,隔了一秒,然後:

換句話說,這並不是我們想要的,這樣只是解決了順序列印的問題,但是並沒有解決每隔一秒的問題。要解決這個問題,我們得先考慮一個問題,就是當我們使用Generator來執行非同步操作的時候,我怎麼能知道什麼時候交回執行權呢?只有非同步執行有了結果的時候,才需要交回執行權,但是我們又不知道什麼時候非同步才會有結果,答案是只有回撥才能知道。所以,針對同步執行的Generator函數,for…of遍歷即可,因為Generator會返回一個Iterator物件,但是針對非同步操作,for…of肯定是不行的。
一)Thunk函數
Thunk函數最初的定義其實是用來替換某個表示式,但是在Javascript中Thunk函數的定義則有些不同,Thunk 函數替換的不是表示式,而是多引數函數,將其替換成一個只接受回撥函數作為引數的單引數函數。比如這樣:
function readFile(filename, callback) { console.log(filename); setTimeout(function () { callback(); }, 1000); } function Thunk(filename) { return function (cb) { return readFile(filename, cb); }; } var readFileThunk = Thunk("filename"); readFileThunk(function () { console.log("ayayay"); });
其實程式碼理解起來並不複雜,我們寫了一個假的readFile方法,接收兩個引數,一個filename和一個callback。當我們呼叫的時候會立即列印filename欄位並且一秒後執行callback。然後我們的Thunk函數,其實也很簡單,就是通過一個先接收一個filename,然後再返回一個直接收一個cb引數的函數,這個函數內部通過閉包拿到filename並傳入readFIle。然後,我們通過Thunk函數率先傳入filename生成一個只接受回撥函數作為引數的readFileThunk函數。
理論上講,任何函數,只要有回撥函數,就可以寫成Thunk函數的形式,那麼我們可以提煉出一個通用的Thunk函數轉換器:
const Thunk = function (fn) { return function (...args) { return function (callback) { return fn.call(this, ...args, callback); }; }; };
然後,針對上面的程式碼,我們就可以這樣來寫:
function readFile(filename, callback) { console.log(filename); setTimeout(function () { callback(); }, 1000); } const Thunk = function (fn) { return function (...args) { return function (callback) { return fn.call(this, ...args, callback); }; }; }; var readFileThunk = Thunk(readFile); readFileThunk("filename")(function () { console.log("ayayay"); });
當然,我們只是最小化的實現了通用的Thunk函數,生產環境建議可以使用Thunkify模組。誒?你這Thunk函數是不是Currying?柯里化?嗯~~我覺得是,但是就不再擴充套件了。如果這樣跑題下去,就沒邊了。
那Thunk函數有啥用呢?前面稍微說過,同步執行的Generator函數可以用for…of遍歷,但是非同步執行的Generator就需要用到Thunk函數了。我們先來看一段程式碼:
function readFile(filename, callback) { setTimeout(function () { callback(filename); }, 1000); } const Thunk = function (fn) { return function (...args) { return function (callback) { return fn.call(this, ...args, callback); }; }; }; var readFileThunk = Thunk(readFile);
這段程式碼跟之前的沒有太大的區別,只是稍稍修改了readFile方法把傳入的filename傳給了callback回撥。其他的就一模一樣了,那麼我們接下來看看,通過Thunk函數處理後,我們如何利用Generator來順序執行非同步:
var gen = function* () { let r1 = yield readFileThunk("path--1"); console.log(r1); let r2 = yield readFileThunk("path--2"); console.log(r2); }; var g = gen(); var r1 = g.next(); r1.value(function (data) { let r2 = g.next(data); r2.value(function (data) { g.next(data); }); });
我們看,首先建立了一個Generator函數gen,然後這個函數內部呼叫了兩次readFileThunk並傳入了filename引數,然後列印結果,然後再來一次。重點在下面的程式碼,首先我們生成遍歷器範例後,通過執行g.next(),此時相當於返回了第一個yield後面的readFileThunk,經過Thunk函數處理,我們只需要傳入回撥函數就可以了。再詳細一點,當我們執行了第一個next的時候,相當於我們把協程切換到Generator內部,轉移執行權。當Generator函數內部執行到yield的的時候,會返回yield後面的內容並把執行權移交給主協程。然後,我們執行r1.value並傳入回撥函數,再通過呼叫next,把回撥函數的引數傳遞給next,此時主協程把執行權交給Generator協程,此時拿到的r1結果並列印,然後遇到第二個yield,再執行上面的步驟。
整個程式碼執行的過程可以這樣理解:當執行next的時候,把程式碼的執行權交給了Generator函數,當執行yield的時候,就把執行權交給了主協程。通過yield和next的引數來實現兩個協程的資料傳遞。最後,再通過Thunk函數直接暴露了回撥函數,可以讓我們在協程外部來執行回撥函數,回撥函數內部去移交執行權。
到現在為止,我們實現了手動呼叫,來移交執行權,讓整個Generator非同步遍歷器可以執行下去,但是如果非同步很多,我們這樣寫下去,你看像不像回撥地獄?哈哈哈哈~沒錯,哪怕是Generator,要想確定非同步返回了結果再往後執行,本質也是通過回撥實現的。
二)基於Thunk函數的自動執行
我們直接上程式碼吧,這個程式碼你應該略微比較熟悉:
function run(fn) { var gen = fn(); function next(data) { var result = gen.next(data); if (result.done) return; result.value(next); } next(); }
這個run函數,傳入的是一個Generator函數。run函數內部則宣告了一個next方法,其實這個next就是回撥,第一次執行next實際上就是啟動,然後執行gen.next,判斷Generator的狀態,再執行result.value。就是遞迴啦~
那麼,還是上面的例子,我們就可以這樣寫,完整的程式碼如下:
function readFile(filename, callback) { setTimeout(function () { callback(filename); }, 1000); } const Thunk = function (fn) { return function (...args) { return function (callback) { return fn.call(this, ...args, callback); }; }; }; var readFileThunk = Thunk(readFile); var gen = function* () { let r1 = yield readFileThunk("path--1"); console.log(r1); let r2 = yield readFileThunk("path--2"); console.log(r2); }; function run(fn) { var gen = fn(); function next(data) { var result = gen.next(data); if (result.done) return; result.value(next); } next(); } run(gen);
所以你看,其實自動執行也不復雜。咱們之前在第六小節做的秒殺的那個解決方案,實際上就是這個思路。那麼這只是我們為了實現本篇文章的目的所做的比較簡單的run方法,生產環境其實可以co模組,這個就不多說了。
三)基於Promise的自動執行
上面的解決方案是基於回撥函數的,還有一種解決方案是基於Promise的,額,其實就是回撥函數的另外一種寫法麼。我們來看看基於Promise的要怎麼寫。其實有了前面的基礎,寫出Promise的例子就很簡單了。那麼我們先改造下readFile:
function readFile(filename) { return new Promise(function (resolve, reject) { setTimeout(function () { resolve(filename); }, 1000); }); }
嗯~就是callback沒了,換成了Promise。簡單吧?繼續,我們的gen方法沒有變化:
var gen = function* () { let r1 = yield readFile("path--1"); console.log(r1); let r2 = yield readFile("path--2"); console.log(r2); };
然後,我們先來看手動執行:
var g = gen(); g.next().value.then(function (data) { g.next(data).value.then(function (data) { g.next(data); }); });
額,我不知道該咋說了,就是回撥巢狀,變成了鏈式呼叫。
那麼,我們再來看看自動執行:
function run(gen) { var g = gen(); function next(data) { var result = g.next(data); if (result.done) return result.value; result.value.then(function (data) { next(data); }); } next(); } run(gen);
也沒啥,對吧?重複的話我就不說了~~
四)迴歸
前面說了那麼多,實際上已經解決了本篇的核心問題,但是由於是測試程式碼,所以我下面附上回歸本篇問題的範例:
function readFile(filename, callback) { setTimeout(function () { callback(filename); }, 1000); } const Thunk = function (fn) { return function (...args) { return function (callback) { return fn.call(this, ...args, callback); }; }; }; var readFileThunk = Thunk(readFile); var gen = function* () { for (var i = 0; i < 6; i += 1) { var r = yield readFileThunk(i); console.log(r, new Date()); } }; function run(fn) { var gen = fn(); function next(data) { var result = gen.next(data); if (result.done) return; result.value(next); } next(); } run(gen);
我啥也沒改啊,就是改了一下gen函數,你看現在這個gen函數,是不是跟我們寫同步程式碼很像了。至於Promise版本的迴圈非同步列印,嗯~~當作作業了,你自己試下~
但是其實我們做了好多的前置內容才實現了這樣的寫法,這種寫法太煩了,有沒有簡單點的?有!
