日常問題: SQL優化
日常開發中,除了開闢新專案,業務需求開發,一般還要做負責系統的日常運維。比如線上告警了,出bug了,必須及時修復。這天,運維反饋mysql cpu告警了,然後抓了該時間節點的慢sql紀錄檔,要開發分析解決。
拿到的慢sql紀錄檔:
# Query 1: 1.16 QPS, 1.96x concurrency, ID 0x338A0AEE1CFE3C1D at byte 7687104
# This item is included in the report because it matches --limit.
# Scores: V/M = 0.02
# Time range: 2022-08-12T16:30:00 to 2022-08-12T17:11:32
# Attribute pct total min max avg 95% stddev median
# ============ === ======= ======= ======= ======= ======= ======= =======
# Count 99 2880
# Exec time 99 4893s 1s 2s 2s 2s 172ms 2s
# Lock time 99 187ms 52us 343us 64us 84us 11us 60us
# Rows sent 97 248 0 1 0.09 0.99 0.28 0
# Rows examine 96 871.46M 308.56k 311.13k 309.85k 298.06k 0 298.06k
# Query size 99 812.81k 289 289 289 289 0 289
# String:
# Hosts 10.22.9.183 (742/25%), 10.26.9.126 (730/25%)... 2 more
# Users order
# Query_time distribution
# 1us
# 10us
# 100us
# 1ms
# 10ms
# 100ms
# 1s ################################################################
# 10s+
# Tables
# SHOW TABLE STATUS LIKE 'serial_number_store'\G
# SHOW CREATE TABLE `serial_number_store`\G
# EXPLAIN /*!50100 PARTITIONS*/
select *
from serial_number_store sn
where 1=1
and company_code = '8511378117'
and warehouse_code = '851'
and sku_no = '6902952880'
and (serial_no = '5007894' or sub_serial_no = 'v')\G查詢資料庫定義,發現定義了幾個index
PRIMARY KEY (`ID`),
KEY `IDX_SERIAL_NUMBER_2` (`WAREHOUSE_CODE`),
KEY `IDX_SERIAL_NUMBER_3` (`SKU_NO`),
KEY `IDX_SERIAL_NUMBER_4` (`SERIAL_NO`),
KEY `IDX_SERIAL_NUMBER_5` (`SUB_SERIAL_NO`),
KEY `IDX_SERIAL_NUMBER_6` (`SKU_NAME`),
KEY `IDX_SERIAL_NUMBER_1` (`COMPANY_CODE`,`WAREHOUSE_CODE`,`SKU_NO`,`SERIAL_NO`) USING BTREE按最左匹配原則,這條sql應該只會命中一個索引。因為or的另一半無法match。
explain發現實際執行計劃:
key: IDX_SERIAL_NUMBER_3
key_len: 259
ref: const
rows: 45864
filtered: 0.95
Extra: Using where表總數量: 13658763
or的優化技巧之一就是拆成2個可以命中索引的sql, 然後union all.
