MPI學習筆記(三):矩陣相乘的分塊並行(行列劃分法)
2022-08-28 21:00:47
mpi矩陣乘法:C=αAB+βC
一、主從模式的行列劃分並行法
1、實現方法
將可用於計算的程序數comm_sz分解為a*b,然後將矩陣A全體行劃分為a個部分,將矩陣B全體列劃分為b個部分,從而將整個結果矩陣劃分為size相同的comm_sz個塊。每個子程序負責計算最終結果的一塊,只需要接收A對應範圍的行和B對應範圍的列,而不需要把整個矩陣傳過去。主程序負責分發和彙總結果。
程序數comm_sz分解為a*b的方法:
int a=comm_sz/(int)sqrt(comm_sz); int b=(int)sqrt(comm_sz);
但當comm_sz=13時,a=3,b=4,此時程序總數comm_sz不等於a*b,這樣就會導致有多餘的程序不參與運算。
2、範例
當總程序數為comm_sz=6時計算以下A*B矩陣,其中矩陣A劃分了a=3塊,B矩陣劃分了b=2塊。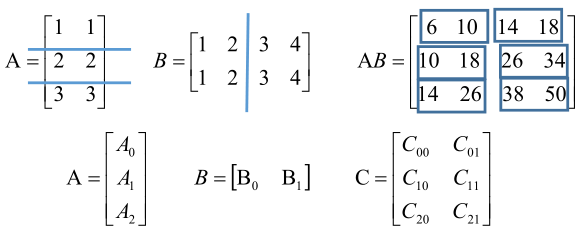
第一個程序計算C00=A0B0,第二個程序計算C01=A0B1,以此類推。那麼如何保證傳輸到各個程序矩陣A的行資料和矩陣B的列資料是相對應的。
3、對程序總數沒有公約數的處理
方法1:當有多餘的程序不參與運算時,使用MPI_ABORT終止該程序。方法2:在MPI開始時加一個判斷語句來終止MPI執行,讓使用者重新選擇程序總數。
4、完整程式碼
#include <stdio.h>
#include "mpi.h"
#include <stdlib.h>
#include <math.h>
#include "dgemm_1.h"
/*** 主從模式 行列劃分 ***/
int main(int argc, char **argv)
{
int M=2000,N=3000,K=2500; // 矩陣維度
int my_rank,comm_sz;
double start, stop; //計時時間
double alpha=2,beta=2; // 係數C=aA*B+bC
MPI_Status status;
MPI_Init(&argc,&argv);
MPI_Comm_size(MPI_COMM_WORLD, &comm_sz);
MPI_Comm_rank(MPI_COMM_WORLD,&my_rank);
int a=comm_sz/(int)sqrt(comm_sz); // A矩陣行分多少塊
int b=(int)sqrt(comm_sz); // B矩陣列分多少塊
if(M<K){
int c=a;
a=b;
b=c;
}
if(comm_sz!=a*b || a>M || b>K){
if(my_rank==0)
printf("error process:%d\n",comm_sz);
MPI_Finalize();
return 0;
}
int saveM=M; // 為了使行資料平均分配每一個程序
if(M%a!=0){
M-=M%a;
M+=a;
}
int saveK=K;// 為了使列資料平均分配每一個程序
if(K%b!=0){
K-=K%b;
K+=b;
}
int each_row=M/a; // 矩陣A每塊分多少行資料
int each_col=K/b; // 矩陣B每列分多少列資料
// 給矩陣A B,C賦值
if(my_rank==0){
double *Matrix_A,*Matrix_B,*Matrix_C,*result_Matrix;
Matrix_A=(double*)malloc(M*N*sizeof(double));
Matrix_B=(double*)malloc(N*K*sizeof(double));
Matrix_C=(double*)malloc(M*K*sizeof(double));
result_Matrix=(double*)malloc(M*K*sizeof(double)); // 儲存資料計算結果
for(int i=0;i<M;i++){
for(int j=0;j<N;j++)
if(i<saveM)
Matrix_A[i*N+j]=i+1;
else
Matrix_A[i*N+j]=0;
for(int p=0;p<K;p++)
Matrix_C[i*K+p]=1;
}
for(int i=0;i<N;i++){
for(int j=0;j<K;j++)
if(j<saveK)
Matrix_B[i*K+j]=j+1;
else
Matrix_B[i*K+j]=0;
}
// 輸出A,B,C
//Matrix_print(Matrix_A,saveM,N);
//Matrix_print2(Matrix_B,N,saveK,K);