八、破壞性解決方案之Async
async,async,我相信大家基本上都用過或者瞭解過,但是async是啥?嗯~~async就是Generator的語法糖,它的本質就是Generator。那麼我們看一段熟悉的程式碼:
function readFile(filename, callback) { return new Promise((resolve, reject) => { setTimeout(function () { resolve(filename); }, 1000); }); } var gen = async function () { let r1 = await readFile("path--1"); console.log(r1); let r2 = await readFile("path--2"); console.log(r2); }; gen();
列印的時候,我們看控制檯,確實是每隔一秒列印了一次。你看,我們十分優雅的解決了最開始的問題,至於迴圈列印,我們可以這樣寫(嗯,我把函數名改了):
function callConsole(i) { return new Promise((resolve, reject) => { setTimeout(function () { resolve(i); }, 1000); }); } var run = async function () { for (let i = 0; i < 6; i++) { let r = await callConsole(i); console.log(r, new Date()); } }; run();
試試看結果?
臥槽,完美的解決方案,一目瞭然的程式碼形式,非同步就像同步那樣簡潔明瞭,這就是我們費了這麼多功夫找到的完美的解決方案。
但是還沒完,因為我們之前大量的鋪墊,才能這麼快得出結果。但是~沒錯,還有但是。我們得分析下,async和generator有啥區別呢?我抄一下阮一峰大神的《ECMAScript 6 入門》針對這一點的描述:
- 內建執行器
- 更清晰的語意
- 更廣的適用性
- 返回值是Promise
差不多區別就是這幾點,首先因為擁有了內建執行器,最直觀的感受就是程式碼更簡單,不需要我們引入額外的模組或者程式碼去像執行Generator那樣來執行Async函數,並且返回值是Promise,讓我們可以用then來進行下一步的操作。
其他關於Async函數的部分,大家有興趣可以自己查閱,不多說了噢,說多了總是會跑題的~
九、破壞性解決方案總結
我們簡單回顧一下,關於破壞性解決方案的部分,我們都經歷了哪些過程。
最開始,我們通過setTimeout的非同步回撥,巢狀回撥,最後形成回撥地獄,當上一個非同步有了結果之後,再執行下一個,再執行下一個,直到沒有回撥了就結束了。但是這樣的程式碼實在是有點LowBi,所以我們通過一個簡單的遞迴,讓程式碼更簡潔了些,但是本質也還是回撥地獄。
然後,我們學習了一個概念,就是促銷秒殺,其實促銷秒殺的本質無非就是維護一個佇列,拿到的事件不會直接讓宿主環境執行,而是先放到佇列裡,挨個執行,等到前一個有結果了,再執行下一個,誒?這話怎麼這麼熟悉,嗯~~其實根本上來說,也是回撥,只不過從遞迴換成了迴圈,並且還加入了一點next的概念,以及通過Promise的包裹,在then裡執行next,但是和回撥沒區別。
繼續,我們就學了破壞性解決方案最複雜的、也是最重要的一部分,Generator函數,我們花了很大的篇幅來講Generator,一步一步的帶大家實現了我們最終的目標。
最後,因為在Generator部分大量的鋪墊,引出了本章最重要的也是最終的完美的解決方案async函數,沒錯,能像同步那樣來寫非同步程式碼,終極的解決方案就是async了。但是我還是要強調的是,無論是遞迴、迴圈、Promise、還是Generator、Async,本質上來說,都離不開回撥,沒有回撥,你怎麼知道我執行完了呢?只不過是書寫形式上的變化和一些些原理實現上的不同罷了。
十、其他解決方案之sleep
sleep是什麼?翻譯過來是睡覺。那我發散下思維,在程式中的sleep,我是不是可以理解為讓程式睡了一覺?醒過來再繼續執行任務?嗯~~差不多,其實在Javascript中並沒有sleep的概念,sleep往往是在Java或者Linux中的概念,完整的概念性解釋如下:
Sleep函數可以使計算機程式(程序,任務或執行緒)進入休眠,使其在一段時間內處於非活動狀態。當函數設定的計時器到期,或者接收到訊號、程式發生中斷都會導致程式繼續執行。
那麼在Javascript中,可以通過setTimeout定時器來實現sleep。迴歸到我們本章的主題,既然是用定時器,我是不是可以這樣?停一秒,列印,停一秒,再列印,是不是就實現了我們的目的?那我們首先來實現一個基於Javascript的Sleep函數。
一)、基於Date的Sleep實現
第一種實現方式,其實就是用來計算時間,程式碼是這樣的:
function sleep(time) { var timeStamp = new Date().getTime(); var endTime = timeStamp + time; while (true) { if (new Date().getTime() > endTime) { return; } } }
這塊程式碼很簡單,就是通過死迴圈來佔用執行緒的任務執行,通過計算當前的時間和延遲的時間,得到結束的時間,結束的時間一到,則終止迴圈,這樣就形成了一個Sleep函數,那麼我們就可以非常簡單的寫出迴圈列印的程式碼了:
for (var i = 0; i < 6; i++) { sleep(1000); console.log(i, new Date()); }
很簡單,並且滿足我們的所有要求。但是這種實現直接佔用了執行緒,導致任何程式碼都無法執行,這種方式只是為了實現而實現,沒有任何實際應用的價值。
二)、基於Promise的Sleep實現
Promise的實現也並不複雜:
function sleep(time, i) { return new Promise(function (resolve) { setTimeout(function () { resolve(i); }, time); }); } for (var i = 0; i < 6; i++) { sleep(1000 * i, i).then((i) => { console.log(i, new Date()); }); }
但是這種實現你發現沒有,似乎回到了我們最開始的部分解決方案的那種方式裡,遞增描述並且把i作為引數傳了進去。這樣寫,只是實現了Sleep,但是其實並沒有實現一種優雅的書寫方式解決非同步遍歷的問題。
三)、基於Async的Sleep實現
這個我不想說啥了,我感覺我不要臉的複製了一下:
function sleep(time) { return new Promise((resolve) => setTimeout(resolve, time)); } async function run() { for (var i = 0; i < 6; i++) { await sleep(1000); console.log(i); } } run();
跟我們破壞性解決方案的Async一模一樣,所以真的沒啥好說的,而且這裡我還略掉了比如Generator的實現,setTimeout的巢狀的實現,因為完全就是在重複我們之前的程式碼,沒有啥多說的價值。
當然,如果我們在Node環境中還可以使用子執行緒或者Sleep的第三方依賴包來實現,不過這些大家有興趣可以自己查閱。
十一、其他解決方案之防抖節流
防抖和節流,相信大家一定很熟悉了,其實無論是防抖的實現還是節流的實現,都是通過setTimeout來作為核心的技術點,聊到setTimeout,咱們首先想到的就是回撥巢狀,回撥巢狀?額?不好意思~~不好意思~~串臺了。
聊到setTimeout,想必大家都很熟悉了,差不多咱們整篇的內容都在聊這個東西,接下來我們就看看怎麼通過setTimeout來實現防抖和節流的功能,以及利用防抖和節流實現非同步順序列印的邏輯。
一)基於防抖實現非同步順序列印
我們要實現防抖,就得先理解什麼是防抖:在最後一次觸發事件後間隔一定的時間再執行回撥。什麼意思呢,大概就是,在你第一次觸發事件後,會間隔一定的時間後再執行回撥,如果在事件觸發和執行回撥的這段時間內再次觸發了事件,則重新計算一定的間隔時間,等到時間到了再去執行回撥。如果,偏激一點,你一直在到達執行回撥的時間點之前觸發事件,理論上講,回撥永遠都不會執行,因為一直在重新計算達到時間。換句話說,我們簡單一點理解的話,防抖就是在停止觸發事件後間隔一定的時間執行回撥。
我們來看看最簡單的防抖的實現:
<!DOCTYPE html> <html lang="en"> <head> <meta charset="UTF-8" /> <meta http-equiv="X-UA-Compatible" content="IE=edge" /> <meta name="viewport" content="width=device-width, initial-scale=1.0" /> <title>Document</title> </head> <body> <input type="text" id="input" /> </body> <script> function debounce(func, delay) { return function (args) { clearTimeout(func.id); func.id = setTimeout(() => { func.call(this, args); }, delay); }; } function jiadeAjax(msg) { console.log("假的ajax:" + msg); } const input = document.getElementById("input"); const debouncedJiadeAjax = debounce(jiadeAjax, 1000); input.addEventListener("keyup", (e) => { debouncedJiadeAjax(e.target.value); }); </script> </html>
這是完整的例子,你可以直接複製下來測試一下。程式碼我就不解釋了,我們來看debounce這個函數,接受兩個引數,一個回撥函數,一個延遲時間,然後會返回一個函數,這個返回的函數的引數會在setTimeout的回撥中傳給func函數。當然,最開始我們會首先清除之前的計時器。程式碼很簡單,一共就8行。那麼,我們怎麼利用這個防抖來實現順序非同步列印呢?