優化為union all
explain select *
from serial_number_store sn
where company_code = '9311046897'
and warehouse_code = '931DCA'
and sku_no = '6935117818696'
and serial_no = '862517054251459'
union all
select *
from serial_number_store sn
where company_code = '9311046897'
and warehouse_code = '931DCA'
and sku_no = '6935117818696'
and sub_serial_no = '862517054251459';最終explain
key: IDX_SERIAL_NUMBER_4 IDX_SERIAL_NUMBER_5
ref: const const
rows: 1 1
filtered: 5.0 5.0
extra: using where 正常到這裡,找到解決方案,就算完事了。但作為線上問題的處理,你得分析為啥以前沒事,現在出問題了。
查詢對應的鏈路追蹤情況:
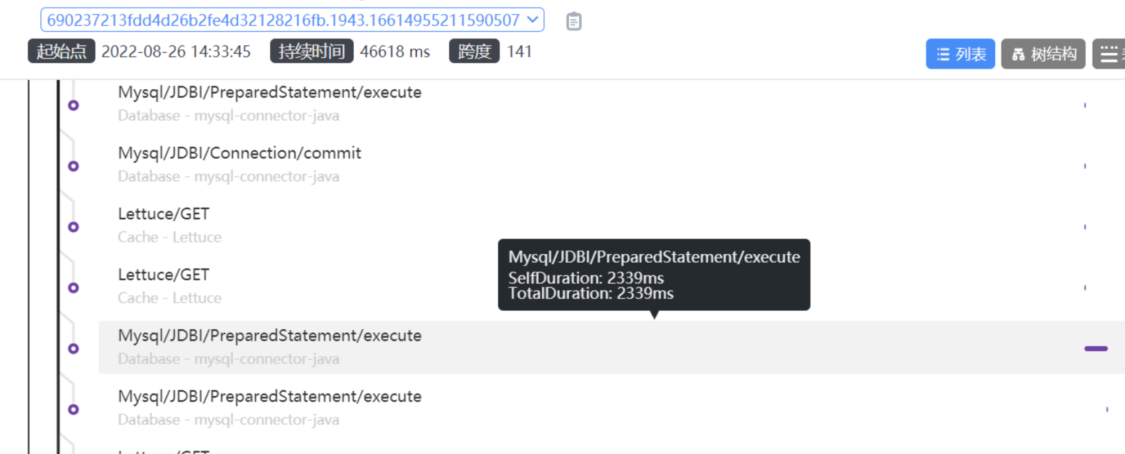
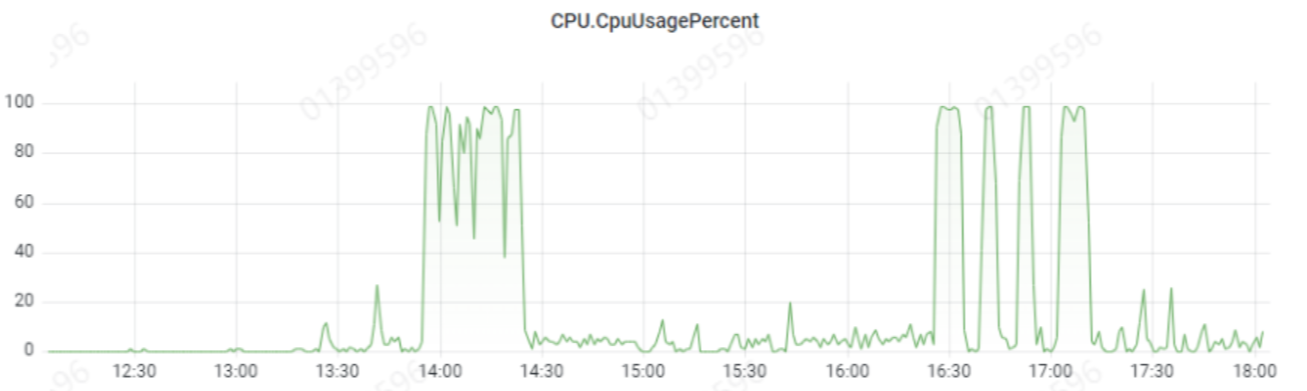
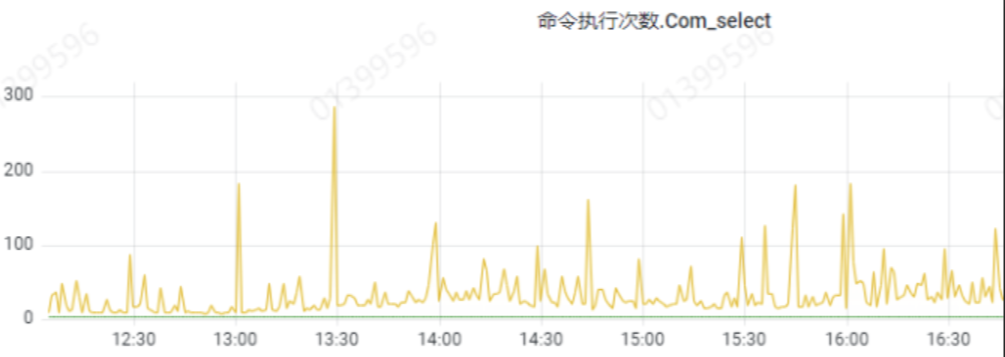
和猜測一致,短時間內批次查詢。幾乎每條sql2s多耗時。雖然是後臺任務,但資料量太大導致cpu 100%.