//Matrix_print2(Matrix_C,saveM,saveK,K);
printf("a=%d b=%d row=%d col=%d\n",a,b,each_row,each_col);
start=MPI_Wtime();
// 主程序計算第1塊
for(int i=0;i<each_row;i++){
for(int j=0;j<each_col;j++){
double temp=0;
for(int p=0;p<N;p++){
temp+=Matrix_A[i*N+p]*Matrix_B[p*K+j];
}
result_Matrix[i*K+j]=alpha*temp+beta*Matrix_C[i*K+j];
}
}
// 向每個程序傳送其它塊資料
for(int i=1;i<comm_sz;i++){
int beginRow=(i/b)*each_row; // 每個塊的行列起始位置(座標/偏移量)
int beginCol=(i%b)*each_col;
MPI_Send(Matrix_A+beginRow*N,each_row*N,MPI_DOUBLE,i,1,MPI_COMM_WORLD);
for(int j=0;j<N;j++)
MPI_Send(Matrix_B+j*K+beginCol,each_col,MPI_DOUBLE,i,j+2,MPI_COMM_WORLD);
for(int p=0;p<each_row;p++)
MPI_Send(Matrix_C+(beginRow+p)*K+beginCol,each_col,MPI_DOUBLE,i,p+2+N,MPI_COMM_WORLD);
}
// 接收從程序的計算結果
for(int i=1;i<comm_sz;i++){
int beginRow=(i/b)*each_row;
int endRow=beginRow+each_row;
int beginCol=(i%b)*each_col;
for(int j=beginRow;j<endRow;j++)
MPI_Recv(result_Matrix+j*K+beginCol,each_col,MPI_DOUBLE,i,j-beginRow+2+N+each_row,MPI_COMM_WORLD,&status);
}
//Matrix_print2(result_Matrix,saveM,saveK,K);
stop=MPI_Wtime();
printf("rank:%d time:%lfs\n",my_rank,stop-start);
free(Matrix_A);
free(Matrix_B);
free(Matrix_C);
free(result_Matrix);
}
else {
double *buffer_A,*buffer_B,*buffer_C,*ans;
buffer_A=(double*)malloc(each_row*N*sizeof(double)); // A的均分行的資料
buffer_B=(double*)malloc(N*each_col*sizeof(double)); // B的均分列的資料
buffer_C=(double*)malloc(each_row*each_col*sizeof(double)); // C的均分行的資料
//接收A行B列的資料
MPI_Recv(buffer_A,each_row*N,MPI_DOUBLE,0,1,MPI_COMM_WORLD,&status);
for(int j=0;j<N;j++){
MPI_Recv(buffer_B+j*each_col,each_col,MPI_DOUBLE,0,j+2,MPI_COMM_WORLD,&status);
}
for(int p=0;p<each_row;p++){
MPI_Recv(buffer_C+p*each_col,each_col,MPI_DOUBLE,0,p+2+N,MPI_COMM_WORLD,&status);
}
//計算乘積結果,並將結果傳送給主程序
for(int i=0;i<each_row;i++){
for(int j=0;j<each_col;j++){
double temp=0;
for(int p=0;p<N;p++){
temp+=buffer_A[i*N+p]*buffer_B[p*each_col+j];
}
buffer_C[i*each_col+j]=alpha*temp+beta*buffer_C[i*each_col+j];
}
}
//matMulti(buffer_A,buffer_B,buffer_C,each_row,N,each_col,alpha,beta);