二)基於節流實現非同步順序列印
防抖我們大概瞭解,那麼節流呢?節流要比防抖好理解一些,也就是規定時間內只允許執行一次回撥。大概意思呢就是不管你觸發了多少次事件,每次回撥執行的間隔時間是固定的。
十二、其他解決方案總結
其他解決方案部分,甚至是整個本篇文章,其實都只是在聊一件事,就是回撥。嗯~~就一句話。
十三、文末逼逼
本篇文章,我們經歷了部分結局方案,通過變數存取不同儲存區域的資料,來獲取到對應的資訊,部分實現了非同步遍歷的能力。破壞性解決方案,則是通過使用現代Javascript的各種能力,最終通過Generator、Async實現了近乎完美的非同步遍歷,就像寫同步程式碼一樣優雅。最後,我們還聊了聊其他解決方案,但是聊著聊著,我們發現其他解決方案也離不開Async、setTimeout、Promise這些Javascript的核心能力。
最後,其實還有一個點我沒說,就是非同步遍歷器,這個的詳細內容,大家可以去連結地址詳細閱讀學習,我說的肯定不如阮一峰大神說的好(主要是我說不明白)。我下面僅提供一下針對本章核心議題的利用一步遍歷器的一種解決方案:
------------恢復內容開始------------
這道題,我相信很多前端從業者都知道,它本質上來說並不複雜,但是卻可以有很深遠的擴充套件,最終核心的主題其實就是非同步的執行,其中對於題目的解法,還涉及到一些作用域的知識。那麼我們以最簡版的題目入手,逐步深入,一點點的剖開這道題所涉及到的知識概念和體系。
我們先來看這道題:
for (var i = 0; i < 6; i++) { setTimeout(() => { console.log(i); }, 1000); }
這個結果想必大家都能很快的說出來,這段程式碼會在重新整理頁面一秒後一次性的列印6次6。這是為啥呢?我們來分析下這段程式碼的實際執行順序:
var i; for (i = 0; i < 6; i++) {} setTimeout(() => { console.log(i); }, 1000); setTimeout(() => { console.log(i); }, 1000); setTimeout(() => { console.log(i); }, 1000); setTimeout(() => { console.log(i); }, 1000); setTimeout(() => { console.log(i); }, 1000); setTimeout(() => { console.log(i); }, 1000);
我們看,其實這段程式碼可以這樣來理解,setTimeout並不是按照我們所想的那樣,在迴圈的內部依次執行的,原因在於setTimeout是一個非同步回撥的宏任務,他會在執行到該程式碼的時候,把傳入setTimeout的回撥函數及引數資訊存在一個延遲佇列中,並不是訊息佇列噢,是延遲佇列。當延遲佇列發現,誒?時間到了,就會把延遲佇列中的回撥函數包裝成事件插入到訊息佇列中,如果此時訊息佇列中沒有其他待執行的任務在前面,那麼就會立即執行該延遲事件。
所以由於非同步回撥的原因,導致了setTimeout中的回撥函數並不是在for迴圈體內部執行的,而是等待for迴圈執行結束之後,並且執行完迴圈體後又i++了一次,等待一秒後,才一次性的執行了6次setTimeout中的回撥。
一秒後,6次6。一秒的延遲是因為我們每次迴圈,新增的到延遲佇列中的事件所包含的資訊就是延遲一秒,因為沒有順序執行,所以並不會出現每次迴圈執行一次,就導致了這樣的情況。而6次,則是因為迴圈體迴圈了6次,從0到5,一共6次。而列印出6則是因為在i = 5的最後一次迴圈執行完迴圈體後,還執行了i++,然後setTimeout中非同步回撥所存取的i是全域性作用域下的i,於是i在執行非同步回撥的時候就是6了。
好啦,我相信大家已經知道為什麼這樣寫程式碼與我們的預期不符。那,要怎麼樣才能符合我們的預期呢?那麼在這裡確定一下,我們的預期是:每隔一秒,列印一次對應的數位。也就是第一秒列印0,第二秒列印1,這樣子。
一、部分解決方案之IIFE
第一種不完全的解決方案就是利用IIFE的特性,形成了一個閉包,我們來看程式碼:
for (var i = 0; i < 6; i++) { (function (j) { setTimeout(() => { console.log(j); }, 1000); })(i); }
我們用一個匿名立即執行函數來包裹整個非同步的setTimeout部分,然後把迴圈中的i作為匿名函數的引數傳入,列印的就是這個傳入的引數即可。這樣,我們就可以在控制檯看到順序列印的0~5,但是還有個問題沒有解決,我們看到0到5是在一秒之後,一下子列印出來的,每隔一秒的需求還是沒有做到。
每秒的事情我們稍後再說,我們先分析下為什麼用立即執行函數就能解決順序列印的問題,為什麼用立即執行函數就不再是6個6了呢?其實問題得到解決的根本原因在於區域性作用域與全域性作用域。函數會產生一個區域性的作用域,當我們使用立即執行函數包裹非同步時,非同步回撥所取的j其實是立即執行函數所傳入的引數i,當立即執行函數執行的時候,會產生一個執行上下文棧幀加入到執行上下文棧的棧頂,而每一個棧幀中會儲存一些上下文資訊。這些上下文資訊中包含了很多東西,比如arguments、比如變數環境、詞法環境、this,作用域指標等等,這裡不再展開,有興趣可以去學習下執行上下文棧。
那麼我們來分析下上面的程式碼是怎麼執行的,每一次迴圈的時候,都會執行立即執行函數,立即執行函數會形成一個棧幀插入到棧頂,那麼在執行到立即執行函數中的非同步回撥setTimeout的時候,會在延遲佇列中新增一個回撥函數,這個回撥函數要去取j,而執行上下文棧中對應的棧幀有這個arguments引數j,所以回撥函數取到的j就是對應迴圈的i。當函數執行完畢,棧幀出棧,下一次迴圈再執行類似的步驟,入棧,執行程式碼讀取棧中的arguments的j,出棧。
那麼,核心的點來了,作用域是真的,執行上下文也是真的,但是在立即函數執行完畢,把setTimeout的回撥加入到延遲佇列中後,執行上文對應的棧幀已經出棧了,我從哪取到的j呢?答案就是閉包,不信你看:
這個圖有點大,大家看到這裡有個Closure,就是延遲佇列中儲存的事件觸發執行時所取到的j。在上面的程式碼中,每一個延遲佇列中的回撥函數都會對應一個閉包,從而取到了j。
Ok,我們現在解決了順序列印的問題,但是每秒列印的問題還沒解決。在這樣的程式碼情況下,有一種破壞性的解決辦法:
for (var i = 0; i < 6; i++) { (function (j) { setTimeout(() => { console.log(j); }, 1000 * (i + 1)); })(i); }
我們在每次迴圈的時候,讓每次加入延遲佇列中的回撥事件的時間按照迴圈次數來遞增,但是實際上,這樣看起來解決了問題,但是卻並不是我們想要解決的方式,其實我們希望的執行方式是:每次迴圈都會在一秒後執行列印。換句話說,希望非同步可以像同步那樣的執行。誒?你是不是想到了什麼?嗯~~我們先看別的解決方案。
二、部分解決方案之塊級作用域
通過IIFE來解決列印順序的問題,其實是利用了函數作用域級棧中儲存的資訊搞定的。那麼我們還有另外一種生成一個區域性作用域的方式,就是塊級作用域:
for (let i = 0; i < 6; i++) { setTimeout(() => { console.log(i); }, 1000); }
那麼我們直接看破壞性的解決每秒列印的問題,其實方法跟IIFE的時候一樣,加秒唄:
for (let i = 0; i < 6; i++) { setTimeout(() => { console.log(i); }, 1000 * (i + 1)); }
其實塊級作用域也好,函數作用域也罷,其核心原理幾乎都是一致的,就是通過作用域來儲存對應的變數,當非同步回撥加入到延遲佇列的時候,取的是對應作用域的值,而不是全域性作用域。
而塊級作用域,實際上是把變數資訊儲存在了執行上下文棧幀中的詞法環境中的,但是這裡,注意這裡,在執行上下文棧中僅僅只有一個全域性的根棧幀,每一次迴圈都會繫結詞法環境中的變數i,就有點像閉包一樣。所以,在非同步回撥加入到延遲佇列的時候,就會去詞法環境中取到對應的i變數。
我們可以通過debugger看到,這裡不再是closure,而是Block,也就是塊級作用域。
那麼我們來簡單分析下上面的程式碼是如何執行的:每次迴圈都會生成一個新的塊級作用域,當setTimeout把非同步回撥函數加入到延遲佇列中時,會在其所依賴的上下文中儲存非同步回撥中使用到的變數i。這裡核心的點就是,加入延遲佇列中的非同步回撥,已經有了所需要的對應的資料資訊。
三、部分解決方案之setTimeout的第三個引數
還有一種解決方案,就是利用setTimeout的第三個引數,既然如此,我們就得先來了解下setTimeout的引數都有哪些:
var timeoutID = scope.setTimeout(function[, delay, arg1, arg2, ...]); var timeoutID = scope.setTimeout(function[, delay]); var timeoutID = scope.setTimeout(code[, delay]);
我們可以看到,setTimeout的第一個引數可以是一個函數,或者一段可執行的程式碼:
for (var i = 0; i < 6; i++) { setTimeout(console.log(i), 1000); }
這樣寫也沒啥問題。但是並不推薦這樣寫,因為瀏覽器會像執行eval包裹的可執行字串那樣來執行這段程式碼,所以我們其實很少這麼使用,第二個引數不用說,就是我們需要延遲執行的時間,誒?setTimeout不僅有第三個引數,還有第四五六七八九十個引數,換句話說,setTimeout的從第三個引數開始,後面可以加任意個引數,這些引數是可選的附加引數,一旦定時器到期,它們會作為引數傳遞給第一個引數的function。
注意!一旦定時器到期,就會把它們作為引數傳遞給function。那我們先試一下:
for (var i = 0; i < 6; i++) { setTimeout( (j) => { console.log(j); }, 1000, i ); }
這樣也行,一點問題沒有,也是隔了一秒,一下子都按順序列印出來了。但是它的原理是咋回事呢?看起來好像跟前兩種解決方案類似,都是每一個非同步回撥在加入到延遲佇列中,觸發執行的時候去某個地方取到了對應的資料。我們還是debugger一下來看看:
我們看setTimeout的第三個引數,所儲存的位置跟前面兩種解決方案完全不同,它存在了Local裡,也就是自己的區域性作用域。至於這種情況的秒數問題我就不寫了吧。好吧~
四、部分解決方案總結
OK,那我們先來總結下這三種場景的解決方案,這三種解決方案都是利用了語言的特性在不同的記憶體位置儲存對應的資料,但是本質上來說並沒有解決核心的需求,也就是我們之前說過的,希望非同步像同步那樣來執行。僅僅只是解決了順序列印的問題,既然我想要順序列印,不考慮每隔一秒的話,那我這樣不就行了:
for (var i = 0; i < 6; i++) { console.log(i); }
那非要非同步隔一秒的話就這樣:
setTimeout(function () { for (var i = 0; i < 6; i++) { console.log(i); } }, 1000);
這不是更好?你扯那些臭氧層有啥用。所以從根本上講,以上三種方法,都算不上是解決方案,只是不得已可以實現的手段罷了。
但是我還有個問題,就是閉包也好、塊級作用域也罷,它們是如何查詢到對應的要列印的那個j的呢?首先,作用域是在函數宣告時就已經確定好的,儲存在執行函數的執行上下文棧幀中的。其次,閉包則像是某一個函數的揹包,在它自己的執行上下文棧幀中找不到的時候,就會去閉包中找。最後,setTimeout的第三個引數會作為function的引數,則是儲存在了執行上下文的aguments中,aguments也是在執行上下文的棧幀裡。你知道我說的這幾種情況對應的以上哪種解決方案的吧?