定位實際的程式碼,mybatis是這麼寫:
<sql id="servialNumberStoreEntityParams">
<if test="id!=null and id!=''"> and ID = #{id}</if>
<if test="companyCode!=null and companyCode!=''"> and company_code = #{companyCode}</if>
<if test="warehouseCode!=null and warehouseCode!=''"> and warehouse_code = #{warehouseCode}</if>
<if test="sku!=null and sku!=''"> and sku_no = #{sku}</if>
<if test="serialNo!=null and serialNo!=''"> and (serial_no = #{serialNo} or sub_serial_no = #{serialNo})</if>
<if test="lotNum!=null and lotNum!=''"> and lot_num = #{lotNum}</if>
</sql>這個查詢片段有多個sql參照了。比如
select *
from serial_number_store sn
where 1=1
<include refid="servialNumberStoreEntityParams" />改造成union也不是不行,比如
select *
from serial_number_store sn
where 1=1
<include refid="servialNumberStoreEntityParams" />
<if test="serialNo!=null and serialNo!=''">
and serial_no = #{serialNo}
union all
select *
from cwsp_tb_serial_number_store sn
where 1=1
<include refid="servialNumberStoreEntityParams" />
and sub_serial_no = #{serialNo}
</if>但前面說了多個片段參照了,對應多個sql查詢方法,然後這多個sql查詢方法又會對應多個業務呼叫。那問題來了,如果改完要測的話,業務場景該怎麼測?一時猶豫了,要不要再花額外的時間去搞迴歸測試,驗證。
和運維小哥說,反正是個後臺任務,先不改吧。運維看沒影響到業務(沒人投訴)也就不管了。
然後第二天上班又收到了告警。逃不掉了。
定位程式碼的時候,發現有個update
<update id="update">
update serial_number_store
<set>
<if test="companyCode!=null and companyCode!=''"> COMPANY_CODE = #{companyCode},</if>
<if test="warehouseCode!=null and warehouseCode!=''"> WAREHOUSE_CODE = #{warehouseCode},</if>
<if test="sku!=null and sku!=''"> SKU_NO = #{sku},</if>
<if test="serialNo!=null and serialNo!=''"> SERIAL_NO = #{serialNo},</if>
<if test="subSerialNo!=null and subSerialNo!=''"> SUB_SERIAL_NO = #{subSerialNo},</if>
<if test="erpno!=null and erpno!=''"> ERP_ORDER = #{erpno},</if>
<if test="docType!=null and docType!=''"> DOCTYPE = #{docType},</if>
<if test="editTime!=null and editTime!=''"> EDITTM = #{editTime},</if>
<if test="editWho!=null and editWho!=''"> EDITEMP = #{editWho},</if>
</set>
where 1=1
<include refid="servialNumberStoreEntityParams" />
</update>這種sql,假如引數沒傳,豈不是全表被覆蓋? 當然,也能改。前提是梳理呼叫鏈路,把這些sql參照的業務場景梳理一遍,確定入參場景,然後修改,然後再模擬場景做測試。想想整個流程,1天不知道搞不搞的定,測試上線等等,還有更長的流程。
這種在設計之初就應該做好優化設計而不是出了問題再改,但當接手古老系統的時候,開發可能換了一波又一波了,這時候除了吐槽之外,只能填坑。與此同時,自己所開發的程式碼,在若干時間後,也許會被另外一個人吐槽(如果自己發現的坑是自己挖的,自然不會吐槽自己)
關注我的公眾號