for(int j=0;j<each_row;j++){
MPI_Send(buffer_C+j*each_col,each_col,MPI_DOUBLE,0,j+2+N+each_row,MPI_COMM_WORLD);
}
free(buffer_A);
free(buffer_B);
free(buffer_C);
}
MPI_Finalize();
return 0;
}
二、對等模式的行列劃分並行法
1、實現方法
i、將可用於計算的程序數為comm_sz,然後將矩陣A全體行劃分為comm_sz個部分,將矩陣B全體列劃分為comm_sz個部分,從而將整個結果矩陣C劃分為size相同的comm_sz*comm_sz個塊。每個子程序負責計算最終結果的一塊,只需要接收A對應範圍的行和B對應範圍的列,而不需要把整個矩陣傳過去。主程序負責分發和彙總結果。ii、主從模式裡是每個程序所需的塊資料都是由主程序提供的,而對等模式裡每個程序裡只儲存一塊資料,所需的其它塊資料要從其它程序交換。
iii、之後開始計算後所需的Bi資料從下一個程序接收,當前程序的Bi資料發向前一個程序,每個程序計算結果矩陣的一行的塊矩陣。
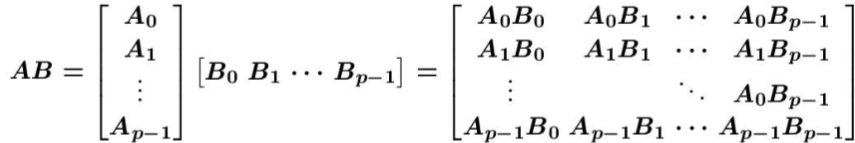
2、實現步驟
(1)將Ai,Bi和Cij(j=0,1,...,p-1)存放在第i個處理器中(這樣處理的方式是為了使得資料在處理器中不重複);(2)Pi負責計算Cij(j=0,1,...,p-1);
(3)由於使用P個處理器,每次每個處理器只計算一個Cij,故計算出整個C需要p次完成。
(4)Cij計算是按對角線進行的。
3、完整程式碼
#include <stdio.h>
#include "mpi.h"
#include <stdlib.h>
#include <math.h>
#include "dgemm_1.h"
/*** 對等模式 行列劃分 ***/
int main(int argc, char **argv)
{
int M=10000,N=10000,K=10000; // 矩陣維度
int my_rank,comm_sz;
double start, stop; //計時時間
double alpha=2,beta=2; // 係數C=aA*B+bC
MPI_Status status;
MPI_Init(&argc,&argv);
MPI_Comm_size(MPI_COMM_WORLD, &comm_sz);
MPI_Comm_rank(MPI_COMM_WORLD,&my_rank);
if(comm_sz>M || comm_sz>K){
if(my_rank==0)
printf("error process:%d\n",comm_sz);
MPI_Finalize();
return 0;
}
int saveM=M; // 為了使行資料平均分配每一個程序
if(M%comm_sz!=0){
M-=M%comm_sz;
M+=comm_sz;
}
int saveK=K;// 為了使列資料平均分配每一個程序
if(K%comm_sz!=0){
K-=K%comm_sz;
K+=comm_sz;
}
int each_row=M/comm_sz; // 矩陣A每塊分多少行資料
int each_col=K/comm_sz; // 矩陣B每列分多少列資料
double *Matrix_A,*Matrix_C,*buffer_A,*buffer_B,*buffer_C,*ans,*result_Matrix;
buffer_A=(double*)malloc(each_row*N*sizeof(double)); // A的塊資料
buffer_B=(double*)malloc(N*each_col*sizeof(double)); // B的塊資料
buffer_C=(double*)malloc(each_row*K*sizeof(double)); // C的塊資料
ans=(double*)malloc(each_row*K*sizeof(double)); // 臨時儲存每塊的結果資料
result_Matrix=(double*)malloc(M*K*sizeof(double)); // 儲存資料計算結果
if(my_rank==0){
double *Matrix_B;
Matrix_A=(double*)malloc(M*N*sizeof(double));
Matrix_B=(double*)malloc(N*K*sizeof(double));
Matrix_C=(double*)malloc(M*K*sizeof(double));
// 給矩陣A B,C賦值
for(int i=0;i<M;i++){
for(int j=0;j<N;j++)