五、破壞性解決方案之遞迴巢狀
破壞性解決方案,什麼意思呢?就是與本篇開頭的那段程式碼無論在形式上還是程式碼的編寫上,都可能會脫離原貌甚至是完全不同,但是卻可以實現我們真正的目的:每隔一秒順序列印。換句話說,我們完全拋棄迴圈內非同步的形式,只要能實現每隔一秒順序列印即可。那麼我們的目的也就變成了如何實現每隔一秒順序列印的問題。
那麼我們先看第一種解決方案,通過回撥的方式,來試試。
setTimeout(() => { console.log(0); setTimeout(() => { console.log(1); setTimeout(() => { console.log(2); setTimeout(() => { console.log(3); setTimeout(() => { console.log(4); setTimeout(() => { console.log(5); }, 1000); }, 1000); }, 1000); }, 1000); }, 1000); }, 1000);
這程式碼是不是很好看,從形式上如此的美妙,勻稱,從編碼上如此的清晰、易懂。完美的實現了我們的需求。我相信你看到這肯定會笑出聲,嗯~我也一樣。哈哈哈哈哈。
雖然你笑出了聲,但是我還是要嚴肅的解釋下上面的程式碼。嗯~~就是非同步回撥裡巢狀非同步回撥,這樣子其實每一次都在延遲佇列中加入了一個事件,當時間到了執行函數的時候就又加進去了一個,如此往復。
這程式碼雖然好看,並且清晰易懂,但是著實不那麼優雅,我們想辦法怎麼讓上面的程式碼更優雅一點呢?
function run(num) { if (num > 5) return; setTimeout(() => { console.log(num); run((num += 1)); }, 1000); } run(0);
其實這程式碼也很好理解,跟我們上面的巢狀的方式沒有任何區別,無非就是遞迴罷了,在每一次run方法執行的setTimeout中再呼叫run方法,遞迴的終點就是num > 5的時候,所以如果強硬的類比一下,遞迴就是迴圈的另外一種形式罷了。這個玩意沒啥技術難度。但是確實是一種解決方案。
這裡額外提一句,死迴圈和棧溢位有啥區別?嗯~~死迴圈可能會導致棧溢位,但是棧溢位不一定是因為死迴圈。
首先死迴圈是指程式碼形式,是指你的程式碼一直的執行下去(一直執行就可能會重複的宣告某些變數,佔用記憶體,就算你就是一個空的死迴圈,也會一直佔用執行佇列導致卡死),沒有終點,於是瀏覽器或者宿主環境會根據你的程式碼,在編譯的時候解析到了死迴圈的程式碼並丟擲錯誤。而棧溢位,實際上可能是由於死迴圈導致的執行上下文棧的無限疊加,超出了宿主環境允許的最大棧幀的數量,從而導致的錯誤。
六、破壞性解決方案之促銷秒殺
額~~其實這個標題有點跑題了,但是它看起來很吸睛,讓不懂的人很好奇,懂的人不珍惜,額~~~沒事,我純粹為了押韻。繼續繼續~~
額~~沒辦法,因為標題跑題了,我不得不解釋下促銷秒殺的實現思路大概是什麼樣的。
首先,促銷秒殺意味著在某一個時間段會有遠超平峰時期的並行,會產生一個伺服器請求處理的擁堵,前面收到的資料還沒處理完,後面的馬上又來了。所以,大量資料在短時間內的並行會造成伺服器的崩潰。當然,這種場景也可以有另外一種叫法,比如Dos或者DDos攻擊,稍微擴充套件一下,大家知道即可。
其次,要解決這樣的場景造成的伺服器阻塞問題,並不僅僅是伺服器中存在,在前端範疇內也是有類似的場景的,比如VueRouter中實現的runQueue方法就是為了解決這樣的問題。那麼解決方案說起來也很簡單,就是我們把所有的請求都放到一個佇列或者也可以說是陣列中,從頭開始呼叫執行陣列中的非同步方法,當非同步結果返回,再去呼叫下一個。
那麼,我們來看下程式碼的實現:
// 一個佇列,我們模擬一下,在佇列中加入了幾個方法。 const queue = []; for (let i = 0; i < 6; i++) { queue.push(function () { return new Promise((resolve, reject) => { setTimeout(() => { console.log(i, new Date()); resolve(i); }, 1000); }); }); } // 執行佇列的方法,主要用來增加步數,也就是遍歷佇列 function runQueue(queue, fn, cb) { const step = (index) => { if (index >= queue.length) { cb(); } else { if (queue[index]) { fn(queue[index], () => { step(index + 1); }); } else { step(index + 1); } } }; step(0); } // 具體的執行邏輯 function run(hook, next) { hook().then((val) => { next(val); }); } // 啟動 runQueue(queue, run, () => { setTimeout(() => { console.log("finally", new Date()); }, 1000); });
我們來看上面完整的程式碼,其實核心的runQueue方法是從VueRouter的原始碼抄過來的,嘿嘿。
首先,們虛擬了一個queue陣列,這個陣列用來儲存所有的非同步方法,我們用Promise包裹了一下,最終會返回這個Promise。Promise內部就是一個一秒之後列印i和當前時間的setTimeout用來模擬ajax請求,或者其他非同步邏輯。
接下來重點來了,就是這個runQueue方法,它接收一個queue作為要執行佇列的資料列表,fn則是作為執行器,執行每一個queue中的事件,cb呢就是回撥,當queue清空了之後會執行這個回撥。runQueue方法的核心是一個step,step內部則其實很簡單,判斷傳入的index,如果大於queue的長度,說明整個queue都執行完畢,則執行回撥。否則,那麼則繼續執行fn執行器來執事件,其第二個引數則是開始下一次執行。
接下來就是執行器方法,也就是runQueue的第二個引數要接收的方法,很簡單,就是呼叫事件,並且在確定有了結果之後執行next,也就是step。
最後,我們執行runQueue方法,傳入queue,run,以及最後的cb,啊~~這裡的cb我為了好看,也延遲了一秒,無所謂,你在本章的場景下,不寫也行。
我們好好看看上面的程式碼,並不複雜,其實它的本質跟我們上一部分的巢狀來說沒什麼區別,只不過不是setTimeout單純的巢狀,而是通過Promise的鏈式呼叫巢狀。只不過我們在執行的過程中加入了步數和回撥,來讓我們可以更細節的操作整個佇列執行的過程,為啥要更細節的操作整個執行過程呢?因為針對複雜場景,很多地方都需要更加細膩的處理。當然,在本章的場景下,其實我們可以簡化下上面的程式碼:
const step = (index) => { if (index > queue.length) return false; if (queue[index]) { queue[index]().then(() => { step(index + 1); }); } else { step(index + 1); } }; step(0);
看到沒,其實就一個step方法……其實就是通過Promise的鏈式呼叫的能力,在then的時候執行下一個事件,當然也可以不用then,也可以用finally,讓巢狀看起來好看了些。這程式碼就很好理解了吧~~
七、破壞性解決方案之Generator
generator是什麼,有什麼,怎麼做,我不會說的很詳細,這不是本篇文章的重點。如果你不清楚generator的作用和效果,為避免不分輕重我會盡可能簡短的介紹清楚,但是如果我沒說清楚,或者你還是沒理解,請一定參考:generator函數的語法和generator的非同步應用以及Iterator。
generator可以理解為一個狀態機,它的內部會使用yield表示式產出狀態,我們可以這樣來建立一個generator函數,通過執行generator函數,會返回一個遍歷器物件,也就是Iterator物件:
function* gen() { yield console.log("hello"); yield console.log("zaking"); } var genItem = gen(); genItem.next(); genItem.next(); console.log(genItem.next());
我們通過funciton*來宣告一個Generator函數,內部有兩個狀態,這兩個狀態是一個console語句。然後我們通過執行gen這個Generator函數後,得到了genItem這個Iterator遍歷器物件,然後就可以通過呼叫遍歷器物件的next來獲取到Generator函數內部的狀態,當遍歷結束後,再執行genItem.next()則會得到擁有value和done欄位的物件,此時的done是true來標識遍歷結束。當然,這只是同步執行前提下的Generator函數,比較好理解。
由於 Generator 函數返回的遍歷器物件,只有呼叫next方法才會遍歷下一個內部狀態,所以其實提供了一種可以暫停執行的函數。yield表示式就是暫停標誌。我們還可以把上面的程式碼寫的豐富一點,便於理解:
function* gen() { console.log("1"); yield "hello"; console.log("2"); yield "zaking"; console.log("3"); } var genItem = gen();
console.log(genItem.next());
這樣會列印出:
但是假設你不執行genItem.next()則不會列印任何內容也就是不會執行任何程式碼,換句話說,通過Generator生成的物件,只有呼叫該物件的next方法才會執行,直到在函數內部遇到yield則會暫停,會返回yield後面的內容到函數外部。再一次執行genItem.next():
最後一次執行genItem.next():
這樣,則整個Generator函數執行完畢,你看,我們有兩個yield,但是其實要三次next()方法的呼叫才能真正的執行完整個Generator函數,那我要想知道什麼時候結束了,只能通過判斷呼叫next()返回的物件的done來確定。
以上都是同步執行,非同步執行怎麼辦呢?其實看起來也並不複雜:
function* gen() { yield setTimeout(function () { console.log(1, new Date()); }, 1000); yield setTimeout(function () { console.log(2, new Date()); }, 1000); } var g = gen(); g.next(); g.next();
上面的程式碼列印出來是這樣的,隔了一秒,然後:
換句話說,這並不是我們想要的,這樣只是解決了順序列印的問題,但是並沒有解決每隔一秒的問題。要解決這個問題,我們得先考慮一個問題,就是當我們使用Generator來執行非同步操作的時候,我怎麼能知道什麼時候交回執行權呢?只有非同步執行有了結果的時候,才需要交回執行權,但是我們又不知道什麼時候非同步才會有結果,答案是隻有回撥才能知道。所以,針對同步執行的Generator函數,for…of遍歷即可,因為Generator會返回一個Iterator物件,但是針對非同步操作,for…of肯定是不行的。
一)Thunk函數
Thunk函數最初的定義其實是用來替換某個表示式,但是在Javascript中Thunk函數的定義則有些不同,Thunk 函數替換的不是表示式,而是多引數函數,將其替換成一個只接受回撥函數作為引數的單引數函數。比如這樣:
function readFile(filename, callback) { console.log(filename); setTimeout(function () { callback(); }, 1000); } function Thunk(filename) { return function (cb) { return readFile(filename, cb); }; } var readFileThunk = Thunk("filename"); readFileThunk(function () { console.log("ayayay"); });
其實程式碼理解起來並不複雜,我們寫了一個假的readFile方法,接收兩個引數,一個filename和一個callback。當我們呼叫的時候會立即列印filename欄位並且一秒後執行callback。然後我們的Thunk函數,其實也很簡單,就是通過一個先接收一個filename,然後再返回一個直接收一個cb引數的函數,這個函數內部通過閉包拿到filename並傳入readFIle。然後,我們通過Thunk函數率先傳入filename生成一個只接受回撥函數作為引數的readFileThunk函數。
理論上講,任何函數,只要有回撥函數,就可以寫成Thunk函數的形式,那麼我們可以提煉出一個通用的Thunk函數轉換器:
const Thunk = function (fn) { return function (...args) { return function (callback) { return fn.call(this, ...args, callback); }; }; };
然後,針對上面的程式碼,我們就可以這樣來寫:
function readFile(filename, callback) { console.log(filename); setTimeout(function () { callback(); }, 1000); } const Thunk = function (fn) { return function (...args) { return function (callback) { return fn.call(this, ...args, callback); }; }; }; var readFileThunk = Thunk(readFile); readFileThunk("filename")(function () { console.log("ayayay"); });
當然,我們只是最小化的實現了通用的Thunk函數,生產環境建議可以使用Thunkify模組。誒?你這Thunk函數是不是Currying?柯里化?嗯~~我覺得是,但是就不再擴充套件了。如果這樣跑題下去,就沒邊了。
那Thunk函數有啥用呢?前面稍微說過,同步執行的Generator函數可以用for…of遍歷,但是非同步執行的Generator就需要用到Thunk函數了。我們先來看一段程式碼:
function readFile(filename, callback) { setTimeout(function () { callback(filename); }, 1000); } const Thunk = function (fn) { return function (...args) { return function (callback) { return fn.call(this, ...args, callback); }; }; }; var readFileThunk = Thunk(readFile);
這段程式碼跟之前的沒有太大的區別,只是稍稍修改了readFile方法把傳入的filename傳給了callback回撥。其他的就一模一樣了,那麼我們接下來看看,通過Thunk函數處理後,我們如何利用Generator來順序執行非同步:
var gen = function* () { let r1 = yield readFileThunk("path--1"); console.log(r1); let r2 = yield readFileThunk("path--2"); console.log(r2); }; var g = gen(); var r1 = g.next(); r1.value(function (data) { let r2 = g.next(data); r2.value(function (data) { g.next(data); }); });
我們看,首先建立了一個Generator函數gen,然後這個函數內部呼叫了兩次readFileThunk並傳入了filename引數,然後列印結果,然後再來一次。重點在下面的程式碼,首先我們生成遍歷器範例後,通過執行g.next(),此時相當於返回了第一個yield後面的readFileThunk,經過Thunk函數處理,我們只需要傳入回撥函數就可以了。再詳細一點,當我們執行了第一個next的時候,相當於我們把協程切換到Generator內部,轉移執行權。當Generator函數內部執行到yield的的時候,會返回yield後面的內容並把執行權移交給主協程。然後,我們執行r1.value並傳入回撥函數,再通過呼叫next,把回撥函數的引數傳遞給next,此時主協程把執行權交給Generator協程,此時拿到的r1結果並列印,然後遇到第二個yield,再執行上面的步驟。
整個程式碼執行的過程可以這樣理解:當執行next的時候,把程式碼的執行權交給了Generator函數,當執行yield的時候,就把執行權交給了主協程。通過yield和next的引數來實現兩個協程的資料傳遞。最後,再通過Thunk函數直接暴露了回撥函數,可以讓我們在協程外部來執行回撥函數,回撥函數內部去移交執行權。
到現在為止,我們實現了手動呼叫,來移交執行權,讓整個Generator非同步遍歷器可以執行下去,但是如果非同步很多,我們這樣寫下去,你看像不像回撥地獄?哈哈哈哈~沒錯,哪怕是Generator,要想確定非同步返回了結果再往後執行,本質也是通過回撥實現的。
二)基於Thunk函數的自動執行
我們直接上程式碼吧,這個程式碼你應該略微比較熟悉:
function run(fn) { var gen = fn(); function next(data) { var result = gen.next(data); if (result.done) return; result.value(next); } next(); }
這個run函數,傳入的是一個Generator函數。run函數內部則宣告了一個next方法,其實這個next就是回撥,第一次執行next實際上就是啟動,然後執行gen.next,判斷Generator的狀態,再執行result.value。就是遞迴啦~
那麼,還是上面的例子,我們就可以這樣寫,完整的程式碼如下:
function readFile(filename, callback) { setTimeout(function () { callback(filename); }, 1000); } const Thunk = function (fn) { return function (...args) { return function (callback) { return fn.call(this, ...args, callback); }; }; }; var readFileThunk = Thunk(readFile); var gen = function* () { let r1 = yield readFileThunk("path--1"); console.log(r1); let r2 = yield readFileThunk("path--2"); console.log(r2); }; function run(fn) { var gen = fn(); function next(data) { var result = gen.next(data); if (result.done) return; result.value(next); } next(); } run(gen);
所以你看,其實自動執行也不復雜。咱們之前在第六小節做的秒殺的那個解決方案,實際上就是這個思路。那麼這只是我們為了實現本篇文章的目的所做的比較簡單的run方法,生產環境其實可以co模組,這個就不多說了。
三)基於Promise的自動執行
上面的解決方案是基於回撥函數的,還有一種解決方案是基於Promise的,額,其實就是回撥函數的另外一種寫法麼。我們來看看基於Promise的要怎麼寫。其實有了前面的基礎,寫出Promise的例子就很簡單了。那麼我們先改造下readFile:
function readFile(filename) { return new Promise(function (resolve, reject) { setTimeout(function () { resolve(filename); }, 1000); }); }
嗯~就是callback沒了,換成了Promise。簡單吧?繼續,我們的gen方法沒有變化:
var gen = function* () { let r1 = yield readFile("path--1"); console.log(r1); let r2 = yield readFile("path--2"); console.log(r2); };
然後,我們先來看手動執行:
var g = gen(); g.next().value.then(function (data) { g.next(data).value.then(function (data) { g.next(data); }); });
額,我不知道該咋說了,就是回撥巢狀,變成了鏈式呼叫。
那麼,我們再來看看自動執行:
function run(gen) { var g = gen(); function next(data) { var result = g.next(data); if (result.done) return result.value; result.value.then(function (data) { next(data); }); } next(); } run(gen);
也沒啥,對吧?重複的話我就不說了~~
四)迴歸
前面說了那麼多,實際上已經解決了本篇的核心問題,但是由於是測試程式碼,所以我下面附上回歸本篇問題的範例:
function readFile(filename, callback) { setTimeout(function () { callback(filename); }, 1000); } const Thunk = function (fn) { return function (...args) { return function (callback) { return fn.call(this, ...args, callback); }; }; }; var readFileThunk = Thunk(readFile); var gen = function* () { for (var i = 0; i < 6; i += 1) { var r = yield readFileThunk(i); console.log(r, new Date()); } }; function run(fn) { var gen = fn(); function next(data) { var result = gen.next(data); if (result.done) return; result.value(next); } next(); } run(gen);
我啥也沒改啊,就是改了一下gen函數,你看現在這個gen函數,是不是跟我們寫同步程式碼很像了。至於Promise版本的迴圈非同步列印,嗯~~當作作業了,你自己試下~
但是其實我們做了好多的前置內容才實現了這樣的寫法,這種寫法太煩了,有沒有簡單點的?有!
八、破壞性解決方案之Async
async,async,我相信大家基本上都用過或者瞭解過,但是async是啥?嗯~~async就是Generator的語法糖,它的本質就是Generator。那麼我們看一段熟悉的程式碼:
function readFile(filename, callback) { return new Promise((resolve, reject) => { setTimeout(function () { resolve(filename); }, 1000); }); } var gen = async function () { let r1 = await readFile("path--1"); console.log(r1); let r2 = await readFile("path--2"); console.log(r2); }; gen();
列印的時候,我們看控制檯,確實是每隔一秒列印了一次。你看,我們十分優雅的解決了最開始的問題,至於迴圈列印,我們可以這樣寫(嗯,我把函數名改了):
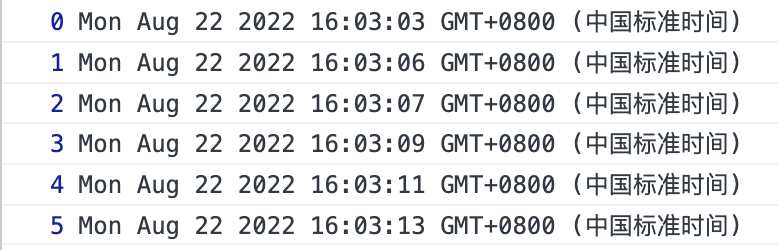
function callConsole(i) { return new Promise((resolve, reject) => { setTimeout(function () { resolve(i); }, 1000); }); } var run = async function () { for (let i = 0; i < 6; i++) { let r = await callConsole(i); console.log(r, new Date()); } }; run();
試試看結果?
臥槽,完美的解決方案,一目瞭然的程式碼形式,非同步就像同步那樣簡潔明瞭,這就是我們費了這麼多功夫找到的完美的解決方案。
但是還沒完,因為我們之前大量的鋪墊,才能這麼快得出結果。但是~沒錯,還有但是。我們得分析下,async和generator有啥區別呢?我抄一下阮一峰大神的《ECMAScript 6 入門》針對這一點的描述:
- 內建執行器
- 更清晰的語意
- 更廣的適用性
- 返回值是Promise
差不多區別就是這幾點,首先因為擁有了內建執行器,最直觀的感受就是程式碼更簡單,不需要我們引入額外的模組或者程式碼去像執行Generator那樣來執行Async函數,並且返回值是Promise,讓我們可以用then來進行下一步的操作。
其他關於Async函數的部分,大家有興趣可以自己查閱,不多說了噢,說多了總是會跑題的~
九、破壞性解決方案總結
我們簡單回顧一下,關於破壞性解決方案的部分,我們都經歷了哪些過程。
最開始,我們通過setTimeout的非同步回撥,巢狀回撥,最後形成回撥地獄,當上一個非同步有了結果之後,再執行下一個,再執行下一個,直到沒有回撥了就結束了。但是這樣的程式碼實在是有點LowBi,所以我們通過一個簡單的遞迴,讓程式碼更簡潔了些,但是本質也還是回撥地獄。
然後,我們學習了一個概念,就是促銷秒殺,其實促銷秒殺的本質無非就是維護一個佇列,拿到的事件不會直接讓宿主環境執行,而是先放到佇列裡,挨個執行,等到前一個有結果了,再執行下一個,誒?這話怎麼這麼熟悉,嗯~~其實根本上來說,也是回撥,只不過從遞迴換成了迴圈,並且還加入了一點next的概念,以及通過Promise的包裹,在then裡執行next,但是和回撥沒區別。
繼續,我們就學了破壞性解決方案最複雜的、也是最重要的一部分,Generator函數,我們花了很大的篇幅來講Generator,一步一步的帶大家實現了我們最終的目標。
最後,因為在Generator部分大量的鋪墊,引出了本章最重要的也是最終的完美的解決方案async函數,沒錯,能像同步那樣來寫非同步程式碼,終極的解決方案就是async了。但是我還是要強調的是,無論是遞迴、迴圈、Promise、還是Generator、Async,本質上來說,都離不開回撥,沒有回撥,你怎麼知道我執行完了呢?只不過是書寫形式上的變化和一些些原理實現上的不同罷了。
十、其他解決方案之sleep
sleep是什麼?翻譯過來是睡覺。那我發散下思維,在程式中的sleep,我是不是可以理解為讓程式睡了一覺?醒過來再繼續執行任務?嗯~~差不多,其實在Javascript中並沒有sleep的概念,sleep往往是在Java或者Linux中的概念,完整的概念性解釋如下:
Sleep函數可以使計算機程式(程序,任務或執行緒)進入休眠,使其在一段時間內處於非活動狀態。當函數設定的計時器到期,或者接收到訊號、程式發生中斷都會導致程式繼續執行。
那麼在Javascript中,可以通過setTimeout定時器來實現sleep。迴歸到我們本章的主題,既然是用定時器,我是不是可以這樣?停一秒,列印,停一秒,再列印,是不是就實現了我們的目的?那我們首先來實現一個基於Javascript的Sleep函數。
一)、基於Date的Sleep實現
第一種實現方式,其實就是用來計算時間,程式碼是這樣的:
function sleep(time) { var timeStamp = new Date().getTime(); var endTime = timeStamp + time; while (true) { if (new Date().getTime() > endTime) { return; } } }
這塊程式碼很簡單,就是通過死迴圈來佔用執行緒的任務執行,通過計算當前的時間和延遲的時間,得到結束的時間,結束的時間一到,則終止迴圈,這樣就形成了一個Sleep函數,那麼我們就可以非常簡單的寫出迴圈列印的程式碼了:
for (var i = 0; i < 6; i++) { sleep(1000); console.log(i, new Date()); }
很簡單,並且滿足我們的所有要求。但是這種實現直接佔用了執行緒,導致任何程式碼都無法執行,這種方式只是為了實現而實現,沒有任何實際應用的價值。
二)、基於Promise的Sleep實現
Promise的實現也並不複雜:
function sleep(time, i) { return new Promise(function (resolve) { setTimeout(function () { resolve(i); }, time); }); } for (var i = 0; i < 6; i++) { sleep(1000 * i, i).then((i) => { console.log(i, new Date()); }); }
但是這種實現你發現沒有,似乎回到了我們最開始的部分解決方案的那種方式裡,遞增描述並且把i作為引數傳了進去。這樣寫,只是實現了Sleep,但是其實並沒有實現一種優雅的書寫方式解決非同步遍歷的問題。
三)、基於Async的Sleep實現
這個我不想說啥了,我感覺我不要臉的複製了一下:
function sleep(time) { return new Promise((resolve) => setTimeout(resolve, time)); } async function run() { for (var i = 0; i < 6; i++) { await sleep(1000); console.log(i); } } run();
跟我們破壞性解決方案的Async一模一樣,所以真的沒啥好說的,而且這裡我還略掉了比如Generator的實現,setTimeout的巢狀的實現,因為完全就是在重複我們之前的程式碼,沒有啥多說的價值。
當然,如果我們在Node環境中還可以使用子執行緒或者Sleep的第三方依賴包來實現,不過這些大家有興趣可以自己查閱。
十一、其他沒解決方案之防抖節流