if(i<saveM)
Matrix_A[i*N+j]=j-i;
else
Matrix_A[i*N+j]=0;
for(int p=0;p<K;p++)
Matrix_C[i*K+p]=i*p;
}
for(int i=0;i<N;i++){
for(int j=0;j<K;j++)
if(j<saveK)
Matrix_B[i*K+j]=j+i;
else
Matrix_B[i*K+j]=0;
}
// 輸出A,B,C
//Matrix_print(Matrix_A,saveM,N);
//Matrix_print2(Matrix_B,N,saveK,K);
//Matrix_print2(Matrix_C,saveM,saveK,K);
printf("row=%d col=%d\n",each_row,each_col);
start=MPI_Wtime();
// 0程序儲存第1塊 B0資料
for(int i=0;i<N;i++)
for(int j=0;j<each_col;j++)
buffer_B[i*each_col+j]=Matrix_B[i*K+j];
// 傳送B1 B2 ... B(comm_sz-1)列資料
for(int p=1;p<comm_sz;p++){
int beginCol=(p%comm_sz)*each_col; // 每個塊的列起始位置(座標/偏移量)
for(int i=0;i<N;i++)
MPI_Send(Matrix_B+i*K+beginCol,each_col,MPI_DOUBLE,p,i,MPI_COMM_WORLD);
}
free(Matrix_B);
}
// 分發A0 A1 A2 ... A(comm_sz)行資料
MPI_Scatter(Matrix_A,each_row*N,MPI_DOUBLE,buffer_A,each_row*N,MPI_DOUBLE,0,MPI_COMM_WORLD);
MPI_Scatter(Matrix_C,each_row*K,MPI_DOUBLE,buffer_C,each_row*K,MPI_DOUBLE,0,MPI_COMM_WORLD);
if(my_rank==0){
free(Matrix_A);
free(Matrix_C);
}
// 接收B列資料
if(my_rank!=0){
for(int i=0;i<N;i++)
MPI_Recv(buffer_B+i*each_col,each_col,MPI_DOUBLE,0,i,MPI_COMM_WORLD,&status);
}
//交換(comm_sz-1)次資料B 計算乘積結果
for(int k=0;k<comm_sz;k++){
//int beginRow=my_rank*each_row; // 每個塊的行列起始位置(座標/偏移量)
int beginCol=((k+my_rank)%comm_sz)*each_col;
for(int i=0;i<each_row;i++){
for(int j=0;j<each_col;j++){
double temp=0;
for(int p=0;p<N;p++){
temp+=buffer_A[i*N+p]*buffer_B[p*each_col+j];
}
ans[i*K+beginCol+j]=alpha*temp+beta*buffer_C[i*K+beginCol+j];
}
}
int dest=(my_rank-1+comm_sz)%comm_sz; // 向上一個程序傳送資料塊B
int src=(my_rank+1)%comm_sz; // 接收位置
MPI_Sendrecv_replace(buffer_B,N*each_col,MPI_DOUBLE,dest,N,src,N,MPI_COMM_WORLD,&status);
}
// 結果聚集
MPI_Gather(ans,each_row*K,MPI_DOUBLE,result_Matrix,each_row*K,MPI_DOUBLE,0,MPI_COMM_WORLD);
if(my_rank==0){
//Matrix_print2(result_Matrix,saveM,saveK,K);
stop=MPI_Wtime();
double E=(double)(5.957/(stop-start))/comm_sz;
printf("time:%lfs 並行效率:%.2lf%\n",stop-start,100*E);
}
free(buffer_A);
free(buffer_B);
free(buffer_C);
free(ans);
free(result_Matrix);
MPI_Finalize();
return 0;
}