防抖和節流,相信大家一定很熟悉了,其實無論是防抖的實現還是節流的實現,都是通過setTimeout來作為核心的技術點,聊到setTimeout,咱們首先想到的就是回撥巢狀,回撥巢狀?額?不好意思~~不好意思~~串臺了。
聊到setTimeout,想必大家都很熟悉了,差不多咱們整篇的內容都在聊這個東西,接下來我們就看看怎麼通過setTimeout來實現防抖和節流的功能,以及利用防抖和節流實現非同步順序列印的邏輯。
一)基於防抖沒實現非同步順序列印
我們要實現防抖,就得先理解什麼是防抖:在最後一次觸發事件後間隔一定的時間再執行回撥。什麼意思呢,大概就是,在你第一次觸發事件後,會間隔一定的時間後再執行回撥,如果在事件觸發和執行回撥的這段時間內再次觸發了事件,則重新計算一定的間隔時間,等到時間到了再去執行回撥。如果,偏激一點,你一直在到達執行回撥的時間點之前觸發事件,理論上講,回撥永遠都不會執行,因為一直在重新計算達到時間。換句話說,我們簡單一點理解的話,防抖就是在停止觸發事件後間隔一定的時間執行回撥。
我們來看看最簡單的防抖的實現:
<!DOCTYPE html> <html lang="en"> <head> <meta charset="UTF-8" /> <meta http-equiv="X-UA-Compatible" content="IE=edge" /> <meta name="viewport" content="width=device-width, initial-scale=1.0" /> <title>Document</title> </head> <body> <input type="text" id="input" /> </body> <script> function debounce(func, delay) { return function (args) { clearTimeout(func.id); func.id = setTimeout(() => { func.call(this, args); }, delay); }; } function jiadeAjax(msg) { console.log("假的ajax:" + msg); } const input = document.getElementById("input"); const debouncedJiadeAjax = debounce(jiadeAjax, 1000); input.addEventListener("keyup", (e) => { debouncedJiadeAjax(e.target.value); }); </script> </html>
這是完整的例子,你可以直接複製下來測試一下。程式碼我就不解釋了,我們來看debounce這個函數,接受兩個引數,一個回撥函數,一個延遲時間,然後會返回一個函數,這個返回的函數的引數會在setTimeout的回撥中傳給func函數。當然,最開始我們會首先清除之前的計時器。程式碼很簡單,一共就8行。那麼,我們怎麼利用這個防抖來實現順序非同步列印呢?
二)基於節流沒實現非同步順序列印
防抖我們大概瞭解,那麼節流呢?節流要比防抖好理解一些,也就是規定時間內只允許執行一次回撥。大概意思呢就是不管你觸發了多少次事件,在一定的時間內,每次回撥執行的間隔時間是固定的。我們可以類比一下,節流可以理解為河中的大壩,限制水流的流速,讓流速滿足我們的要求。那麼我們來看下怎麼實現節流吧:
<!DOCTYPE html> <html lang="en"> <head> <meta charset="UTF-8" /> <meta http-equiv="X-UA-Compatible" content="IE=edge" /> <meta name="viewport" content="width=device-width, initial-scale=1.0" /> <title>Document</title> </head> <body> <input type="text" id="input" /> </body> <script> const throttle = function (func, wait) { let previous = 0; return function (args) { let now = +new Date(); if (now - previous >= wait) { func.call(this, args); previous = now; } }; }; function jiadeAjax(msg) { console.log("假的ajax:" + msg, new Date()); } const input = document.getElementById("input"); const throttleJiadeAjax = throttle(jiadeAjax, 1000); input.addEventListener("keyup", (e) => { throttleJiadeAjax(e.target.value); }); </script> </html>
這算是最簡版的節流的實現,也不過區區十行程式碼,核心的形式跟防抖是一樣的,只不過在節流的實現上,我們要記錄開始和當前觸發事件的時間,如果現在的時間減去之前的時間大於或等於wait的時間,則執行回撥,並重新設定previous,很簡單。
十二、其他方案總結
其他解決方案部分,甚至是整個本篇文章,其實都只是在聊一件事,就是回撥。嗯~~就一句話。然後,本來想的是防抖和節流也是通過setTimeout實現的,我的理解是隻要存在非同步理論上講就可以非同步遍歷,但是想來想去沒想出來基於防抖節流怎麼實現非同步遍歷。算了,不想了~~就當留個笑話~~哈哈哈,第一次見寫部落格寫到最後寫不出來了。
十三、文末逼逼
本篇文章,我們經歷了部分解決方案,通過變數存取不同儲存區域的資料,來獲取到對應的資訊,部分實現了非同步遍歷的能力。破壞性解決方案,則是通過使用現代Javascript的各種能力,最終通過Generator、Async實現了近乎完美的非同步遍歷,就像寫同步程式碼一樣優雅。最後,我們還聊了聊其他解決方案,但是聊著聊著,我們發現其他解決方案也離不開Async、setTimeout、Promise這些Javascript的核心能力,比如實現Sleep,方法很多,但是再寫下去其實就是再過一遍破壞性解決方案,沒意義。
本來我覺得防抖和節流也是可以實現非同步遍歷的,並且我可以確定的告訴你,基於防抖、節流的實現邏輯,配合一定的程式碼修改,是可以實現非同步遍歷的,但是問題在於,這又回到破壞性解決方案的部分了,所以我寫著寫著不想寫了~~~額~~~不會寫了也行,反正就是不寫了。
最後,其實還有一個點我沒說,就是非同步遍歷器,這個的詳細內容,大家可以去連結地址詳細閱讀學習,我說的肯定不如阮一峰大神說的好(主要是我說不明白)。我簡單的介紹下非同步遍歷器,Generator函數只能返回同步遍歷器,如果我們想要在Generator中使用非同步,就必須返回一個Thunk函數或者Promise,因為這樣會把回撥暴露到外層,讓我們在回撥中操作稍後返回的資料。但是由於這樣的寫法很不直觀,所以ES2018原生的支援了非同步遍歷器,也就是Symbol.asyncIterator。不管是什麼樣的物件,只要它的Symbol.asyncIterator屬性有值,就表示應該對它進行非同步遍歷。不過,非同步遍歷器目前還沒有瀏覽器的實現,只是規範的一個草案。
雖然非同步遍歷器還沒有被實現,但是其實我們完全可以自己動手去寫一個非同步遍歷器,並且其實已經在阮一峰大神的敘述講解中給出了方案,本章的核心內容已經完美的告一段落,我就不再畫蛇添足。